

python 基本数据类型
Python Number(数字)
数字数据类型用于存储数值,它们是不可变数据类型。这意味着,更改数字数据类型的值会导致新分配对象。当为数字数据类型分配值时,Python将创建数字对象
Python 数字类型
- int(有符号整数) - 它们通常被称为整数或整数。它们是没有小数点的正或负整数。
- float(浮点实数值) - 也称为浮点数,它们表示实数,并用小数点写整数和小数部分。 浮点数也可以是科学符号,E或e表示10的幂 -
- complex(复数) - 复数是以a + bJ的形式,其中a和b是浮点,J(或j)表示-1的平方根(虚数)。数字的实部是a,虚部是b。复数在Python编程中并没有太多用处
Python 数字类型转换
Python可将包含混合类型的表达式内部的数字转换成用于评估求值的常用类型。 有时需要从一个类型到另一个类型执行明确数字转换,以满足运算符或函数参数的要求。
- int(x)将x转换为纯整数。
- float(x)将x转换为浮点数。
- complex(x, y)将x和y转换为具有实部为x和虚部为y的复数。x和y是数字表达式


print(type(int(1.6))) print(type(int('6'))) print(type(float(1))) print(type(float('1.6'))) --------------------------------------------- <class 'int'> <class 'int'> <class 'float'> <class 'float'>
Python 数字进制转换
|
↓ |
2进制 |
8进制 |
10进制 |
16进制 |
|
2进制 |
- |
bin(int(x, 8)) |
bin(int(x, 10)) |
bin(int(x, 16)) |
|
8进制 |
oct(int(x, 2)) |
- |
oct(int(x, 10)) |
oct(int(x, 16)) |
|
10进制 |
int(x, 2) |
int(x, 8) |
- |
int(x, 16) |
|
16进制 |
hex(int(x, 2)) |
hex(int(x, 8)) |
hex(int(x, 10)) |
- |
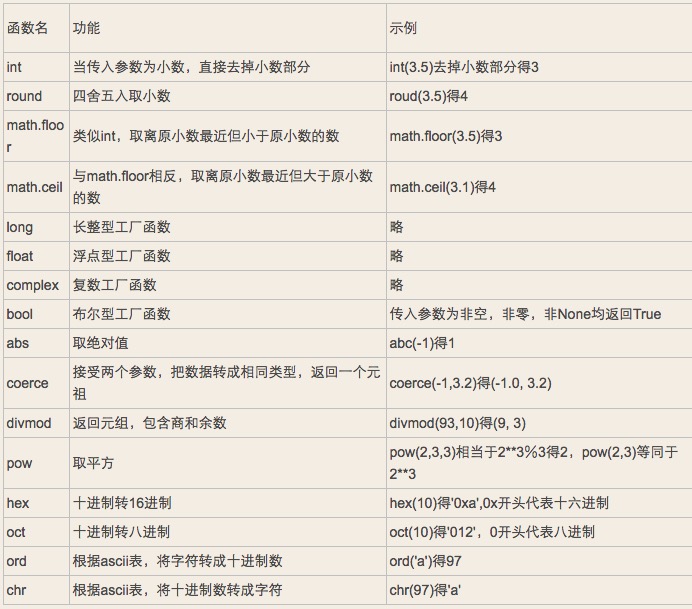
数字内建函数
Python 字符串
字符串是 Python 中最常用的数据类型。我们可以使用引号( ' 或 " )来创建字符串。
Ps:python中字符串是不可变对象,所以所有修改和生成字符串的操作的实现方法都是另一个内存片段中新生成一个字符串对象
大小写转换(lower、upper)
>>> print('ab XY'.lower())
ab xy
>>> print('ab XY'.upper())
AB X
title、capitalize
ps:前者返回S字符串中所有单词首字母大写且其他字母小写的格式,后者返回首字母大写、其他字母全部小写的新字符串
>>> print('ab XY'.title())
Ab Xy
>>> print('abc DE'.capitalize())
Abc de
swapcase
ps:swapcase()对S中的所有字符串做大小写转换(大写-->小写,小写-->大写)
>>> print('abc XYZ'.swapcase())
ABC xyz
isalpha,isdecimal,isdigit,isnumeric,isalnum
ps:测试字符串S是否是数字、字母、字母或数字。对于非Unicode字符串,前3个方法是等价的
>>> print('34'.isdigit())
True
>>> print('abc'.isalpha())
True
>>> print('a34'.isalnum())
True
islower,isupper,istitle
ps:判断是否小写、大写、首字母大写。要求S中至少要包含一个字符串字符,否则直接返回False。例如不能是纯数字。istitle()判断时会对每个单词的首字母边界判断
>>> print('a34'.islower())
True
>>> print('AB'.isupper())
True
>>> print('Aa'.isupper())
False
>>> print('Aa Bc'.istitle())
True
>>> print('Aa_Bc'.istitle())
True
>>> print('Aa bc'.istitle())
False
>>> print('Aa_bc'.istitle())
False
# 下面的返回False,因为非首字母C不是小写
>>> print('Aa BC'.istitle())
False
isspace,isprintable,isidentifier
ps:分别判断字符串是否是空白(空格、制表符、换行符等)字符、是否是可打印字符(例如制表符、换行符就不是可打印字符,但空格是)、是否满足标识符定义规则
>>> print(' '.isspace())
True
>>> print(' \t'.isspace())
True
>>> print('\n'.isspace())
True
>>> print(''.isspace())
False
>>> print('Aa BC'.isspace())
False
isprintable
