深度学习与Pytorch入门实战(十三)RNN
1. 词嵌入
nn.Embedding(num_embeddings, embedding_dim, padding_idx=None,
max_norm=None, norm_type=2.0, scale_grad_by_freq=False,
sparse=False, _weight=None)
-
其为一个简单的 存储固定大小的词典 的 嵌入向量的查找表
- 意思是说,给一个编号,嵌入层就能 返回这个编号对应的嵌入向量(嵌入向量反映了各个编号代表的符号之间的语义关系)
-
输入:一个编号列表,输出:对应的 符号嵌入向量列表。
-
num_embeddings(int):词典的大小尺寸,比如总共出现5000个词,那就输入5000。此时index为(0-4999); -
embedding_dim(int): 嵌入向量的维度,即用多少维来表示一个符号; -
padding_idx(int,可选):比如,输入长度为100,但是每次的句子长度并不一样,后面就需要用统一的数字填充,而这里就是指定这个数字; -
max_norm(float,可选):最大范数,如果嵌入向量的范数超过了这个界限,就要进行再归一化; -
norm_type (float, 可选):指定利用什么范数计算,并用于对比max_norm,默认为2范数; -
scale_grad_by_freq (boolean, 可选):根据单词在mini-batch中出现的频率,对梯度进行放缩,默认为False; -
sparse (bool, 可选):若为True,则 与权重矩阵相关的梯度 转变为稀疏张量;
import torch
from torch import nn
# 给单词编索引号
word_to_idx = {'hello':0, 'world':1}
# 得到目标单词索引
lookup_tensor = torch.tensor([word_to_idx['hello']], dtype=torch.long)
embeds = nn.Embedding(num_embeddings=2, embedding_dim=5)
# 传入单词的index,返回对应的嵌入向量
hello_embed = embeds(lookup_tensor)
print(hello_embed)
tensor([[ 0.3951, 0.6753, 0.2209, -2.4807, -0.6213]],
grad_fn=<EmbeddingBackward>)
Tip:
-
上面
nn.Embedding的那张表是没有初始化的,得到的嵌入向量是随机生成的 -
初始化一般采用现成的编码方式,把
word2vec或者GloVe下载下来,数据内容填充进表。
下面直接使用GloVe方式进行查表操作(提前pip install pytorch-nlp)
from torchnlp.word_to_vector import GloVe
# 下载太漫长
vectors = GloVe()
print(vectors('hello'))

2. nn.RNN
-
nn.RNN的数据处理如下图所示。 -
每次向网络中输入batch个样本,每个时刻处理的是该时刻的batch个样本,因此 \(x_t\) 是shape为[batch,feature_len]的Tensor。
- 例如,输入3句话,每句话10个单词(T_x),每个单词用100维的向量表示,那么seq_len=10,batch=3,feature_len=100。
-
隐藏记忆单元h 的shape是二维的[batch,hidden_len],其中hidden_len是一个可以自定的超参数
- 例如,可以取为20,表示每个样本用20长度的向量记录。
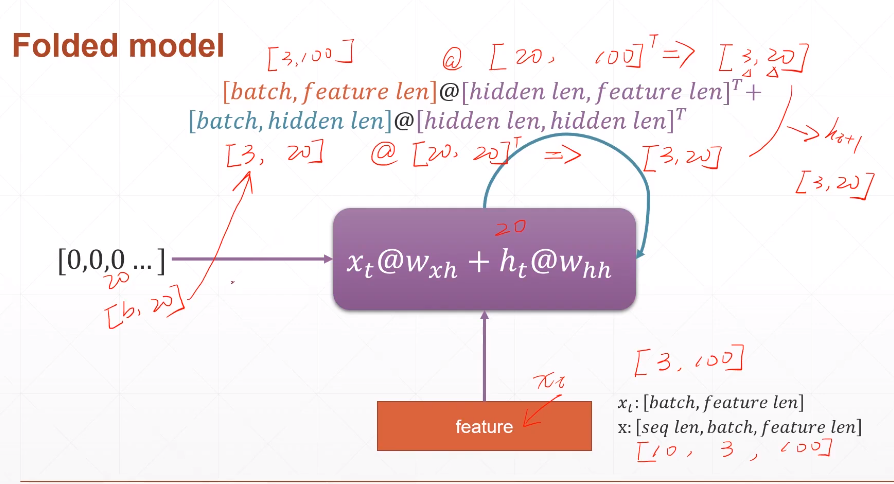
Tip:x相当于seq_len个\(x_t\)
2.1 nn.RNN参数
nn.RNN(input_size, hidden_size, num_layers=1,
nonlinearity=tanh, bias=True, batch_first=False,
dropout=0, bidirectional=False)
参数:
-
