

2020.06.20--全天课--第2次:python简介、编解码、python数据类型
一、python简介
1、python特点简介
python语言是一种可以称得上既简单又功能强大的编程语言,注重能够解决问题,而不是繁琐的语法和数据结构
特点:
- 简单易学,功能强大的编程语言
- 高效率的高层数据结构
- 简单而有效地实现面向对象编程
- 简洁的语法和对动态输入的支持
- 特别适用于快速的应用程序开发
- 免费开源
- 移植性很好
- 类库强大
2、python的类别
Cpython
Jpython
Ironpython
3、执行python
交互模式:
每一行代码执行后,均输出结果
文件模式:
代码写在文件中,然后执行
执行平台:
Windows、linux、mac
常用的编辑器:
- Eclipse+pydev
- Pycharm
- Sublime
- Notepad++
- 写字板
对于初学者,强烈建议使用写字板进行程序编写,强化常用语法的记忆和使用效果
二、编码初解
1、了解编码
1.1、编码支持
- ASCII编码
- GB2312编码
- GBK编码
- ANSI(扩展的ASCII编码)
- Unicode编码
- UTF-8编码
1.2、UTF-8、UTF-16、UTF-32的一些区别
1.2.1、UTF编码方式的设计初衷主要就是节省,UTF-8因为兼容ASCII,可以使用一个字节表示英语世界常用字符,比较节省空间和宽度,UTF-8是变长的字符串
1.2.2、UTF-16因为使用两个字节为单位,所以分大尾和小尾,即UTF-16 be和UTF-16 le。很多人其实不知道UTF-16有两种,他们也搞不清楚自己把数据存成了be还是le。
1.2.3、对于编程来说,最友好的编码是UTF-32。由于UTF-32表示任何字符都使用4字节,读到内存中是个均匀的整型数组,于是我们可以很方便地随机访问任何一个字符。其他方式则不允许这么操作,UTF-8是变长的,无法使用随机访问的方式读取。
1.2.4、所以最理想的文字处理方式是用UTF-8存储和传输,程序读到内存中转为UTF-32处理。
2、python代码的中文问题
2.1、python2.7版本:
2.2、python3版本:
总结一句话:
3、字符串与编码
3.1、Python的字符串类型
3.1.1、创建方法:
>>> bytestring = 'hello Unicode World!' >>> print(bytestring) hello Unicode World! >>> print(type(bytestring)) <class 'str'>
创建一个字节字符串:(字节字符串前面会有一个b)
>>> unicodeString = 'hello world!'.encode('gbk') >>> print(unicodeString) b'hello world!' >>> print(type(unicodeString)) <class 'bytes'> >>>