ps:判断是否是可打印字符
>>> print('\n'.isprintable())
False
>>> print('\t'.isprintable())
False
>>> print('acd'.isprintable())
True
>>> print(' '.isprintable())
True
>>> print(''.isprintable())
True
isidentifier
ps:判断是否满足标识符定义规则。标识符定义规则为:只能是字母或下划线开头、不能包含除数字、字母和下划线以外的任意字符
>>> print('abc'.isidentifier())
True
>>> print('2abc'.isidentifier())
False
>>> print('abc2'.isidentifier())
True
>>> print('_abc2'.isidentifier())
True
>>> print('_abc_2'.isidentifier())
True
>>> print('_Abc_2'.isidentifier())
True
>>> print('Abc_2'.isidentifier())
True
center
ps:S.center(width[, fillchar])将字符串居中,左右两边使用fillchar进行填充,使得整个字符串的长度为width。fillchar默认为空格。如果width小于字符串的长度,则无法填充直接返回字符串本身(不会创建新字符串对象)
>>> print('ab'.center(4,'_'))
_ab_
>>> print('ab'.center(5,'_'))
__ab_
*使用默认的空格填充并居中字符串
>>> print('ab'.center(4))
ab
>>> print(len('ab'.center(4)))
4
*width小于字符串长度
>>> print('abcde'.center(3))
abcde
ljust和rjust
ps:ljust()使用fillchar填充在字符串S的右边,使得整体长度为width。rjust()则是填充在左边。如果不指定fillchar,则默认使用空格填充,如果width小于或等于字符串S的长度,则无法填充,直接返回字符串S(不会创建新字符串对象)
>>> print('xyz'.ljust(5,'_'))
xyz__
>>> print('xyz'.rjust(5,'_'))
__xyz
zfill
ps:用0填充在字符串S的左边使其长度为width。如果S前右正负号+/-,则0填充在这两个符号的后面,且符号也算入长度。如果width小于或等于S的长度,则无法填充,直接返回S本身(不会创建新字符串对象)
>>> print('abc'.zfill(5)) 00abc >>> print('-abc'.zfill(5)) -0abc >>> print('+abc'.zfill(5)) +0abc >>> print('42'.zfill(5)) 00042 >>> print('-42'.zfill(5)) -0042 >>> print('+42'.zfill(5)) +0042
count
ps:
S.count(sub[, start[, end]])返回字符串S中子串sub出现的次数,可以指定从哪里开始计算(start)以及计算到哪里结束(end),索引从0开始计算,不包括end边界。
>>> print('xyabxyxy'.count('xy')) 3 # 次数2,因为从index=1算起,即从'y'开始查找,查找的范围为'yabxyxy' >>> print('xyabxyxy'.count('xy',1)) 2 # 次数1,因为不包括end,所以查找的范围为'yabxyx' >>> print('xyabxyxy'.count('xy',1,7)) 1 # 次数2,因为查找的范围为'yabxyxy' >>> print('xyabxyxy'.count('xy',1,8)) 2
endswith和startswith
ps:
S.endswith(suffix[, start[, end]])与S.startswith(prefix[, start[, end]]),endswith()检查字符串S是否已suffix结尾,返回布尔值的True和False。suffix可以是一个元组(tuple)。可以指定起始start和结尾end的搜索边界。同理startswith()用来判断字符串S是否是以prefix开头。
*suffix是普通的字符串时 >>> print('abcxyz'.endswith('xyz')) True # False,因为搜索范围为'yz' >>> print('abcxyz'.endswith('xyz',4)) False # False,因为搜索范围为'abcxy' >>> print('abcxyz'.endswith('xyz',0,5)) False >>> print('abcxyz'.endswith('xyz',0,6)) True *suffix是元组(tuple)时,只要tuple中任意一个元素满足endswith的条件,就返回True。 >>> print('abcxyz'.endswith(('ab','xyz'))) True # tuple中'ab'和'xy'都不满足条件 >>> print('abcxyz'.endswith(('ab','xy'))) False # tuple中的'z'满足条件 >>> print('abcxyz'.endswith(('ab','xy','z'))) True
