Pytorch-从零开发NLP聊天机器人
1. 聊天机器人综合介绍
1.1 知识点
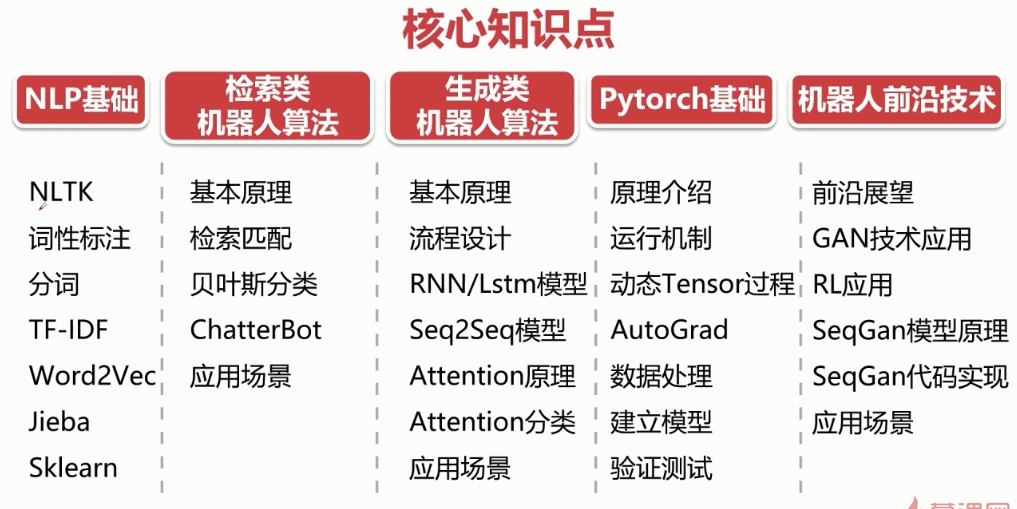
1.2 聊天机器人分类
1.21 从领域划分
- 固定领域(技术支持)
- 固定领域(天气查询)
- 开放领域(娱乐助手)
1.22 从模式划分
- 检索模式

应用:

简单原理:

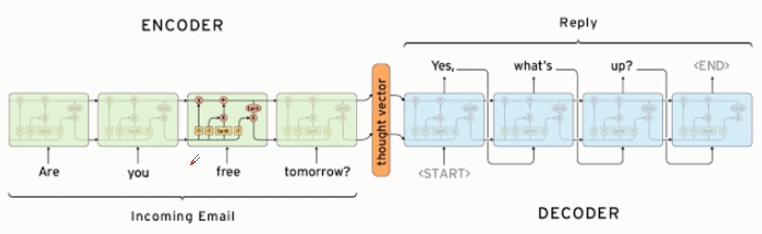
- 生成模式

应用:
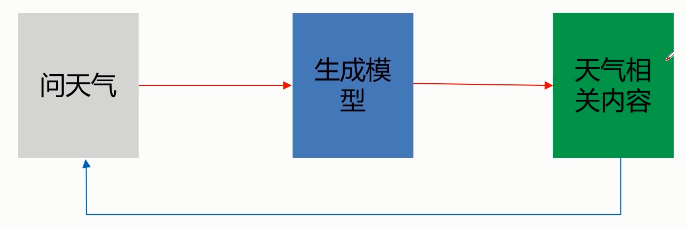
简单原理:
1.23 从功能划分
-
问答型聊天机器人
-
任务型聊天机器人
-
闲聊型聊天机器人
1.3 如何构建最简单的聊天机器人
1.31 基于规则的简单聊天机器人
- 应用

- 原理
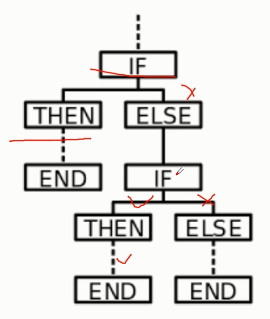
- 实现方法及环境
python3.7
notebook
nltk
pytorch 1.4
- rule-base机器人
from nltk import word_tokenize
import random
# 打招呼
greetings = ['hola', 'hello', 'hi', 'Hi', 'hey!','hey']
# 回复打招呼
random_greeting = random.choice(greetings)
# 对于“假期”的话题关键词
question = ['break','holiday','vacation','weekend']
# 回复假期话题
responses = ['It was nice! I went to Paris',"Sadly, I just stayed at home"]
# 随机选一个回
random_response = random.choice(responses)
# 机器人跑起来
while True:
userInput = input('>>>')
# 清理一下输入,看看都有哪些词
cleaned_input = word_tokenize(userInput)
# 这里,比较一下关键词,确定他属于哪个问题
# isdisjoint: 是否无交集
if not set(cleaned_input).isdisjoint(greetings):
print(random_greeting)
elif not set(cleaned_input).isdisjoint(question):
print(random_response)
elif userInput == 'bye':
break
else:
print('I did not understand what you said')


我们可以用各种数据库,建立起一套体系,然后通过搜索的方式,来查找答案。
比如,最简单的就是Python自己的graph数据结构来搭建一个“地图”。
依据这个地图,我们可以清楚的找寻从一个地方到另一个地方的路径,
然后作为回答,反馈给用户。
# 建立一个基于目标行业的database
# 比如 这里我们用python自带的graph
graph = {'上海': ['苏州', '常州'],
'苏州': ['常州', '镇江'],
'常州': ['镇江'],
'镇江': ['常州'],
'盐城': ['南通'],
'南通': ['常州']}
# 明确如何找到从A到B的路径
def find_path(start, end, path=[]):
path = path + [start]
if start == end:
return path
if start not in graph:
return None
for node in graph[start]:
if node not in path:
newpath = find_path(node, end, path)
if newpath:
return newpath
return None
print(find_path('上海', "镇江"))
# ['上海', '苏州', '常州', '镇江']
2. NLP基础(分词和提取文本向量)
- NLP领域


- NLP研究难点
单词边界界定
词义的消歧
不规范的输入
句法的模糊性
语言行为与计划
- 词处理
分词
词性标注(Part-of-speech tagging)
- 把分好的词一个一个分类(如, 动词, 形容词,名词)
实体识别
- 名词识别
词义消歧
- 联系上下文
- 语句处理
句法分析(Syntactic Analysis)
