pytorch练习(一)词向量
1. 创建vocabulary
-
学习词向量的概念
-
用Skip-thought模型训练词向量
-
学习使用PyTorch dataset 和 dataloader
-
学习定义PyTorch模型
-
学习torch.nn中常见的Module
- Embedding
-
学习常见的PyTorch operations
-
bmm
-
logsigmoid
-
-
保存和读取PyTorch模型
训练数据:
链接:https://pan.baidu.com/s/1tFeK3mXuVXEy3EMarfeWvg 密码:v2z5
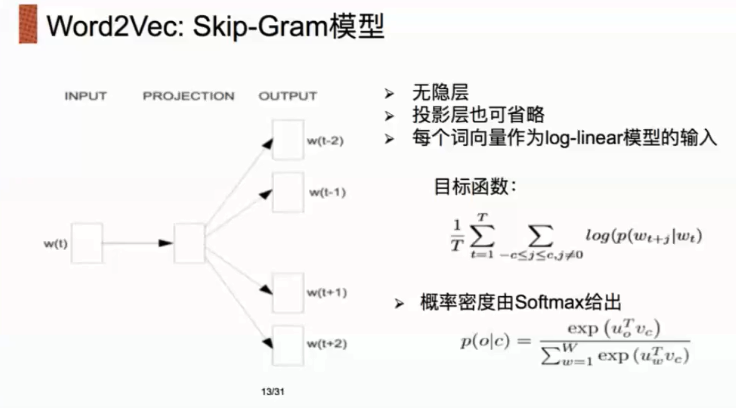
在这一份notebook中,我们会(尽可能)尝试复现论文Distributed Representations of Words and Phrases and their Compositionality中训练词向量的方法.
我们会实现Skip-gram模型,并且使用论文中noice contrastive sampling的目标函数。
以下是一些我们没有实现的细节
- subsampling:参考论文section 2.3

import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as tud
from torch.nn.parameter import Parameter
from collections import Counter
import numpy as np
import random
import math
import pandas as pd
import scipy
import sklearn
from sklearn.metrics.pairwise import cosine_similarity
USE_CUDA = torch.cuda.is_available() #有GPU可以用
# 为了保证实验结果可以复现,我们经常会把各种random seed固定在某一个值
random.seed(53113)
np.random.seed(53113)
torch.manual_seed(53113)
if USE_CUDA:
torch.cuda.manual_seed(53113)
# 设定一些超参数
K = 100 # number of negative samples 负样本随机采样数量
C = 3 # nearby words threshold 指定周围三个单词进行预测
NUM_EPOCHS = 2 # The number of epochs of training 迭代轮数
MAX_VOCAB_SIZE = 30000 # the vocabulary size 词汇表多大
BATCH_SIZE = 128 # the batch size 每轮迭代1个batch的数量
LEARNING_RATE = 0.2 # the initial learning rate #学习率
EMBEDDING_SIZE = 100 # 词向量维度
LOG_FILE = "word-embedding.log"
# tokenize函数,把一篇文本转化成一个个单词
def word_tokenize(text):
return text.split()
-
从文本文件中读取所有的文字,通过这些文本创建一个vocabulary
-
由于单词数量可能太大,我们只选取最常见的MAX_VOCAB_SIZE个单词
-
我们添加一个UNK单词表示所有不常见的单词
-
我们需要记录单词到index的mapping,以及index到单词的mapping,单词的count,单词的(normalized) frequency,以及单词总数。
with open("./text8.train.txt", "r") as fin:
text = fin.read()
text = [w for w in word_tokenize(text.lower())] # 分词,在这里类似于text.split()
vocab = dict(Counter(text).most_common(MAX_VOCAB_SIZE-1)) # 字典格式,把(MAX_VOCAB_SIZE-1)个最频繁出现的单词取出来,-1是留给不常见的单词
vocab["<unk>"] = len(text) - np.sum(list(vocab.values())) # 不常见单词数=总单词数-常见单词数,这里计算的vocab["<unk>"]=29999
idx_to_word = [word for word in vocab.keys()] # 取出字典的所有单词key
word_to_idx = {word:i for i, word in enumerate(idx_to_word)} # 取出所有单词的单词和对应的索引,索引值与单词出现次数相反,最常见单词索引为0。
word_counts = np.array([count for count in vocab.values()], dtype=np.float32) # 所有单词的频数values
word_freqs = word_counts / np.sum(word_counts) # 所有单词的频率
word_freqs = word_freqs ** (3./4.) # 论文里频率乘以3/4次方
word_freqs = word_freqs / np.sum(word_freqs) # 被选作negative sampling的单词概率
VOCAB_SIZE = len(idx_to_word) # 词汇表单词数30000=MAX_VOCAB_SIZE
2. 实现Dataloader
一个dataloader需要以下内容:
-
把所有text编码成数字,然后用subsampling预处理这些文字。
-
保存vocabulary,单词count,normalized word frequency
-
每个iteration sample一个中心词
-
根据当前的中心词,返回context单词
-
根据中心词sample一些negative单词,返回单词的counts
这里有一个好的tutorial介绍如何使用PyTorch dataloader.
