《数据分析实战-托马兹.卓巴斯》读书笔记第1章-数据格式与数据交互
 趁着过年宅家,读了托马兹·卓巴斯的《数据分析实战》,2018年6月出版,本系列为读书笔记。主要是为了系统整理,加深记忆。本文主要记录使用python工具及第1 章内容。第1章讲解了利用多种数据格式与数据库来读取与写入数据的过程,以及使用OpenRefine与Python对数据进行清理。
趁着过年宅家,读了托马兹·卓巴斯的《数据分析实战》,2018年6月出版,本系列为读书笔记。主要是为了系统整理,加深记忆。本文主要记录使用python工具及第1 章内容。第1章讲解了利用多种数据格式与数据库来读取与写入数据的过程,以及使用OpenRefine与Python对数据进行清理。
趁着过年宅家,读了托马兹·卓巴斯的《数据分析实战》,2018年6月出版,本系列为读书笔记。主要是为了系统整理,加深记忆。
关于作者
托马兹·卓巴斯(Tomasz Drabas)是微软的数据科学家,目前工作于西雅图。他拥有超过13年的数据分析经验,行业领域覆盖高新技术、航空、电信、金融以及咨询。
2003年,Tomasz获得战略管理的硕士学位后,从位于波兰华沙的LOT波兰航空公司开启了他的职业生涯。2007年,他前往悉尼,在新南威尔士大学航空学院攻读运筹学博士学位;他的研究结合了离散选择模型和航空作业。在悉尼的日子里,他曾担任过Beyond Analysis Australia公司的数据分析师,沃达丰和记澳大利亚公司的高级数据分析师/数据科学家,以及其他职位。他也发表过学术论文,参加过国际会议,并且担任过学术期刊的审稿人。
2015年,他搬到西雅图,开始在微软工作。在这里他致力于解决高维特征空间的问题。
本书深入数据分析与建模的世界,使用多种方法、工具及算法,提供了丰富的技巧。
本书第 一部分会讲授一些实战技巧,用于读取、写入、清洗、格式化、探索与理解数据;第二部分由一些较深入的主题组成,比如分类、聚类和预测等。第三部分介绍更高深的主题,从图论到自然语言处理,到离散选择模型,再到模拟。
通过阅读本书,你将学到:
- 使用Pandas与OpenRefine读取、清洗、转换与存储数据
- 使用Pandas与D3.js理解数据,探索变量间的关系
- 使用Pandas、mlpy、NumPy与Statsmodels,应用多种技法,分类、聚类银行的营销电话
- 使用Pandas、NumPy与mlpy减少数据集的维度,提取重要的特征
- 使用NetworkX和Gephi探索社交网络的交互,用图论的概念识别出欺诈行为
- 通过加油站的例子,学习代理人基建模的模拟技术
第1章讲解了利用多种数据格式与数据库来读取与写入数据的过程,以及使用OpenRefine与Python对数据进行清理。
第2章描述了用于理解数据的多种技巧。我们会了解如何计算变量的分布与相关性,并生成多种图表。
第3章介绍了处理分类问题的种种技巧,从朴素贝叶斯分类器到复杂的神经网络和随机树森林。
第4章解释了多种聚类模型;从最常见的k均值算法开始,一直到高级的BIRCH算法和DBSCAN算法。
第5章展示了很多降维的技巧,从最知名的主成分分析出发,经由其核版本与随机化版本,一直讲到线性判别分析。
第6章涵盖了许多回归模型,有线性的,也有非线性的。我们还会复习随机森林和支持向量机,它们可用来解决分类或回归问题。
第7章探索了如何处理和理解时间序列数据,并建立ARMA模型以及ARIMA模型。
第8章介绍了如何使用NetworkX和Gephi来对图数据进行处理、理解、可视化和分析。
第9章描述了多种与分析文本信息流相关的技巧:词性标注、主题抽取以及对文本数据的分类。
第10章解释了选择模型理论以及一些流行的模型:多项式Logit模型、嵌套Logit模型以及混合Logit模型。
第11章涵盖了代理人基的模拟;我们模拟的场景有:加油站的加油过程,电动车耗尽电量以及狼——羊的掠食。
本文主要记录使用python工具及第1 章内容。
(一)使用工具
1、本人使用python 3.7.5,64位,可官方下载。https://www.python.org/getit/
2、IDE书中推荐使用Anaconda
Anaconda 官方下载 https://www.anaconda.com/distribution/#download-section
注:如果想直接使用全书示例,请使用该版本。如果想学习各个组件的部署,请参照书中指示手工配置各个组件。
Anaconda 是Python的一个发行版,里面内置了很多工具,不用单独安装,因为做了优化也免去了单独安装带来的一些麻烦。
Anaconda 是一种Python语言的免费增值开源发行版,用于进行大规模数据处理、预测分析,和科学计算,致力于简化包的管理和部署。
下载安装过程时不要添加到Path变量,Anaconda会自动搜索你本机已经安装的python版本。
国内镜像下载
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
Spyder是简单高效的IDE,Spyder是Python(x,y)的作者为它开发的一个简单的集成开发环境。和其他的Python开发环境相比,它最大的优点就是模仿MATLAB的“工作空间”的功能,可以很方便地观察和修改数组的值。
个人感觉:
1)普通的笔记本配置运行Anaconda有点吃力,内存专给它4G还好,主要的是硬盘和CPU,明显听到SATA物理硬盘嘎嘎响(后改到SSD分区好些),启动时CPU会近60%。
