MySQL高级文章集合
开发时,把测试数据拷贝到本地数据库时,需要把sql_mode也拷贝过来,让配置都一样。
缓存:读信息用的
缓冲:写信息用的
=================================
利用show profile查看sql的执行周期:
1.修改配置文件/etc/my.cnf
新增一行:query_cache_type=1
重启mysql
2.show variables like '%profiling%'
set profiling=1;
3.select * from xxx;
show profiles;显示最近几次查询
更细致的查询是:
show profile cpu,block io for query 2;(其中2代表id)
==================================
行锁会出现死锁
CSV引擎 可以将普通的CSV文件作为MySQL的表来处理,但不支持索引。CSV引擎可以作为一种数据交换机制,非常有用。
MySQL没有全连接,只有Oracle有
===================================================
#列出所有人员和机构的对照关系(AB全有)
#MySQL Full Join的实现,因为MySQL不支持FULL JOIN,所以用#left join+union(可去除重复数据)+right join
select * from t_tmp A left join t_dept B on A.deptId=B.id
union (union或者union all必须保证两个的字段一致还有顺序一致)
select * from t_tmp A right join t_dept B on A.deptId=B.id
====================================================
除了主键是聚簇索引外都是非聚簇索引
====================================================
-
一般我们认为MVCC有下面几个特点:
- 每行数据都存在一个版本,每次数据更新时都更新该版本
- 修改时Copy出当前版本, 然后随意修改,各个事务之间无干扰
- 保存时比较版本号,如果成功(commit),则覆盖原记录, 失败则放弃copy(rollback)
- 就是每行都有版本号,保存时根据版本号决定是否成功,听起来含有乐观锁的味道, 因为这看起来正是,在提交的时候才能知道到底能否提交成功
-
而InnoDB实现MVCC的方式是:
- 事务以排他锁的形式修改原始数据
- 把修改前的数据存放于undo log,通过回滚指针与主数据关联
- 修改成功(commit)啥都不做,失败则恢复undo log中的数据(rollback)
- 二者最本质的区别是: 当修改数据时是否要
排他锁定,如果锁定了还算不算是MVCC?
- Innodb的实现真算不上MVCC, 因为并没有实现核心的多版本共存,
undo log中的内容只是串行化的结果, 记录了多个事务的过程, 不属于多版本共存。但理想的MVCC是难以实现的, 当事务仅修改一行记录使用理想的MVCC模式是没有问题的, 可以通过比较版本号进行回滚, 但当事务影响到多行数据时, 理想的MVCC就无能为力了。 - 比如, 如果事务A执行理想的MVCC, 修改Row1成功, 而修改Row2失败, 此时需要回滚Row1, 但因为Row1没有被锁定, 其数据可能又被事务B所修改, 如果此时回滚Row1的内容,则会破坏事务B的修改结果,导致事务B违反ACID。 这也正是所谓的
第一类更新丢失的情况。 - 也正是因为InnoDB使用的MVCC中结合了排他锁, 不是纯的MVCC, 所以第一类更新丢失是不会出现了, 一般说更新丢失都是指第二类丢失更新
====================================================
一条SQL语句在MySQL中如何执行的 ※
MySQL大表优化方案
MySQL高性能优化规范建议
腾讯面试:一条SQL语句执行得很慢的原因有哪些?---不看后悔系列
为什么索引能提高查询速度
====================================================
一般在保存少量字符串的时候,我们会选择CHAR或者VARCHAR,而在保存较大文本时,通常会选择使用TEXT或者BLOB。二者之间的主要差别是BLOB能用来保存二进制数据,比如照片;而TEXT只能保存字符数据,比如一遍文章或日记。TEXT和BLOB中又分别包括TEXT,MEDIUMTEXT,LONGTEXT和BLOB,MEDIUMBLOB,LONGBLOB三种不同的类型,他们之间的主要区别是存储文本长度不用和存储字节不用,用户应该根据实际情况选择能够满足需求的最小存储类型。
=====================================================
MySQL索引详细介绍
高性能mysql之前缀索引
MYSQL索引:对聚簇索引和非聚簇索引的认识
Mysql中MVCC的使用及原理详解
mysql-覆盖索引
drop、truncate和delete的区别
在mysql中删除数据后,添加数据,id值依然从删除的位置开始增加,问题详解。
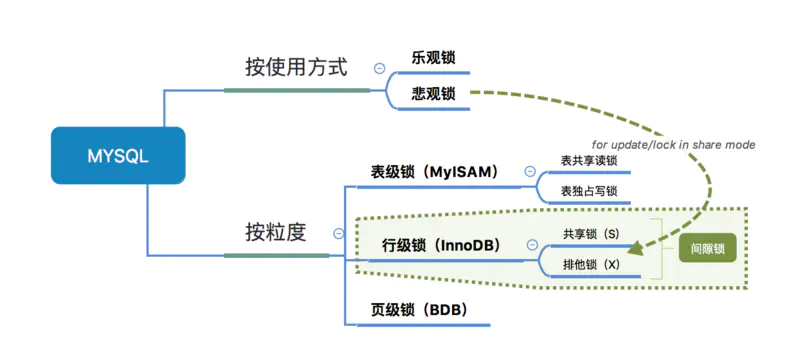
数据库两大神器【索引和锁】
怎么把原先要花费17s执行的SQL优化到300ms
史上最全的 SQL 优化方案
你说对MySQL事务很熟?那我问你10个问题
MySQL的索引是怎么加速查询的?


 浙公网安备 33010602011771号
浙公网安备 33010602011771号