Day 29 29.3 base64编码
base64编码
(1)base64是什么
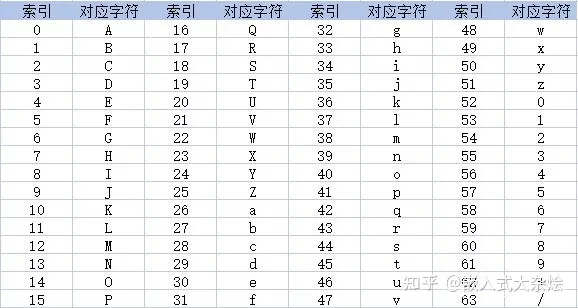
- Base64编码,是由64个字符组成编码集:26个大写字母AZ,26个小写字母az,10个数字0~9,符号“+”与符号“/”。
- Base64编码的基本思路是将原始数据的三个字节拆分转化为四个字节,然后根据Base64的对应表,得到对应的编码数据。
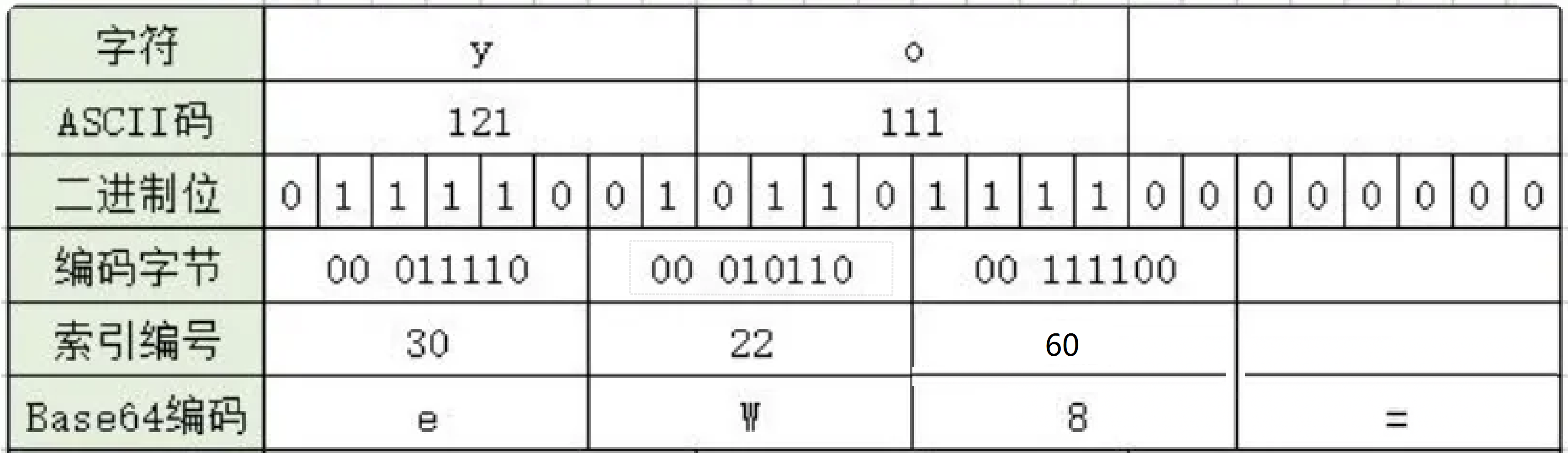
- 当原始数据凑不够三个字节时,编码结果中会使用额外的符号“=”来表示这种情况。
(2)base64原理
- 一个Base64字符实际上代表着6个二进制位(bit)
- 4个Base64字符对应3字节字符串/二进制数据。
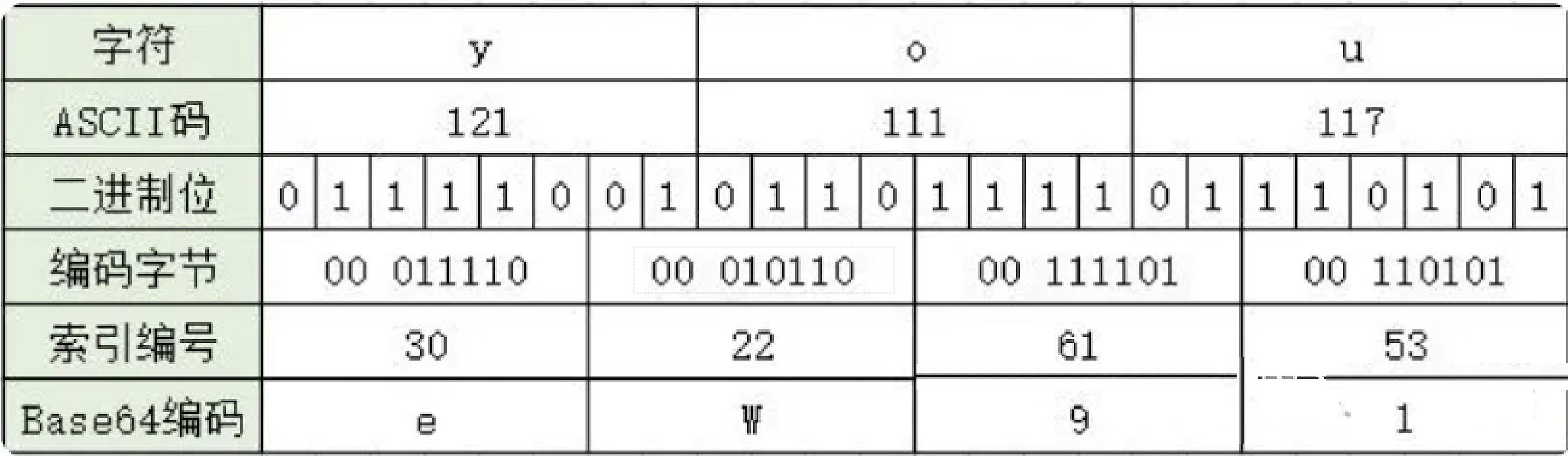
- 3个字符为一组的的base64编码方式如:
- 小于3个字符为一组的编码方式如:
- 总结:base64过程
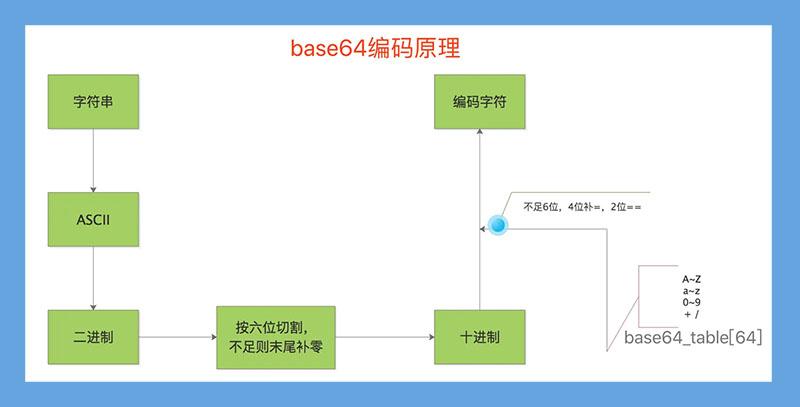
- 最后处理完的编码字符再转字节中不再有base64以外的任何字符。
(3)base64测试
import base64
bs = "you".encode("utf-8")
# 把字节转化成b64
print(base64.b64encode(bs).decode())
bs = "yo".encode("utf-8")
# 把字节转化成b64
print(base64.b64encode(bs).decode())
