
Redis 设计与实现(第八章) -- 对象
概述
前面几张介绍了一些Redis的数据结构,比如SDS,集合,字典等,但是Redis并不会直接使用这些数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统,这些对象包括字符串对象,列表对象,哈希对象,集合对象和有序集合对象。每种对象都用到了一种或多种前面介绍的数据结构。
通过不同类型的对象,Redis在执行命令之前可以根据类型来判断一个对象是否可以执行给定的命令。
Redis对象还使用了基于引用计数的内存回收机制,当程序不再使用某个对象时,这个对象占用的内存就会释放。
Redis的对象带有访问时间记录信息,可以用于计算数据空键的空转时长,在服务器启用了maxmemory的情况下,空转时长比较大的键的可能会被服务器删除。
对象类型与编码
首先看一下对象的数据结构:
typedef struct redisObject { unsigned type:4; //类型,主要包括: unsigned encoding:4; //编码 unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */ int refcount; void *ptr; //执行底层实现的数据结构的指针 } robj;
type有以下几种类型,在redis客户端可通过type key来查看对应key的类型
/* Object types */
#define REDIS_STRING 0
#define REDIS_LIST 1
#define REDIS_SET 2
#define REDIS_ZSET 3
#define REDIS_HASH 4
encoding类型有,在redis客户端可通过OBJECT ENCONDING key来查看对应key的encoding类型
#define REDIS_ENCODING_RAW 0 /* Raw representation */
#define REDIS_ENCODING_INT 1 /* Encoded as integer */
#define REDIS_ENCODING_HT 2 /* Encoded as hash table */
#define REDIS_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define REDIS_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list */
#define REDIS_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define REDIS_ENCODING_INTSET 6 /* Encoded as intset */
#define REDIS_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define REDIS_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
接下来对五中类型的对象一一讲解下:
字符串对象
字符串对象的编码可以是int,raw或者embstr
如果一个字符串key保存的是整数值,而且这个整数可以通过long类型的表示,那么字符串对象就会将整数值保存在字符串对象结构的ptr里面(void *long),并将字符串的编码类型设置为int,如下:
redis 127.0.0.1:6379> set msg 10086
OK
redis 127.0.0.1:6379> object encoding msg
"int"
但是如果保存是字符串类型呢?
127.0.0.1:6379[15]> set msg "hello"
OK
127.0.0.1:6379[15]> object encoding msg
"embstr"
127.0.0.1:6379[15]> set msg "helloasdfasdfsadfasdfasdfsadfsadfasdfasdfasdfsadf"
OK
127.0.0.1:6379[15]> object encoding msg
"raw"
可以看到,分布使用了embstr和raw编码来保存字符串值,为什么会有这种区别呢? 还有什么情况下使用raw什么时候使用embstr呢?
当字符串长度超过32时,字符串对象采用raw来编码,如果小于32时,则使用embstr。那ptr怎么指向呢? Redis里面的string通常都使用SDS来表示。所以数据结构如果:
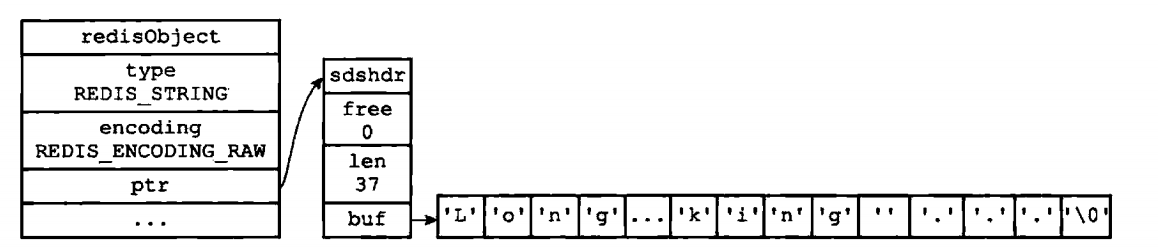
embstr是专门用于保存短字符串的一种优化编码方式,和raw一样,都需要使用redisObject和sds结构来表示字符串对象,不同的是raw会调用两次内存分配来分别为两个数据结构分配空间大小,而embstr只需要调用一次来分配连续空间。
使用embstr的好处在哪呢?
