

MySQL选择合适的数据类型
一。char和varchar
char是固定长度的,查询速度比varchar速度快的多。char的缺点是浪费存储空间。
检索char列时,返回的结果会删除尾部空格,所以程序需要对为空格进行处理。
对于长度变化不大且对查询速度有较高要求的数据可以考虑使用char。
随着MySQL的不断升级,varchar的性能不断改进并提高。
存储引擎使用原则:
MyISAM:建议使用固定长度列代替可变长度列。
InnoDB:建议使用varchar类型
二。text和blob
在保存大文本时,通常选择text或者blob。
二者的差别是blob可以保存二进制数据,比如照片。
text和blob又包括text、mediumtext、longtext和blob、mediumblob、longblob,他们之间的区别是存储文本长度不同和存储字节不同。
应根据情况选择满足需求的最小存储类型。
1.blob和text执行大量删除操作时,产生数据“空洞”
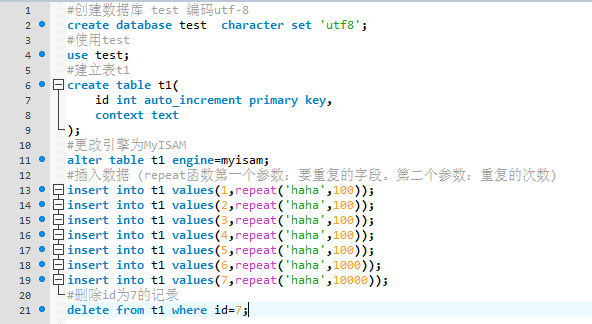
删除id为7记录前后数据库所占内存,没有发生变化。
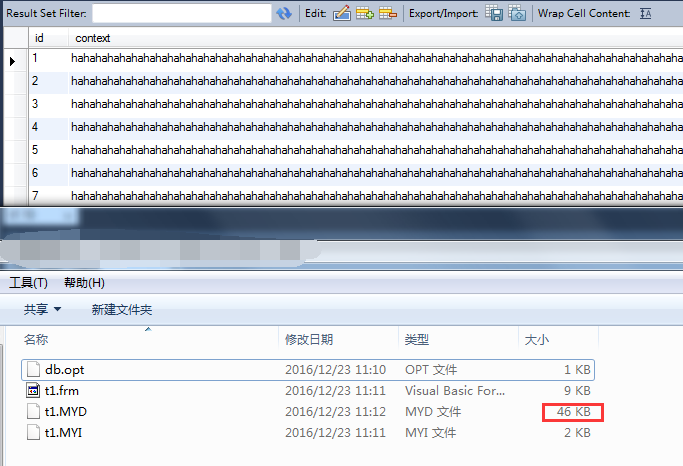

可以发现数据文件并没有因为数据删除而减少。
对表进行optimize(优化)操作:
optimize table t1;
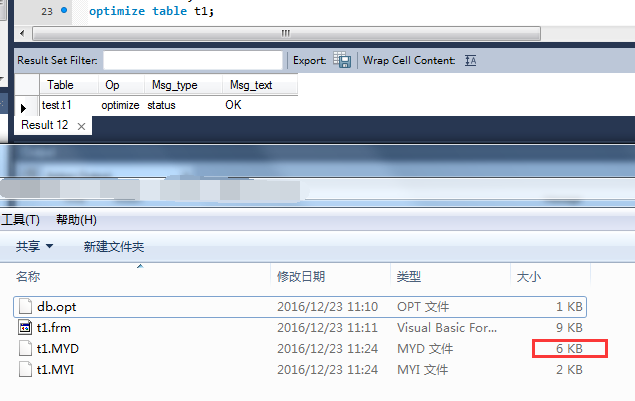
可以发现表数据文件大大缩小,“空洞”空间已经被回收。
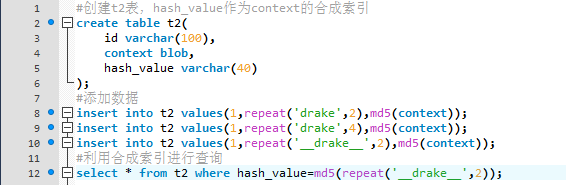
2.用合成(Synthetic)索引提高查询性能
根据大文本字段(text、blob)的内容建立一个散列值,并把这个值存储在单独的数据列中,然后通过散列值找数据行。
缺点:只能进行精确查询(<、>=范围操作符是没有用处的)
可以通过MySQL自带函数md5()、sha1()、crc32()生成散列值,也可以通过编程语言计算散列值。
注:如果散列算法生成的字符串带有尾部空格,不要把他们存储在char、varchar列中,他们会受到尾部空格去除的影响。
如果需要对blob或clob字段进行模糊查询,可以用前缀索引:
#前缀索引:对context字段的前100个字符创建索引 create index idx_blob on t2(context(100)); #查询方法 select * from t2 where context like 'drake%';
注:%不能放在最前面
合成索引只能用于精确匹配,在一定程度上减少了I/O,从而提高了查询效率。
3.在不必要的时候避免检索大型的blob或text值。
4.把blob或text列分离到单独的表中。
三、浮点数和定点数
1.浮点数存在误差问题。
2.对货币等对精度敏感的数据,应该用定点数表示或存储。
3.在编程中,如果用到浮点数,要特别注意误差问题,并尽量避免做浮点数比较。
4.要注意一些特殊值的处理。
四、日期类型的选择
1.根据实际需要选择能够满足应用的最小存储日期类型。
2.如果记录年月日时分秒,并且记录年份比较久远,最好使用datetime,不要使用timestamp。
3.如果记录的日期需要让不同时区的用户使用,最好使用timestamp,因为日期类型中只有它能够和实际时区相对应。