- “我去北京天安门”: 主谓分开
语义分析(Senmantic Analysis)
- 句子的理解
机器翻译
语音合成
- 篇章处理
- 自动文摘
- 机器读文章,写出摘要
- 统计语言模型
马尔科夫模型
隐马尔科夫模型
2.1 分词
-
把句子变成词
-
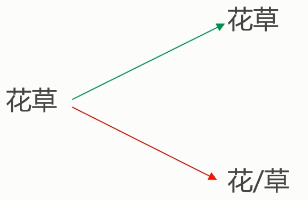
分词难点
- 分词标准
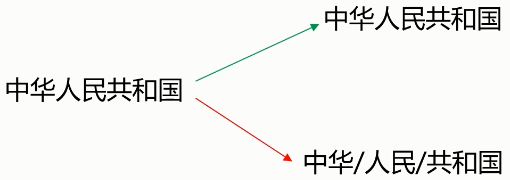
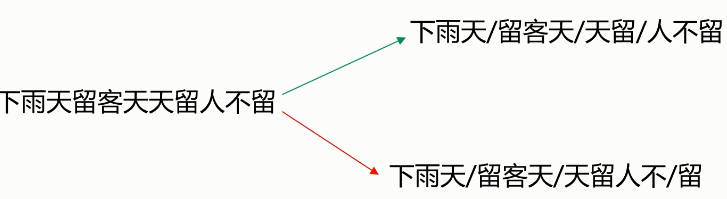
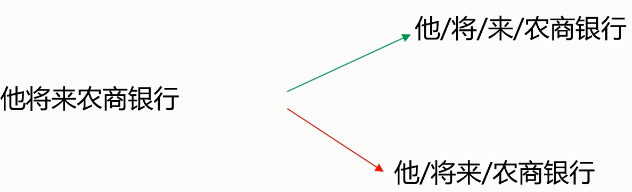
切分歧义(分词造成的语义分歧)
- 分词细粒度不同:
- 真正存在歧义的句子:
- 交集型的歧义
新词
- 给力,花呗,贸易战等等
- 分词的算法
基于词典的分词算法
- 正向最大匹配法
- 逆向最大匹配法
- 双向匹配分词
- 全切分路径选择
基于统计的分词算法
- HMM,隐马尔科夫模型
- CRF,条件随机场
- 深度学习
import jieba
seg_list = jieba.cut('我来到北京清华大学', cut_all=True)
print('Full Mode: ' + '/ '.join(seg_list)) # 全模式
# Full Mode: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
seg_list = jieba.cut('我来到北京清华大学', cut_all=False)
print('Default Mode: ' + '/ '.join(seg_list)) # 精确模式
# Default Mode: 我/ 来到/ 北京/ 清华大学
seg_list = jieba.cut('他来到了网易杭研大厦') # 默认是精确模式
print('/ '.join(seg_list))
# 他/ 来到/ 了/ 网易/ 杭研/ 大厦
# 搜索引擎模式
seg_list = jieba.cut_for_search('小明硕士毕业于中国科学院计算所,后在日本京都大学深造')
print('/ '.join(seg_list))
# 小明/ 硕士/ 毕业/ 于/ 中国/ 科学/ 学院/ 科学院/ 中国科学院/ 计算/ 计算所/ ,/ 后/ 在/ 日本/ 京都/ 大学/ 日本京都大学/ 深造
2.2 TF-IDF
- 这句话非常重要:TF-IDF,是为了抑制在很多文档都出现这个词条的比重!!!(如果在很多文档都促出现了,IDF就低)



-
TF-IDF的作用
- 提取文本向量的特征
-
TF-IDF算法代码示例
import numpy as np # 数值计算、矩阵运算、向量运算
import pandas as pd # 数值分析、科学计算
# 1. 定义数据和预处理
# 定义文档
docA = 'The cat sat on my bed'
docB = 'The dog sat on my knees'
# 切割文档
bowA = docA.split(' ')
bowB = docB.split(' ')
# bowA # ['The', 'cat', 'sat', 'on', 'my', 'bed']
# bowB # ['The', 'dog', 'sat', 'on', 'my', 'knees']
# 构建词库
wordSet = set(bowA).union(set(bowB))
# wordSet # {'The', 'bed', 'cat', 'dog', 'knees', 'my', 'on', 'sat'}
# 2. 进行词数统计
# 用字典来保存词出现的次数
wordDictA = dict.fromkeys(wordSet, 0)
wordDictB = dict.fromkeys(wordSet, 0)
wordDictA
wordDictB
# 遍历文档,统计词数
for word in bowA:
wordDictA[word] += 1
for word in bowB:
wordDictB[word] += 1
pd.DataFrame([wordDictA, wordDictB])
# 3. 计算词频 TF
def computeTF(wordDict, bow):
# 用一个字典对象保存 TF,把所有对应于 bow 文档里的 TF都计算出来
tfDict = {}
nbowCount = len(bow)
for word, count in wordDict.items():