1.刚才讲到的,内存分配次数从两次降到一次;
2.所以内存释放也只需要调用一次了;
3.连续内存能够更好的利用缓存优势。
embstr的结构如下:

最后浮点数也是以字符串的方式来保存的,可以看下:
127.0.0.1:6379[15]> set msg 3.14159
OK
127.0.0.1:6379[15]> object encoding msg
"embstr"
编码是可以转换的,比如msg刚开始是int,后来追加了一条数据,编码就会改变
127.0.0.1:6379[15]> set msg 3
OK
127.0.0.1:6379[15]> object encoding msg
"int"
127.0.0.1:6379[15]> append msg abc
(integer) 4
127.0.0.1:6379[15]> object encoding msg
"raw"
127.0.0.1:6379[15]> get msg
"3abc"
列表对象
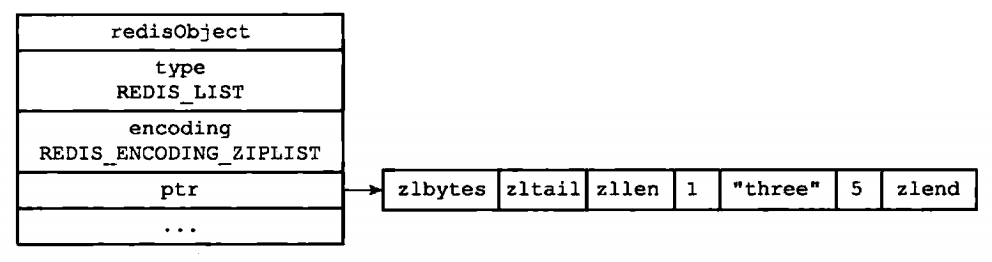
列表对象的编码方式可以是ziplist或者linkedlist。
如果是ziplist,那么对象应该为下图,ptr执行ziplist结构
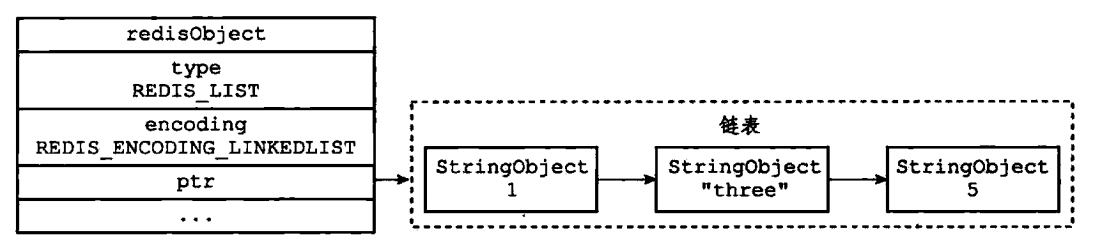
如果是linkedlist,对象结构如下,stringObject代表是SDS,这里是为了简化一下
什么时候使用ziplist,什么时候使用linkedlist?(版本仅针对3.0.x的,3.2.x版本上目前使用的都是quicklist)
当列表对象同时满足下面两个条件时,使用ziplist,否则使用linkedlist:
1.列表对象保存的所有字符串长度都小于64;
2.列表对象保存的元素个数小于512;
哈希对象
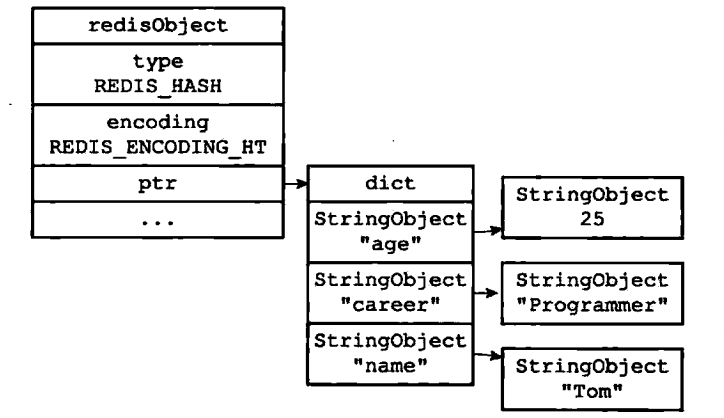
hash对象的编码方式由ziplist和hashtable
使用ziplist保存结构如下图

使用hashtable保存结构如下,其中stringObject也是为SDS结构
什么时候使用的ziplist,什么时候使用hashtable?