find,rfind和index,rindex
ps:S.find(sub[, start[, end]])、S.rfind(sub[, start[, end]])¶、S.index(sub[, start[, end]])、S.rindex(sub[, start[, end]]),find()搜索字符串S中是否包含子串sub,如果包含,则返回sub的索引位置,否则返回"-1"。可以指定起始start和结束end的搜索位置。index()和find()一样,唯一不同点在于当找不到子串时,抛出ValueError错误。rfind()则是返回搜索到的最右边子串的位置,如果只搜索到一个或没有搜索到子串,则和find()是等价的。同理rindex()。
>>> print('abcxyzXY'.find('xy')) 3 >>> print('abcxyzXY'.find('Xy')) -1 >>> print('abcxyzXY'.find('xy',4)) -1 >>> print('xyzabcabc'.find('bc')) 4 >>> print('xyzabcabc'.rfind('bc')) 7
in
ps:使用in操作符来判断字符串S是否包含子串sub,它返回的不是索引位置,而是布尔值
>>> 'xy' in 'abxycd' True >>> 'xyz' in 'abxycd' False
replace
ps:S.replace(old, new[, count]),将字符串中的子串old替换为new字符串,如果给定count,则表示只替换前count个old子串。如果S中搜索不到子串old,则无法替换,直接返回字符串S(不创建新字符串对象)。
>>> print('abcxyzoxy'.replace('xy','XY')) abcXYzoXY >>> print('abcxyzoxy'.replace('xy','XY',1)) abcXYzoxy >>> print('abcxyzoxy'.replace('mn','XY',1)) abcxyzoxy
split、rsplit和splitlines
ps:S.split(sep=None, maxsplit=-1)、S.rsplit(sep=None, maxsplit=-1)、S.splitlines([keepends=True]),都是用来分割字符串,并生成一个列表。split()根据sep对S进行分割,maxsplit用于指定分割次数,如果不指定maxsplit或者给定值为"-1",则会从做向右搜索并且每遇到sep一次就分割直到搜索完字符串。如果不指定sep或者指定为None,则改变分割算法:以空格为分隔符,且将连续的空白压缩为一个空格。rsplit()和split()是一样的,只不过是从右边向左边搜索。splitlines()用来专门用来分割换行符。虽然它有点像split('\n')或split('\r\n'),但它们有些区别,见下文解释。
>>> '1,2,3'.split(',') ['1', '2', '3'] >>> '1,2,3'.split(',',1) ['1', '2,3'] # 只分割了一次 >>> '1,2,,3'.split(',') ['1', '2', '', '3'] # 不会压缩连续的分隔符 >>> '<hello><><world>'.split('<') ['', 'hello>', '>', 'world>'] # sep为多个字符时 >>> '<hello><><world>'.split('<>') ['<hello>', '<world>'] # 不指定sep时 >>> '1 2 3'.split() ['1', '2', '3'] >>> '1 2 3'.split(maxsplit=1) ['1', '2 3'] >>> ' 1 2 3 '.split() ['1', '2', '3'] >>> ' 1 2 3 \n'.split() ['1', '2', '3'] # 显式指定sep为空格、制表符、换行符时 >>> ' 1 2 3 \n'.split(' ') ['', '1', '', '2', '', '3', '', '\n'] >>> ' 1 2 3 \n'.split('\t') [' 1 2 3 \n'] >>> ' 1 2\n3 \n'.split('\n') [' 1 2', '3 ', ''] # 注意列表的最后一项'' >>> ''.split('\n') ['']
splitlines
ps:splitlines()中可以指定各种换行符,常见的是\n、\r、\r\n。如果指定keepends为True,则保留所有的换行符
>>> 'ab c\n\nde fg\rkl\r\n'.splitlines() ['ab c', '', 'de fg', 'kl'] >>> 'ab c\n\nde fg\rkl\r\n'.splitlines(keepends=True) ['ab c\n', '\n', 'de fg\r', 'kl\r\n'] *将split()和splitlines()相比较一下 >> ''.split('\n') [''] # 因为没换行符可分割 >>> 'One line\n'.split('\n') ['One line', ''] #### splitlines() >>> "".splitlines() [] # 因为没有换行符可分割 >>> 'Two lines\n'.splitlines() ['Two lines']