# 猜测结果
bs = "y".encode("utf-8")
# 把字节转化成b64
print(base64.b64encode(bs).decode())
-
注意, b64处理后的字符串长度
- 一定是4的倍数
- 如果在网页上看到有些密文的b64长度不是4的倍数
- 会报错
-
例如,
import base64
s = "eW91"
ret = base64.b64decode(s)
print(ret)
s = "eW91eQ=="
ret = base64.b64decode(s)
print(ret)
s = "eW91eQ"
ret = base64.b64decode(s)
print(ret)
- 解决思路
- base64长度要求. 字符串长度必须是4的倍数. 填充一下即可
s = "eW91eQ"
# ret = base64.b64decode(s)
# print(ret)
s += ("=" * (4 - len(s) % 4))
print("填充后", s)
ret = base64.b64decode(s).decode()
print(ret)
(4)为什么要base64编码
-
base64 编码的优点:
- 算法是编码,不是压缩,编码后只会增加字节数(一般是比之前的多1/3,比如之前是3, 编码后是4)
- 算法简单,基本不影响效率
- 算法可逆,解码很方便,不用于私密传输。
- 毕竟编码了,肉眼不能直接读出原始内容。
- 加密后的字符串只有【0-9a-zA-Z+/=】 ,不可打印字符(转译字符)也可以传输(关键!!!)
