二分类之IMDB数据集
电影评论好坏分类(随笔)
加载数据集
from keras.datasets import imdb
(train_data, train_labels),(test_data,test_labels) = imdb.load_data(num_words=10000)
##此处10000是为了保留训练数据中前10000个最常出现的单词,并抛弃低频的单词,保证数据不会太大
解码评论,将整数转换成单词
## 将单词映射为以整数为索引的字典
word_index = imdb.get_word_index()
## 键值颠倒,将索引转为单词
reverse_word_index = dict([(value,key) for (key,value) in word_index.items()])
## 解码函数
def decode_review(text):
return ' '.join([reverse_word_index.get(i-3, '?') for i in text])
样例
decode_review(trian_data[0])
"? this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert ? is an amazing actor and now the same being director ? father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for ? and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also ? to the two little boy's that played the ? of norman and paul they were just brilliant children are often left out of the ? list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all"
显而易见train_data[0]是个好评
train_labels[0]
output: 1
不过这只是个开始,还要考虑每个评论长短不一的问题,因为神经网络的输入要求长度相同,所以在此需要处理一下数据
准备数据
先把列表转换成张量
- 填充列表
- 用one-hot编码,将整个列表转为0和1的向量,比如序列[3,5],在转为10000维的向量的时候,只有索引3,5下才是1,其他是0
以下是one-hot的代码,跟着书本上来的
import numpy as np
def vectorize_sequence(sequence,dimension=10000):
results = np.zeros((len(sequence),dimension)) ## 创建一个形状为(len(sequence),dimension)的零矩阵
for i,sq in enumerate(sequence):
results[i,sq] = 1.
return results
x_train = vectorize_sequence(train_data)
x_test = vectorize_sequence(test_data)
## 将labels向量化
y_train =np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
构建网络
先用Keras构建一个3层的神经网络
from keras import models
from keras import layers
model = models.Sequential()
## 构建输入层,设置16个输入单元,并设置10000维的输入张量,激活函数就relu吧
model.add(layers.Dense(16,activation='relu',input_shape=(10000,)))
## 隐藏层,设置16个隐藏单元,同样activation为relu
model.add(layers.Dense(16,activation='relu'))
## 输出层,仅包含一个单元,因为就是输出判断好评与否,因为要控制在0-1之间所以激活函数是sigmoid
model.add(layers.Dense(1,activation='sigmoid'))
验证方法
在此我们设置一个验证集,之前听说过训练集以及测试集,在这里验证集就是一个衡量的标准吧
x_val = x_train[:10000]
partial_x_train=x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
训练模型
from keras import losses
from keras import metrics
from keras import optimizers
## 编译模型,优化器选择rmsprop,损失函数选择二叉熵
model.compile(optimizer = 'rmsprop',
loss = 'binary_crossentropy',
metrics=['accuracy'])
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
## 验证数据传入validation_data来完成
validation_data=(x_val,y_val))
绘制训练损失和验证损失
import matplotlib.pyplot as plt
history_dict=history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1,len(loss_values)+1)
plt.plot(epochs,loss_values,'bo',label='Training loss')
plt.plot(epochs,val_loss_values,'b',label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
如下图所示:
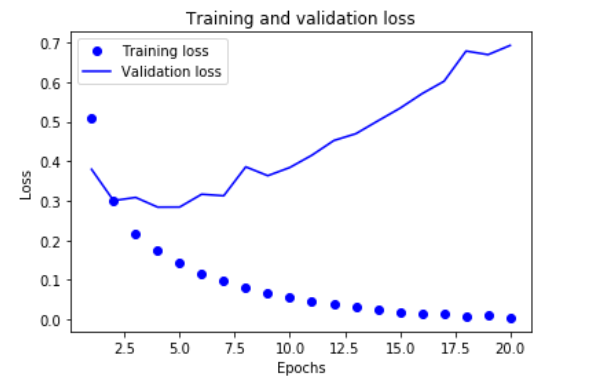
图中,圆点是Train loss,折线是Validation loss,可见周期越大,训练的损失越小,但验证损失却在大约第四轮之后变大了,这就是overfit了,因此我们这里只用4次的epoch就可以达到最优了
从头训练一个模型
这里我们让epochs=4
model = models.Sequential()
model.add(layers.Dense(16,activation='relu',input_shape=(10000,)))
model.add(layers.Dense(16,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss ='binary_crossentropy',
metrics=['accuracy'])
model.fit(x_train,y_train,epochs=4,batch_size=512)
results = model.evaluate(x_test,y_test)
得到的结果是:

这里的精度是88%左右并可以用以下代码查看评论是否正面
model.predict(x_test)
看《Pythons深度学习》之后,给自己做的一个笔记
其中也借鉴了下
https://blog.csdn.net/qq_20084101/article/details/82054749

 浙公网安备 33010602011771号
浙公网安备 33010602011771号