为了使用dataloader,我们需要定义以下两个function:
__len__function需要返回整个数据集中有多少个item__get__根据给定的index返回一个item
有了dataloader之后,我们可以轻松随机打乱整个数据集,拿到一个batch的数据等等。
class WordEmbeddingDataset(tud.Dataset): # tud.Dataset父类
def __init__(self, text, word_to_idx, idx_to_word, word_freqs, word_counts):
''' text: a list of words, all text from the training dataset
word_to_idx: the dictionary from word to idx
idx_to_word: idx to word mapping
word_freq: the frequency of each word
word_counts: the word counts
'''
super(WordEmbeddingDataset, self).__init__() # 初始化模型
self.text_encoded = [word_to_idx.get(t, VOCAB_SIZE-1) for t in text] # 取出text里每个单词word_to_idx字典里对应的索引,不在字典里返回"<unk>"的索引,get括号里第二个参数应该写word_to_idx["<unk>"]
self.text_encoded = torch.LongTensor(self.text_encoded) # 变成Longtensor类型
self.word_to_idx = word_to_idx # 以下皆为保存数据
self.idx_to_word = idx_to_word
self.word_freqs = torch.Tensor(word_freqs)
self.word_counts = torch.Tensor(word_counts)
def __len__(self):
''' 返回整个数据集(所有单词)的长度
'''
return len(self.text_encoded)
def __getitem__(self, idx): # 这里__getitem__函数是个迭代器,idx代表了所有的单词索引
''' 这个function返回以下数据用于训练
- 中心词
- 这个单词附近的(positive)单词
- 随机采样的K个单词作为negative sample
'''
center_word = self.text_encoded[idx] # 中心词索引
pos_indices = list(range(idx-C, idx)) + list(range(idx+1, idx+C+1)) # 除中心词外,周围词的索引,比如idx=0时,pos_indices = [-3, -2, -1, 1, 2, 3]
pos_indices = [i%len(self.text_encoded) for i in pos_indices] # idx可能超出词汇总数,需要取余
pos_words = self.text_encoded[pos_indices] # 周围词索引,是正例单词
# 负例采样单词索引
# torch.multinomial:对self.word_freqs做 K * pos_words.shape[0](正确单词数量)次取值,输出的是self.word_freqs对应的下标
# 取样方式采用有放回的采样,并且self.word_freqs数值越大,取样概率越大
neg_words = torch.multinomial(self.word_freqs, K * pos_words.shape[0], True)
return center_word, pos_words, neg_words
创建dataset和dataloader
dataset = WordEmbeddingDataset(text, word_to_idx, idx_to_word,
word_freqs, word_counts)
# dataset[5]
dataloader = tud.DataLoader(dataset, batch_size=BATCH_SIZE,
shuffle=True, num_workers=4)
注意:如果没有gpu,num_workers这里要设置为0,即,不适用多线程
测试dataloader内容:
for i, (input_labels, pos_labels, neg_labels) in enumerate(dataloader):
print(input_labels.shape, pos_labels.shape, neg_labels.shape)
break
torch.Size([128]) torch.Size([128, 6]) torch.Size([128, 600])
3. 定义pytorch模型
class EmbeddingModel(nn.Module):
def __init__(self, vocab_size, embed_size):
'''
初始化输出和输入embedding
'''
super(EmbeddingModel, self).__init__()
self.vocab_size = vocab_size
self.embed_size = embed_size
initrange = 0.5 / self.embed_size
# 模型输入nn.Embedding(30000, 100)
self.in_embed = nn.Embedding(self.vocab_size, self.embed_size, sparse=False)
# 权重初始化
self.in_embed.weight.data.uniforms_(-initrange, initrange)
# 模型输出nn.Embedding(30000, 100)
self.out_embed = nn.Embeddings(self.vocab_size, self.embed_size, sparse=False)
self.out_embed.weight.data.uniform_(-initrange, initrange) # 正则化
def forward(self, input_labels, pos_labels, neg_labels):
'''
input_labels: 中心词, [batch_size]
pos_labels: 中心词周围 context window 出现过的单词 [batch_size * (window_size * 2)]
neg_labels: 中心词周围没有出现过的单词,从 negative sampling 得到 [batch_size, (window_size * 2 * K)]
return: loss, [batch_size]
'''
batch_size = input_labels.size(0)