同时满足下面两个条件时,使用ziplist,否则使用hashtable:
1.hash的键值对的长度均小于64;
2.hash对象的保存的键值对数量小于512;
127.0.0.1:6379[15]> object encoding book
"ziplist"
127.0.0.1:6379[15]> hset book content "C++asdfasdkfjlasdjfl;sajdfljsadlkfjsakldfjlksadjfklsdjflksajdflkasjdlfkjasdl;fjasl;dfjl;sadfjlsadkjflsadf"
(integer) 1
127.0.0.1:6379[15]> object encoding book
"hashtable"
集合对象
集合对象的编码方式由intset和hashtable
intset和hashtable表示的结构分布如下:
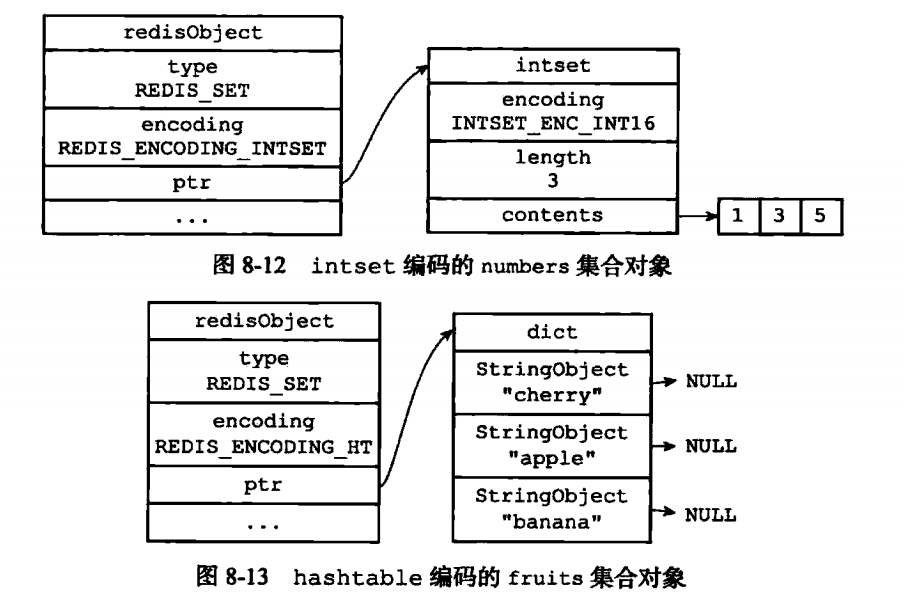
什么时候用hashtable,什么时候用intset?
同时满足下面两个条件时,使用intset,否则使用hashtable:
1.所有对象元素为整数值;
2.集合对象的元素数量不超过512个;
127.0.0.1:6379[15]> sadd keyset 1 2 3
(integer) 3
127.0.0.1:6379[15]> object encoding keyset
"intset"
127.0.0.1:6379[15]> sadd keyset "aa"
(integer) 1
127.0.0.1:6379[15]> object encoding keyset
"hashtable"
有序集合对象
有序集合对象的编码可以是ziplist和skiplist
ziplist编码,压缩列表中的元素按照score从小到大排序,结构如下:

skiplist编码方式使用的zset结构作为底层实现,一个zset结构同时包含了一个skiplist和一个hashtable
typedef struct zset { dict *dict; zskiplist *zsl; } zset;
zsl跳跃表按照分值从小到大保存了所有元素,每个跳跃点都保存了一个集合元素,跳跃节点的object属性保存了元素的成员,score属性保存了分值,通过跳跃表程序可以对有序集合进行范围操作,比如zrange等。
为什么还需要dict呢?