input_size:输入特征的维度- 一般rnn中输入的是词向量,那么
input_size就等于 一个词向量的维度,即feature_len;
- 一般rnn中输入的是词向量,那么
-
hidden_size:隐藏层神经元个数- 即,输出的维度(因为rnn输出为各个时间步上的隐藏状态);
-
num_layers:网络的层数; -
nonlinearity:激活函数; -
bias:是否使用偏置; -
batch_first:输入数据的形式,默认是 False,就是这样形式,(seq(num_step), batch, input_dim)- 即,将序列长度放在第一位,batch 放在第二位;
-
dropout:是否应用dropout, 默认不使用,如若使用将其设置成一个0-1的数字即可; -
birdirectional:是否使用双向的 rnn,默认是 False;
from torch import nn
# 词向量维度100维,输出维度10
rnn = nn.RNN(100, 10)
print(rnn._parameters.keys())
# odict_keys(['weight_ih_l0', 'weight_hh_l0', 'bias_ih_l0', 'bias_hh_l0'])
# W_hh: W_aa, W_ih: W_xa
print(rnn.weight_hh_l0.shape, rnn.weight_ih_l0.shape)
# torch.Size([10, 10]) torch.Size([10, 100])
# batch size: 10
print(rnn.bias_hh_l0.shape, rnn.bias_ih_l0.shape)
# torch.Size([10]) torch.Size([10])
Tip:
- bias只取hidden_len,等到作加法时会广播到所有的batch上。
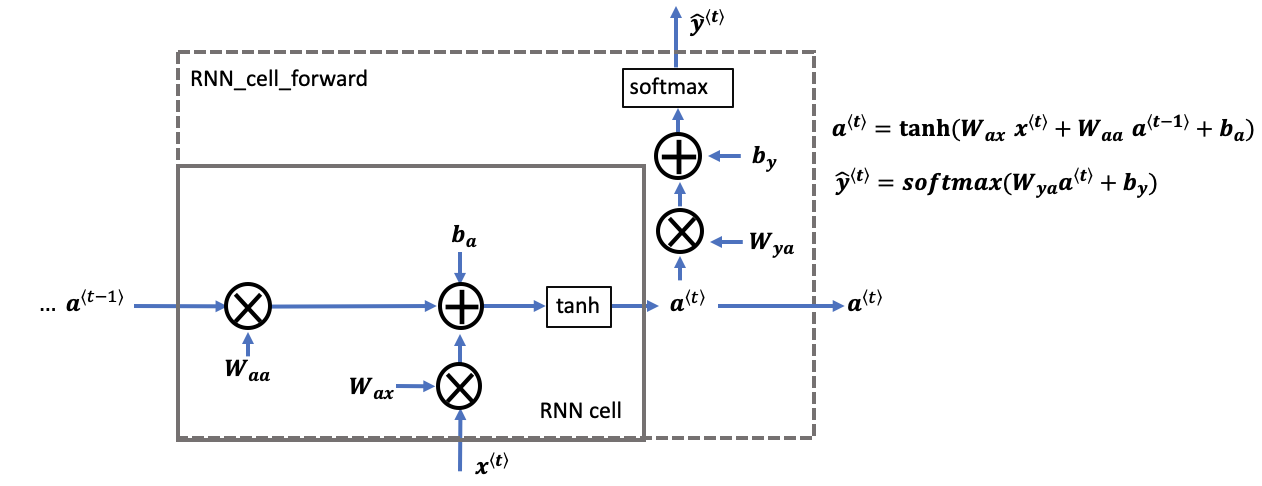
2.2 forward前向传播
out, ht = forward(x, h0)
-
x:[seq_len, batch, feature_len] 它是一次性将所有时刻特征喂入的,不需要每次喂入当前时刻的\(x_t\);
-
h0/ht:[num_layers, batch, hidden_len] h0是第一个时间戳所有层的记忆单元的Tensor(理解成每一层中每个句子的隐藏输出)(h0:a0, ht: at);
-
out:[seq_len, batch, hidden_len] out是 每一个时刻上 空间上最后一层的输出(相当于 \(\hat{y^{<t>}}\))
# 5层RNN
import torch
from torch import nn
# (词向量维度)feature_len=100, (神经元数)hidden_len=20, 网络层数=5
rnn = nn.RNN(input_size=100, hidden_size=20, num_layers=5)
# 单词数量(seq_len=10),句子数量(batch=3),每个特征100维度(feature_len=100)
x = torch.randn(10, 3, 100)
# 传入RNN处理, 另外传入h_0, shape是<网络层数=5, batch=3, (神经元数)hidden_len=20>
# forward
out, h = rnn(x, torch.zeros(5, 3, 20))
print(out.shape) # torch.Size([10, 3, 20])
print(h.shape) # at: torch.Size([5, 3, 20])
2.3 使用nn.RNN构建多层循环网络
- 相比2.1处的代码,只要改变层数即可。
from torch import nn
# 词向量维度100维,输出维度20,层数为2
rnn = nn.RNN(100, 20, 2)
print(rnn._parameters.keys())