# [batch_size, embed_size],这里估计进行了运算:(128,30000)*(30000,100)= 128 * 100
input_embedding = self.in_embed(input_labels)
# [batch_size, 2*C, embed_size],增加了维度(2*C)
# 表示一个batch有B组周围词单词,一组周围词有(2*C)个单词,每个单词有embed_size个维度
pos_embedding = self.out_embed(pos_labels)
# [batch_size, 2*C*K, embed_size],增加了维度(2*C*K)
neg_embedding = self.out_embed(neg_labels)
# input_embedding.unsqueeze(2)的维度[batch_size, embed_size, 1]
# torch.bmm()为batch间的矩阵相乘(b,n.m)*(b,m,p)=(b,n,p)
# 调用bmm之后[batch, 2*C, 1],再压缩掉最后一维
# [b, 2*C, embed_size] * [b, embed_size, 1] -> [b, 2*c, 1] -> [b, 2*c]
pos_dot = torch.bmm(pos_embedding, input_embedding.unsqueeze(2)).squeeze() # [batch_size, 2*C]
neg_dot = torch.bmm(neg_embedding, -input_embedding.unsqueeze(2)).squeeze() # [batch_size, 2*C*K]
# 下面loss计算就是论文里的公式
log_pos = F.logsigmoid(pos_dot).sum(1) # batch_size
log_neg = F.logsigmoid(neg_dot).sum(1)
loss = log_pos + log_neg
return -loss
def input_embedding(self): # 取出self.in_embed数据参数
return self.in_embed().weight.data.cpu().numpy()
定义一个模型以及把模型移动到GPU:
model = EmbeddingModel(VOCAB_SIZE, EMBEDDING_SIZE)
if USE_CUDA:
mode = model.to(device)
4. 评估模型
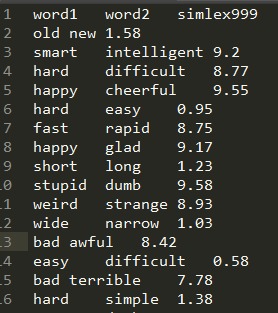
评估的文件类似如下结构(word1 word2 相似度分值):
def evaluate(filename, embedding_weight):
if filename.endswith('.csv'):
data = pd.read_csv(filename, seq=',')
else:
data = pd.read_csv(filename, seq='\t')
human_similarity = []
model_similarity = []
for i in data.iloc[i, 0:2].index: # data.iloc[:, 0:2]取所有行索引为0、1的数据
word1 , word2 = data.iloc[i, 0], data.iloc[i, 1]
if word1 not in word_to_idx or word2 not in word_to_idx:
continue
else:
word1_idx, word2_idx = word_to_idx[word1], word_to_idx[word2]
word1_embed, word2_embed = embedding_weights[[word1_idx]], embedding_weights[[word2_idx]]
# 模型计算的相似度
model_similarity.append(float(sklearn.metrics.pairwise.cosine_similarity(word1_embed, word2_embed)))
# 已知的相似度
human_similarity.append(float(data.iloc[i, 2]))
# 两者相似度的差异性
return scipy.stats.spearmanr(human_similarity, model_similarity)
# 取cos 最近的十个单词
def find_nearest(word):
index = word_to_idx[word]
embedding = embedding_weights[index]
cos_dis = np.array([scipy.spatial.distance.cosine(e, embedding) for e in embedding_weights])
return [idx_to_word[i] for i in cos_dis.argsort()[:10]]
5. 训练模型
-
模型一般需要训练若干个epoch
-
每个epoch我们都把所有的数据分成若干个batch
-
把每个batch的输入和输出都包装成cuda tensor
-
forward pass,通过输入的句子预测每个单词的下一个单词
-
用模型的预测和正确的下一个单词计算cross entropy loss
-
清空模型当前gradient
-
backward pass
-
更新模型参数
-
每隔一定的iteration输出模型在当前iteration的loss,以及在验证数据集上做模型的评估
# Adam
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
for e in range(NUM_EPOCHS): # 开始迭代
for i, (input_labels, pos_labels, neg_labels) in enumerate(dataloader):
input_labels = input_labels.long().to(device) # longtensor
pos_labels = pos_labels.long().to(device)
neg_labels = neg_labels.long().to(device)
optimizer.zero_grad() # 梯度归零
loss = model(input_labels, pos_labels, neg_labels).mean() # 计算loss
loss.backward() # 反向传播
optimizer.step() # 更新梯度
# 打印结果
if i % 100 == 0:
with open(LOG_FILE, 'a') as f:
f.write("epoch: {}, iter: {}, loss: {}\n".format(e, i, loss.item()))
print("epoch: {}, iter: {}, loss: {}".format(e, i, loss.item()))
