

2020.05.21--预习课--第2节--基本类型
一、执行代码
1、交互模式:所见即所得,输入一行代码可以一行代码的执行结果
2、文件模式:把代码保存在文件中
绝对路径:例如: C:\Users\wuxiaohua>python e:\a.py hello world!
相对路径:例如在文件的目录下直接运行文件:先进入到e盘,在直接运行文件,文件前不需要加路径
C:\Users\wuxiaohua>e:
E:\>python a.py
hello world!
一般来说:调试代码,在交互模式 代码缩进比较多,建议使用文件模式。
3、书籍:《从一到无穷大》https://item.jd.com/12685024.html
二、字符类型
>>> a = 1 >>> b = 1.1 >>> c = 1+1j >>> d = '光荣之路' >>> e = '光荣之路'.encode('utf-8') >>>
>>> type(a) <class 'int'> >>> type(b) <class 'float'> >>> type(c) <class 'complex'> >>> type(d) <class 'str'> >>> type(e) <class 'bytes'> >>>
>>> f = b'a' >>> type(f) <class 'bytes'>
bytes类型,如果是 b'xxx' 的模式,字母和数字是没有问题的,如果中文,就会报错,如下 ,所以中文就只能用.encode()
>>> f = b'光荣之路' File "<stdin>", line 1 SyntaxError: bytes can only contain ASCII literal characters. >>>
1、str和bytes类型
str:
在python的编程中,可以直接使用,进行各种运算。不可以用在网络传输。
python的内置变量类型,仅在python里面有效
bytes:
用于网络传输中使用。网络传输公共数据的一种类型。
在python的环境中是不能进行字符串直接操作的,必须转换为str类型,才可以进行字符串的各种操作。
2、ASCII码
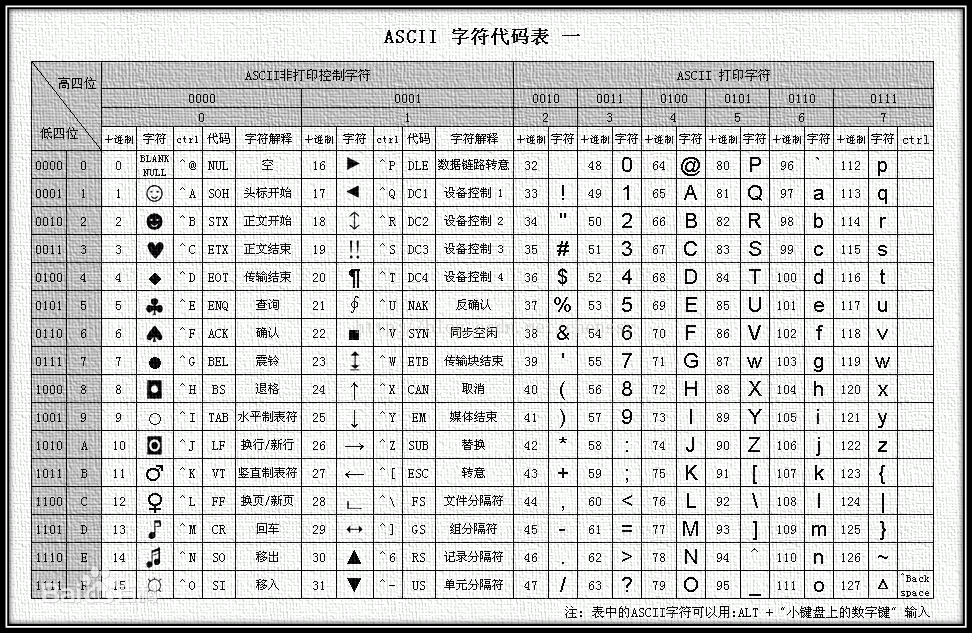
>>> ord('a') 97 >>> ord('A') 65 >>> ord('z') 122 >>> ord('Z') 90 >>>
>>> chr(65) 'A' >>> chr(90) 'Z' >>> chr(97) 'a' >>> chr(122) 'z' >>>
ascii:0-127 纯英文
unicode:和ascii 类似,它包含全世界目前官方认可的所有字符 (只能用于内存)
不是用于存储到磁盘的。
对应的是str类型。
简体:
GBK:数字的key---->汉字 (字符集的字数要比gb2312多)
GB2312: 数字的key---->汉字 (没有生僻字)
繁体:
Big5:台湾和香港
utf-8
utf-16
utf-32
以上几种都是用于存储到磁盘的。如果是计算内存中的字符,想存储到本地磁盘 encode("xxx编码")
3、其他类型
3.1、列表
>>> l = [] >>> l.append(a) >>> l [1] >>> l = [] >>> l.append(1) >>> l.append(2) >>> l.append('a') >>> l.append([1,2]) >>> l [1, 2, 'a', [1, 2]] >>> type(l) <class 'list'> >>>
列表:可以存储多个对象,里面存储的内容,均可以做增删改查
所有python的对象存储,均是用class(类)来进行实例化存储的。
3.1.1、列表的修改
>>> l [100, 2, 'a', [1, 2]] >>> l[0] = 'a' >>> l ['a', 2, 'a', [1, 2]] >>>
3.2、元组
3.2.1、单个元素的元组创建,赋值要加一个 ',' ,否则会被认为是单字符,()起不到元组标识作用