tfDict[word] = count / nbowCount
return tfDict
# 测试
tfA = computeTF(wordDictA, bowA)
tfB = computeTF(wordDictB, bowB)
print(tfA)
print(tfB)
# 4. 计算逆文档频率 IDF
def computeIDF(wordDictList):
# 用一个字典对象保存 IDF,每个词作为 key,初始值为 0
idfDict = dict.fromkeys(wordDictList[0], 0)
# 总文档数量
N = len(wordDictList)
import math
for wordDict in wordDictList:
# 遍历字典中的每个词汇,统计 Ni
for word, count in wordDict.items():
if count > 0 :
# 先把 Ni 增加 1,存入到 idfDict 中
idfDict[word] += 1
# 已经得到所有词汇 i 对应的 Ni,现在根据公式把它替换成 idf 值
for word, Ni in idfDict.items():
idfDict[word] = math.log10((N + 1)/(Ni + 1))
return idfDict
# 测试
idfs = computeIDF([wordDictA, wordDictB])
# 5. 计算 TF-IDF
def computeTFIDF(tf, idfs):
tfidf = {}
for word, tfval in tf.items():
tfidf[word] = tfval * idfs[word]
return tfidf
# 测试
tfidfA = computeTFIDF(tfA, idfs)
tfidfB = computeTFIDF(tfB, idfs)
pd.DataFrame([tfidfA, tfidfB])
# knees cat sat The on dog bed my
# 0 0.000000 0.029349 0.0 0.0 0.0 0.000000 0.029349 0.0
# 1 0.029349 0.000000 0.0 0.0 0.0 0.029349 0.000000 0.0
- scikit-learn计算TF-IDF
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['I come to China to travel',
'This is a car polupar in China',
'I love tea and Apple',
'The work is to write some papers in science']
vectorizer = CountVectorizer()
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))
print(tfidf)
(0, 16) 0.4424621378947393
(0, 15) 0.697684463383976
(0, 4) 0.4424621378947393
(0, 3) 0.348842231691988
(1, 14) 0.45338639737285463
(1, 9) 0.45338639737285463
(1, 6) 0.3574550433419527
(1, 5) 0.3574550433419527
(1, 3) 0.3574550433419527
(1, 2) 0.45338639737285463
(2, 12) 0.5
(2, 7) 0.5
(2, 1) 0.5
(2, 0) 0.5
(3, 18) 0.3565798233381452
(3, 17) 0.3565798233381452
(3, 15) 0.2811316284405006
(3, 13) 0.3565798233381452
(3, 11) 0.3565798233381452
(3, 10) 0.3565798233381452
(3, 8) 0.3565798233381452
(3, 6) 0.2811316284405006
(3, 5) 0.2811316284405006
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer()
corpus=["我 来到 北京 清华大学", # 第一类文本切词后的结果,词之间以空格隔开
"他 来到 了 网易 杭研 大厦", # 第二类文本的切词结果