2)Anaconda+spyder比通用的Eclipse+pyDev要专业的多,当然后者的项目管理功能更强。
邀月推荐:新手用Anaconda即可。毕竟集成了spyder,其中spyder建议手动升级到4.0以上或最新版本。本人钟爱Eclipse,所以使用Eclipse2019-09版本。
3、PIP国内镜像(主要解决域外服务器不稳定,你一定懂的。)
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
设置方法:(以清华镜像为例,其它镜像同理)
(1)临时使用:
可以在使用 pip 的时候,加上参数-i和镜像地址(如https://pypi.tuna.tsinghua.edu.cn/simple),
例如:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas,这样就会从清华镜像安装pandas库。
(2)永久修改,一劳永逸:
(a)Linux下,修改 ~/.pip/pip.conf (没有就创建一个文件夹及文件。文件夹要加“.”,表示是隐藏文件夹)
内容如下:
[global] index-url = https://pypi.tuna.tsinghua.edu.cn/simple [install] trusted-host = https://pypi.tuna.tsinghua.edu.cn
(b) windows下,直接在user目录中创建一个pip目录,如:C:\Users\xx\pip,然后新建文件pip.ini,即 %HOMEPATH%\pip\pip.ini,在pip.ini文件中输入以下内容(以清华镜像为例):
[global] index-url = https://pypi.tuna.tsinghua.edu.cn/simple [install] trusted-host = https://pypi.tuna.tsinghua.edu.cn
4、如果不喜欢pip,可以使用conda,本文不赘述,同样要注意设置清华镜像站点。
本人使用win10及以上环境,编译过了书中96%以上的代码,其中报错处,后续文中详述。本文末尾附上随书源代码下载地址。
(二)第1 章内容:
第1章 准备数据
本章内容涵盖了使用Python和OpenRefine来完成读取、存储和清理数据这些基本任务。你将学习以下内容:
·使用Python读写CSV/TSV文件
·使用Python读写JSON文件
·使用Python读写Excel文件
·使用Python读写XML文件
·使用pandas检索HTML页面
·存储并检索关系数据库
·存储并检索MongoDB
·使用OpenRefine打开并转换数据
·使用OpenRefine探索数据
·排重
·使用正则表达式与GREL清理数据
·插补缺失值
·将特性规范化、标准化
·分级数据
·编码分类变量
1.2使用python读取CSV/TSV文件
独立安装 pandas
pip install pandas
官方文档在这里:
https://pandas.pydata.org/pandas-docs/stable/
/* Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple ........ Installing collected packages: pytz, numpy, python-dateutil, pandas Successfully installed numpy-1.17.4 pandas-0.25.3 python-dateutil-2.8.1 pytz-2019.3 FINISHED */
读取CSV:
https://pandas.pydata.org/pandas-docs/stable/user_guide/io.html#io-read-csv-table
padas读取大容量数据的速度,不得不赞一下。
Tips:
1、python3 写CSV文件多一个空行
解决方案:打开文件的时候多指定一个参数。
#write to files with open(w_filenameCSV,'w',newline='') as write_csv: write_csv.write(tsv_read.to_csv(sep=',', index=False))
1.3使用python读取JSON文件
独立安装 pandas 同上,略
读取CSV:
https://pandas.pydata.org/pandas-docs/stable/user_guide/io.html#io-json-reader
1.4使用python读取Excel文件
独立安装 pandas 同上,略
Tips:
/* Module Not Found Error: No module named 'openpyxl' */
解决方案:pip install openpyxl
Tips2:
/* Traceback (most recent call last): File "D:\Java2018\practicalDataAnalysis\Codes\Chapter01\read_xlsx_alternative.py", line 16, in <module> labels = [cell.value for cell in xlsx_ws.rows[0]] TypeError: 'generator' object is not subscriptable */