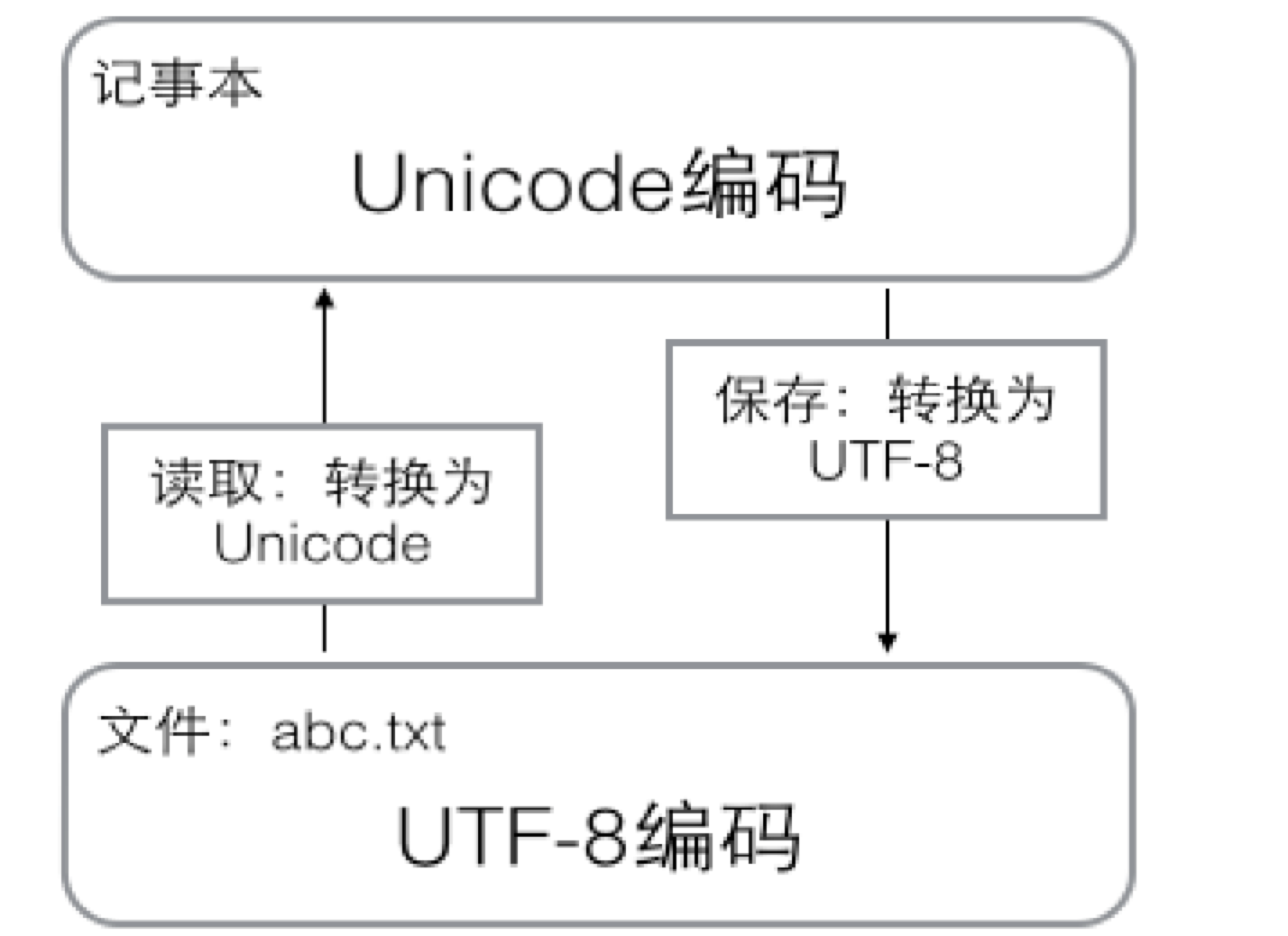
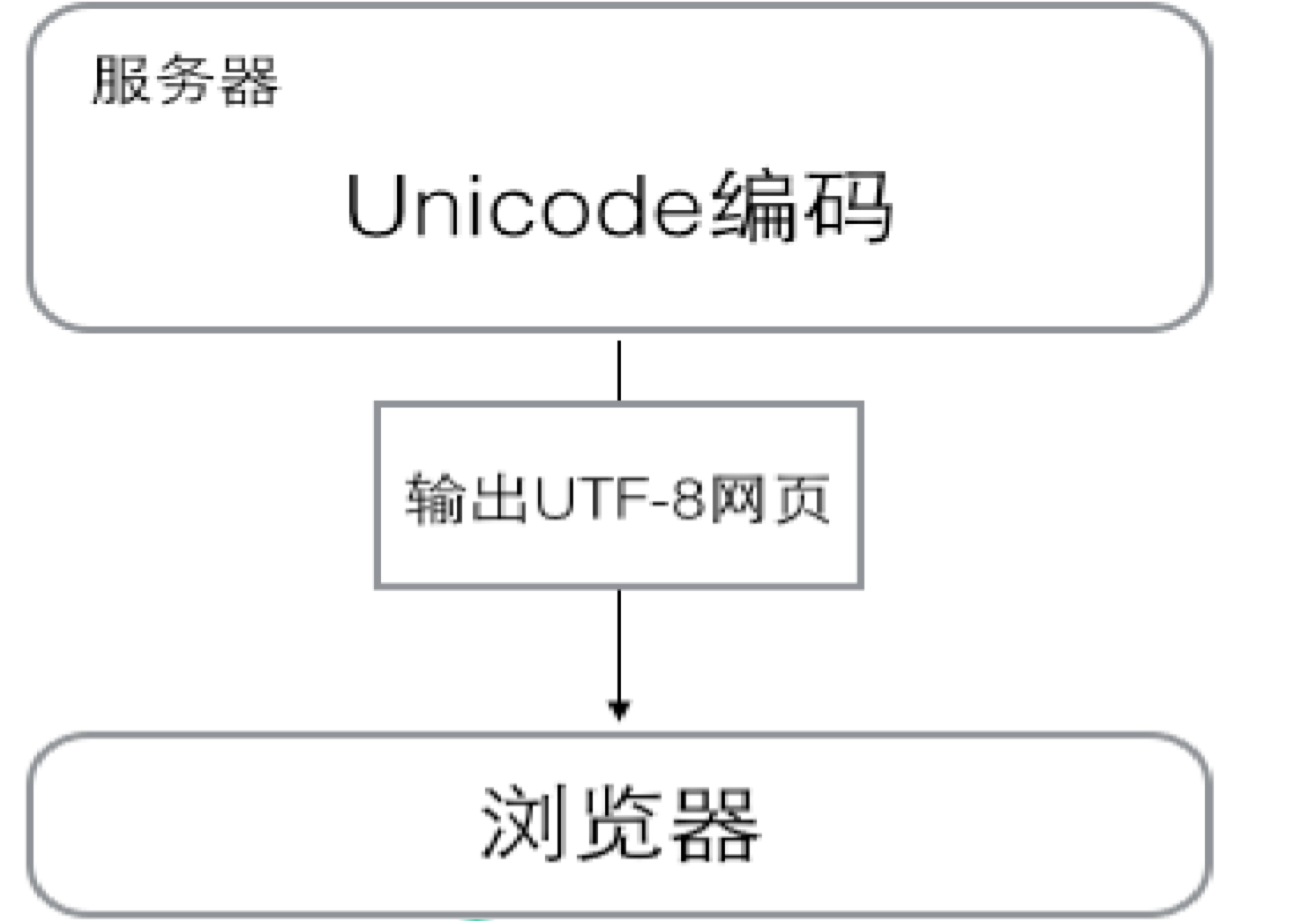
3.2、字符转换的过程
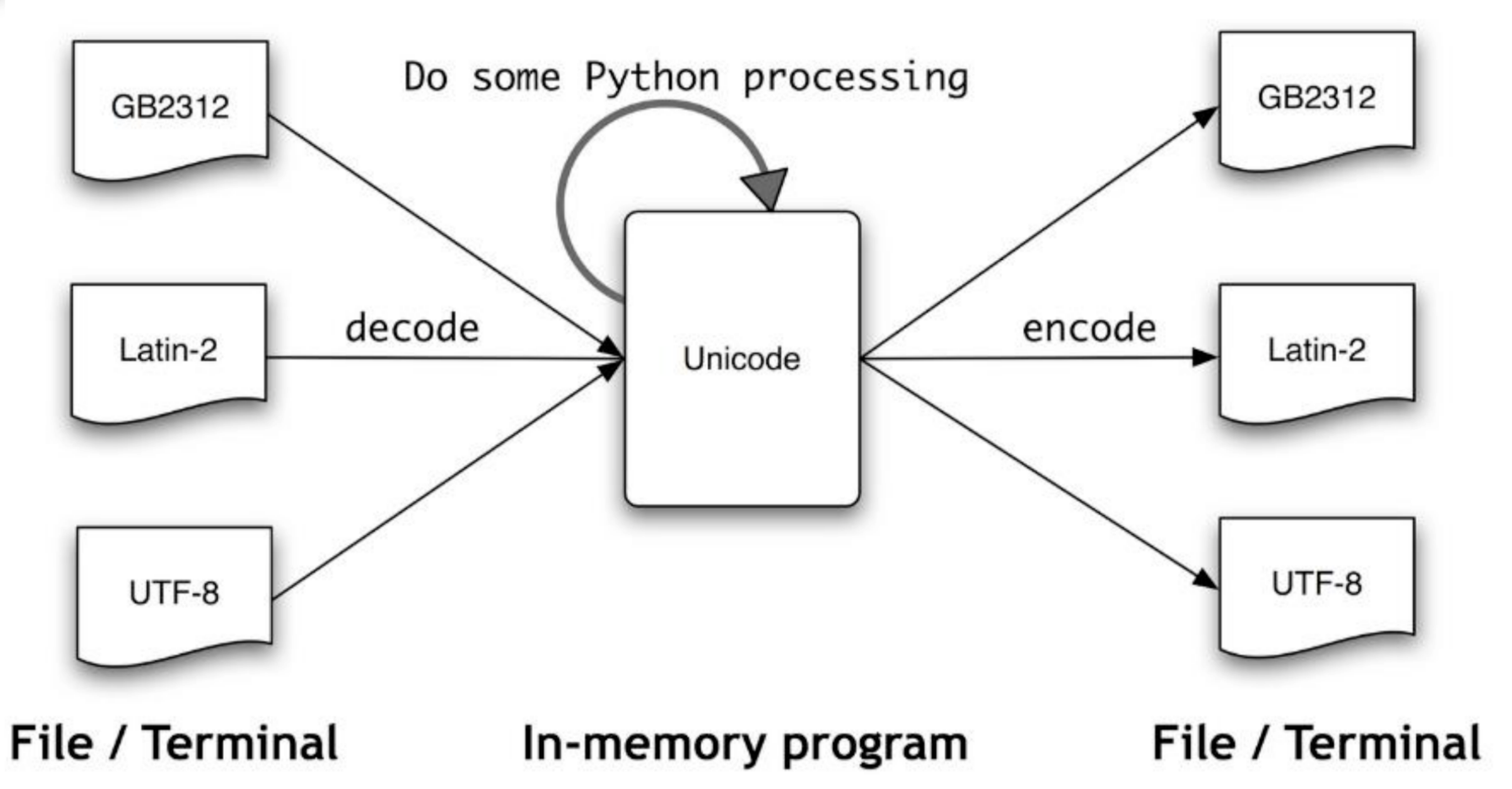
3.3、编码转换
3.3.1.、代码中字符串的默认是unicode。
3.3.2、 所以要做一些编码转换通常是要将Unicode转换为对应得字节字符串,即从Unicode编码(encode)成另一种编码。
unicode→encode(“utf-8”)
➢ decode 的作用是将其他编码的字符串转换成 Unicode 编码
➢ encode 的作用是将Unicode编码转换成其他编码的字符串
➢ 进行编码转换的时候必须先知道 name 是那种编码,然后 decode 成 Unicode 编码,最后再 encode 成需要编码
➢ name 已经就是 Unicode 编码了,那么就不需要进行 decode 进行解码转换了,直接用 encode 就可以编码成你所需要的编码
3.4、中文使用ASCII码编码报错
>>> '测试'.encode('gbk') b'\xb2\xe2\xca\xd4' >>> '测试'.encode('utf-8') b'\xe6\xb5\x8b\xe8\xaf\x95' >>> '测试'.encode('ascii') Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128) >>> b'测试' File "<stdin>", line 1 SyntaxError: bytes can only contain ASCII literal characters. >>> b'abc' b'abc' >>>
3.5、字节字符串和Unicode的字符串的互转
>>> s = 'glory' >>> print('字符串类型:',type(s)) 字符串类型: <class 'str'> >>> s_1 = 'glory'.encode('utf-8') >>> print('字节字符串类型:',type(s_1)) 字节字符串类型: <class 'bytes'> >>> s_2 = 'glory'.encode('utf-8').decode('utf-8') >>> print('字符串类型:',type(s_2)) 字符串类型: <class 'str'> >>>
>>> s = b"glory" >>> print("字节字符串类型:", type(s)) 字节字符串类型: <class 'bytes'> >>> s_1 = "glory" >>> print("字符串类型",type(s_1)) 字符串类型 <class 'str'> >>> s_2 = b"glory".decode("utf-8").encode("utf-8") >>> print("字节字符串类型:", type(s_2)) 字节字符串类型: <class 'bytes'> >>>
