

[Python 应用:爬虫] Selenium 定位元素方法
本文内容参考:https://selenium-python.readthedocs.io/locating-elements.html
定位元素有很多种方式,你可以选择适合你使用情况的。Selenium 提供如下几种定位元素的方式:
- find_element_by_id
- find_element_by_name
- find_element_by_xpath
- find_element_by_link_text
- find_element_by_partial_link_text
- find_element_by_tag_name
- find_element_by_class_name
- find_element_by_css_selector
上述定位方式只定位页面中的拥有同样类型第一个元素,如果想定位同样名字或同样名字的所有元素,以下方式可以采用:(返回的是一个列表,这样的话也意味着你可以定位列表中的任何一个元素,比如可用于有同样的class name 的元素的的定位,通过 class name定位所有同样class name的元素列表,再指定列表中的某个元素就 能得到你想要的元素了)
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
除了上面的方式外,还有两种可选择的方式:find_element and find_elements. 但是这两种方式要导入 By ,如下例子:
from selenium.webdriver.common.by import By
driver.find_element(By.XPATH, '//button[text()="Some text"]')
driver.find_elements(By.XPATH, '//button')
通过By 的方式,下面的属性是可以通过By方式调用来定位元素的:
ID = "id"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
NAME = "name"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"
此处为分割线
--------------------------------------------------------------------------------------------------------
下面将分别举例说明每种定位方式:
一、通过 Id 定位元素
这种方式是最好理解的。如果你已经知道某个元素的Id属性,直接可以用Id定位到这个元素。但是在有多个元素都拥有这个Id属性的时候,你通过find_element_by_id只能返回第一个匹配到的元素。
下面的方式也会有同样的问题,往下就不会赘述这个问题。如果匹配不到的话,会返回NoSuchElementException。
看个例子,网页代码如下:

form 元素就可以通过如下方式定位到:
login_form = driver.find_element_by_id('loginForm')
二、通过 Name 定位元素
第二种方式也是很好理解的。还是上面的网页代码,如果想过定位到 username & password 两个元素,就可以通过 find_element_by_name 的方式
username = driver.find_element_by_name('username')
password = driver.find_element_by_name('password')
假设网页代码中有如下:

可以看到,有两个元素有同样的名字属性。我们通过 find_element_by_name的方式实际只能定位到 Login 。
Login = driver.find_element_by_name('continue')
如果我们想定位到Clear 怎么办呢? 可以通过 find_elements_by_name 的方式。上面说过通过这种方式返回的是一个list, 那个对应list 第二个元素就是我们要的Clear 了。
Clear = driver.find_elements_by_name('continue')[1]
三、通过 XPath 定位元素
XPath是什么?
Xpath 是一种可以定位XML文件节点的语言。HTML文件作为XML的一种implementation, Selenium 用户便可以利用这种强大的语言来定位网页中元素。XPath 不仅只是可以通过简单的Id和Name属性来定位元素,它还提供了其他的可能性。
为什么我们要用XPath?
一个主要原因是当你没有一个合适的id 或者Name 属性来定位你要查找的元素,你就需要用到这种方式。你可以通过XPath来用绝对路径定位你要找的元素,或者关联某个拥有特定Id或者Name的元素。XPath 同样可以指定元素不是通过Id或者Name的方式而是通过其他属性。
怎么用XPath?
详见文章:[Python 应用:爬虫] Selenium 之 XPath 语法
简单看一下语法,以有助于后续理解
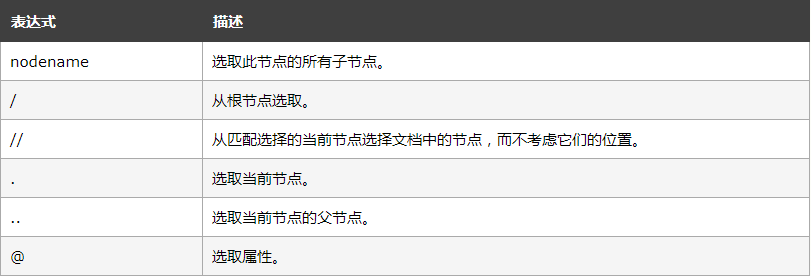
绝对路径的XPath可以包含从根节点开始的所有元素,这样的话,结构树稍微有调整,就意味着路径可能失效。通过定位到某个元素再来定位和它有关系的其他元素是我们常用的方式。这样的话修改的可能性更小。
举例来说明:
网页如下

