Coursera Deep Learning笔记 序列模型(二)NLP & Word Embeddings(自然语言处理与词嵌入)
1. Word Representation
之前介绍用词汇表表示单词,使用one-hot 向量表示词,缺点:它使每个词孤立起来,使得算法对相关词的泛化能力不强。


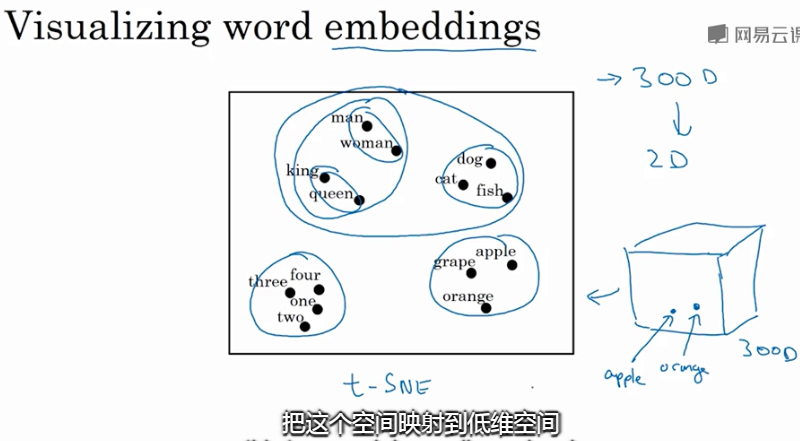
从上图可以看出相似的单词分布距离较近,从而也证明了Word Embeddings能有效表征单词的关键特征。
2. 词嵌入(word embedding)

Transfer learning and word embedding:
-
从海量词汇库中学习word embeddings(即所有单词的特征向量),或者从网上下载预训练好的word embeddings。
-
将word embeddings迁移到新的任务中,只有少量标注训练集的任务中。例如,用这个 300维的词嵌入 来表示你的单词
- 好处:你可以用更低维度的特征向量,代替原来的1000维的one-hot向量,
-
(可选):继续使用新数据微调word embeddings。(只有当第二步有很大数据才会微调)
当训练集较小时,词嵌入作用最明显。它广泛应用于NLP领域(命名实体识别,文本摘要,文本解析,指代消减),在语言模型、机器翻译领域用的不多。
-
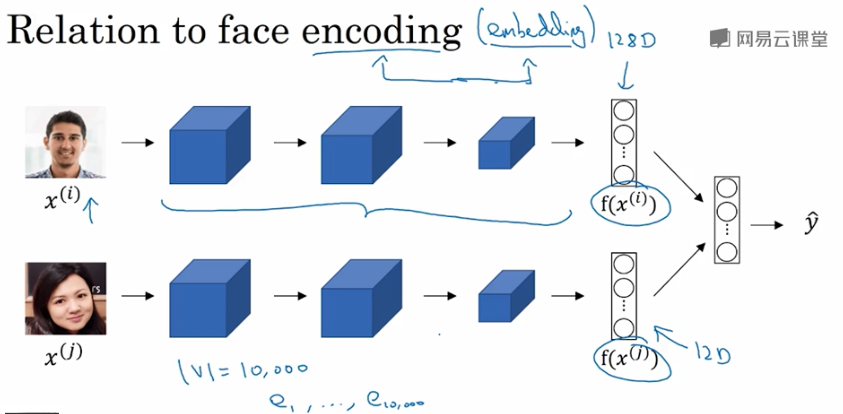
人脸图片经过Siamese网络,得到其特征向量 \(f(x)\),这点跟word embedding是类似的。
-
二者不同的是Siamese网络输入的人脸图片可以是网络上海量的数据;而word embedding一般都是 已建立的词汇库 中的单词,非词汇库单词统一用
表示
3. 词嵌入的特性(Properties of word embeddings)
Word embeddings可以帮助实现类比推理,找到 不同单词之间的相似类别关系,如下图所示:
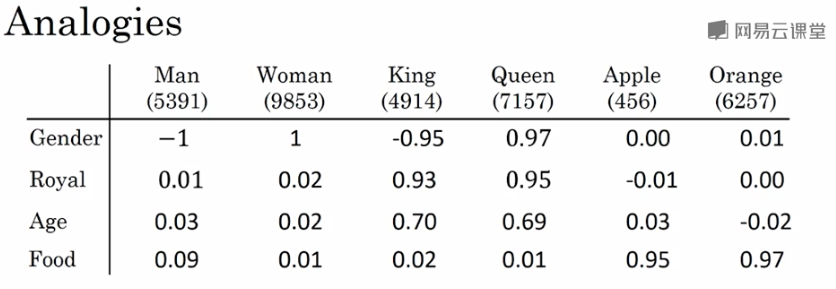
上例中,特征维度是4维的,分别是[Gender, Royal, Age, Food]。