join
ps:S.join(iterable)将可迭代对象(iterable)中的字符串使用S连接起来。注意,iterable中必须全部是字符串类型,否则报错。
>>> L='python' >>> '_'.join(L) 'p_y_t_h_o_n'
修剪:strip、lstrip和rstrip
ps:S.strip([chars])、S.lstrip([chars])、S.rstrip([chars]),分别是移除左右两边、左边、右边的字符char。如果不指定chars或者指定为None,则默认移除空白(空格、制表符、换行符)。唯一需要注意的是,chars可以是多个字符序列。在移除时,只要是这个序列中的字符,都会被移除。
*移除单个字符或空白 >>> ' spacious '.lstrip() 'spacious ' >>> ' spacious '.rstrip() ' spacious' >>> 'spacious '.lstrip('s') 'pacious ' >>> 'spacious'.rstrip('s') 'spaciou' *移除字符中的字符 >>> print('www.example.com'.lstrip('cmowz.')) example.com >>>print('wwwz.example.com'.lstrip('cmowz.')) example.com >>> print('wwaw.example.com'.lstrip('cmowz.')) aw.example.com >>> print('www.example.com'.strip('cmowz.')) 'examp
Python 转义字符
ps:字符中使用特殊字符时,python用反斜杠(\)转义字符。如下表:
|
转义字符 |
描述 |
|
\(在行尾时) |
续行符 |
|
\\ |
反斜杠符号 |
|
\' |
单引号 |
|
\" |
双引号 |
|
\a |
响铃 |
|
\b |
退格(Backspace) |
|
\e |
转义 |
|
\000 |
空 |
|
\n |
换行 |
|
\v |
纵向制表符 |
|
\t |
横向制表符 |
|
\r |
回车 |
|
\f |
换页 |
|
\oyy |
八进制数,yy代表的字符,例如:\o12代表换行 |
|
\xyy |
十六进制数,yy代表的字符,例如:\x0a代表换行 |
|
\other |
其它的字符以普通格式输出 |
Python字符串运算符
|
操作符 |
描述 |
实例 |
|
+ |
字符串连接 |
a + b 输出结果: HelloPython |
|
* |
重复输出字符串 |
a*2 输出结果:HelloHello |
|
[] |
通过索引获取字符串中字符 |
a[1] 输出结果 e |
|
[ : ] |
截取字符串中的一部分,遵循左闭右开原则,str[0,2] 是不包含第 3 个字符的。 |
a[1:4] 输出结果 ell |
|
in |
成员运算符 - 如果字符串中包含给定的字符返回 True |
'H' in a 输出结果 True |
|
not in |
成员运算符 - 如果字符串中不包含给定的字符返回 True |
'M' not in a 输出结果 True |
*原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母 r(可以大小写)以外,与普通字符串有着几乎完全相同的语法。
python 列表
列表是Python中最基本的数据结构。列表中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推。列表都可以进行的操作包括索引,切片,加,乘,检查成员。列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。列表的数据项不需要具有相同的类型。 列表序列操作有:索引、切片、修改、追加、插入、删除、扩展、统计、排序(翻转)、获取下标、拷贝
索引 (list[i])
peoples = ['Tom','Sun','Jack','Eso','Psi'] print(peoples[1]) print(peoples[-2]) ---------------------------- Sun Eso
切片 (list[a:b])
peoples = ['Tom','Sun','Jack','Eso','Psi'] print(peoples[:]) print(peoples[:3]) print(peoples[2:]) print(peoples[:-2]) print(peoples[1:4]) print(peoples[::2]) print(peoples[1:4:2]) ----------------------------------------- ['Tom', 'Sun', 'Jack', 'Eso', 'Psi'] ['Tom', 'Sun', 'Jack'] ['Jack', 'Eso', 'Psi'] ['Tom', 'Sun', 'Jack'] ['Sun', 'Jack', 'Eso'] ['Tom', 'Jack', 'Psi'] ['Sun', 'Eso']
