

概述
1.SDS介绍
2.SDS API
3.SDS与C的比较
SDS介绍
在C语言中,用来表达字符串的方式通常有两种,
char *buf1="redis";
char buf2[]="redis";
方式1,通过一个char指针指向一个字符串字面量,起内容无法改变,即无法通过buf1[1]='c'来改变内容,如果需要改变,需要将指针重新赋值,指向其他内存空间;
方式2,char数组,末尾有一个‘\0’来代表结束,但是不携带长度信息,在字符串操作时,比如strcat,可能会导致缓存区溢出。
在Redis里面C中的字符串字面量一般只用于不需要对字符串值修改的地方,比如打印日志:
redisLog(REDIS_WARNING,'redis now is ready to exit,bye bye...')
当需要对字符串值进行修改时,会使用SDS结构来表示字符串值;
在Redis中,SDS用于很多地方,比如数据库中的键值,缓冲区,AOF缓冲区等。 可以说SDS是redis的基础。
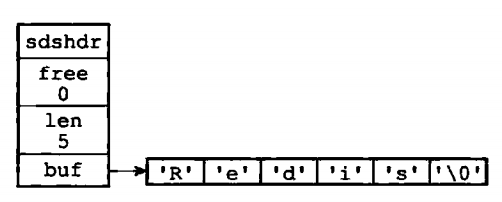
可以看一下SDS的数据结构,在sds.h文件:
struct sdshdr { unsigned int len; //记录buf数组中已经使用的字节数量,等于SDS的长度 unsigned int free; //buf数组中未使用的字节数量 char buf[]; //buf数组,用于存储字符串 };
可以看到,sds的数据结构多了len和free字段,后面会讲到这两个字段的主要用途。下图说明存储结构:

SDS API
创建
sds sdsnewlen(const void *init, size_t initlen) { struct sdshdr *sh; if (init) { sh = zmalloc(sizeof(struct sdshdr)+initlen+1); //初始化,+1用于存储"\0" } else { sh = zcalloc(sizeof(struct sdshdr)+initlen+1); } if (sh == NULL) return NULL; sh->len = initlen; //设置长度 sh->free = 0; //free为0 if (initlen && init) memcpy(sh->buf, init, initlen); //将init中的内存拷贝到sds中 sh->buf[initlen] = '\0'; //结尾符 return (char*)sh->buf; }
复制
sds sdsdup(const sds s) { return sdsnewlen(s, sdslen(s)); }
释放
void sdsfree(sds s) { if (s == NULL) return; zfree(s-sizeof(struct sdshdr)); }
清除
void sdsclear(sds s) { struct sdshdr *sh = (void*) (s-(sizeof(struct sdshdr))); sh->free += sh->len; //free回收 sh->len = 0; //len变为0 sh->buf[0] = '\0'; }
获取长度
static inline size_t sdslen(const sds s) { struct sdshdr *sh = (void*)(s-(sizeof(struct sdshdr))); return sh->len; } static inline size_t sdsavail(const sds s) { struct sdshdr *sh = (void*)(s-(sizeof(struct sdshdr))); return sh->free; }
sdscat
sds sdscatlen(sds s, const void *t, size_t len) { struct sdshdr *sh; size_t curlen = sdslen(s); s = sdsMakeRoomFor(s,len); //调用扩容 if (s == NULL) return NULL; sh = (void*) (s-(sizeof(struct sdshdr))); memcpy(s+curlen, t, len); sh->len = curlen+len; sh->free = sh->free-len; s[curlen+len] = '\0'; return s; } /* Append the specified null termianted C string to the sds string 's'. * * After the call, the passed sds string is no longer valid and all the * references must be substituted with the new pointer returned by the call. */ sds sdscat(sds s, const char *t) { return sdscatlen(s, t, strlen(t)); }
扩容
sds sdsMakeRoomFor(sds s, size_t addlen) { struct sdshdr *sh, *newsh; size_t free = sdsavail(s); size_t len, newlen; if (free >= addlen) return s; //判断是否需要扩容 len = sdslen(s); sh = (void*) (s-(sizeof(struct sdshdr))); newlen = (len+addlen); if (newlen < SDS_MAX_PREALLOC) //小于1M则扩展为新的长度的两倍 newlen *= 2; else newlen += SDS_MAX_PREALLOC; //大于1M则扩容为字符串长度加上1M newsh = zrealloc(sh, sizeof(struct sdshdr)+newlen+1); if (newsh == NULL) return NULL; newsh->free = newlen - len; return newsh->buf; }
#define SDS_MAX_PREALLOC (1024*1024) //定义MAX_PREALLOC
SDS与C的比较
1.获取字符串长度复杂度为常数
在C中,获取char数组的长度时,需要遍历整个数组,直到最后一个。然后使用一个计数器累加。这样的复杂度为O(N)
对于SDS,由于使用len属性保存了字符串长度,所以获取长度的复杂度为O(1).
2.杜绝缓冲区溢出
针对strcat函数,假设需要使用strcat(char *dest,const char * src),将src中的字符串拼接到dest后
在C中,由于没有保存字符串长度,所以strcat假设在用户执行字符串拼接函数时,已经为dest分配了足够的内存,保证能够容纳src中的所有内容,所以一旦假设不成立,就会造成缓冲区溢出。举个例子,假设程序中两个在内存中紧挨着的字符串s1和s2,s1保存了字符串“redis”,s2保存了字符串“mongo”,这时程序员执行strcat(s1,“cluster”),并且在执行前忘了扩展s1的内存空间,这时s2就会被替换为cluster。
在SDS中,拼接字符串的函数为sdscat,由于保存了字符串的长度和剩余的空间,在执行前会先判断当前的空间是否容得下要拼接的字符串长度,如果不符合会执行空间的扩容,扩容后再进行字符串拼接。假设当前s1保存了redis,且剩余空间为0,如下:
这时执行sdscat(s1,"cluster"),sds会先判断剩余的空间是否能够容纳cluster的长度,发现不够,这时SDS会进行扩容,扩容后再进行拼接处理。