常识地,“Man”与“Woman”的关系,类比于“King”与“Queen”的关系。而利用 Word embeddings 可以找到这样的对应类比关系。
我们将“Man”的embedding vector 与 “Woman”的embedding vector相减:
类似地,将 “King”的embedding vector” 与 “Queen”的embedding vector”相减:
相减结果表明,“Man”与“Woman”的主要区别是性别,“King”与“Queen”也是一样。
一般地,A类比于B 相当于 C类比于“?”,这类问题可以使用embedding vector进行运算。
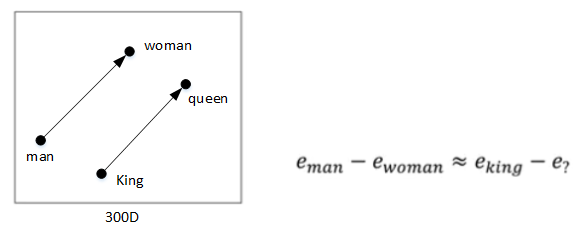
如上图所示,根据等式 \(e_{man}-e_{woman}\approx e_{king}-e_?\)得:
利用相似函数,
- For word w: argmax_w \(sim(e_w, e_{king}-e_{man}+e_{woman})\) .
关于相似函数,比较常用的是 余弦相似度(cosine similarity),其表达式为:
还可以计算Euclidian distance来比较相似性,即 \(||u-v||^2\),距离越大,相似性越小。
4. 嵌入矩阵(Embedding matrix)
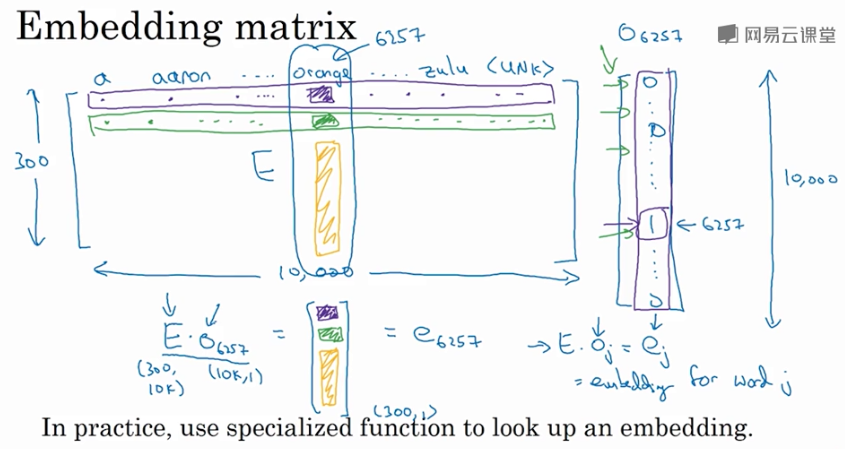
-
假设某个词汇库包含了10000个单词,每个单词包含的特征维度为300,那么表征所有单词的 embedding matrix 维度为
300 x 10000,用 \(E\) 来表示。 -
某单词w 的 one-hot向量 表示为 \(O_w\),维度为
10000 x 1,则该单词的 embedding vector 表达式为:
- 因此,求出 embedding matrix \(E\),就能计算出所有单词的 embedding vector \(e_w\),重点介绍如何求出 \(E\)。
5. 学习词嵌入(Learning word embeddings)
Embedding matrix \(E\) 可以通过构建自然语言模型,运用梯度下降算法得到,例:
I want a glass of orange (juice).