修改
peoples = ['Tom','Sun','Jack','Eso','Psi'] peoples[2] = 'dragon' peoples[-1] = 'Qai' print(peoples) ------------------------------------------------ ['Tom', 'Sun', 'dragon', 'Eso', 'Qai']
追加 (list.append(elem))
*追加元素 peoples = ['Tom','Sun','Jack','Eso','Psi'] peoples.append('Risa') print(peoples) ------------------------------------------------- ['Tom', 'Sun', 'Jack', 'Eso', 'Psi', 'Risa'] *追加列表 peoples = ['Tom','Sun','Jack','Eso','Psi'] friends = ['zhangsan','lisi','wangmazi'] peoples.append(friends) print(peoples) -------------------------------------------------- ['Tom', 'Sun', 'Jack', 'Eso', 'Psi', ['zhangsan', 'lisi', 'wangmazi']]
插入 (list.inset(i, elem))
peoples = ['Tom','Sun','Jack','Eso','Psi'] peoples.insert(2,'Ben') peoples.insert(-2,'Kim') print(peoples) -------------------------------------------------- ['Tom', 'Sun', 'Ben', 'Jack', 'Kim', 'Eso', 'Psi']
删除
peoples = ['Tom','Sun','Jack','Eso','Psi'] #根据元素下标删除指定元素 del peoples[0] print(peoples) #删除指定元素 print(peoples.remove('Sun')) #删除最后一个元素,并返回该元素 print(peoples.pop()) ----------------------------------------------------- ['Sun', 'Jack', 'Eso', 'Psi'] None Psi
扩展 ( list.extend(new_list) )
peoples = ['Tom','Sun','Jack','Eso','Psi'] Man = ['Zhangsan','Lisi','Wangmazi'] #扩展是将一个列表追加到另一个列表,组成一个新的列表 peoples.extend(Man) print(peoples) ----------------------------------------------------- ['Tom', 'Sun', 'Jack', 'Eso', 'Psi', 'Zhangsan', 'Lisi', 'Wangmazi']
统计 list.count(elem)
peoples = ['Tom','Sun','Eso','Jack','Eso','Psi','Eso'] print(peoples.count('Eso')) print(peoples.count('Tom')) ----------------------------------- 3 1
排序(翻转)list.sort(self
key=None, reverse=False)key 可以为int,str, len, lambda等reverse可以为True和False
Ps:python3.0不允许不同数据类型进行排序
peoples = ['Tom','Sun','Jack','Es','Psi'] #默认按照ASCII表先后顺序排序 peoples.sort() print(peoples) #默认第一原则 字符串从短到长排序,第二原则ASCII表先后顺序 peoples.sort(key=len) print(peoples) ------------------------------------------------- ['Es', 'Jack', 'Psi', 'Sun', 'Tom'] ['Es', 'Psi', 'Sun', 'Tom', 'Jack']
翻转 list.reverse()
peoples = ['Tom','Sun','Jack','Es','Psi'] peoples.reverse() print(peoples) --------------------------------------------- ['Psi', 'Es', 'Jack', 'Sun', 'Tom']
获取下标 (list.index(elem))
ps: list.index(self,value,[start,[stop]]),value: 带获取下标的元素,start: 开始查询的下标,stop:终止查询的下标