dict为有序集合创建了一份从成员到分值的映射,程序可以在O(1)时间复杂度内查询成员的score值,ZSCORE就是用到了dict。如果没有dict,那么查询成员score的复杂度将由O(1)上升到O(logn)
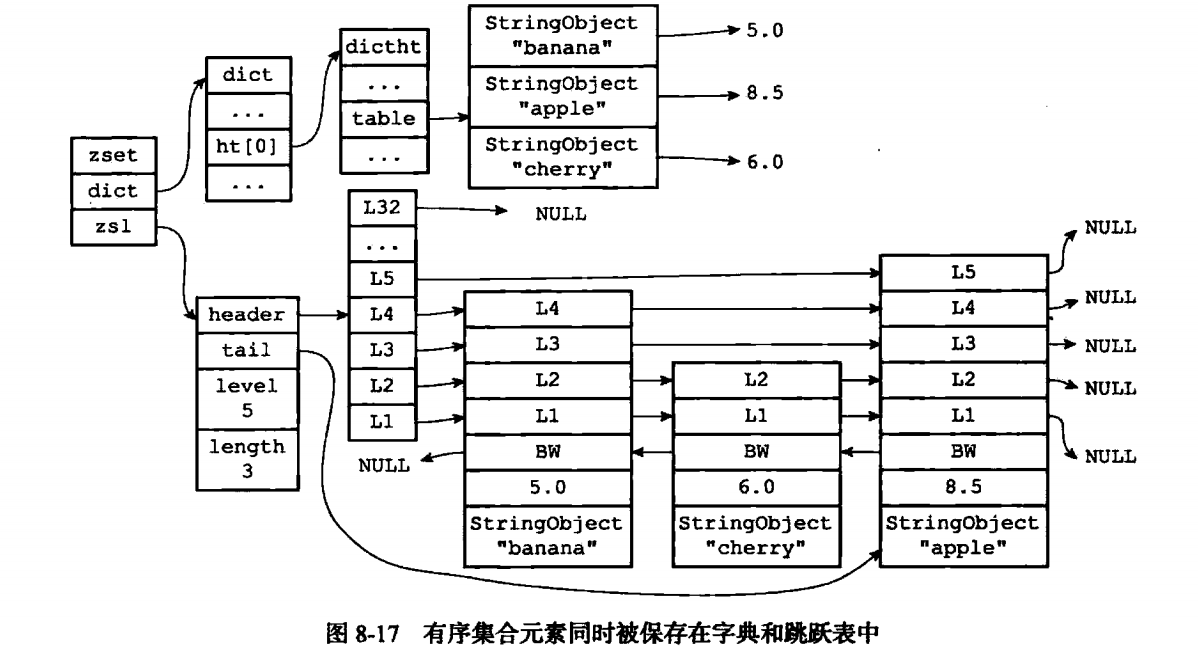
什么时候使用ziplist,什么时候使用skiplist呢?
同时满足下面两个条件的时候,使用ziplist,否则使用skiplist:
1.有序集合保存的元素数小于128;
2.有序集合所有元素的长度均小于64;
类型检查与命令多态
类型检查
Redis中用于操作键的命令基本上分为两种。一种是可以作用于任何键上的命令,比如DEL,TYPE,OBJECT,EXPIRE等。
另一种是只能针对特定集合的命令,比如:

如果对一个字符串键执行SADD命令,则会报错。在Redis执行命令之前,会先检查键的类型是否正确,然后再决定是否需要执行命令。
比如在字符串键上执行SADD命令:
在执行SADD命令之前,Redis会先检查数据库键对象类型是否为集合对象,也就是检查redisObject的type属性是否为REDIS_SET,如果不是,则报错,如果是,则执行命令。
多态命令
除了上面的类型检查,Redis还会根据对象的编码方式,选择正确的命令实现代码来执行命令。
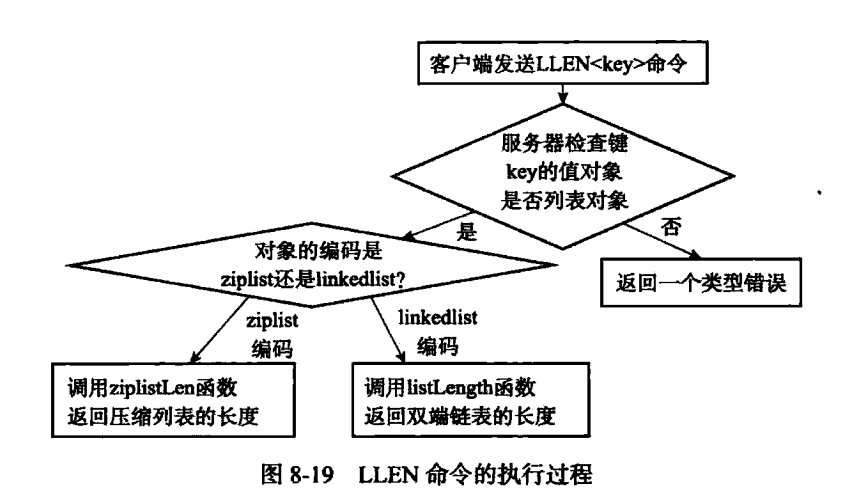
举例来说,之前说到list集合底层有ziplist和linkedlist两种实现方式,比如现在需要对key执行一个LLEN命令来返回list的长度,
如果是基于ziplist的方式,则会调用ziplist的ziplistLen函数来返回;
如果是基于linkedlist,则会调用listLength函数来返回。
从面向对象的角度来看,我们认为LLEN命令是多态的,只要LLEN命令执行的是列表键,无论是ziplist还是linkedlist都能够正确返回长度。实际上,DEL,TYPE,EXPIRE都可以称为多态,因为无论键是什么类型,命令都可以正确执行。
内存回收
C并不具有自动回收内存机制,所有Redis构建了一个引用计数实现内存的回收机制,通过这一机制,程序可以在适当的时候自动释放对象并回收内存。
我们可以看到redisObject的数据结构中,有个refcount属性,
typedef struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */ int refcount; void *ptr; } robj;
