java stream 原理
java stream 原理
需求
从"Apple" "Bug" "ABC" "Dog"中选出以A开头的名字,然后从中选出最长的一个,并输出其长度
1. 最直白的实现
缺点
- 迭代次数过多
- 频繁产生中间结果,性能无法接受
2. 平常写法
int longest = 0;
for(String str : strings){
if(str.startsWith("A")){// 1. filter(), 保留以张开头的字符串
int len = str.length();// 2. mapToInt(), 转换成长度
longest = Math.max(len, longest);// 3. max(), 保留最长的长度
}
}
System.out.println(longest);
缺点
- 具体业务与算法混在一起,不利于代码复用
- 耦合性太强,代码不清晰
3. 责任链模式解耦
public interface Chain {
void proceed(Object object);
}
public class ForChain implements Chain {
private final Chain chain;
public ForChain(Chain chain){
this.chain = chain;
}
@Override
public void proceed(Object object) {
List<String> list = (List<String>) object;
for(String a : list){
if(a.startsWith("A"))
chain.proceed(a);
}
}
}
public class LengthChain implements Chain {
private final Chain chain;
public LengthChain(Chain chain){
this.chain = chain;
}
@Override
public void proceed(Object object) {
String string = (String)object;
chain.proceed(string.length());
}
}
public class ResultChain implements Chain {
private Integer result = 0;
@Override
public void proceed(Object object) {
Integer integer = (Integer) object;
result = Math.max(integer,result);
}
public Integer getResult() {
return result;
}
}
public class Client {
public static void main(String[] args) {
ResultChain resultChain = new ResultChain();
LengthChain lengthChain = new LengthChain(resultChain);
ForChain forChain = new ForChain(lengthChain);
List<String> list = Arrays.asList("Apple","Bug","ABC","Dog");
forChain.proceed(list);
System.out.println("result is "+ resultChain.getResult());
}
}
4. java stream 实现
OptionalInt max = Stream.of("Apple", "Bug", "ABC", "Dog").
filter(e -> e.startsWith("A")).
mapToInt(e -> e.length()).
max();
System.out.println("result is "+ max.getAsInt());
优点
- 开发者是需要关注具体的业务,顶层算法都封装在框架中
- 代码结构清晰,代码量少,减少出错的机会
5. Stream 的原理
5.1 stream与集合比较
尽管stream与集合框架在表现上非常相似,二者都是对数据进行处理,但事实上二者完全不同。集合是一种数据结构,主要关注在内存中组织数据,会在一段时间在内存中持续的存在,而流的主要关注在计算,不为数据提供任何存储空间,只会通过管道提供计算结果。
5.2 stream 操作分类
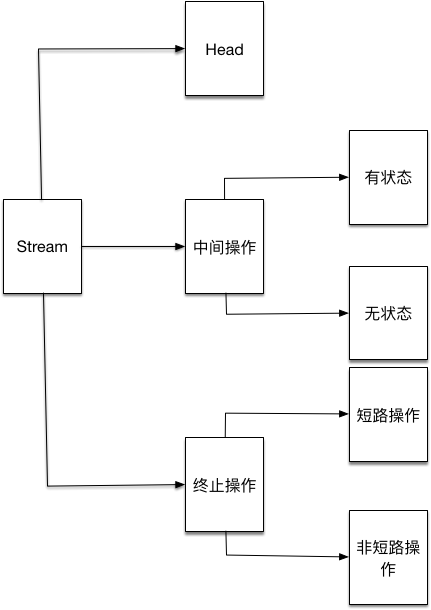
中间操作:返回一个新的stream
- 有状态:必须等上一步操作完,才能执行下一步操作
- 无状态:该操作不受上一步操作的影响
终止操作:返回结果
- 短路:找到即返回
- 费短路:遍历所有元素
以上操作决定了Stream一定是先构建完毕再执行的特点,也就是延迟执行,当需要结果(终端操作时)开始执行流水线。
5.3 stream 结构示意图
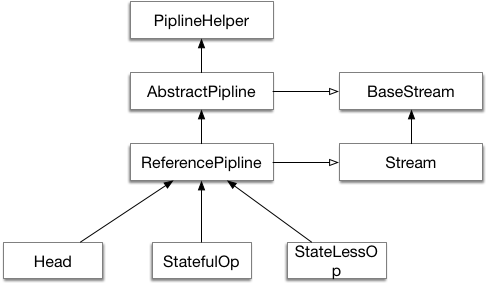
5.4 操作如何记录
- Head记录起始操作
- StateLessOp记录中间操作
- StatefulOp记录有状态的中间操作
这三个操作,在实例化的时候回指向前一个操作,和后一个操作,形成双向链表,每一步操作都能得知上一步和下一步操作。
对于Head:
AbstractPipeline(Spliterator<?> source,
int sourceFlags, boolean parallel) {
this.previousStage = null;
this.sourceSpliterator = source;
this.sourceStage = this;
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
// The following is an optimization of:
// StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE);
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
this.depth = 0;
this.parallel = parallel;
}
对于其他操作:
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
previousStage.nextStage = this; // 构造双向链表
this.previousStage = previousStage;
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
this.sourceStage = previousStage.sourceStage;
if (opIsStateful())
sourceStage.sourceAnyStateful = true;
this.depth = previousStage.depth + 1;
}
例子:
data.stream()
.filter(x -> x.length() == 2)
.map(x -> x.replace(“三”,”五”))
.sorted()
.filter(x -> x.contains(“五”))
.forEach(System.out::println);
Stage

5.5 操作如何叠加
从终止操作依次构造Sink,如此Sink链构造完成
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
// 依次构造sink
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
sink

- 依次调用sink的begin方法,通知sink链数据已准备好
- 依次调用sink的accept方法,处理数据
- 依次调用sink的end方法,通知数据处理完毕
@Override
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}

5.6 如何收集结果
对于forEach是不需要收集结果的,对于collect结果保存在最后一个sink中,这样的操作都会提供一个get方法取出数据。终止操作都会实现Supplier的get方法
@Override
public <P_IN> R evaluateSequential(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator) {
return helper.wrapAndCopyInto(makeSink(), spliterator).get();
}
public interface Supplier<T> {
/**
* Gets a result.
*
* @return a result
*/
T get();
}
interface TerminalSink<T, R> extends Sink<T>, Supplier<R> { }
没有智能的代码,源码面前了无秘密

 浙公网安备 33010602011771号
浙公网安备 33010602011771号