python人脸识别项目之学习笔记(四):神经网络
你将会学到的知识点
- 神经网络是什么?
- 构建一个简单的神经网络
1. 什么是神经网络
单个的感知器就构成了一个简单的模型,但在现实世界中,实际的决策模型则要
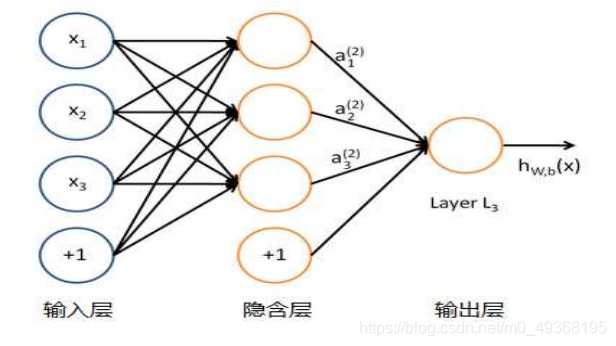
复杂得多,往往是由多个感知器组成的多层网络,如下图所示,这也是经典的神
经网络模型,由输入层、隐含层、输出层构成。
人工神经网络可以映射任意复杂的非线性关系,具有很强的鲁棒性、记忆能力、
自学习等能力,在分类、预测、模式识别等方面有着广泛的应用
一个简单的神经网络
一个例子:三好学生的应用
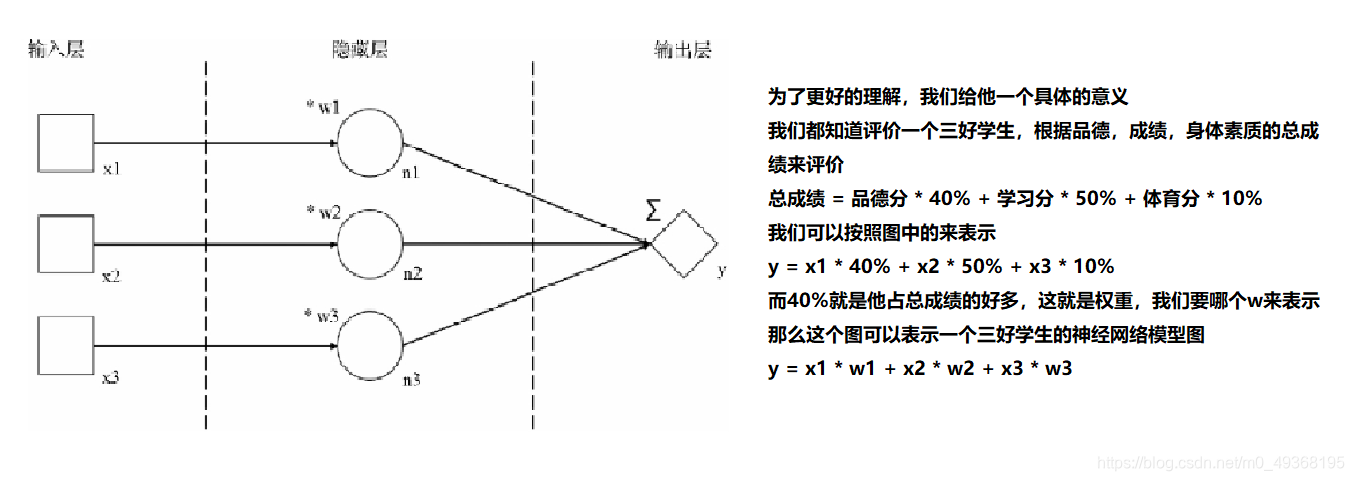
- 输入层: 描述输入数据的形态的;我们用方块来代表每一条输入数据的一个数,叫作输入节点;输入节点一般用x来命名
- 隐藏层:描述我们设计的神经网络模型结构中最重要的部分;隐藏层可能有多个;每一层中都会有1个或多个神经元,我们用圆圈来表示,叫作神经元节点或隐藏节点,有时也直接简称为节点;每一个节点都接收上一层传来的数据并进行一定的运算后向下一层输出数据,符合神经元的特性,神经元节点上的这些运算称为“操作”(简称op)
- 输出层:一般是神经网络模型的最后一层,会包含1个或多个以菱形表示的输出节点;输出节点代表着整个神经网络计算的最后结果;
有两位孩子的家长,知道了自己孩子的3项分数及总分,但是学校并没有告诉家长们计算出总分的规则。家长们猜测出计算总分的方法肯定是把3项分数乘以不同的权重后相加来获得,唯一不知道的就是这几个权重值到底是多少。现在家长们就想用人工智能中神经网络的方法来大致推算出这3个权重分别是多少。
代码实现
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
x1 = tf.placeholder(dtype=tf.float32)
x2 = tf.placeholder(dtype=tf.float32)
x3 = tf.placeholder(dtype=tf.float32)
# 传入针对每一组输入数据我们期待的对应计算结果
yTrain = tf.placeholder(dtype=tf.float32)