peoples = ['Tom','Sun','Jack','Es','Psi','Sun'] print(peoples.index('Sun')) print(peoples.index('Sun',3)) ---------------------------------------- 1 5
拷贝 (list.copy())
ps: list.copy为浅拷贝,即只为列表元素的第一层开辟新地址,而第二层共用第一层的地址,也就是说,列表元素的第一层可以独立修改,而第二层不可独立修改
*浅拷贝 import copy peoples = ['Tom','Sun','Jack','Es','Psi',['Zhangsan','Lisi','Wangmazi']] copy_po = copy.copy(peoples) #改变第一层的值 peoples[2] = 'Jim' #改变第二层的值 peoples[5][1] = 'Wanger' print(peoples) print(copy_po) ----------------------------------------------- ['Tom', 'Sun', 'Jim', 'Es', 'Psi', ['Zhangsan', 'Wanger', 'Wangmazi']] ['Tom', 'Sun', 'Jack', 'Es', 'Psi', ['Zhangsan', 'Wanger', 'Wangmazi']] *深拷贝 import copy peoples = ['Tom','Sun','Jack','Es','Psi',['Zhangsan','Lisi','Wangmazi']] copy_po = copy.deepcopy(peoples) peoples[2] = 'Jim' copy_po[5][1] = 'Wanger' print(peoples) print(copy_po) ------------------------------------------------ ['Tom', 'Sun', 'Jim', 'Es', 'Psi', ['Zhangsan', 'Lisi', 'Wangmazi']] ['Tom', 'Sun', 'Jack', 'Es', 'Psi', ['Zhangsan', 'Wanger', 'Wangmazi']]
python 元组
存多个值,对比列表来说,元组不可变(是可以当做字典的key的),主要是用来读
创建
tuple = ('Tom','Sun','Jack','Es','Psi','Sun')
索引index
tuple = ('Tom','Sun','Jack','Es','Psi','Sun') print(tuple[1]) print(tuple[-2]) ---------------------------------------------- Sun Psi
统计count
tuple = ('Tom','Sun','Jack','Es','Psi','Sun','Es') print(tuple.count('Es')) print(tuple.index('Sun')) ---------------------------------------- 2 1
python 字典
Python字典是另一种可变容器模型,且可存储任意类型对象,如字符串、数字、元组等其他容器模型。每个键与值用冒号隔开(:),每对用逗号,每对用逗号分割,整体放在花括号中({})。键必须独一无二,但值则不必。值可以取任何数据类型,但必须是不可变的,如字符串,数或元组。
创建
dict = {'Tom':22,'Jack': 25,'Sun':23,'Qin': 26}
print(dict)
-----------------------------------------------------
{'Tom': 22, 'Jack': 25, 'Sun': 23, 'Qin': 26}
取值
dict = {'Tom':22,'Jack': 25,'Sun':23,'Qin': 26}
print(dict['Sun'])
---------------------------------------------------
23
修改
dict = {'Tom':22,'Jack': 25,'Sun':23,'Qin': 26}
#修改
dict['Tom'] = 12
#增加
dict['Risa'] = 21
print(dict)
------------------------------------------------------------
{'Tom': 12, 'Jack': 25, 'Sun': 23, 'Qin': 26, 'Risa': 21}
删除
- del dict['Name']; # 删除键是'Name'的条目
- dict.clear(); # 清空词典所有条目
- del dict ; # 删除词典
dict = {'Tom':22,'Jack': 25,'Sun':23,'Qin': 26}
#删除值
del dict['Jack']
print(dict)
-----------------------------------------------------
{'Tom': 22, 'Sun': 23, 'Qin': 26}