form 这个元素可以通过以下几种方式来定位:
login_form = driver.find_element_by_xpath("/html/body/form[1]")
login_form = driver.find_element_by_xpath("//form[1]")
login_form = driver.find_element_by_xpath("//form[@id='loginForm']")
第一种是绝对路径的方式;
第二种是所有Name为form中的第一个元素;
第三种是所有Name为form中Id 属性为‘loginForm’ 的元素
username 可以通过下面几种方式来定位
username = driver.find_element_by_xpath("//form[input/@name='username']")
username = driver.find_element_by_xpath("//form[@id='loginForm']/input[1]")
username = driver.find_element_by_xpath("//input[@name='username']")
第一种表达的是,Name 为form 的所有元素中那个有Name为input的子元素,而且该子元素包含username 的name 属性。
第二种表达的是,name 为from 的所有元素中id为‘loginForm’的那个元素中第一个input子元素。
第三种表达的是,第一个name 为input 而且有name 属性为'username'的元素。
Clear 按钮元素可以通过以下几种方式定位
clear_button = driver.find_element_by_xpath("//input[@name='continue'][@type='button']")
clear_button = driver.find_element_by_xpath("//form[@id='loginForm']/input[4]")
第一个表达的是,Input的所有元素中拥有 name属性为‘continue’ 和 type属性为‘button’的那个元素
第二个表达的是,name 为form 的所有元素中id属性为‘loginForm’的那个元素中的子元素为input 的第四个元素。
四、通过 Link Text 定位超链接
如果说知道一个网页链接附属的链接文本,可以通过这种方式来匹配满足要求的第一个元素。没有元素匹配到的话,这会返回NoSuchElementException。
下面看个例子,网页文本如下:
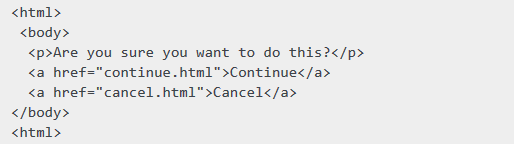
如果说想要定位到 continue.html 这个链接,这可以通过如下方式
continue_link = driver.find_element_by_link_text('Continue')
continue_link = driver.find_element_by_partial_link_text('Conti')
五、通过 Tag Name 定位元素
这种方式很好理解,就是通过元素的tag name 来定位元素。如果匹配到的话,则匹配成功的第一个元素会被返回,没匹配成功的话,
则会返回NoSuchElementException。
下面看个例子,网页如下:
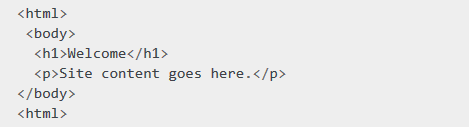
heading (h1)元素可以通过下面的方式定位
heading1 = driver.find_element_by_tag_name('h1')
六、通过 Class Name 定位元素
这种方式就是通过元素的class name 属性来定位元素。方式不同,返回结果同上面。
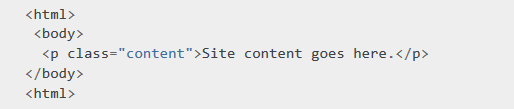
看个简单例子,网页如下:
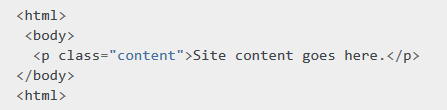
p 元素就可以通过下面的元素定位到
content = driver.find_element_by_class_name('content')
七、通过 CSS 选择器来定位元素
这种方式就是通过css 选择器句法的方式来定位元素。这种方式类似XPath ,但css selectors 到底是什么,我们要怎么用 css selectors 呢?
详情请看文章:[Python 应用:爬虫] Selelium 之 css selectors
下面只是看个非常简单的例子,虽然可能根本看不懂咋回事,没关系,上面链接可以拯救你。
p 这个元素可以通过下面的方式定位到
content = driver.find_element_by_css_selector('p.content')
