


提取不重复的整数
美妙的问题描述:
输入一个int型整数,按照从右向左的阅读顺序,返回一个不含重复数字的新的整数。
for example: If you input 9876673,the coumputer gives 37689.
我想到啦两种方法,一种是从字符串的角度,一种是从整数的角度!
从整数的角度:
我刚开始时的做法:
1 #include<bits/stdc++.h> 2 using namespace std; 3 int main() 4 { 5 int n; 6 int a[100]={0}; 7 while(cin>>n) 8 { 9 int count=0; 10 while(n) 11 { 12 a[n%10]=1; 13 count++; 14 n/=10; 15 } 16 for(int i=0;i<100;i++) 17 { 18 if(a[i]==1) cout<<i; 19 } 20 cout<<endl; 21 } 22 return 0; 23 }// 结果是有所错误滴!
该如何优化嘞:
#include<bits/stdc++.h>
using namespace std;
int main()
{
int n;
while(cin>>n)
{
int a[10]={0};
while(n)
{
a[n%10]++:
if(a[n%10]==1) cout<<n%10; //颇有些逆的思想!由值寻下标!
n/=10;
}
cout<<endl;
}
return 0;
}
关于整数角度的另一种优化方法:
1 链接:https://www.nowcoder.com/questionTerminal/253986e66d114d378ae8de2e6c4577c1 2 来源:牛客网 3 4 #include<iostream> 5 using namespace std; 6 int main() 7 { 8 int n; 9 int a[10]={0}; 10 int num=0; 11 cin>>n ; 12 while(n) 13 { 14 if(a[n%10]==0) 15 { 16 a[n%10]++;//这一步是更新,遇到下次相同的数会跳过 17 num=num*10+n%10; 18 } 19 n/=10; 20 } 21 22 cout<<num<<endl; 23 24 return 0; 25 }
关于从字符串的角度:
我一开始时的思绪停滞于此:
#include<bits/stdc++.h>
using namespace std;
int main()
{
string s;
while(cin>>s)
{
int len=s.size();
for(int i=len-1;i>=0;i--)
{
for(int j=len-1;j<i,j--)
{
if(s)
}
}
}
}
发现一些美丽的做法:
#include<bits/stdc++.h>
using namespace std;
int main()
{
string s;
int len,i;
int a[10]={0};
cin.getline(s);
len=s.size();
for(i=len-1;i>=0;i--)
{
if(a[s[i]-'0']==0) //
{
cout<<s[i];
a[s[i]-'0']++;
}
}
return 0;
}
关于数字字符的一些补充:
运用字符串库函数中的find()函数:
1 #include<bits/stdc++.h> 2 using namespace std; 3 int main() 4 { 5 string s; 6 string s1=" "; //抬头有双字符串在天空飞翔! 7 cin>>s; 8 for(int i=s.length();i>=0;i--) 9 { 10 if(s1.find(s[i])==string::npos) //此为何意!且待细品! 11 s1+=s[i]; 12 } 13 cout<<s1<<endl; 14 return 0; 15 }
运用这种模板这种思路这种方法可以迅速地解决下面这个问题:
字符个数统计:
编写一个函数,计算字符串中含有的不同字符的个数。字符在ACSII码范围内(0~127)。不在范围内的不作统计。
#include<bits/stdc++.h>
using namespace std;
int main()
{
string s,s1=" ";
int count=0;
while(cin>>s)
{
for(int i=s.size()-1;i>=0;i--)
{
if(s1.find(s[i])==string::npos)
{
s1+=s[i];
count++;
}
}
cout<<count<<endl;
}
return 0;
}
Also: 更加恣意自由之思考做法!
#include<bits/stdc++.h>
using namespace std;
int main()
{
string s;
while(cin>>s)
{
int k=0;
for(int i=0;i<=127;i++)
{
if(s.find(i)!=-1) k++;
cout<<k<<endl;
}
}
return 0;
}
当然运用集合(元素互异性)这一种数据结构可以更好的从一种角度解决问题来嘞!