3.6、文件中的 3 种编码互转
>>> fp1 = open("/Users/a.txt",'r',encoding="gbk") >>> info1 = fp1.read() >>> print("字符串类型:",type(info1)) 字符串类型: <class 'str'> >>> print("字节类型:",type(info1.encode("utf-8"))) # 编码为 utf-8 格式字节类型数据 字节类型: <class 'bytes'> >>> fp2 = open("/Users/a.txt","w",encoding="utf-8") >>> fp2.write(info1) 11 >>> fp1.close() >>> fp2.close() >>>
3.7、如何判断是否是字符串
>>> s = "字符串" >>> b = b"byte" >>> if isinstance(s,str): ... print("s是字符串") ... s是字符串 >>> if isinstance(b, bytes): ... print("b是字节类型") ... b是字节类型 >>>
三、python基础
1、数据类型和变量
1.1、help命令
1.1.1、print
>>> help('print')


Help on built-in function print in module builtins: print(...) print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False) Prints the values to a stream, or to sys.stdout by default. Optional keyword arguments: file: a file-like object (stream); defaults to the current sys.stdout. sep: string inserted between values, default a space. end: string appended after the last value, default a newline. flush: whether to forcibly flush the stream. (END)
1.1.2、zip
help(zip)
help(zip)>>> zip((1,2,3),(4,5,6)) <zip object at 0x103713c48> >>> list(zip((1,2,3),(4,5,6))) [(1, 4), (2, 5), (3, 6)] >>> zip((1,2,3),(4,5,6),(7,8,9)) <zip object at 0x103713c48> >>> list(zip((1,2,3),(4,5,6),(7,8,9))) [(1, 4, 7), (2, 5, 8), (3, 6, 9)] >>>