解决方案:
1、改代码
# name of files to read from r_filenameXLSX = '../../Data/Chapter01/realEstate_trans.xlsx' # open the Excel file xlsx_wb = oxl.load_workbook(filename=r_filenameXLSX) # extract the 'Sacramento' worksheet xlsx_ws = xlsx_wb.active #默认第一个sheet labels=[] for row in xlsx_ws.iter_cols(min_row=1,max_row=1): labels+=([cell.value for cell in row]) # extract the data and store in a list # each element is a row from the Excel file data = [] for row in xlsx_ws.iter_rows(min_row=1,max_col=10, max_row=10): data.append([cell.value for cell in row]) ###print the prices of the first 10 properties print( [item[labels.index('price')] for item in data[0:10]] )
2、修改openpyxl版本
pip install -I openpyxl==2.3.3
3、采用其他插件如xlrd
# name of files to read from r_filenameXLSX = '../../Data/Chapter01/realEstate_trans.xlsx' try: # 打开文件 xlsx_wb = exls.open_workbook(r_filenameXLSX) #sheet2_name = workbook.sheet_names() # 获取所有sheet名称 #print(sheet2_name) # 根据sheet索引或者名称获取sheet内容 xlsx_ws = xlsx_wb.sheet_by_index(0) # sheet索引从0开始 # sheet1 = workbook.sheet_by_name('sheet2') # sheet1的名称,行数,列数 print("sheet名:"+xlsx_ws.name, "共",str(xlsx_ws.nrows)+"行", str(xlsx_ws.ncols)+"列") s=""; labels=xlsx_ws.row_values(0,1,10) data=[] # first 10 rows of xlsx_ws.nrows for rownum in range(0, 10): #first 10 columns of xlsx_ws.ncols data.append(xlsx_ws.row_values(rownum,1,10)) # print(labels) # print(data) print( [item[labels.index('price')] for item in data[0:10]] ) except Exception as e: print(e)
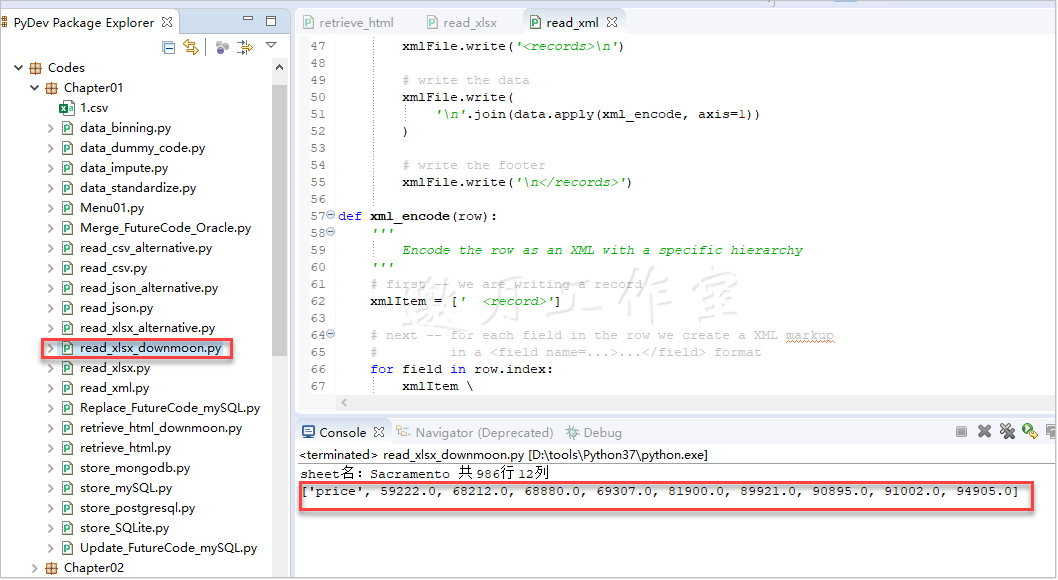
1.5使用python读取XML文件
独立安装 pandas 同上,略
1.6使用python读取html文件
独立安装 pandas 同上,略
独立安装 re 正则表达式模块
pip install html5lib
/* Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple ........ Installing collected packages: webencodings, html5lib Successfully installed html5lib-1.0.1 webencodings-0.5.1 FINISHED */
Tips:ImportError: lxml not found, please install it
/* File "D:\tools\Python37\lib\site-packages\pandas\io\html.py", line 843, in _parser_dispatch raise ImportError("lxml not found, please install it") ImportError: lxml not found, please install it */
解决方案:pip install lxml
Tips:ImportError: BeautifulSoup4 (bs4) not found, please install it
/* File "D:\tools\Python37\lib\site-packages\pandas\io\html.py", line 837, in _parser_dispatch raise ImportError("BeautifulSoup4 (bs4) not found, please install it") ImportError: BeautifulSoup4 (bs4) not found, please install it */
