Day 13 13.3 Cookie与Session
Cookie
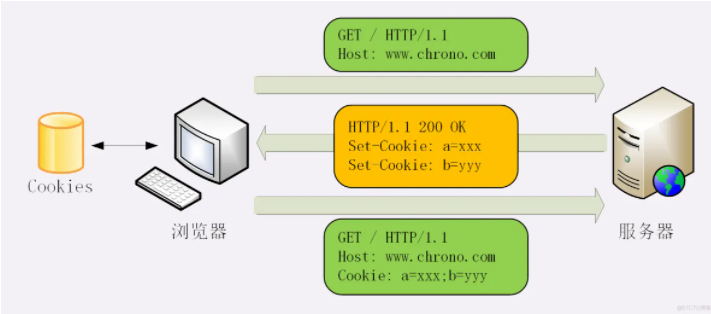
一、什么是cookie?
- cookie的本质就是一组数据(键值对的形式存在)
- 是由服务器创建,返回给客户端,最终会保存在客户端浏览器中。
- 如果客户端保存了cookie,则下次再次访问该服务器,就会携带cookie进行网络访问。
- 典型的案例:网站的免密登录
二、Cookie的玩法
1、构建服务器
# server.py
from flask import Flask, request, make_response, render_template
import json
app = Flask(__name__, template_folder="temps")
COOKIE = "sadfnwejfnfcvxwerw213kbnkj2k3j23234jk2k"
@app.route("/login")
def login():
return render_template("login.html")
@app.route("/auth", methods=['POST'])
def auth():
user = request.form.get("user")
pwd = request.form.get("pwd")
if user == "yuan" and pwd == "123":
# 设置响应体
resp = make_response("登录成功")
resp.set_cookie("cookie", COOKIE)
return resp
else:
print("OK")
return "登录失败!"
@app.route("/")
def index():
return render_template("index.html")
@app.route("/books")
def books():
print(request.cookies.get("cookie"))
if request.cookies.get("cookie") == COOKIE:
data = ["西游记", "三国演义", "水浒传", "大话西游"]
return json.dumps(data, ensure_ascii=False)
else:
return "认证失败,请重新登录!"
if __name__ == '__main__':
app.run() # 默认端口号
2、构建index页面
# index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.5.1/jquery.js"></script>
</head>
<body>
<h1>四大名著</h1>
<p class="content"></p>
<script>
$.ajax({
url: "/books",
success: function (res) {
console.log(res)
$(".content").html(res)
}
})
</script>
</body>
</html>
3、爬虫的cookie应用
# 请求cookie
requests.get(url="", headers={}, cookies={})
# 响应cookie
print(respone.cookies)
print(respone.cookies.get_dict())
print(respone.cookies.items())
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
}
# 获取从服务器端响应的cookie
url = 'https://xueqiu.com/'
res = requests.get(url, headers=headers)
cookies = dict(res.cookies)
url = 'https://stock.xueqiu.com/v5/stock/batch/quote.json?symbol=SH000001,SZ399001,SZ399006,SH000688,SH000016,SH000300,BJ899050,HKHSI,HKHSCEI,HKHSTECH,.DJI,.IXIC,.INX'
res = requests.get(url, headers=headers, cookies=cookies)
# print(res.json())
print(res.content.decode())
三、爬取雪球网中的咨询数据
-
经过分析发现帖子的内容是通过ajax动态加载出来的,因此通过抓包工具,定位到ajax请求的数据包,从数据包中提取:
-
url:https://xueqiu.com/statuses/hot/listV2.json?since_id=-1&max_id=311519&size=15
-
请求方式:get
-
请求参数:拼接在了url后面
import requests import os headers = { 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36', } url = 'https://xueqiu.com/statuses/hot/listV2.json' param = { "since_id": "-1", "max_id": "311519", "size": "15", } response = requests.get(url=url,headers=headers,params=param) data = response.json() print(data) #发现没有拿到我们想要的数据-
分析why?
- 切记:只要爬虫拿不到你想要的数据,唯一的原因是爬虫程序模拟浏览器的力度不够!一般来讲,模拟的力度重点放置在请求头中!
- 上述案例,只需要在请求头headers中添加cookie即可!
-
爬虫中cookie的处理方式(两种方式之cookie):
-
手动处理:将抓包工具中的cookie赋值到headers中即可
- 缺点:
- 编写麻烦
- cookie通常都会存在有效时长
- cookie中可能会存在实时变化的局部数据
- 缺点:
-
-
-
Session
1、什么是session
- session对象:该对象和requests模块用法几乎一致.如果在请求的过程中产生了cookie,如果该请求使用session发起的,则cookie会被自动存储到session中.
- session 对象
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
}
# 获取从服务器端响应的cookie
url = 'https://xueqiu.com/'
session = requests.session()
session.get(url, headers=headers)
url = 'https://stock.xueqiu.com/v5/stock/batch/quote.json?symbol=SH000001,SZ399001,SZ399006,SH000688,SH000016,SH000300,BJ899050,HKHSI,HKHSCEI,HKHSTECH,.DJI,.IXIC,.INX'
res = session.get(url, headers=headers)
print(res.json())
2、爬虫中cookie的处理方式(两种方式之session):
-
自动处理
-
-
基于session对象实现自动处理cookie。
- 1.创建一个空白的session对象。
- 2.需要使用session对象发起请求,请求的目的是为了捕获cookie
- 注意:如果session对象在发请求的过程中,服务器端产生了cookie,则cookie会自动存储在session对象中。
- 3.使用携带cookie的session对象,对目的网址发起请求,就可以实现携带cookie的请求发送,从而获取想要的数据。
-
注意:session对象至少需要发起两次请求
-
第一次请求的目的是为了捕获存储cookie到session对象
-
后次的请求,就是携带cookie发起的请求了
import requests #1.创建一个空白的session对象 session = requests.Session() headers = { 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36', } main_url = 'https://xueqiu.com/' #2.使用session发起的请求,目的是为了捕获到cookie,且将其存储到session对象中 session.get(url=main_url,headers=headers) url = 'https://xueqiu.com/statuses/hot/listV2.json' param = { "since_id": "-1", "max_id": "311519", "size": "15", } #3.就是使用携带了cookie的session对象发起的请求(就是携带者cookie发起的请求) response = session.get(url=url,headers=headers,params=param) data = response.json() print(data)
-
-
本文来自博客园,作者:Chimengmeng,转载请注明原文链接:https://www.cnblogs.com/dream-ze/p/17176494.html

