机器学习算法整理(五)决策树_随机森林——鹃尾花实例 Python实现
以下均为自己看视频做的笔记,自用,侵删!
还参考了:http://www.ai-start.com/ml2014/
In [8]:
%matplotlib inline
import pandas as pd
import matplotlib.pylab as plt
iris_data = pd.read_csv('iris.data')
iris_data.columns = ['sepal_length_cm', 'sepal_width_cm', 'petal_length_cm', 'petal_width_cm', 'class']
iris_data.head()
Out[8]:
In [9]:
from PIL import Image
img = Image.open('test.jpg')
plt.imshow(img)
plt.show()

In [10]:
iris_data.describe()
Out[10]:
画出每个种类的分布
In [12]:
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sb
# pairplot传入的数据不能有缺失值
sb.pairplot(iris_data.dropna(), hue='class')
Out[12]:

In [13]:
plt.figure(figsize=(10, 10))
# 列名的索引,改列名
for column_index, column in enumerate(iris_data.columns):
if column == 'class':
continue
plt.subplot(2, 2, column_index + 1)
sb.violinplot(x='class', y=column, data=iris_data)

划分训练集和测试集
In [15]:
from sklearn.cross_validation import train_test_split
all_inputs = iris_data[['sepal_length_cm', 'sepal_width_cm',
'petal_length_cm', 'petal_width_cm']].values
all_classes = iris_data['class'].values
(training_inputs,
testing_inputs,
training_classes,
testing_classes) = train_test_split(all_inputs, all_classes, train_size=0.75, random_state=1)
构建决策树模型
In [19]:
from sklearn.tree import DecisionTreeClassifier
# 1.criterion gini or entropy 评判标准
# 2.splitter best or random 前者是在所有特征中找最好的切分点 后者是在部分特征中(数据量大的时候)
# 3.max_features None(所有),log2,sqrt,N 特征小于50的时候一般使用所有的
# 4.max_depth 数据少或者特征少的时候可以不管这个值,如果模型样本量多,特征也多的情况下,可以尝试限制下(预剪枝)
# 5.min_samples_split 如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分
# 如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。(停止的操作)
# 6.min_samples_leaf 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被
# 剪枝,如果样本量不大,不需要管这个值,大些如10W可是尝试下5
# 7.min_weight_fraction_leaf 这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起
# 被剪枝默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,
# 或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。
# 8.max_leaf_nodes 通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。
# 如果加了限制,算法会建立在最大叶子节点数内最优的决策树。
# 如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制
# 具体的值可以通过交叉验证得到。
# 9.class_weight 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多
# 导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重
# 如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。
# 10.min_impurity_split 这个值限制了决策树的增长,如果某节点的不纯度
# (基尼系数,信息增益,均方差,绝对差)小于这个阈值
# 则该节点不再生成子节点。即为叶子节点 。(用的比较多)
decision_tree_classifier = DecisionTreeClassifier()
# Train the classifier on the training set
decision_tree_classifier.fit(training_inputs, training_classes)
# Validate the classifier on the testing set using classification accuracy
decision_tree_classifier.score(testing_inputs, testing_classes)
Out[19]:
In [28]:
from sklearn.cross_validation import cross_val_score
import numpy as np
decision_tree_classifier = DecisionTreeClassifier()
# cross_val_score returns a list of the scores, which we can visualize
# to get a reasonable estimate of our classifier's performance
cv_scores = cross_val_score(decision_tree_classifier, all_inputs, all_classes, cv=10)
print(cv_scores)
#kde=False
sb.distplot(cv_scores, kde=False)
plt.title('Average score: {}'.format(np.mean(cv_scores)))
Out[28]:

In [29]:
decision_tree_classifier = DecisionTreeClassifier(max_depth=1)
cv_scores = cross_val_score(decision_tree_classifier, all_inputs, all_classes, cv=10)
print (cv_scores)
sb.distplot(cv_scores, kde=False)
plt.title('Average score: {}'.format(np.mean(cv_scores)))
Out[29]:

