偏置-方差分解(Bias-Variance Decomposition)
本文地址为:http://www.cnblogs.com/kemaswill/,作者联系方式为kemaswill@163.com,转载请注明出处。
机器学习的目标是学得一个泛化能力比较好的模型。所谓泛化能力,是指根据训练数据训练出来的模型在新的数据上的性能。这就牵扯到机器学习中两个非常重要的概念:欠拟合和过拟合。如果一个模型在训练数据上表现非常好,但是在新数据集上性能很差,就是过拟合,反之,如果在训练数据集和新数据集上表现都很差,就是欠拟合,如下图所示
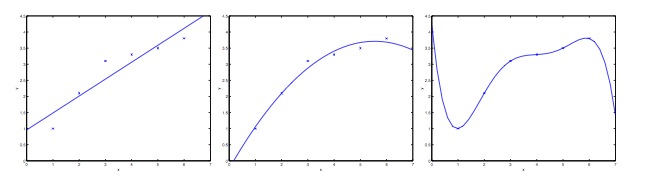
其中蓝叉点表示训练数据,蓝色的线表示学到的模型。左边学到的模型不能很好的描述训练数据,模型过于简单,是欠拟合(Under-fitting)。中间的模型可以比较好的描述训练数据。右边的模型过度的拟合了训练数据(所谓过度,是指训练数据集其实是包含一定的噪声的,如果完全拟合训练数据,会把这些随机噪声也拟合进去),导致模型过于复杂,很可能在新数据集上表现极差,称为过拟合(Over-fitting)。
偏置-方差分解(Bias-Variance Decomposition)是统计学派看待模型复杂度的观点。具体如下:
假设我们有K个数据集,每个数据集都是从一个分布p(t,x)中独立的抽取出来的(t代表要预测的变量,x代表特征变量)。对于每个数据集D,我们都可以在其基础上根据学习算法来训练出一个模型y(x;D)来。在不同的数据集上进行训练可以得到不同的模型。学习算法的性能是根据在这K个数据集上训练得到的K个模型的平均性能来衡量的,亦即:

其中的h(x)代表生成数据的真实函数,亦即t=h(x).
我们可以看到,给定学习算法在多个数据集上学到的模型的和真实函数h(x)之间的误差,是由偏置(Bias)和方差(Variance)两部分构成的。其中偏置描述的是学到的多个模型和真实的函数之间的平均误差,而方差描述的是学到的某个模型和多个模型的平均之间的平均误差(有点绕,PRML上的原话是variance measures the extent to which the solutions for individual data sets vary around their average)。
所以在进行学习时,就会存在偏置和方差之间的平衡。灵活的模型(次数比较高的多项式)会有比较低的偏置和比较高的方差,而比较严格的模型(比如一次线性回归)就会得到比较高的偏置和比较低的方差。下图形象的说明了以上两种情况:
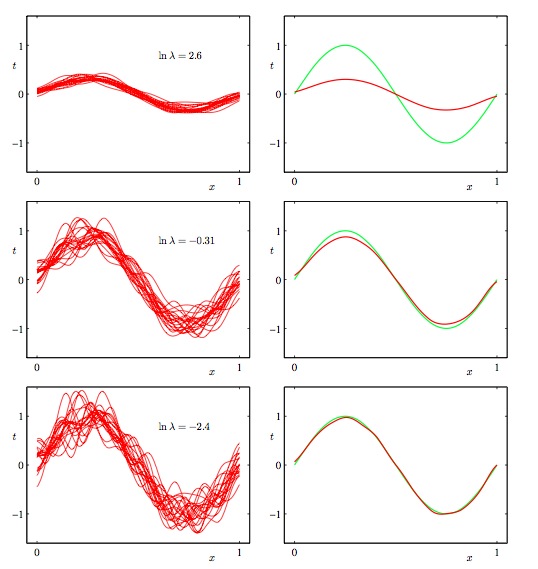
用于训练的是100个数据集,每个数据集包含25个由h(x)=sin(2πx)[右图中的绿线]随机生成的点的。 参数λ控制模型的灵活性(复杂度),λ越大,模型越简单(严格),反之越复杂(灵活)。我们生成多个模型(左图中的红线),并区多个模型的平均值(右图中的红线)。我们可以看到,当λ较大时(最上面的两个图),平均模型比较简单(最上面的右图),不能很好的拟合真实函数h(x),亦即偏差较大,但是多个模型之间比较相似,差距不大,方差较小(最上面的左图)。当λ较小时(最下面的两个图),平均模型能够非常好的拟合真实函数h(x),亦即偏差较小(最下面的右图),但是多个模型之间差距很大,方差比较大(最下面的左图)。
使用Bagging方法可以有效地降低方差。Bagging是一种再抽样方法(resampling),对训练数据进行有放回的抽样K次,生成K份新的训练数据,在这K个新的训练数据上训练得到K个模型,然后使用K个模型的平均来作为新的模型。随机森林(Random Forest)是一种基于Bagging的强大的算法。
造成偏置和方差的原因除了学习方法的不同和参数的不同(比如λ)之外,数据集本身也会对其造成影响。如果训练数据集和新数据集的分布是不同的,会增大偏置。如果训练数据集过少,会增大方差。
偏置-方差分解是统计学派解释模型复杂度的观点,但是其实用价值不大(Bagging也许是一个例外吧~),因为偏置-方差分解是基于多个数据集的,而实际中只会有一个训练数据集,将这个数据集作为一个整体进行训练会比将其划分成多个固定大小的数据集进行训练再取平均的效果要好。
参考文献
[1]. Bishop. PRML(Pattern Recognization and Machine Learning). p11-16
[2]. Understanding the Bias-Variance Decomposition.
[3]. Andrew NG. CS229 Lecture Note1: Supervised Learning, Discrimitive Algorithms


 浙公网安备 33010602011771号
浙公网安备 33010602011771号