# odict_keys(['weight_ih_l0', 'weight_hh_l0',
# 'bias_ih_l0', 'bias_hh_l0', 'weight_ih_l1',
# 'weight_hh_l1', 'bias_ih_l1', 'bias_hh_l1'])
print(rnn.weight_hh_l0.shape, rnn.weight_ih_l0.shape)
# torch.Size([20, 20]) torch.Size([20, 100])
print(rnn.weight_hh_l1.shape, rnn.weight_ih_l1.shape)
# torch.Size([20, 20]) torch.Size([20, 20]) 这里输入不是100,是20
Tip:
-
从 \(l_1\) 层开始接受的输入都是下面层的输出,即接受的输入特征数不再是feature_len而是hidden_len
-
即,这里参数
weight_ih_l1的shape是:[hidden_len,hidden_len]
out, ht=forward(x, h0)
import torch
from torch import nn
# feature_len=100, hidden_len=20, 层数=4
rnn = nn.RNN(100, 20, 4)
# 单词数量(seq_len=10),句子数量(batch=3),每个特征100维度(feature_len=100)
x = torch.randn(10, 3, 100)
# 传入RNN处理, 另外传入h_0, shape是<层数, batch, hidden_len=20>
out, h = rnn(x, torch.zeros(4, 3, 20))
print(out.shape) # torch.Size([10, 3, 20])
print(h.shape) # torch.Size([4, 3, 20])
3. nn.RNNCell
-
nn.RNN是一次性将 所有时刻 特征喂入的 -
nn.RNNCell将序列上的 每个时刻 分开来处理。 -
举例:如果要处理3个句子,每个句子10个单词,每个单词用100维的嵌入向量表示
-
nn.RNN传入的Tensor的shape是[10,3,100]
-
nn.RNNCell传入的Tensor的shape是[3,100],将此计算单元运行10次。
-
3.1 nn.RNNCell()
初始化方法和上面一样。
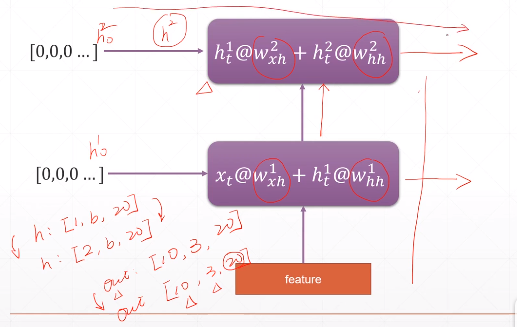
3.2 ht = forward(xt, ht-1)
-
\(x_t\):[batch, feature_len]表示当前时刻的输入;
-
\(h_{t-1}\):[num layers, batch, hidden_len]前一个时刻的单元输出,\(h_t\)是下一时刻的单元输入;
-
out: out相当于 \(\hat{y^{<t>}}\)
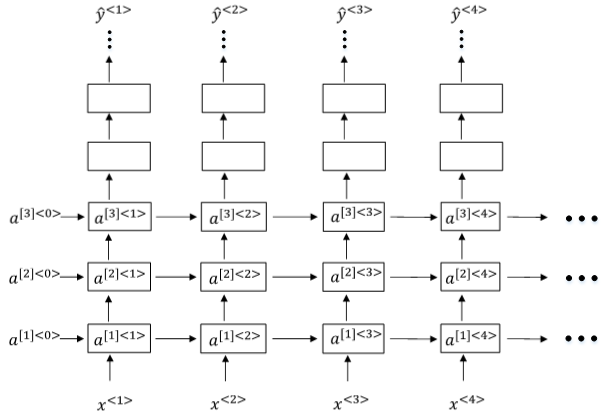
多层RNN类似下图:
import torch
from torch import nn
# 单层RNN, feature_len=100, hidden_len=20
cell1 = nn.RNNCell(100, 20)
h1 = torch.zeros(3, 20)
x = torch.randn(10, 3, 100)
for xt in x: # xt.shape=[3, 100]
h1 = cell1(xt, h1)
print(h1.shape) # torch.Size([3, 20])
# 多层RNN
cell1 = nn.RNNCell(100, 30)
cell2 = nn.RNNCell(30, 20)
h1 = torch.zeros(3, 30)
h2 = torch.zeros(3, 20)
x = torch.randn(10, 3, 100)
for xt in x:
h1 = cell1(xt, h1)
h2 = cell2(h1, h2)
print(h1.shape) # torch.Size([3, 30])
print(h2.shape) # torch.Size([3, 20])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号