

Hadoop初识
Hadoop的思想之源
- HADOOP最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
数据存储和计算难题
- 大量的网页怎么存储
- 搜索算法(倒排索引的计算)
关键技术和思想(Google 三大理论)
- GFS:分布式文件系统,可用于处理海量网页的存储
- Map-Reduce:分布式计算框架,可用于处理海量网页的索引计算问题
- Bigtable:提供了一种可以在超大数据集中进行实时CRUD操作的功能
Hadoop创始人介绍
- Hadoop作者Doug cutting,就职Yahoo期间开发了Hadoop项目(之前已经开始实施),目前在Cloudera 公司从事架构工作

Hadoop简介
- 名字来源于Doug Cutting儿子的玩具大象。
- 2003-2004年,Google公开了部分GFS和Mapreduce思想的细节,以此为基础Doug Cutting等人用了2年业余时间实现了DFS和Mapreduce机制,一个微缩版:Nutch
- Hadoop 于 2005 年秋天作为 Lucene的子项目 Nutch的一部分正式引入Apache基金会。2006 年 3 月份,Map-Reduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目
- Hadoop官网:http://hadoop.apache.org
- 版本:1.x,2.x,3.x
Hadoop核心组件
- Hadoop Common
- 支持其他Hadoop模块的常用工具
- 分布式存储系统HDFS (Hadoop Distributed File System )POSIX
- 分布式存储系统
- 提供了 高可靠性、高扩展性和高吞吐率的数据存储服务
- 分布式计算框架MapReduce
- 分布式计算框架(计算向数据移动)
- 具有 易于编程、高容错性和高扩展性等优点。
- 分布式资源管理框架YARN(Yet Another Resource Management)
- 负责集群资源的管理和调度
Hadoop生态圈图
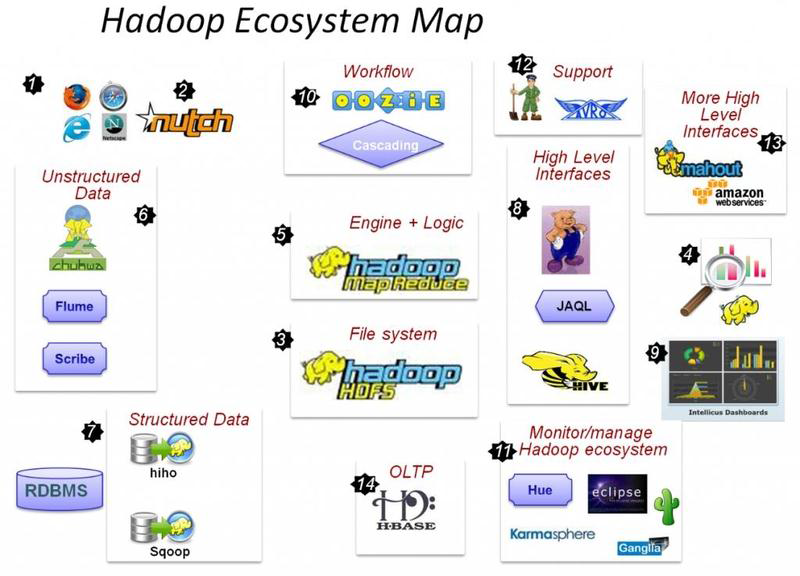
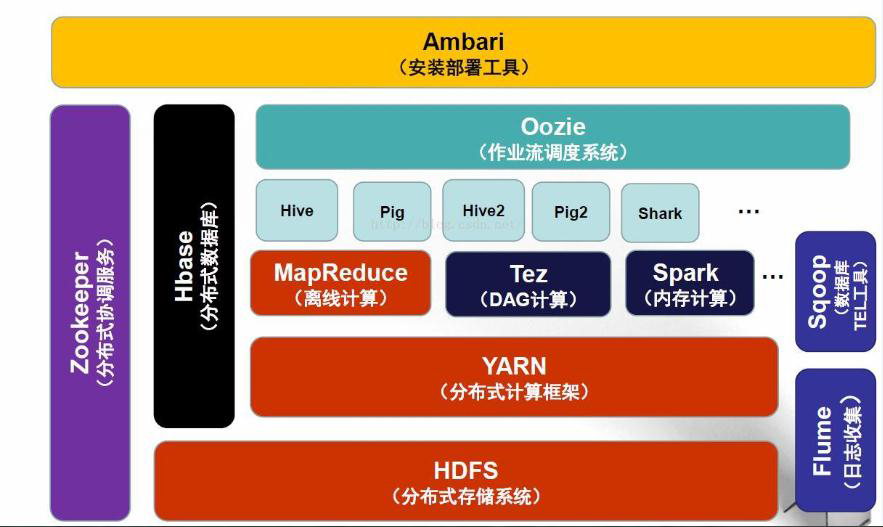
Hadoop生态圈组件
- HDFS:Hadoop的分布式文件存储系统。
- MapReduce:Hadoop的分布式程序运算框架,也可以叫做一种编程模型。
- Hive:基于Hadoop的类SQL数据仓库工具
- Hbase:基于Hadoop的列式分布式NoSQL数据库
- ZooKeeper:分布式协调服务组件
- Mahout:基于MapReduce/Flink/Spark等分布式运算框架的机器学习算法库
- Oozie/Azkaban:工作流调度引擎
- Sqoop:数据迁入迁出工具
- Flume:日志采集工具

