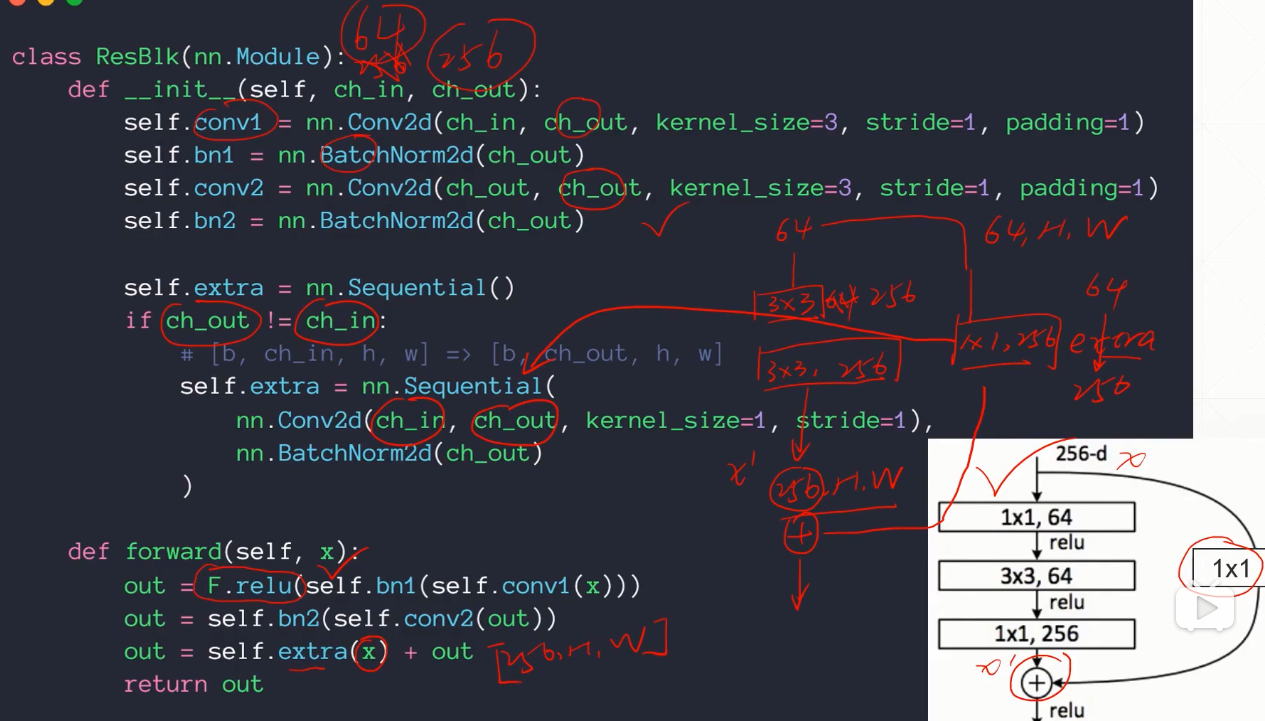
深度学习与Pytorch入门实战(十)ResNet&nn.Module
1. ResNet
2. nn.Module
-
在PyTorch中
nn.Module类是用于 定义网络中 前向结构 的父类 -
当要定义自己的网络结构时就要继承这个类
-
现有的那些类式接口(如
nn.Linear、nn.BatchNorm2d、nn.Conv2d等)也是继承这个类的 -
nn.Module类可以嵌套若干nn.Module的对象,来形成网络结构的嵌套组合 -
下面记录
nn.Module的功能
3. 继承nn.Module类的模块
-
使用其初始化函数创建对象,然后调用forward函数就能使用里面的前向计算过程。
-
包括:Linear、ReLU、Sigmoid、Conv2d、ConvTransposed2d、Dropout...
4. 容器nn.Sequential()
-
nn.Sequential是一个Sequential容器 -
模块将按照 构造函数中传递的顺序 添加到模块中。
-
通俗的说,就是根据自己的需求,把不同的函数组合成一个(小的)模块使用 或者 把组合的模块添加到自己的网络中。
from torch import nn
conv_module = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# 具体的使用方法
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv_module = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
def forward(self, input):
out = self.conv_module(input)
return out
Tip:
-
使用
nn.Module,我们可以根据自己的需求改变传播过程,如RNN等; -
如果需要快速构建或者不需要过多的过程,直接使用
nn.Sequential。
5. 模块内部参数管理
可以用 .parameters() 或者 .named_parameters() 返回 其内的所有参数的迭代器:
from torch import nn
net = nn.Sequential(
nn.Linear(4, 2), # 输入维度4,输出维度2 的线性层
nn.Linear(2, 2)
)
print(list(net.parameters()))
# [Parameter containing:
# tensor([[-0.0829, 0.3424, 0.4514, -0.3981],
# [-0.3401, 0.1429, -0.4525, 0.4991]], requires_grad=True),
# Parameter containing:
# tensor([-0.0321, 0.0872], requires_grad=True),
# Parameter containing:
# tensor([[ 0.0628, 0.3092],
# [ 0.5135, -0.4738]], requires_grad=True),
# Parameter containing:
# tensor([-0.4249, 0.3921], requires_grad=True)]
print(dict(net.named_parameters()))
# {'0.weight': Parameter containing:
# tensor([[-0.0829, 0.3424, 0.4514, -0.3981],
# [-0.3401, 0.1429, -0.4525, 0.4991]], requires_grad=True),
# '0.bias': Parameter containing:
# tensor([-0.0321, 0.0872], requires_grad=True),
# '1.weight': Parameter containing:
# tensor([[ 0.0628, 0.3092],
# [ 0.5135, -0.4738]], requires_grad=True),
# '1.bias': Parameter containing:
# tensor([-0.4249, 0.3921], requires_grad=True)}
Tip:
-
以第0层为例,weight.shape=[2,4],输出维度在前,输入维度在后,和Linear定义的时候相反;
-
相比
.parameters(),.named_parameters()能看到参数名,默认情况下会使用 所在的层数 + 参数类型 的方式,从0层开始编号; -
使用优化器时,可以直接调用
nn.Module类定义的参数。
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
6. 模块树形结构
-
模块之间通过 嵌套组合 会形成树形结构,使用
.children()可以 获取其直接孩子结点 -
使用
.modules()可以 获取其所有子结点。
from torch import nn
class BaseNet(nn.Module):
def __init__(self):
# super(BaseNet, self).__init__() # python2写法
super().__init__()
self.net = nn.Linear(4, 3) # 输入4维,输出3维的线性层
def forward(self, x):
return self.net(x)
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__() # 使用Seq容器组合了三个模块
self.net = nn.Sequential(
BaseNet(),
nn.ReLU(),
nn.Linear(3, 2)
)
def forward(self, x):
return self.net(x)
my_net = MyNet()
print(list(my_net.children())) # 直接孩子