如上图所示,SDS不仅对字符串进行了拼接,而且分配了13个字节长的空间,恰好拼接后的长度也是13,这是为什么呢? 和SDS的内存分配策略有关,后面会讲到。
3.减少修改字符串时带来的内存重分配次数
在C中,因为不记录自身字符串的长度,所以对于一个包含N个字符的数组来说,底层实现为N+1长的数组,额外的空间用于保存空字符。基于这种关系,所以在字符串增长或缩短的时候,程序都需要为数组进行一次内存重分配操作,这样对于Redis这种高并发操作是不能忍受的。
在SDS中,会有free属性来记录剩余的空间字节数,字符串长度和数组空间没有任何关联。所以在SDS中,buf数组长度不一定就是字符数+1,里面可能有未使用的字节空间。
通过未使用空间,SDS实现了空间预分配和惰性释放的优化策略。
空间预分配:
用于优化SDS的字符串增长操作,当对一个SDS进行增长修改时,并且需要对SDS空间进行扩展时,程序不仅会分配修改所必须的空间,还会为SDS分配额外未使用的空间,具体策略如下:
- 如果修改后,sds的长度小于1M,那么程序将会分配同样的未使用空间给SDS。这时free和len属性相同。
- 如果修改后,SDS的长度大于等于1M,则会分配1M的空间。
在扩展SDS前,如果内存足够使用,则不需要对内存进行重分配,这样将内存重分配的次数充N次减少到了最多N次。
惰性释放:
惰性释放用于字符串缩短操作,当一个字符串缩短时,并不会立即回收多出来的字节,而是使用使用free属性将这些数保存起来,供后面使用。这样的好处是下次如果再进行增长操作时,不需要再次内存重分配。这样的弊端在哪呢? 很明显,可能会造成内存的浪费。 SDS也提供了相应的API,可以在有需要时,真正释放未使用的空间。
4.保存的二进制文件,安全
C里面保存的是字符串数据,SDS的buf数组保存的是二进制;
比如针对字符串“a b c”,对于C用的函数只能失败a出来,默认任务空为结束符了。而SDS存储格式为二进制,所以无论什么样的格式都不会有影响。
5.能够兼容一部分C的字符串函数
可以使用<string.h>中的一部分函数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号