1.2、dir命令
1.2.1、math的内置方法
>>> import math >>> dir(math)
['__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil', 'copysign', 'cos', 'cosh', 'degrees', 'e', 'erf', 'erfc', 'exp', 'expm1', 'fabs', 'factorial', 'floor', 'fmod', 'frexp', 'fsum', 'gamma', 'gcd', 'hypot', 'inf', 'isclose', 'isfinite', 'isinf', 'isnan', 'ldexp', 'lgamma', 'log', 'log10', 'log1p', 'log2', 'modf', 'nan', 'pi', 'pow', 'radians', 'remainder', 'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'tau', 'trunc']
1.2.2、字符串相关的内置方法
>>> dir("abc") ['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill'] >>>
1.3、内置方法
dir(__builtins__)
['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'ZeroDivisionError', '_', '__build_class__', '__debug__', '__doc__', '__import__', '__loader__', '__name__', '__package__', '__spec__', 'abs', 'all', 'any', 'ascii', 'bin', 'bool', 'breakpoint', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']
1.3.1、abs 取绝对值
>>> abs(-2) 2 >>> abs(5) 5 >>> abs(0) 0 >>>
1.3.2、取最大值
>>> max([1,2,3,4,5]) 5 >>> max([1,2,300,4,5]) 300 >>> max([1,2,300,4000,5]) 4000 >>>
1.3.3、输出--print
>>> print('学习python') 学习python