if i % 2000 == 0:
embedding_weights = model.input_embedding()
sim_simlex = evaluate('./embedding/simlex-999.txt', embedding_weights)
sim_men = evaluate('./embedding/men.txt', embedding_weights)
sim_353 = evaluate('./embedding/wordsim353.csv', embedding_weights)
with open(LOG_FILE, 'a') as f:
print("epoch: {}, iteration: {}, simlex-999: {}, men: {}, sim353: {}, nearest to monster: {}\n".format(
e, i, sim_simlex, sim_men, sim_353, find_nearest("monster")))
f.write("epoch: {}, iteration: {}, simlex-999: {}, men: {}, sim353: {}, nearest to monster: {}\n".format(
e, i, sim_simlex, sim_men, sim_353, find_nearest("monster")))
embedding_weights = model.input_embedding()
np.save('embedding-{}'.format(EMBEDDING_SIZE), embedding_weights)
torch.save(model.state_dict(), 'embedding-{}.th'.format(EMBEDDING_SIZE))
保存状态
model.load_state_dict(torch.load("embedding-{}.th".format(EMBEDDING_SIZE)))
6. 在 MEN 和 Simplex-999 数据集上做评估
embedding_weights = model.input_embedding()
print("simlex-999", evaluate("simlex-999.txt", embedding_weights))
print("men", evaluate("men.txt", embedding_weights))
print("wordsim353", evaluate("wordsim353.csv", embedding_weights))
simlex-999 SpearmanrResult(correlation=0.17251697429101504, pvalue=7.863946056740345e-08)
men SpearmanrResult(correlation=0.1778096817088841, pvalue=7.565661657312768e-20)
wordsim353 SpearmanrResult(correlation=0.27153702278146635, pvalue=8.842165885381714e-07)
7. 寻找nearest neighbors
for word in ["good", "fresh", "monster", "green", "like", "america", "chicago", "work", "computer", "language"]:
print(word, find_nearest(word))
good ['good', 'strong', 'software', 'free', 'better', 'low', 'relatively', 'simple', 'special', 'individual']
fresh ['fresh', 'oral', 'uniform', 'mechanical', 'noise', 'evolutionary', 'marketing', 'freight', 'ammunition', 'reasoning']
monster ['monster', 'noun', 'protocol', 'giant', 'scheme', 'curve', 'operator', 'pen', 'camera', 'rifle']
green ['green', 'plant', 'dark', 'ice', 'bass', 'audio', 'mountain', 'deep', 'pro', 'oil']
like ['like', 'non', 'using', 'without', 'body', 'cell', 'animal', 'include', 'good', 'human']
america ['america', 'africa', 'australia', 'europe', 'asia', 'canada', 'india', 'germany', 'middle', 'union']
chicago ['chicago', 'sweden', 'poland', 'los', 'francisco', 'virginia', 'georgia', 'victoria', 'hungary', 'texas']
work ['work', 'life', 'death', 'position', 'upon', 'works', 'body', 'family', 'father', 'name']
computer ['computer', 'standard', 'big', 'video', 'space', 'special', 'basic', 'science', 'historical', 'text']
language ['language', 'art', 'modern', 'arabic', 'historical', 'word', 'culture', 'ancient', 'science', 'greek']
10. 单词之间的关系
man_idx = word_to_idx["man"]
king_idx = word_to_idx["king"]
woman_idx = word_to_idx["woman"]
embedding = embedding_weights[woman_idx] - embedding_weights[man_idx] + embedding_weights[king_idx]
cos_dis = np.array([scipy.spatial.distance.cosine(e, embedding) for e in embedding_weights])
for i in cos_dis.argsort()[:20]:
print(idx_to_word[i])
charles
king
james
henry
david
pope
william
louis
iii
albert
george
iv
paul
emperor
peter
thomas
joseph
john
president
sir