改计数会随着对象的使用状态而不断变化:
- 在创建一个新的对象时,改计数的初始值为1
- 当对象被一个程序使用时,计数+1;
- 当对象不再被一个程序使用时,计数-1;
- 当对象的引用计数变为0时,进行释放且回收内存
举个例子,如下:

对象共享
引用计数除了内存回收外,还有对象共享的作用。比如键A创建了一个包含整数值100的字符串作为值对象,如果这时候键B也要创建一个同样保存数值100的字符串作为值对象,这时服务器有两种做法:
1.为键B也创建数值为100的字符串对象;
2.让AB共享一个100的字符串对象。
先让方法2会更节约内存,这时只需要把数据库键的指针指向一个现有的值对象,并且将被共享值对象的refcount+1;

如下:
127.0.0.1:6379[15]> object refcount msg1
(integer) 209
127.0.0.1:6379[15]> set msg2 100
OK
127.0.0.1:6379[15]> object refcount msg2
(integer) 210
虽然如此,Redis只对包含整数值的字符串对象进行共享。为什么不对String值的字符串对象进行共享呢?
如果服务器需要进行对象共享的话,首先需要判断要创建的目标对象是否与给定的共享对象完全相同,这时进行比较时,如果共享对象保存的值越复杂,判断起来就越复杂:
1.针对整数值的字符串对象判断,时间复杂度为O(1)
2.针对字符串值的字符串对象判断,时间复杂度为为O(N)
3.如果字符串对象包含了多个值对象,那么判断的复杂度就会更高了。
判断负责度会消耗CPU,所以Redis只对整数值的字符串对象进行共享。
对象的空转时长
redisObject属性中中,还有一个没有介绍到,就是lru,该属性记录了对象最后一次被访问的时间。OBJECT IDLETIME key命令就可以打印出键的空转时长,这一空转时长就是通过当前时间减去键对象的lru时间计算出来的。OBJECT IDLETIME 命令比较特性,在访问键的时候,不会修改lru属性。
127.0.0.1:6379[15]> object idletime msg2
(integer) 1098153
键的空转时长还有一个作用,当服务器开启maxmemory时,如果服务器的内存超过了maxmemory设置的上限,那么服务器就会优先释放空转时长比较长的那部分键,从而回收内存。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号