w1 = tf.Variable(0.1, dtype=tf.float32)
w2 = tf.Variable(0.1, dtype=tf.float32)
w3 = tf.Variable(0.1, dtype=tf.float32)
n1 = x1*w1
n2 = x2*w2
n3 = x3*w3
y = n1 + n2 + n3
# loss
loss = tf.abs(y - yTrain)
# 定义了一个优化器变量optimizer
# 调整神经网络可变参数的对象
# 其中的参数0.001是这个优化器的学习率(learn rate
# 学习率决定了优化器每次调整参数的幅度大小,先赋一个常用的数值0.001
# 是要求优化器按照把loss最小化(minimize)的原则来调整可变参数
optimizer = tf.train.RMSPropOptimizer(0.001)
train = optimizer.minimize(loss)
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
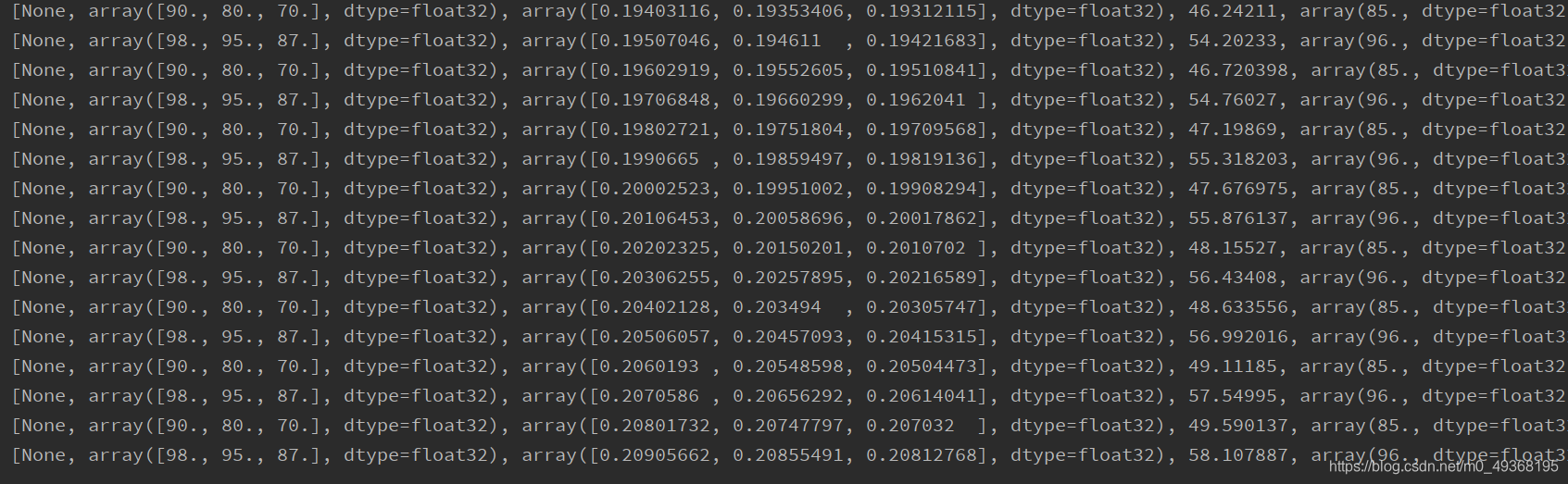
for i in range(100):
result = sess.run([train, x1, x2, x3, w1, w2, w3, y, yTrain, loss], feed_dict={x1: 90, x2: 80, x3: 70, yTrain: 85})
print(result)
result = sess.run([train, x1, x2, x3, w1, w2, w3, y, yTrain, loss], feed_dict={x1: 90, x2: 80, x3: 70, yTrain: 96})
print(result)
sess.close()
执行结果
简化神经网络
我们将刚刚的数字变成一个变量进行输入、
第一个学生的3项分数可以用[90, 80, 70]这样一个数组就表示出来了(这个数组是有顺序的)
第二个学生的3项分数可以用[80, 70, 60]这样一个数组就表示出来了(这个数组是有顺序的)