解决方案:pip install BeautifulSoup4
示例:
https://programtalk.com/python-examples/pandas.read_html/
1.7存储并检索关系数据库
独立安装 pandas 同上,略
独立安装 sqlalchemy,psycopg2
pip install sqlalchemy #pip install psycopg2
sqlalchemy支持各特别是常见数据库,比如mySQL,Oracle,SqlLite,PostgreSQL等


1 /* 2 Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple 3 ........ 4 Installing collected packages: sqlalchemy 5 Successfully installed sqlalchemy-1.3.11 6 FINISHED 7 8 9 Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple 10 Collecting psycopg2 11 Downloading https://pypi.tuna.tsinghua.edu.cn/packages/1a/85/853f11abfccfd581b099e5ae5f2dd807cc2919745b13d14e565022fd821c/psycopg2-2.8.4-cp37-cp37m-win_amd64.whl (1.1MB) 12 Installing collected packages: psycopg2 13 Successfully installed psycopg2-2.8.4 14 FINISHED 15 16 17 18 D:\tools\Python37\lib\site-packages\dateutil\parser\_parser.py:1218: UnknownTimezoneWarning: tzname EDT identified but not understood. Pass `tzinfos` argument in order to correctly return a timezone-aware datetime. In a future version, this will raise an exception. 19 category=UnknownTimezoneWarning) 20 index street city ... price latitude longitude 21 0 0 3526 HIGH ST SACRAMENTO ... 59222 38.631913 -121.434879 22 1 1 51 OMAHA CT SACRAMENTO ... 68212 38.478902 -121.431028 23 2 2 2796 BRANCH ST SACRAMENTO ... 68880 38.618305 -121.443839 24 3 3 2805 JANETTE WAY SACRAMENTO ... 69307 38.616835 -121.439146 25 4 4 6001 MCMAHON DR SACRAMENTO ... 81900 38.519470 -121.435768 26 27 [5 rows x 13 columns] */
1.8存储并检索MongoDB
独立安装 pandas 同上,略
独立安装 PyMongo
pip install --upgrade PyMongo
1.9使用OpenRefine打开并转换数据
下载:https://github.com/OpenRefine/OpenRefine/releases
(substring(value,4,10)+','+substring(value,24,29)).toDate()
1.10使用OpenRefine探索数据
1.11排重
1.12使用正则表达式与GREL清理数据
--value.match(/(.*)(..)(\d{5})/)[0],注意空格
value.match(/(.*) (..) (\d{5})/)[0]--city
value.match(/(.*) (..) (\d{5})/)[1]--State
value.match(/(.*) (..) (\d{5})/)[2]--zip
1.13插补缺失值
# impute mean in place of NaNs #估算平均数以替代空值 csv_read['price_mean'] = csv_read['price'] \ .fillna( csv_read.groupby('zip')['price'].transform('mean') ) # impute median in place of NaNs #估算中位数以替代空值 csv_read['price_median'] = csv_read['price'] \ .fillna( csv_read.groupby('zip')['price'].transform('median') )
1.14将特征规范化、标准化
- 数据规范化:让所有的数都落在0与1的范围内(闭区间)
- 数据标准化:移动其分布,使得数据的平均数是0,标准差是1