dict = {'Tom':22,'Jack': 25,'Sun':23,'Qin': 26}
#清空字典
print(dict.clear())
------------------------------------------------------
None
------------------------------------------------------
dict = {'Tom':22,'Jack': 25,'Sun':23,'Qin': 26}
#删除字典
del dict
内置函数
cmp(dict1, dict2):比较两个字典元素。 len(dict):计算字典元素个数,即键的总数。 str(dict):输出字典可打印的字符串表示。 type(variable):返回输入的变量类型,如果变量是字典就返回字典类型
内置函数
radiansdict.clear():删除字典内所有元素 radiansdict.copy():返回一个字典的浅复制 radiansdict.fromkeys():创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 radiansdict.get(key, default=None):返回指定键的值,如果值不在字典中返default值 radiansdict.has_key(key):如果键在字典dict里返回true,否则返回false radiansdict.items():以列表返回可遍历的(键, 值) 元组数组 radiansdict.keys():以列表返回一个字典所有的键 radiansdict.setdefault(key, default=None):和get()类似, 但如果键不已经存在于字典中,将会添加键并将值设为default radiansdict.update(dict2):把字典dict2的键/值对更新到dict里 radiansdict.values():以列表返回字典中的所有值
python集合
集合(set)是一个无序的不重复元素序列。可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
- 不同元素组成
- 无序
- 集合中的元素必须是不可变类型
创建集合
sets = {1,2,3,4,5,6}
#创建空集合
params = set()
print(sets)
print(type(params))
----------------------
{1, 2, 3, 4, 5, 6}
<class 'set'>
add,update添加元素
add,update添加元素 sets = {1,2,3,4,5,6} #返回值为空 sets.add(7) print(sets) ---------------------- {1, 2, 3, 4, 5, 6, 7} sets = {1,2,3,4,5,6} sets.update({8,9}) print(sets) ----------------------- {1, 2, 3, 4, 5, 6, 8, 9}
clear 清空集合
sets = {1,2,3,4,5,6,'Jack','Tom'}
print(sets.clear())
------------------------
None
len 计算元素个数
sets = {1,2,3,4,5,6,'Jack','Tom'}
print(len(sets))
------------------------
8
pop 删除并返回任意的集合元素(如果集合为空,会引发 KeyError)
sets = {1,2,3,4,5,6,'Jack','Tom'}
print(sets.pop())
-----------------------
1
remove 删除集合中的一个元素(如果元素不存在,会引发 KeyError)
sets = {1,2,3,4,5,6,'Jack','Tom'}
sets.remove('Tom')
print(sets)
---------------------
{1, 2, 3, 4, 5, 6, 'Jack'}
in 判断是否在集合中
sets = {1,2,3,4,5,6,'Jack','Tom'}
print(1 in sets)
---------------------
True
集合其它方法
copy 返回集合的浅拷贝
discard 删除集合中的一个元素(如果元素不存在,则不执行任何操作)
intersection 将两个集合的交集作为一个新集合返回
union 将集合的并集作为一个新集合返回
difference 将两个或多个集合的差集作为一个新集合返回
symmetric_difference 将两个集合的对称差作为一个新集合返回(两个集合合并删除相同部分,其余保留)
update 用自己和另一个的并集来更新这个集合
intersection_update() 用自己和另一个的交集来更新这个集合
isdisjoint() 如果两个集合有一个空交集,返回 True
issubset() 如果另一个集合包含这个集合,返回 True
issuperset() 如果这个集合包含另一个集合,返回 True
difference_update() 从这个集合中删除另一个集合的所有元素
symmetric_difference_update() 用自己和另一个的对称差来更新这个集合
集合内置函数
| 函数 | 描述 |
