论文阅读(11)RoBERTa: A Robustly Optimized BERT Pretraining Approach(2019)
RoBERTa: A Robustly Optimized BERT Pretraining Approach(一种鲁棒优化的 BERT预训练方法)
细读,半天
Motivation
目前自训练方法例如Elmo,GPT,Bert,XLNet在NLP领域取得了很不错的成绩,但是要确定哪些方法对效果的提升贡献最为明显,这是比较困难的。
这主要是因为以下几个原因:
-
第一是因为训练成本比较高,要对模型进行彻底的调优成本很高;
-
第二是因为我们在进行训练的时候通常是在不同大小的私有训练数据上进行的,限制了对模型效果的评测。
基于以上问题,作者重新研究了Bert的预训练机制,评估了超参 和 训练集大小对效果影响。
发现了Bert的预训练并不充分,因此作者提出了改进Bert的方法,即,RoBERTa。
解决方法
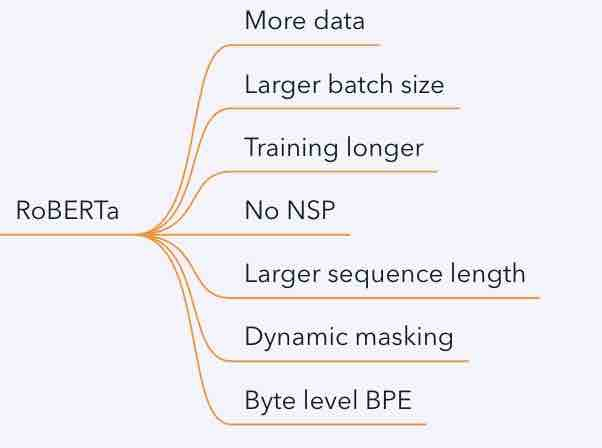
-
使用更大的batch,在更大的数据集上对Bert进行训练
-
不再使用NSP(Next Sentence Prediction)任务
-
使用更长的序列进行训练
-
动态调整Masking机制
-
更大的 byte-level BPE
模型结构
-
We keep the model architecture fixed.
-
Specifically, we begin by training BERT models with the same configuration as \(BERT_{BASE}\) (L=12, H = 768, A = 12, 110M params).
改进:
1. 静态Masking vs 动态Masking
原始Bert:对每一个序列随机选择15%的Tokens替换成[MASK],为了消除与下游任务的不匹配,还对这15%的Tokens进行
(1)80%的时间替换成[MASK];
(2)10%的时间不变;
(3)10%的时间替换成其他词。但整个训练过程,这15%的Tokens一旦被选择就不再改变,也就是说从一开始随机选择了这15%的Tokens,之后的N个epoch里都不再改变了。这就叫做静态Masking。
RoBERTa: 一开始把预训练的数据复制10份,每一份都随机选择15%的Tokens进行Masking,也就是说,同样的一句话有10种不同的mask方式。
然后每份数据(同一个mask)都训练N/10个epoch。这就相当于在这N个epoch的训练中,每个序列的被mask的tokens是会变化的。这就叫做动态Masking。
N = N * 10
for epoch in range(epoches):
for step in range(N / 10): # 按每次都是全部数据 来理解
对mask1训练
.....