"小明 硕士 毕业 与 中国 科学院", # 第三类文本的切词结果
"我 爱 北京 天安门"] # 第四类文本的切词结果
result = tfidf.fit_transform(corpus).toarray()
print(result)
# 统计关键词
word = tfidf.get_feature_names()
print(word)
# 统计关键词出现次数,几句话对比几次
for k,v in tfidf.vocabulary_.items():
print(k,v)
# 对比第i类文本的词语tf-idf权重
for i in range(len(result)):
print('----------------------',i,'--------------------')
for j in range(len(word)):
print(word[j],result[i][j])
[[0. 0.52640543 0. 0. 0. 0.52640543
0. 0. 0.66767854 0. 0. 0. ]
[0. 0. 0.52547275 0. 0. 0.41428875
0.52547275 0. 0. 0. 0. 0.52547275]
[0.4472136 0. 0. 0. 0.4472136 0.
0. 0.4472136 0. 0.4472136 0.4472136 0. ]
[0. 0.6191303 0. 0.78528828 0. 0.
0. 0. 0. 0. 0. 0. ]]
['中国', '北京', '大厦', '天安门', '小明', '来到', '杭研', '毕业', '清华大学', '硕士', '科学院', '网易']
来到 5
北京 1
清华大学 8
网易 11
杭研 6
大厦 2
小明 4
硕士 9
毕业 7
中国 0
科学院 10
天安门 3
---------------------- 0 --------------------
中国 0.0
北京 0.5264054336099155
大厦 0.0
天安门 0.0
小明 0.0
来到 0.5264054336099155
杭研 0.0
毕业 0.0
清华大学 0.6676785446095399
硕士 0.0
科学院 0.0
网易 0.0
---------------------- 1 --------------------
中国 0.0
北京 0.0
大厦 0.5254727492640658
天安门 0.0
小明 0.0
来到 0.41428875116588965
杭研 0.5254727492640658
毕业 0.0
清华大学 0.0
硕士 0.0
科学院 0.0
网易 0.5254727492640658
---------------------- 2 --------------------
中国 0.4472135954999579
北京 0.0
大厦 0.0
天安门 0.0
小明 0.4472135954999579
来到 0.0
杭研 0.0
毕业 0.4472135954999579
清华大学 0.0
硕士 0.4472135954999579
科学院 0.4472135954999579
网易 0.0
---------------------- 3 --------------------
中国 0.0
北京 0.6191302964899972
大厦 0.0
天安门 0.7852882757103967
小明 0.0
来到 0.0
杭研 0.0
毕业 0.0
清华大学 0.0
硕士 0.0
科学院 0.0
网易 0.0
- NLTK计算TF-IDF
from nltk.text import TextCollection
corpus = ['I come to China to travel',
'This is a car polupar in China',
'I love tea and Apple',
'The work is to write some papers in science']
corpus = TextCollection(corpus)
# 直接就能算出TF-IDF
print(corpus.tf_idf('China', 'I come to China to travel'))
# 0.027725887222397813
2.3 NLTK

- 示例
import nltk
sentence = """At eight o'clock on Thursday morning
Arthur didn't feel very good.