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
x = tf.placeholder(shape=[3], dtype=tf.float32)
# 传入针对每一组输入数据我们期待的对应计算结果
yTrain = tf.placeholder(shape=[], dtype=tf.float32)
# tf.zeros([3])的返回值将是一个数组[0, 0, 0]
w = tf.Variable(tf.zeros([3]), dtype=tf.float32)
n = x*w
# tf.reduce_sum函数的作用是把作为它的参数的向量(以后还可能会是矩阵)中的所有维度的值相加求和,与原来y=n1+n2+n3的含义是相同的。
y = tf.reduce_sum(n)
# loss
loss = tf.abs(y - yTrain)
# 定义了一个优化器变量optimizer
# 调整神经网络可变参数的对象
# 其中的参数0.001是这个优化器的学习率(learn rate
# 学习率决定了优化器每次调整参数的幅度大小,先赋一个常用的数值0.001
# 是要求优化器按照把loss最小化(minimize)的原则来调整可变参数
optimizer = tf.train.RMSPropOptimizer(0.001)
train = optimizer.minimize(loss)
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
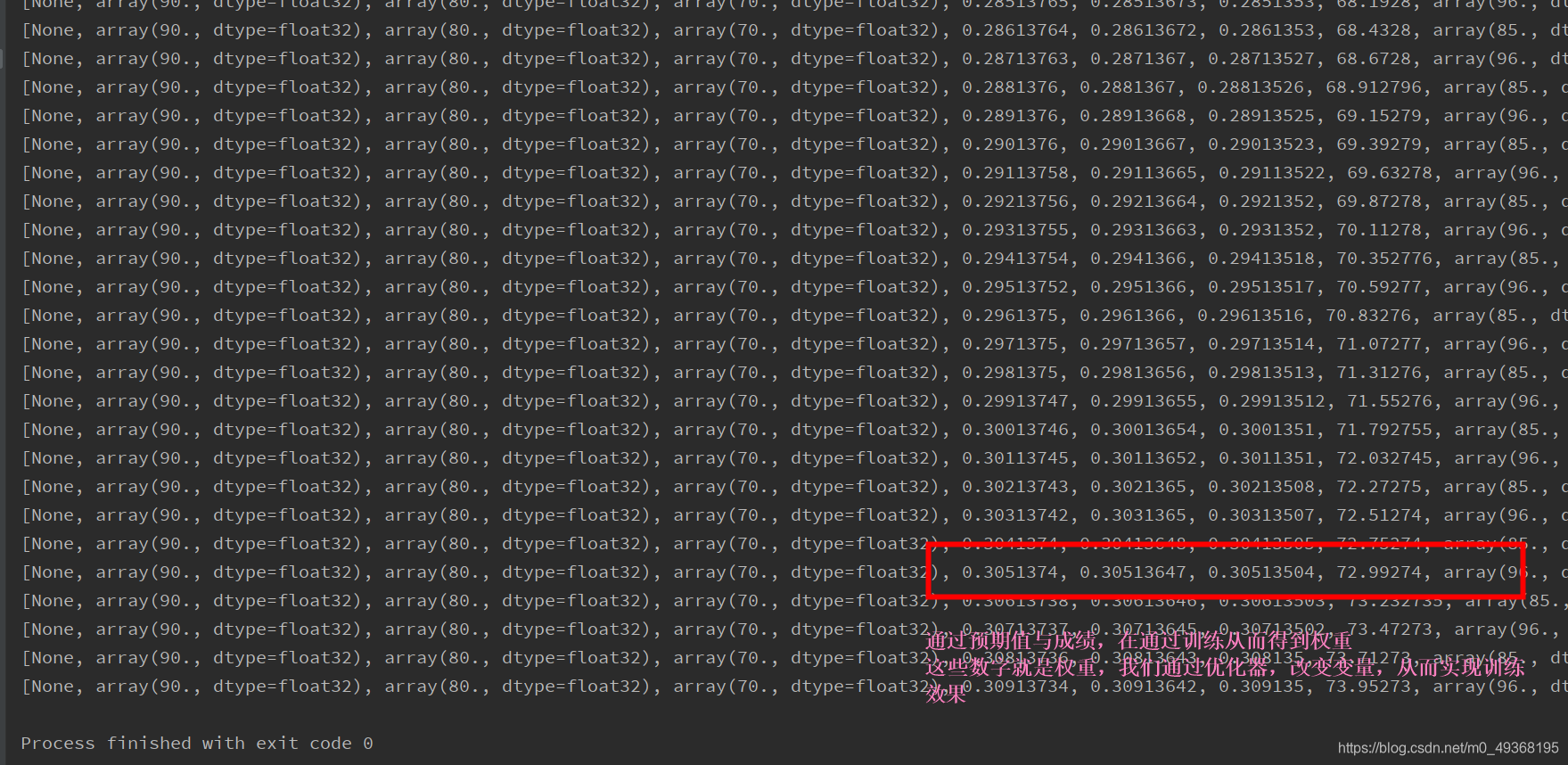
for i in range(100):
result = sess.run([train, x, w, y, yTrain, loss], feed_dict={x:[90, 80, 70], yTrain: 85})
print(result)
result = sess.run([train, x,w, y, yTrain, loss], feed_dict={x:[98, 95, 87], yTrain: 96})
print(result)
sess.close()
执行结果