| all() | 如果集合中的所有元素都是 True(或者集合为空),则返回 True。 |
| any() | 如果集合中的所有元素都是 True,则返回 True;如果集合为空,则返回 False。 |
| enumerate() | 返回一个枚举对象,其中包含了集合中所有元素的索引和值(配对)。 |
| len() | 返回集合的长度(元素个数) |
| max() | 返回集合中的最大项 |
| min() | 返回集合中的最小项 |
| sorted() | 从集合中的元素返回新的排序列表(不排序集合本身) |
| sum() | 返回集合的所有元素之和 |
python布尔类型
ps:布尔类型只有True和False两种值,但是布尔类型有以下几种运算
与运算
ps:只有两个布尔值都为 True 时,计算结果才为 True。
True and True ==> True
True and False ==> False
False and True ==> False
False and False ==> False
或运算
ps:只要有一个布尔值为 True,计算结果就是 True。
True or True ==> True
True or False ==> True
False or True ==> True
False or False ==> False
非运算
ps:把True变为False,或者把False变为True:
not True ==> False
not False ==> True
bytes类型
存8bit整数,数据基于网络传输或内存变量存储到硬盘时需要转成bytes类型,字符串前置b代表为bytes类型
x = 'hello sb' >>> x 'hello sb' >>> x.encode('gb2312') b'hello sb'
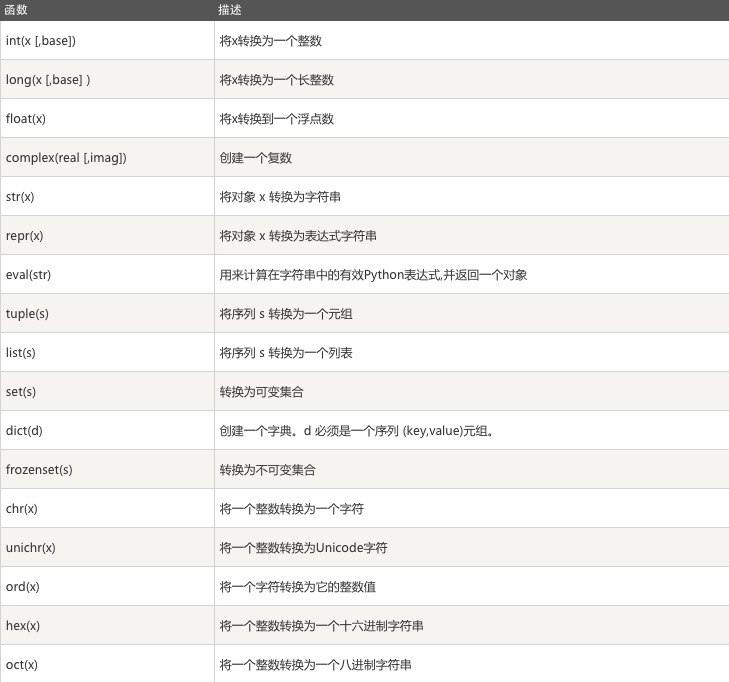
数据类型转换内置函数
简单示例
#!/usr/bin/env python # -*- coding:utf-8 -*- ''' 打印示例菜单 可返回上一级 可随时退出程序 ''' menu_dict = {'陕西':{ '西安':{ '雁塔':['高塔','喷泉'], '碑林':['莲湖','湖水'] }, '延安':{ '沧浪':['宝塔','皇帝'], '安阳':['高原','黄河'] } }, '河北':{ '泊头':{ '泊水':['林木','花草'], '北京':['故宫','会堂'] }, '林溪':{ '锡林':['西一','西二'], '海淀':['大学','中学'] } }, } flag = True while flag: print("===provice===") for key,value in menu_dict.items(): print("%6s" %key) print("=============") choice_provice = input("please choice provice or enter 'q' quit >>: ") if choice_provice == "q": flag = False continue if choice_provice not in menu_dict: continue while flag: city_dict = menu_dict[choice_provice] print("====city====") for key,value in city_dict.items(): print("%6s" %key) print("============") choice_city = input("pleease choice city or enter 'b' back or enter 'q' quit >> ") if choice_city == 'q': flag = False continue if choice_city == "b": break if choice_city not in menu_dict[choice_provice]: continue while flag: area_dict = menu_dict[choice_provice][choice_city] print("====area====") for key,values in area_dict.items(): print("%5s" %key) print("============") choice_area = input("please choice area or enter 'b' or enter 'q' quit >> ") if choice_area == 'q': flag = False if choice_area == 'b': break if choice_area not in menu_dict[choice_provice][choice_city]: continue while flag: list_view = menu_dict[choice_provice][choice_city][choice_area] print("====end=====") for i in list_view: print("%4s" %i) print("============") flag = False