"""
tokens = nltk.word_tokenize(sentence)
print(tokens)
# ['At', 'eight', "o'clock", 'on', 'Thursday', 'morning', 'Arthur', 'did', "n't", 'feel', 'very', 'good', '.']
# 词性标注
targed = nltk.pos_tag(tokens)
print(targed[0:6])
# [('At', 'IN'), ('eight', 'CD'), ("o'clock", 'NN'), ('on', 'IN'), ('Thursday', 'NNP'), ('morning', 'NN')]
2.4 预料及词性标注
# 中文词性标注, jieba
import jieba.posseg as pseg
words = pseg.cut('我爱北京天安门')
for word, flag in words:
print(word, flag)
# 我 r
# 爱 v
# 北京 ns
# 天安门 ns
3. 文本处理方法
- Word2Vec
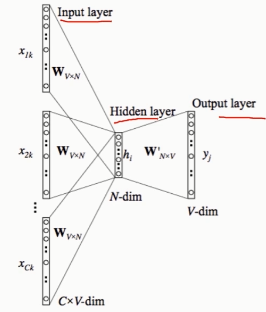
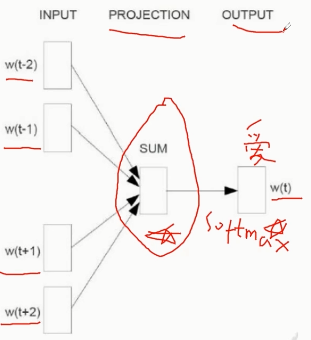
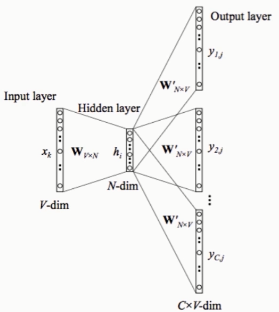
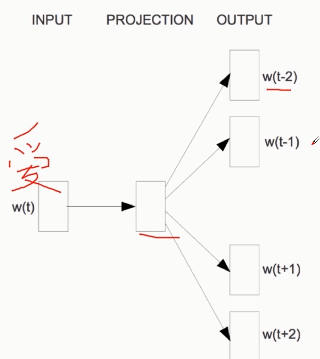
自动过滤某些字或词('the','is','at','which','on'等)
# 1. Getting started with Word2Vec in Gensim and making it work!
# 1.01 Imports and logging
# imports needed and set up logging
import gzip
import gensim
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
# 1.02 Dataset
data_file="reviews_data.txt.gz"
with gzip.open ('reviews_data.txt.gz', 'rb') as f:
for i,line in enumerate (f):
print(line)
break
# b"Oct 12 2009 \tbabababaaba.......\n"
# 1.03 Read files into a list
def read_input(input_file):
"""This method reads the input file which is in gzip format"""
logging.info("reading file {0}...this may take a while".format(input_file))
with gzip.open (input_file, 'rb') as f:
for i, line in enumerate (f):
if (i%10000==0):
logging.info ("read {0} reviews".format (i))
# do some pre-processing and return a list of words for each review text
yield gensim.utils.simple_preprocess (line)
# read the tokenized reviews into a list
# each review item becomes a serries of words
# so this becomes a list of lists
documents = list (read_input (data_file))
logging.info ("Done reading data file")
# gensim.utils.simple_preprocess("I love you. But you don't like me?")
# ['love', 'you', 'but', 'you', 'don', 'like', 'me']
# 1.1 Training the Word2Vec model
model = gensim.models.Word2Vec(documents, size=150, window=10,
min_count=2, workers=10)
model.train(documents, total_examples=len(documents), epochs=10)
# 1.2 验证输出
w1 = "dirty"
model.wv.most_similar (positive=w1)