1.3.4、四舍五入--round--【是在没弄明白这个函数的用法】
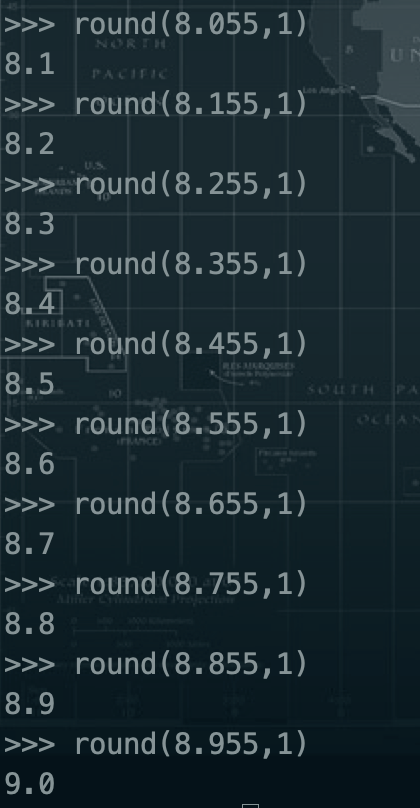
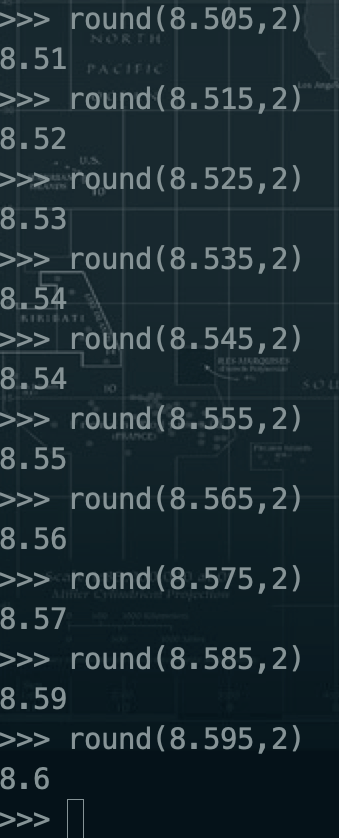
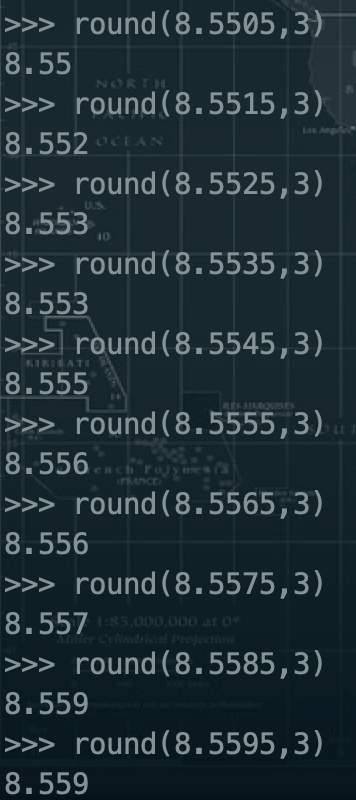
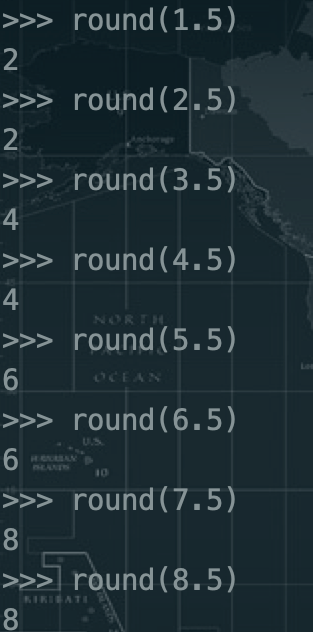
>>> round(12345.12345,-2)
12300.0
>>>
print math.ceil(f) #向上取整 print math.floor(f) #向下取整 自己定
1.3.5、求商和余数--divmod
>>> divmod(9,3) (3, 0) >>> divmod(10,3) (3, 1) >>> divmod(11,3) (3, 2) >>> divmod(12,3) (4, 0) >>> divmod(12,3)[0] 4 >>> divmod(12,3)[1] 0 >>>
1.3、常量
1.3.1、定义:
常量是指一旦初始化后就不能修改的固定值
1.4、数
1.4.1:定义
python3 中有 4 种类型的数----整数、布尔类型、浮点数和复数。
1.4.2、整数:
5 是一个整数的例子
>>> a = 1 >>> type(a) <class 'int'>
1.4.3、布尔类型
True+1 的结果为 2.(默认 True 为 1 ,False 为 0。)
>>> c = True >>> type(c) <class 'bool'> >>> d = False >>> type(d) <class 'bool'> >>> e = True + 1 >>> type(e) <class 'int'> >>> e 2 >>> f = False +1 >>> f 1
1.4.4、浮点数
3.21 和 52.3E-4 是浮点数的例子。E 标记表示 10 的幂。在这里,52.3E-4 表示52.3*10-4
>>> b = 1.1 >>> type(b) <class 'float'>
1.4.5、复数
(-5+4j) 和(2.3-4.6j) 是复数的例子
>>> g = 1+1j >>> type(g) <class 'complex'>
1.5、逻辑值、与或非
1.5.1、and:只要有一个 false,整个表达式值为 false。
T and T --> T F and T --> F T and F --> F F and F --> F
>>> 1 < 2 and 2 < 3 True >>> 1 > 2 and 2 < 3 False >>> 1 < 2 and 2 > 3 False >>> 1 > 2 and 2 > 3 False >>>
练习:
函数,有个参数,如果两个参数都是数字 那么打印一句话,都是数字 否则打印不都是数字
