K-Means 及 K-Means++
原始K-means算法最开始随机选取数据集中K个点作为聚类中心,而K-means++按照如下的思想选取K个聚类中心:
- 假设已经选取了n个初始聚类中心(0<n<K),则在选取第n+1个聚类中心时:距离当前n个聚类中心越远的点会有更高的概率被选为第n+1个聚类中心。
- 在选取第一个聚类中心(n=1)时同样通过随机的方法。
可以说这也符合我们的直觉:聚类中心当然是互相离得越远越好。这个改进虽然直观简单,但是却非常得有效。
经典K-means算法:

值得一提的是关于聚类中心数目(K值)的选取,的确存在一种可行的方法,叫做Elbow Method:
通过绘制K-means代价函数与聚类数目K的关系图,选取直线拐点处的K值作为最佳的聚类中心数目。
上述方法中的拐点在实际情况中是很少出现的。
比较提倡的做法还是从实际问题出发,人工指定比较合理的K值,通过多次随机初始化聚类中心选取比较满意的结果。
K-means++算法:
起步
由于 K-means 算法的分类结果会受到初始点的选取而有所区别,因此有提出这种算法的改进: K-means++ 。
算法步骤
其实这个算法也只是对初始点的选择有改进而已,其他步骤都一样。初始质心选取的基本思路就是,初始的聚类中心之间的相互距离要尽可能的远。
算法描述如下:
- 步骤一:随机选取一个样本作为第一个聚类中心 c1;
- 步骤二:
- 计算每个样本与当前已有类聚中心最短距离(即与最近一个聚类中心的距离),用
D(x)表示; - 这个值越大,表示被选取作为聚类中心的概率较大;
- 最后,用轮盘法选出下一个聚类中心;
- 计算每个样本与当前已有类聚中心最短距离(即与最近一个聚类中心的距离),用
- 步骤三:重复步骤二,知道选出 k 个聚类中心。
选出初始点后,就继续使用标准的 k-means 算法了。
效率
K-means++ 能显著的改善分类结果的最终误差。
尽管计算初始点时花费了额外的时间,但是在迭代过程中,k-mean 本身能快速收敛,因此算法实际上降低了计算时间。
网上有人使用真实和合成的数据集测试了他们的方法,速度通常提高了 2 倍,对于某些数据集,误差提高了近 1000 倍。

下面结合一个简单的例子说明K-means++是如何选取初始聚类中心的。
数据集中共有8个样本,分布以及对应序号如下图所示:

假设经过图2的步骤一后6号点被选择为第一个初始聚类中心,
那在进行步骤二时每个样本的D(x)和被选择为第二个聚类中心的概率如下表所示:
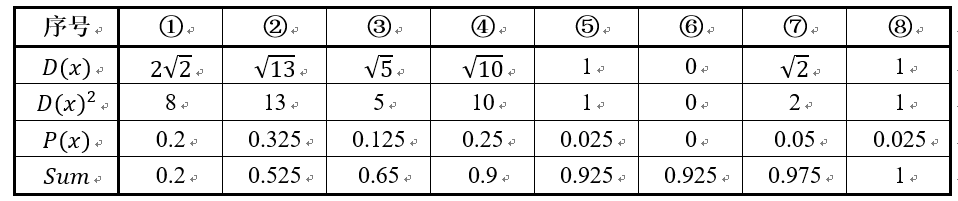
其中的P(x)就是每个样本被选为下一个聚类中心的概率。
最后一行的Sum是概率P(x)的累加和,用于轮盘法选择出第二个聚类中心。
方法是随机产生出一个0~1之间的随机数,判断它属于哪个区间,那么该区间对应的序号就是被选择出来的第二个聚类中心了。
例如1号点的区间为[0,0.2),2号点的区间为[0.2, 0.525)。
从上表可以直观的看到第二个初始聚类中心是1号,2号,3号,4号中的一个的概率为0.9。
而这4个点正好是离第一个初始聚类中心6号点较远的四个点。
这也验证了K-means的改进思想:即离当前已有聚类中心较远的点有更大的概率被选为下一个聚类中心。
可以看到,该例的K值取2是比较合适的。当K值大于2时,每个样本会有多个距离,需要取最小的那个距离作为D(x)。
# coding: utf-8
import math
import random
from sklearn import datasets
def euler_distance(point1: list, point2: list) -> float:
"""
计算两点之间的欧拉距离,支持多维
"""
distance = 0.0
for a, b in zip(point1, point2):
distance += math.pow(a - b, 2)
return math.sqrt(distance)
def get_closest_dist(point, centroids):
min_dist = math.inf # 初始设为无穷大
for i, centroid in enumerate(centroids):
dist = euler_distance(centroid, point)
if dist < min_dist:
min_dist = dist
return min_dist
def kpp_centers(data_set: list, k: int) -> list:
"""
从数据集中返回 k 个对象可作为质心
"""
cluster_centers = []
cluster_centers.append(random.choice(data_set))
d = [0 for _ in range(len(data_set))]
for _ in range(1, k):
total = 0.0
for i, point in enumerate(data_set):
d[i] = get_closest_dist(point, cluster_centers) # 与最近一个聚类中心的距离
total += d[i]
total *= random.random()
for i, di in enumerate(d): # 轮盘法选出下一个聚类中心;
total -= di
if total > 0:
continue
cluster_centers.append(data_set[i])
break
return cluster_centers
if __name__ == "__main__":
iris = datasets.load_iris()
print(kpp_centers(iris.data, 4))
posted on 2019-03-13 15:13 victory__li 阅读(918) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号