-
有些网络传输协议是为了传输
ASCII文本设计的,- 当你使用其传输二进制流时(比如视频/图片),二进制流中的数据可能会被协议错误的识别为控制字符等等,因而出现错误。
- 那这时就要将二进制流传输编码,因为有些8Bit字节码并没有对应的ASCII字符。
-
比如十进制ASCII码8对应的是后退符号(backspace), 如果被编码的数据中包含这个数值,那么编码出来的结果在很多编程语言里会导致前一个字符被删掉。
- 又比如ASCII码0对应的是空字符,在一些编程语言里代表字符串结束,后续的数据就不会被处理了。
-
用Base64编码因为限定了用于编码的字符集,确保编码的结果可打印且无歧义。
-
不同的网络节点设备交互数据需要:
- 设备A把base64编码后的数据封装在
json字符串里, - 设备B先解析json拿到value,
- 再进行base64解码拿到想要的数据。
- 设备A把base64编码后的数据封装在
早年制定的一些协议都是只支持文本设定的。随着不断发展需要支持非文本了,才搞了一个base64做兼容
虽然编码之后的数据与加密一样都具有不可见性,但编码与加密的概念并不一样。编码是公开的,任何人都可以解码;而加密则相反,你只希望自己或者特定的人才可以对内容进行解密。
- base64处理图片数据:
import base64
source = "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAACAAAAAgCAMAAABEpIrGAAAA7VBMVEUAAAD////////s8v////+txP+qwv+4zf/w9f/2+P+hu//Q3f+yyP+4zf/Q3f////+kvv+90P+80f+2yv/S4P/T4P/M2//z9/+cuP/V4P9Whv////9Uhf9Sg/9Pgf9NgP/8/f9di/9Xh/9lkf5aif9qlP7z9//k7P/c5v+2y/94nv51nP6lv/+LrP6Ep/6BpP5gjf7v9P+wxv/U4f/M2/+sxP+vxv73+f/P3v/J2v+5zf+ivP+fuv9xmf+Ytv6Usv6Hqf58of5vl/7m7v/g6f+zyf6QsP75+//q8P/B0v/W4//C1P6+0P6qwv6ct/76fHZiAAAAGnRSTlMAGAaVR/Py45aC9Mfy2b8t9OPZ2ce/v4L0x/e74/EAAAIZSURBVDjLZVPXYuIwEDSmQ4BLv5O0ku3Yhwu2IZTQe0hy7f8/57QSoYR5sVea1c424wgzl324LRRuH7I507hEJluYucCFEOBGhWzmy7X5+N0WwIjTbrcdBsKulM0z96onGCGE2X6n+cTkj/CqJ480igzkNXp26E9JkABSbBz8i4Bn3EkH840mKHoxs49fZQzt2Kd03FQEzSB3WsejB9Jqf1CJQBM0wCurABWBoub0gkDENwyStTHA62pwSWDtklRQ4FLfjnaiPqVW60hAYeLKNHIREOZuKTL80H6XBFCwn4BAmDOyLiOQUIlOSEjaoS+Ju57NZuul73Fml4w6yAivSLBW3MGfcfBmIegmArg3alICdJHgy1jQt8Z/6CcC4DdGXhLIoiWRACpbLYbDYW80GnXp2GH8ShP+PUvEoHsAIFq9Xm8+kXlIwkkI9pm+05Tm3yWqu9EiB0pkwjWBx2i+tND1XqeZqpPU4VhUbq/ekR8CwTRVoRxf3ifTbeIwcONNsJZ2lxFVKDMv1KNvS2zXdrnD+COvR1PQpTZKNlKD3cLCOJNnivgVxkw169BunlKFaV9/B+LQbqOsByY4IVgDB59dl/cjR9TIJV1Lh7CGqUqH/DDPhhZYOPkdLz6m0X7GrzPHsSe6zJwzxvm+5NeNi8U5ABfn7mz7zHJFrZ6+BY6rd7m8kQtcAtwwXzq4n69/vZbP1+pn6/8fsrRmHUhmpYYAAAAASUVORK5CYII="
s = source.split(",")[1]
with open("a.png", "wb") as f:
f.write(base64.b64decode(s))
(5)base64编码的变种
- 因为Base64编解码的变种只与索引表和反向索引表有关系,所以可以在ASCII码(1字节范围内)做任意变种。下面描述一个变种例子。
- 标准的Base64并不适合直接放在URL里传输
- 为解决此问题
- 可采用一种用于URL的改进Base64编码,它在末尾填充'='号
- 并将标准Base64中的
/和+分别改成了-和_ - 这样就免去了在URL编解码和数据库存储时所要作的转换,避免了编码信息长度在此过程中的增加,并统一了数据库、表单等处对象标识符的格式。
- 另有一种用于正则表达式的改进Base64变种,它将“+”和“/”改成了“!”和“-”
- 因为
+,*以及前面在 IRCu 中用到的[和]在正则表达式中都可能具有特殊含义。
- 因为
- _此外还有一些变种
- Base64要求把每三个8Bit的字节转换为四个6Bit的字节(38 = 46 = 24),然后把6Bit再添两位高位0,组成四个8Bit的字节,也就是说,转换后的字符串理论上将要比原来的长1/3。
本文来自博客园,作者:Chimengmeng,转载请注明原文链接:https://www.cnblogs.com/dream-ze/p/17380722.html