题解 >>> def two_num(num1,num2): ... if isinstance(num1,(int,float)) and isinstance(num2,(int,float)): ... print("都是数字!!") ... else: ... print("不都是数字。") ... >>> two_num(1,'a') 不都是数字。 >>> two_num(1,5) 都是数字!! >>> two_num('a','b') 不都是数字。 >>> two_num('a',1) 不都是数字。
1.5.2、or:只要有一个true,整个表达式值为true;多个条件,只要有一个是 True 就是 True
T or T --> T T or F --> T F or T --> T F or F --> F
>>> 1 < 2 or 2 < 3 True >>> 1 < 2 or 2 > 3 True >>> 1 > 2 or 2 < 3 True >>> 1 > 2 or 2 > 3 False >>>
练习:
函数,两个参数,
只要有一个是数字,那么就打印至少有一个数字
否则,打印都不是数字
>>> def two_num1(num1,num2): ... if isinstance(num1,(int,float)) or isinstance(num2,(int,float)): ... print("至少有一个是数字类型") ... else: ... print("两个都不是数字") ... >>> two_num1(1,'a') 至少有一个是数字类型 >>> two_num1('b','a') 两个都不是数字 >>> two_num1('b',1) 至少有一个是数字类型 >>> two_num1(5,1) 至少有一个是数字类型 >>>
1.5.3、非--not:表达式的相反值
not True --> False not Falose --> True
练习:
函数,就一个参数,
如果不是数字类型,那么return None
如果是数字类型,打印一下数字+10后的结果。
>>> def is_num(num1): ... if isinstance(num1,(int,float)): ... return num1+10 ... else: ... return None ... >>> print(is_num(10)) 20 >>> print(is_num("a")) None >>>
1.5.4、bool类型
>>> 2>1 True >>> 2<1 False >>> bool(2>1) True >>> bool(2<1) False >>> bool([]) False >>> bool(()) False >>> bool({}) False >>> bool("") False >>> bool((1,2)) True
1.6、变量
1.6.1、定义:
变量就是可以改变的量。