1 #include<bits/stdc++.h> 2 using namespace std; 3 int main() 4 { 5 char c; 6 set<char> s; 7 while(cin>>s) 8 { 9 if(c>=0&&c<=127) 10 s.insert(c); 11 } 12 cout<<s.size()<<endl; 13 }
使用map来嘞:
#include<bits/stdc++.h>
using namespace std;
int main()
{
map<char,int> mp;
char c;
while(cin>>c)
{
mp[c]++;
}
cout<<mp.size()<<endl; //任他云卷云舒,我自闲庭阔步之感!
return 0;
}
有个关于int的小话题叙述于此:
int型的数到底最大值是多少? int占32位的时候,最大可以赋值为:2147483647。也就是0x7fffffff。也就是十位数字!
详细讨论可见该篇blog.
2019/7/19 重新翻阅这篇博客,再来补充一下关于find_last_of()的一些字符串相关的查找函数的叙述。
Functions:
1.find_first_of和find_last_of函数进行简单的匹配
例如:在字符串中查找单个字符c。
#include<bits/stdc++.h> using namespace std; int main() { string s; cin>>s; int pos1=s.find_first_of('a',0); //下标是从0开始的。 int pos2=s.find_first_of('a'); int pos3=s.find_last_of('a'); cout<<pos1<<" "<<pos2<<endl; return 0; }
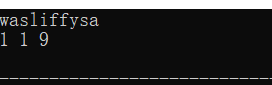
对啦:size_t是一种数据相关的无符号类型,它被设计得足够大以便能够内存中任意对象的大小。在C++中,设计 size_t 就是为了适应多个平台的 。size_t的引入增强了程序在不同平台上的可移植性。
在需要通过数组下标来访问数组时,通常建议将下标定义size_t类型,因为一般来说在进行下标访问时,下标都是正的。当然,也不是所有的下标访问操作下标都是正的。
精辟的论述:
关于指针的大小,网上描述基本上是千篇一律,认为指针是存放地址的,如果是32位机器就是4字节的,如果是64位机器就是8字节的,根据机器字而决定的。
这里的32位机器和64位机器指的是什么呢?我觉的CPU的架构决定了机器的类型,如果CPU是x86架构,那么就是32位的CPU,当然并非所有的x86架构的CPU都是32位的,比如intel的8086和8088就是16位的CPU。
如果CPU是x86-64的架构,那么就是64位的CPU。CPU的位数是由其字长决定,字长表示CPU在同一时间中能够处理二进制数的位数叫字长。字长是由CPU中寄存器的位数决定的,并非由数据总线的宽度决定的,只是数据总线的宽度一般与CPU的位数相一致。
系统的位数是依赖于CPU的位数,即32位的CPU不能装64位的系统,但是现在(2015年)的CPU基本上都是x86-64的CPU,都支持64位的系统。但是正如上面的讨论,如果编译生成的程序不是64位的,那么指针的大小依然是4个字节。
所以这个语句一点都不冲突啦:
size_t found = str.find_first_of(';'); //找到第一个';'的位置 使用size_t可能会提高代码的可移植性、有效性或者可读性,或许同时提高这三者。
参考blog:https://blog.csdn.net/Richard__Ting/article/details/79433814
Further on the exploration of strings:
npos是一个常数,表示size_t的最大值(Maximum value for size_t)。许多容器都提供这个东西,用来表示不存在的位置,类型一般是std::container_type::size_type。
find函数在找不到指定值得情况下会返回string::npos。
举例如下(计算字符串中含有的不同字符的个数):
#include<bits/stdc++.h>
using namespace std;
int main()
{
string s;
getline(cin,s);
int count=0;
for(int i=0;i<=127;i++)
{
if(s.find(i)!=string::npos) count++;
}
cout<<count<<endl;
}