[('filthy', 0.871721625328064),
# ('stained', 0.7922376990318298),
# ('unclean', 0.7915753126144409),
# ('dusty', 0.7772612571716309),
# ('smelly', 0.7618112564086914),
# ('grubby', 0.7483716011047363),
# ('dingy', 0.7330487966537476),
# ('gross', 0.7239381074905396),
# ('grimy', 0.7228356599807739),
# ('disgusting', 0.7213647365570068)]
# 1.21 Similarity between two words in the vocabulary
# similarity between two different words
model.wv.similarity(w1="dirty",w2="smelly") # 0.76181122646029453
# similarity between two unrelated words
model.wv.similarity(w1="dirty",w2="clean") # 0.25355593501920781
# 1.22 Find the odd one out
# Which one is the odd one out in this list?
model.wv.doesnt_match(["cat","dog","france"]) # 'france'
4. 检索类聊天机器人




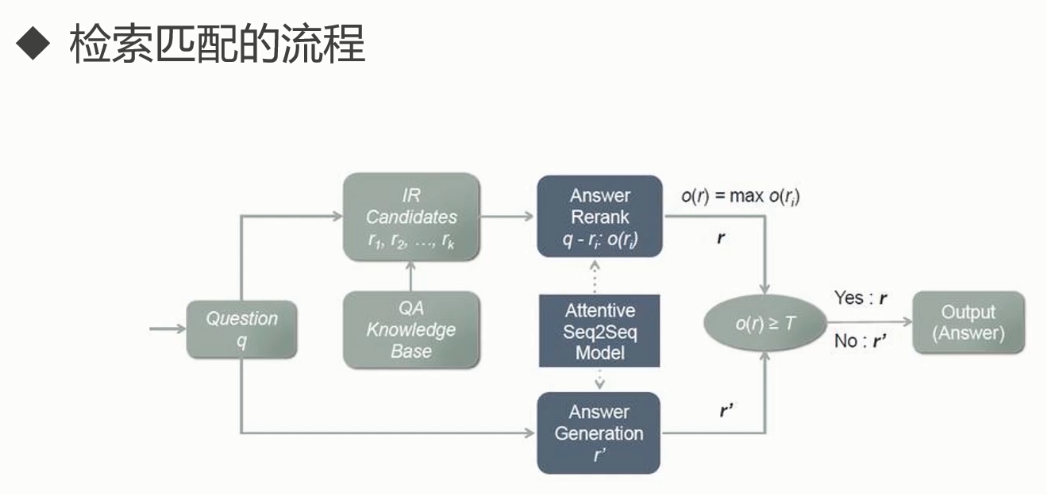
from chatterbot import ChatBot
from chatterbot.trainers import ListTrainer
# Create a new chat bot named Charlie
chatbot = ChatBot(
'Example Bot',
storage_adapter='chatterbot.storage.SQLStorageAdapter',
logic_adapters=[
'chatterbot.logic.BestMatch',
'chatterbot.logic.MathematicalEvaluation',
'chatterbot.logic.TimeLogicAdapter'
],
database_uri='sqlite:///database.db'
)
trainer = ListTrainer(chatbot)
trainer.train([
'How can I help you?',
'I want to create a chat bot',
'Have you read the documentation?',
'No, I have not',
'This should help get you started: http://chatterbot.rtfd.org/en/latest/quickstart.html'
])
trainer.train([
'Hello, how are you?',
'I am great.',
'That is awesome.',
'Thanks'
])
# 给定问题并取回结果
question = "How are you doing today?"
print(question)
response = chatbot.get_response(question)
print(response)
print("\n")
question = 'Have you read the documentation?'
print(question)
response = chatbot.get_response(question)
print(response)
print("\n")
print('What is 7 plus 7?')
response = chatbot.get_response('What is 7 plus 7?')
print(response)
# How are you doing today?
# I am doing well.
# Have you read the documentation?
# No, I have not
# What is 7 plus 7?
# 7 plus 7 = 14
5. 生成类聊天机器人
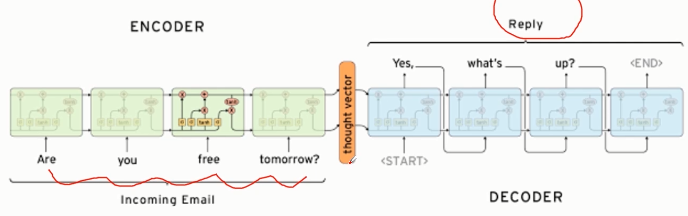
- 语言模型
- Seq2Seq代码练习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号