➢变量是存储在内存中的值。这就意味着在创建变量时会在内存中开辟一个空间。
a=1 1在内存中有个地址。 a=1:a是一个指针,指针就是存储一个内存地址的变量 a---->1在内存中的地址 a=2: 1在内存中的地址有没有发生改变呢? 本质:a这个指针指向了内存2存在的地址。 变量本质:存储的在内存中变量的地址变了 1 并没有被改变 数字:不可变类型。
>>> a = 1 >>> id(a) 4416880304 >>> a = 1.1 >>> id(a) 4418310816 >>> >>> >>> >>> a = 1 >>> A = 1 >>> id(a) 4416880304 >>> id(A) 4416880304 >>> a == A True >>> A = 2 >>> id(a) 4416880304 >>> id(A) 4416880336 >>> a == A False >>>
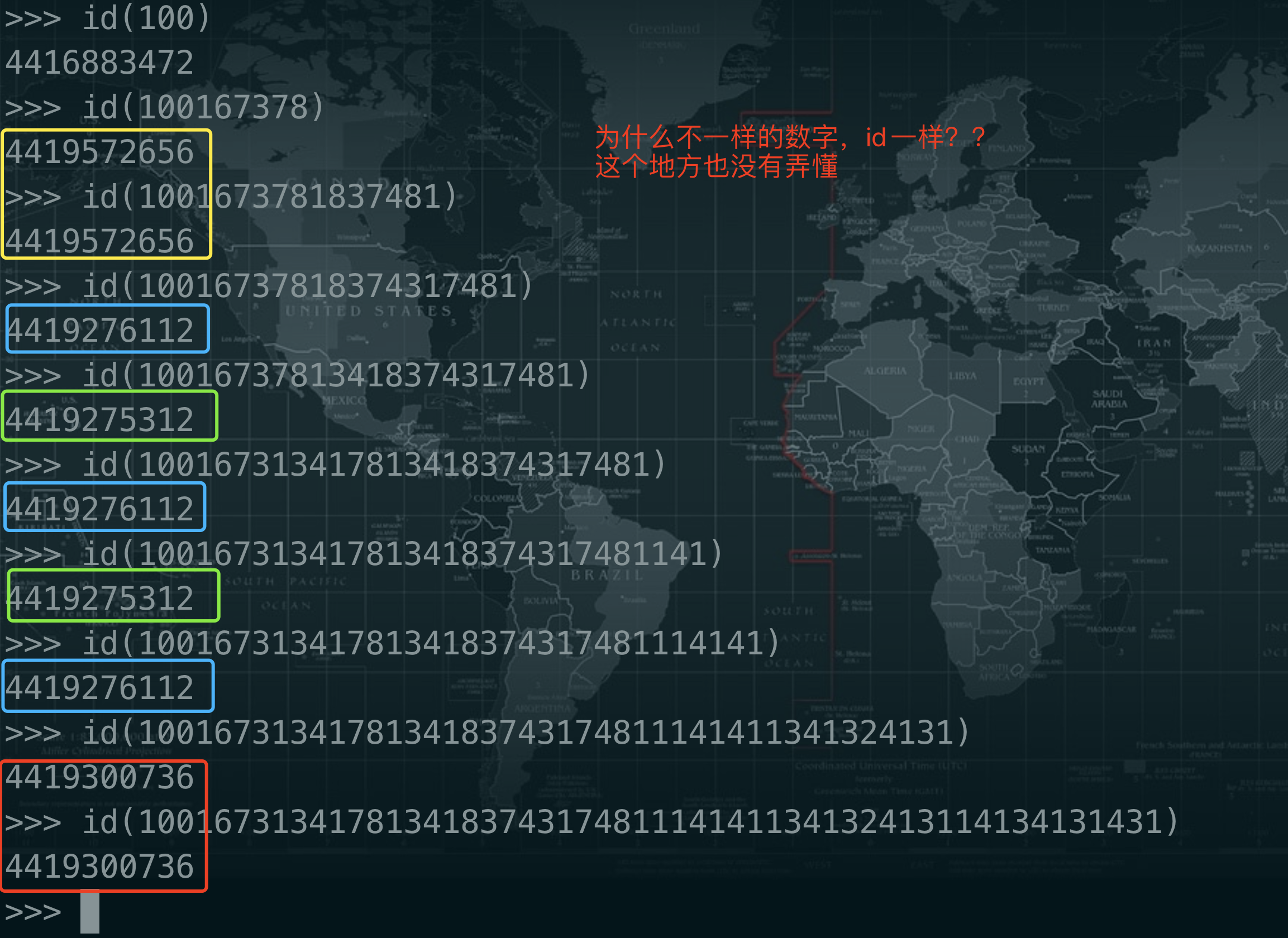
1.6.2、变量命名规则
"单下划线"开始的成员变量叫做保护变量,意思是只有类对象和子类对象自己能访问到这些变量。 "双下划线"开始的是私有成员,意思是只有类对象自己能访问,连子类对象也不能访问到这个数据。
1.6.3、数据类型
Numbers --数字 String --字符串 List --列表 Tuple --元组 Dictionary --字典 Set --集合
>>> number = 100 >>> type(number) <class 'int'>
>>> string = 'String' >>> type(string) <class 'str'>
>>> list_L = [1,2,3] >>> type(list_L) <class 'list'>
>>> tuple_T = (1,2,3) >>> type(tuple_T) <class 'tuple'>
>>> dictionary_D = {1:2,3:4} >>> type(dictionary_D) <class 'dict'>
>>> set_S = set("abc") >>> set_S {'a', 'c', 'b'} >>> type(set_S) <class 'set'> >>>
1.6.4、变量赋值
1.6.4.1、批量赋值
>>> a = b = c = 1 >>> a 1 >>> b 1 >>> c 1
>>> a,b,c = 4,5,6 >>> a 4 >>> b 5 >>> c 6 >>>
>>> a,b,c = (7,8,9) >>> a 7 >>> b 8 >>> c 9 >>>
>>> a,b,c,d,e = 1,'a',{1:2},[1,2,3],(1,2,3) >>> a 1 >>> b 'a' >>> c {1: 2} >>> d [1, 2, 3] >>> e (1, 2, 3) >>>
