爬虫作业
(2)请用requests库的get()函数访问如下一个网站20次,打印返回状态,text()内容,计算text()属性和content属性所返回网页内容的长度。(不同学号选做如下网页,必做及格)
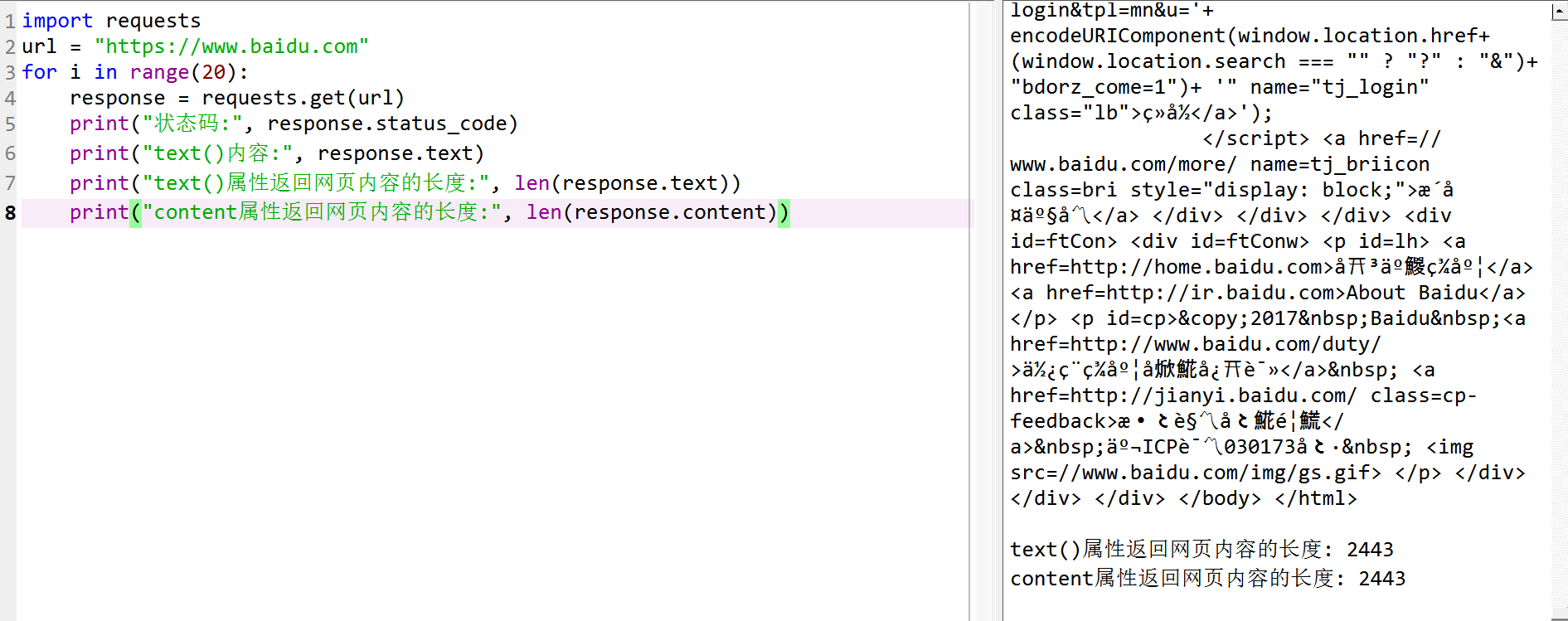
import requests
url = "https://www.baidu.com"
for i in range(20):
response = requests.get(url)
print("状态码:", response.status_code)
print("text()内容:", response.text)
print("text()属性返回网页内容的长度:", len(response.text))
print("content属性返回网页内容的长度:", len(response.content))
(3)这是一个简单的html页面,请保持为字符串,完成后面的计算要求。
import requests
from bs4 import BeautifulSoup
a="<html><head><meta charset='utf-8'><title>菜鸟教程(runoob.com)</title></head><body><h1>我的第一个标题</h1><p id='first'>我的第一个段落。</p></body><table border='1'><tr><td>row 1, cell 1</td><td>row 1, cell 2</td></tr><tr><td>row 2, cell 1</td><td>row 2, cell 2</td></tr></table></html>"
soup=BeautifulSoup(a,features="lxml")
print(soup.head)
print(16)
print(soup.body)
print(soup.p)
text = soup.get_text()
print(text)

(4)爬中国大学排名网站内容,
# e23.1CrawUnivRanking.py
import re
import pandas as pd
import requests
from bs4 import BeautifulSoup
allUniv = []
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def fillUnivList(soup):
soup.encode('utf-8')
data = soup.find_all('tr')
list1=[]
for tr in data:
ltd = tr.find_all('td')
if len(ltd) == 0:
continue
singleUniv = []
for td in ltd:
temp=re.findall('[\u4e00-\u9fff]+' ,str(td))
if td.string!=None and td.string!="[]":
singleUniv.append(td.string)
if temp!=[]:
if type(temp)==list:
str1=''
for i in temp:
str1+=i
singleUniv.append(str1)
allUniv.append(singleUniv)
return allUniv
def printUnivList(num):
print("{:^5}{:^4}{:^5}{:^10}{:^10}".format("排名", "学校名称", "省市", "类型", "总分"))
for i in range(num):
u = allUniv[i]
u[0]=u[0][29:31]
u[1]=u[1][:4]
u[4]=u[4][25:31]
print("{:^5} {:^4}{:^5}{:^10}{:^10}".format(u[0], u[1], u[2], u[3], u[4]))
def main(flag):
url = 'https://www.shanghairanking.cn/rankings/bcur/201711'
html = getHTMLText(url)
soup = BeautifulSoup(html, "html.parser")
list1=fillUnivList(soup)
if flag==0:
printUnivList(10)
else:
return list1
# 定义一个函数,将里面的嵌套列表的第一个元素取出
def combination(list1,count):
list2=[]
for i in list1:
list2.append(i[count])
return list2
main(0)
list1=main(1)
# 定义一个函数,处理一下获取到的数据
def deal_data(list1):
list_1=combination(list1,0)
list_2=combination(list1,1)
list_3=combination(list1,2)
list_4=combination(list1,3)
list_5=combination(list1,4)
data = pd.DataFrame({
"排名": list_1,
"学校名称": list_2,
'省市': list_3,
'类型': list_4,
'总分': list_5
})
return data
data=deal_data(list1)
data.to_csv('University_grade.csv',index=False)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号