>>> t = (1) >>> t 1 >>> type(t) <class 'int'> >>> >>> >>> t_1 = (1,) >>> t_1 (1,) >>> type(t_1) <class 'tuple'> >>>
3.2.2、多个元素的元组创建,最后则不需要多加一个','
>>> t_2 = (1,2,3) >>> t_2 (1, 2, 3) >>> type(t_2) <class 'tuple'> >>>
3.2.3、即使没有元素的tuple赋值,不需要加 ','
>>> t = () >>> t () >>> type(t) <class 'tuple'> >>>
3.2.4、元组不可进行更改
>>> t = ('a','b','c') >>> t ('a', 'b', 'c') >>> t[0] = 'd' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment >>>
3.3、字典
3.3.1、字典是由 key : value 的模式组成,key 只能是不可变类型:整数、小数、字符串、元组
>>> d = {1:'a'}
>>> d
{1: 'a'}
>>> d = {[1]:'a'}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
>>>
3.4、集合--set
3.4.1、集合是可以用来排重的,没有顺序
>>> s_1 = set('abcabcadfabc') >>> s_1 {'f', 'a', 'b', 'd', 'c'} >>> s_2 = set('123123123') >>> s_2 {'3', '1', '2'} >>> s_3 = set([1,2,1,3,1,2,4,2,3,4]) >>> s_3 {1, 2, 3, 4} >>>
4、可变与不可变
4.1、可变类型:
list、dict、set
4.2、不可变类型
整数、小数、字符串、元组
5、编码
>>> s = "光荣之路" >>> type(s) <class 'str'> >>> s = s.encode('utf-8') >>> s b'\xe5\x85\x89\xe8\x8d\xa3\xe4\xb9\x8b\xe8\xb7\xaf' >>> s.decode('utf-8') '光荣之路' >>>
s="光荣之路" #类型:str--Unicode类型
s=s.encode("utf-8") #bytes类型,可以用于网络传输
其他机器收到了内容,怎么变成str类型?
s.decode("utf-8") #从bytes 变为了str类型。
encode:编码 str--->bytes
decode:解码 bytes----->str
用什么东西进行编码(encode)的就要用什么东西进行解码(decode),否则解码出错或者直接报错
你的程序使用文件模式执行,建议:不管里面有没有中文,都存储成utf-8编码格式。
你的程序如果使用gbk编码保存,则文件的第一行写上#encoding=gbk,就可以了。
引用:【链接】Windows记事本的ANSI、Unicode、UTF-8这三种编码模
6、模板字符串--占位符 --%s
>>> s = 'python' >>> print("老师正在讲%s课"%s) 老师正在讲python课 >>> print("老师正在讲%s课,%s"%(s,'晚上')) 老师正在讲python课,晚上
7、输入的内容都是【字符串】类型
>>> p = input(">>>:") >>>:123 >>> p '123' >>> p+1 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: must be str, not int >>> int(p)+1 124 >>>
三、总结
1 各种变量类型
2 输入和输出
3 模板字符串
4 encode和decode
5 外加各种字符集
6 ord和chr
7 可变类型和不可变类型
8 python文件保存的编码