# [Sequential(
# (0): BaseNet(
# (net): Linear(in_features=4, out_features=3, bias=True)
# )
# (1): ReLU()
# (2): Linear(in_features=3, out_features=2, bias=True)
# )]
print(list(my_net.modules())) # 所有孩子
# [MyNet(
# (net): Sequential(
# (0): BaseNet(
# (net): Linear(in_features=4, out_features=3, bias=True)
# )
# (1): ReLU()
# (2): Linear(in_features=3, out_features=2, bias=True)
# )
# ),
# Sequential(
# (0): BaseNet(
# (net): Linear(in_features=4, out_features=3, bias=True)
# )
# (1): ReLU()
# (2): Linear(in_features=3, out_features=2, bias=True)
# ),
# BaseNet(
# (net): Linear(in_features=4, out_features=3, bias=True)
# ),
# Linear(in_features=4, out_features=3, bias=True), ReLU(), Linear(in_features=3, out_features=2, bias=True)]
-
.children()只返回自己的直系孩子列表,在这里也就是一个nn.Sequential容器。 -
而使用
.modules()获取的所有孩子是包括自己的。
7. 设备
- 使用
.to(device)可以在具体的CPU/GPU上切换,这会将其所有子模块也一起转移过去运行。
device = torch.device('cuda')
net = Net()
net.to(device)
Tip:
-
模块的
.to(device)是原地操作并返回自己的引用 -
而Tensor的
.to(device)不会在当前Tensor上操作,返回的 才是在目标设备上对应创建的Tensor- 所以
net = MLP().to(device)。
- 所以
8. 加载和保存
-
使用
torch.load()载入检查点文件,然后传入net.load_state_dict()网络模型设置参数 -
把当前类所有状态
net.state_dict()传入torch.save()保存到文件中去。 -
在训练过程中,每隔一定的迭代次数可以保存一下检查点,将当前网络模型的状态传进去。
-
eg.
ckpt.mdl是网络的一个中间状态
net.load_state_dict(torch.load('ckpt.mdl'))
# train...
torch.save(net.state_dict(), 'ckpt.mdl')
9. 训练和测试模式
-
前面的学习中提到
Dropout和Batch Normalization在训练和测试中的行为不同 -
需要对每一个
nn.Module()模块 单独设置训练状态和测试状态 -
可以直接为网络使用方法
.train()切换到训练模式,使用.eval()方法 切换到测试模式。
# train
net.train()
...
# test
net.eval()
...
10. 实现自定义的类
10.1 nn.Sequential用法
class Flatten(nn.Module):
def __init__(self):
super(Flatten, self).__init__()
def forward(self, input):
return input.view(input.size(0), -1)
class TestNet(nn.Module):
def __init__(self):
super(TestNet, self).__init__()
self.net = nn.Sequential(nn.Conv2d(1, 16, stride=1, padding=1),
nn.MaxPool2d(2, 2),
Flatten(),
nn.Linear(1*14*14, 10))
def forward(self, x):
return self.net(x)
Tip:
-
只有类才能写到
Sequential里面,比如F.relu不可以,要重新定义nn.ReLU -
如,Flatten类,Reshape类都需要自己实现!
10.2 nn.Parameters 和 .parameters()
-
如果在继承
nn.Module类来实现模块时,出现需要操作Tensor的部分,那么应当使用nn.Parameters(注意这里P大写) 将其包装起来。 -
如果直接使用Tensor,那么就不能用
.parameters()(注意这里p小写)获取到所有参数,也就不能直接传给优化器去记录要优化的这些参数了。
class MyLinear(nn.Module):
def __init__(self, inp, outp):
super(MyLinear, self).__init__()
# 线性层的参数w和b,对w而言输出维度放在前面
# requires_grad = True
self.w = nn.Parameter(torch.randn(outp, inp)) # w: [n^l, n^{l-1}]
self.b = nn.Parameter(torch.randn(outp))
def forward(self, x):
x = x @ self.w.t() + self.b
return x
Tip:
-
上述MyLinear 和 pytorch自带的Linear类效果一样
-
使用
nn.Parameter()包装Tensor时,自动设置了requires_grad=True -
即默认情况下认为它是反向传播优化的参数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号