规范化数据,即让每个值都落在0和1之间,我们减去数据的最小值,并除以样本的范围。统计学上的范围指的是最大值与最小值的差。normalize(...)方法就是做的前面描述的工作:对数据的集合,减去最小值,除以范围。
标准化的过程类似:减去平均数,除以样本的标准差。这样,处理后的数据,平均数为0而标准差为1。standardize(...)方法做了这些处理:
def normalize(col): #Normalize column 规范化 return (col - col.min()) / (col.max() - col.min()) def standardize(col): #Standardize column 标准化 return (col - col.mean()) / col.std()
1.15分级数据
当我们想查看数据分布的形状,或将数据转换为有序的形式时,数据分级就派上用场了。
独立安装 pandas 同上,略
独立安装 Numpy
pip install numpy
分位数与百分位数有紧密的联系。区别在于百分位数返回的是给定百分数的值(即间隔均匀),而分位数返回的是给定分位点的值(即数目大致相等)。
想了解更多,可访问https://www.stat.auckland.ac.nz/~ihaka/787/lectures-quantiles-handouts.pdf
1)以下代码取百分位数:
# 根据线性划分的价格的范围,创建间隔相等的价格容器 # 示例linspace(0,6,6)==>[0,,1.2,,2.4,,3.6,,4.8,,6.0] bins = np.linspace( csv_read['price_mean'].min(), csv_read['price_mean'].max(), 6 ) # and apply the bins to the data # 将容器应用到数据上,digitize第一个参数是要分级的列,第二个参数是容器的数组 csv_read['b_price'] = np.digitize( csv_read['price_mean'], bins ) # print out the counts for the bins # 每个容器中的记录计数 counts_b = csv_read['b_price'].value_counts() print(counts_b.sort_index())
有时候我们不会用均匀间隔的值,我们会让每个箱中拥有相同的数目。要达成这个目标,我们可以使用分位数。
我们想把列拆成十分位数,即10个(差不多)相等的容器。要做到这点,我们可以使用下面的代码:
# create bins based on deciles # 创建基于十分位数的箱子,即每个箱中拥有差不多相同的数目 decile = csv_read['price_mean'].quantile(np.linspace(0,1,11)) # and apply the decile bins to the data # 对数据应用分数位 csv_read['p_price'] = np.digitize( csv_read['price_mean'], decile ) # print out the counts for the percentile bins counts_p = csv_read['p_price'].value_counts() print(counts_p.sort_index())
. quantile(...)方法可以传一个(0到1之间的)数字,来表明要返回的分位数(例如,0.5是中位数,0.25和0.75是上下四分位数)。它也可以传入一个分位的列表,返回相应的值的数组。.linspace(0,1,11)方法会生成这个数组:.quantile(...)方法会以price_mean列的最小值开始,直到最大值,返回十分位数的列表。
/* 1 350 2 480 3 118 4 26 5 4 6 3 Name: b_price, dtype: int64 1 96 2 100 3 98 4 98 5 97 6 97 7 99 8 97 9 99 10 97 11 3 Name: p_price, dtype: int64 */
1.16编码数据变量
最后一步就是分类变量。
统计模型只能接受有序的数据。分类变量(有时根据上下文可表示为数字)不能直接在模型中使用。要使用它们,我们要先进行编码,也就是给它们一个唯一的数字编号。
Tips:
# dummy code the column # 根据房产类型列[type]处理的简单代码 # prefix指定以d开头,本例中是d_Condo,可通过prefix_sep参数修改 csv_read = pd.get_dummies( csv_read, prefix='d', columns=['type'] )
结果生成4个水平列:
d_Condo、d_Multi-Family、d_Residential、d_Unkown
官方文档:http://pandas.pydata.org/pandas-docs/stable/generated/pandas.get_dummies.html
第1 章完。
随书源码官方下载:
http://www.hzcourse.com/web/refbook/detail/7821/92

 浙公网安备 33010602011771号
浙公网安备 33010602011771号