
【算法】BILSTM+CRF中的条件随机场
BILSTM+CRF中的条件随机场
tensorflow中crf关键的两个函数是训练函数tf.contrib.crf.crf_log_likelihood和解码函数tf.contrib.crf.viterbi_decode
crf_log_likelihood(inputs, tag_indices, sequence_lengths, transition_params=None)
Computes the log-likelihood of tag sequences in a CRF.
Args:
inputs: A [batch_size, max_seq_len, num_tags] tensor of unary potentials
to use as input to the CRF layer.
tag_indices: A [batch_size, max_seq_len] matrix of tag indices for which we
compute the log-likelihood.
sequence_lengths: A [batch_size] vector of true sequence lengths.
transition_params: A [num_tags, num_tags] transition matrix, if available.
Returns:
log_likelihood: A scalar containing the log-likelihood of the given sequence
of tag indices.
transition_params: A [num_tags, num_tags] transition matrix. This is either
provided by the caller or created in this function.
viterbi_decode(score, transition_params)
Decode the highest scoring sequence of tags outside of TensorFlow.
This should only be used at test time.
Args:
score: A [seq_len, num_tags] matrix of unary potentials.
transition_params: A [num_tags, num_tags] matrix of binary potentials.
Returns:
viterbi: A [seq_len] list of integers containing the highest scoring tag
indicies.
viterbi_score: A float containing the score for the Viterbi sequence.
看着这两个函数定义,我懵逼了。在看完了李航的《统计学习方法》后,我以为我可以轻松搞定bilstm+crf中的crf。然而对着这两个函数发呆了半天,发现怎么跟书上的理论对不上号?特征函数呢?转移函数呢?怎么训练完之后就只有个transition_params,维度还是num_tags x num_tags。这是什么东西。
郁闷的在网上找资料,终于看到了参考资料里面的讲解,总算是醍醐灌顶看懂了。这里记录一下。
bilstm和crf的作用
在bilstm+crf结构中,bilstm的输出已经是各个标签取值的概率了,crf的作用仅仅是根据标签间的关系做结果调整。借用参考资料里的图片
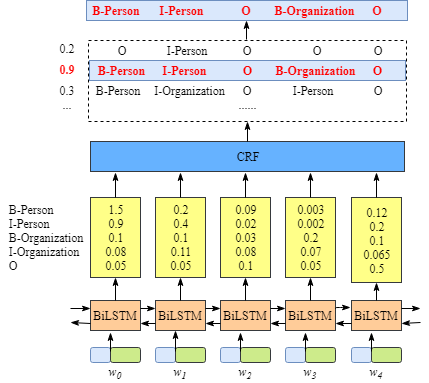
那么,bilstm已经输出标签取值概率了,为什么还需要crf层呢。因为直接用bilstm输出的标签有些并不合理,比如B-Person,I-Organization就是一个不合理的序列。crf做的就是在bilstm输出的基础上,调整输出标签,使得标签结果顺序更为合理。
crf细节
与之前介绍的标准形式相似,在条件\(x\)的情况下,序列\(y\)出现的概率\(P(y|x)\)可以表达为:
\(e^s\)是当前序列的分数,分母是所有序列分数的和。
可以对比一下之前介绍crf那篇的公式,到这里跟传统的crf都是一样的,只是表达上现在的公式化简了一些。
下面就是和前一篇不同的地方了,区别就在于\(s\)。在之前的介绍中,\(s\)由状态特征函数和转移特征函数组成,并有各自的权重。而bilstm+crf中的crf其\(s\)的组成要简单很多。
先介绍两个重要变量:
\(EmissionScore\): bilstm输出的每个位置是各个标签的概率。是一个\(seq\_len\times num\_tags\)的矩阵。如上图黄色矩形部分。
\(TransitionScore\): 标签间的转移概率。是一个\(num\_tags\times num\_tags\)的矩阵
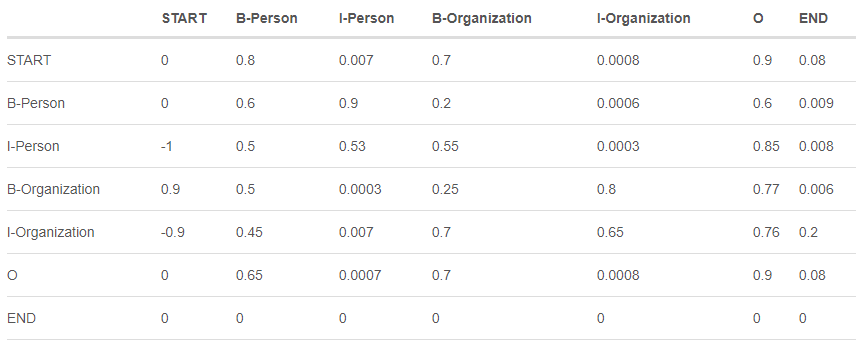
上面矩阵的含义是,如果前一个标签是START,而后一个标签为B-Person的概率为0.8,而START后接I-Organization的概率只有0.0008。这是符合人们的认知的。
这样,就可以介绍\(s_i\)的组成了。
对于序列来说,比如有一个序列是“START B-Person I-Person O B-Organization O END”,则
看到这里就知道bilstm之上的crf与普通crf的区别了。普通crf的样本概率受特征函数和相关权值的影响。而bilstm上的crf则没有特征函数,也没有权值,结果受bilstm层输出的各个位置标签概率,以及标签间的状态转移矩阵影响。对于bilstm+crf的crf层来说,要学习的就只有标签间状态转移矩阵而已。
看到这,再对应tensorflow的函数定义,就很明白了。
crf_log_likelihood函数输出的transition_params,就是要求解的状态转移矩阵。
viterbi_decode(score, transition_params),就是通过bilstm的输出score和求解的状态转移矩阵transition_params来解码最终结果。
参考资料
- https://createmomo.github.io/2017/09/12/CRF_Layer_on_the_Top_of_BiLSTM_1/
- https://createmomo.github.io/2017/09/23/CRF_Layer_on_the_Top_of_BiLSTM_2/
- https://createmomo.github.io/2017/10/08/CRF-Layer-on-the-Top-of-BiLSTM-3/
- https://createmomo.github.io/2017/10/17/CRF-Layer-on-the-Top-of-BiLSTM-4/
- https://createmomo.github.io/2017/11/11/CRF-Layer-on-the-Top-of-BiLSTM-5/
- https://createmomo.github.io/2017/11/24/CRF-Layer-on-the-Top-of-BiLSTM-6/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号