for step in range(N / 10):
对mask10训练
那么这样改变是否真的有效果?作者在只将静态Masking改成动态Masking,其他参数不变的情况下做了实验,动态Masking确实能提高性能。

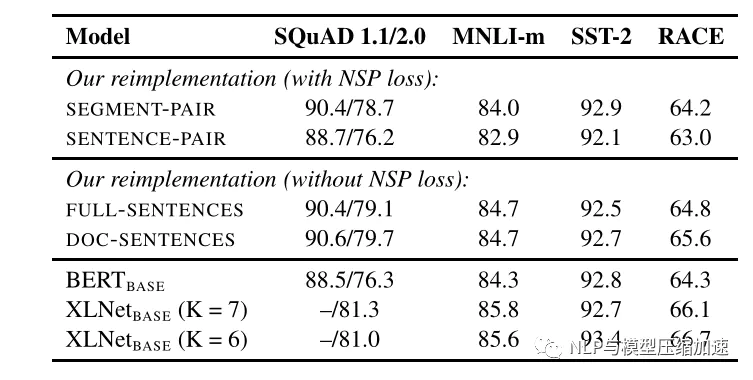
2. with NSP vs without NSP
原始的Bert:为了捕捉句子之间的关系,使用了NSP任务进行预训练,就是输入一对句子A和B,判断这两个句子是否是连续的。在训练的数据中,50%的B是A的下一个句子,50%的B是随机抽取的。
RoBERTa:去除了NSP,而是每次输入连续的多个句子,直到最大长度512(可以跨文章)。这种训练方式叫做(FULL-SENTENCES),而原来的Bert每次只输入两个句子。实验表明在MNLI这种推断句子关系的任务上RoBERTa也能有更好性能。
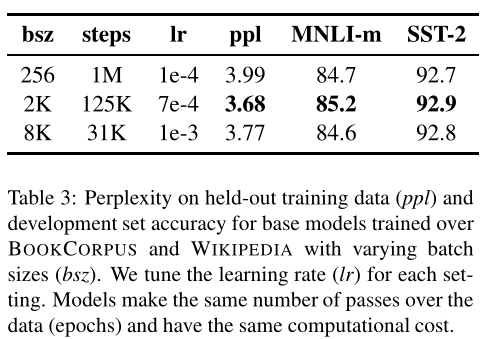
3. 更大的mini-batch
原始的\(BERT_{base}\): batch size 是 256,训练 1M 个steps。
RoBERTa: batch size 为 8k。为什么要用更大的batch size呢?作者借鉴了在机器翻译中,用更大的batch size配合更大学习率能提升模型优化速率 和 模型性能的现象,并且也用实验证明了确实Bert还能用更大的batch size。
4. Text Encoding
- BPE:使用字节可以学习一个中等大小(50K units)的子单词词汇表,它仍然可以编码任何输入文本,而不会引入任何“un-known”标记。
5. 更多的数据,更长时间的训练
借鉴XLNet用了比Bert多10倍的数据,RoBERTa也用了更多的数据。性能确实再次彪升。当然,也需要配合更长时间的训练。

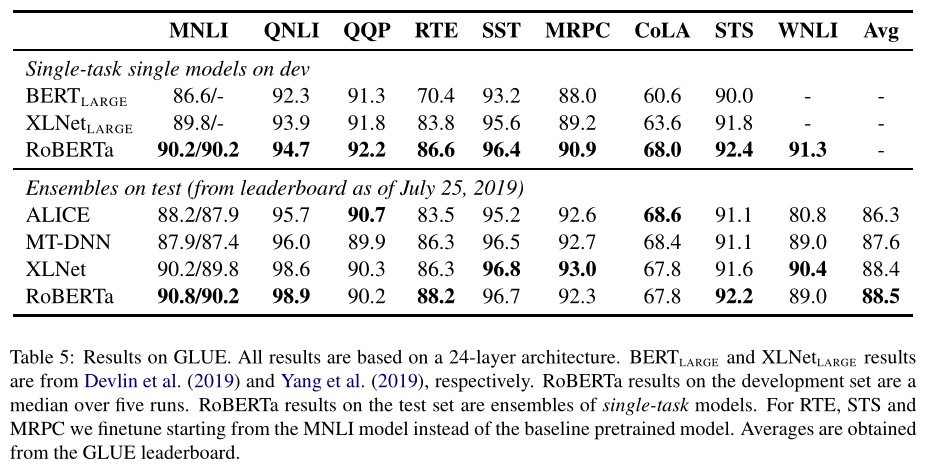
实验结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号