1.6.4.2、特殊的列表赋值(引用赋值) a指向的地址,赋值给b,a和b同时指向同一个地址,无论是谁对指向的地址做修改,两者都会变化
>>> a = [1,2,3] >>> b = a >>> b.append(4) >>> b [1, 2, 3, 4] >>> a [1, 2, 3, 4] >>>
1.6.4.3、python的内存中
0-256 在内存中只会有一个地址
其他数字,一个数字在内存中就会有一个地址
引用赋值:全部都是同一个地址,操作时不独立.把值的内容存在了一个内存地址给大家共用。
按值赋值:虽然值是一样的,但是内存中的地址是不一样的,操作的时候互相独立
# 引用赋值 >>> a = 1 >>> b = 1 >>> c = 1 >>> id(a) 4416880304 >>> id(b) 4416880304 >>> id(c) 4416880304 >>> id(1) 4416880304 >>> >>> >>> >>> >>> a = 256 >>> b = 256 >>> c = 256 >>> id(a) 4416888464 >>> id(b) 4416888464 >>> id(c) 4416888464 >>> id(256) 4416888464 >>> >>> >>>
>>> a = b = c = [1,2,3] >>> a [1, 2, 3] >>> b [1, 2, 3] >>> c [1, 2, 3] >>> id(a) 4419538312 >>> id(b) 4419538312 >>> id(c) 4419538312 >>> >>> >>> a.append(4) >>> b.append(5) >>> c.append(6) >>> a [1, 2, 3, 4, 5, 6] >>> b [1, 2, 3, 4, 5, 6] >>> c [1, 2, 3, 4, 5, 6] >>> id(a) 4419538312 >>> id(b) 4419538312 >>> id(c) 4419538312 >>>
# 按值赋值 >>> a = 1000 >>> b = 1000 >>> c = 1000 >>> id(a) 4419574576 >>> id(b) 4419574640 >>> id(c) 4419574480 >>> id(1000) 4419574448 >>> >>> >>> a = [1,2,3] >>> id(a) 4419538696 >>> b = [1,2,3] >>> id(b) 4419538184 >>> c = [1,2,3] >>> id(c) 4419538120 >>>
1.6.4.5判断是否按引用传递:
只要两个变量的id值不一样,就说明是按值赋值的 只要两个变量的id值一样,就说明是按引用赋值的 简单判断原则:a=b=c=1000,这样连等的赋值都是引用赋值的。否则就是 按值来赋值的。
2、python基础
四、课后练习