In [30]:
from sklearn.grid_search import GridSearchCV
from sklearn.cross_validation import StratifiedKFold
decision_tree_classifier = DecisionTreeClassifier()
parameter_grid = {'max_depth': [1, 2, 3, 4, 5],
'max_features': [1, 2, 3, 4]}
cross_validation = StratifiedKFold(all_classes, n_folds=10)
grid_search = GridSearchCV(decision_tree_classifier,
param_grid=parameter_grid,
cv=cross_validation)
grid_search.fit(all_inputs, all_classes)
print('Best score: {}'.format(grid_search.best_score_))
print('Best parameters: {}'.format(grid_search.best_params_))
In [31]:
grid_visualization = []
for grid_pair in grid_search.grid_scores_:
grid_visualization.append(grid_pair.mean_validation_score)
grid_visualization = np.array(grid_visualization)
grid_visualization.shape = (5, 4)
sb.heatmap(grid_visualization, cmap='Blues')
plt.xticks(np.arange(4) + 0.5, grid_search.param_grid['max_features'])
plt.yticks(np.arange(5) + 0.5, grid_search.param_grid['max_depth'][::-1])
plt.xlabel('max_features')
plt.ylabel('max_depth')
Out[31]:

In [32]:
decision_tree_classifier = grid_search.best_estimator_
decision_tree_classifier
Out[32]:
In [33]:
import sklearn.tree as tree
from sklearn.externals.six import StringIO
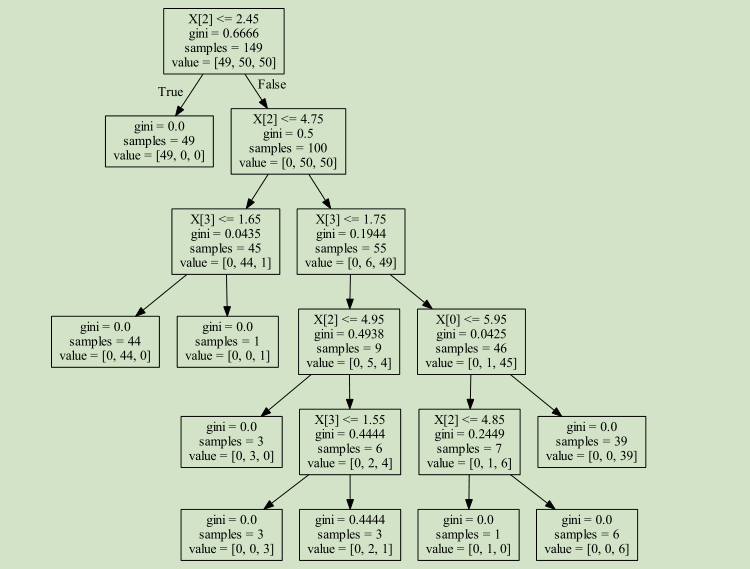
with open('iris_dtc.dot', 'w') as out_file:
out_file = tree.export_graphviz(decision_tree_classifier, out_file=out_file)
#http://www.graphviz.org/
用dot -Tpng -test.png iris_dtc.dot 生成下面的图片
In [34]:
from sklearn.ensemble import RandomForestClassifier
random_forest_classifier = RandomForestClassifier()
parameter_grid = {'n_estimators': [5, 10, 25, 50],
'criterion': ['gini', 'entropy'],
'max_features': [1, 2, 3, 4],
'warm_start': [True, False]}
cross_validation = StratifiedKFold(all_classes, n_folds=10)
grid_search = GridSearchCV(random_forest_classifier,
param_grid=parameter_grid,
cv=cross_validation)
grid_search.fit(all_inputs, all_classes)
print('Best score: {}'.format(grid_search.best_score_))
print('Best parameters: {}'.format(grid_search.best_params_))
grid_search.best_estimator_
Out[34]:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号