通过这句话的前6个单词,预测最后的单词 “juice”。 \(E\) 未知待求,每个单词可用 embedding vector \(e_w\) 表示。构建的神经网络模型结构如下图所示:
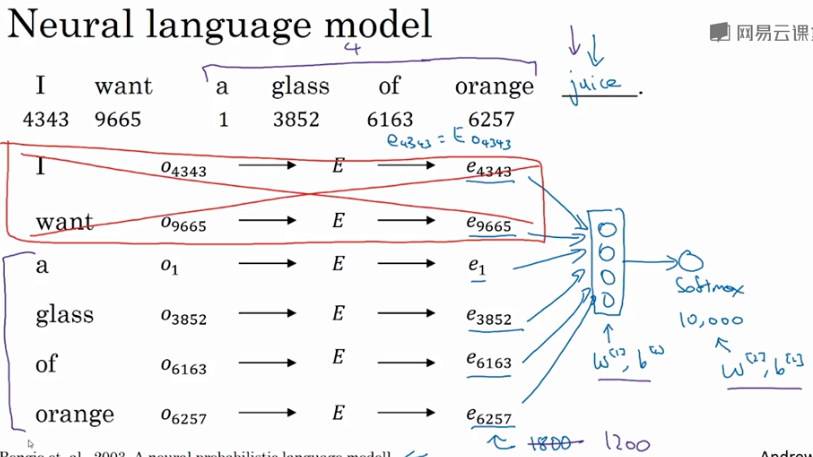
神经网络输入层包含6个embedding vectors,每个embedding vector维度是300,则输入层总共有1800个输入。Softmax层有10000个概率输出,与词汇表包含的单词数目一致。
正确的输出label是“juice”。其中 \(E,W^{[1]},b^{[1]},W^{[2]},b^{[2]}\) 为待求值。对足够的训练例句样本,运用梯度下降算法,迭代优化,最终求出embedding matrix \(E\)。
一般地,我们把输入叫做context,输出叫做target。对应到上面这句话里:
-
context: a glass of orange
-
target: juice
关于context的选择有多种方法:
-
target前n个单词或后n个单词,n可调
-
target前1个单词
-
target附近某1个单词(Skip-Gram)
不同的context选择方法都能计算出较准确的 embedding matrix \(E\)。
6. Word2Vec
Skip-Gram模型 是Word2Vec的一种:
I want a glass of orange juice to go along with my cereal.
Skip-Gram模型:
-
首先,随机选择一个单词作为context,例如“orange”.
-
然后,使用一个宽度为5或10(自定义)的滑动窗,在context附近选择一个单词作为target,可以是“juice”、“glass”、“my”等等。最终得到了多个 context—target对 作为监督式学习样本。
训练的过程是构建自然语言模型,经过softmax单元的输出为:
其中,\(\theta_t\) 与输出(target)有关的的参数,即某个词t和标签相符的概率是多少,\(e_c\) 为context的 embedding vector,且 \(e_c = E ⋅ O_c\) 。
相应的loss function为:
然后,运用梯度下降算法,迭代优化,最终得到embedding matrix \(E\)。
上述算法慢,主要因为softmax输出单元为10000个,\(\hat y\) 计算公式中包含了大量的求和运算。
解决办法:
- 使用
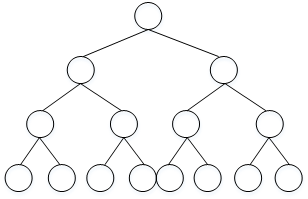
hierarchical softmax classifier,即分级softmax分类器。其结构如下图所示:
-
这种树形分类器是一种二分类。与之前的softmax分类器不同,它在每个数节点上对目标单词进行区间判断,最终定位到目标单词。
-
类似二叉搜索树,此分类器最多需要 \(log\ N\) 步就能找到目标单词,N为单词总数。
-
实际应用中,对树形分类器做了一些改进。改进后的树形分类器是非对称的,通常选择把常用单词放在树的顶层,不常用单词放在树的底层,更能提高搜索速度。
-
关于context的采样,注意:
-
如果使用均匀采样,那么一些常用的介词、冠词,例如the, of, a, and, to等出现的概率更大一些。但是,这些单词的embedding vectors通常不是我们最关心的,我们更关心例如orange, apple, juice等这些名词等。
-
所以,实际应用中,一般不选择随机均匀采样的方式来选择context,而是使用其它算法来处理这类问题。
-
7. 负采样(Negative sampling)
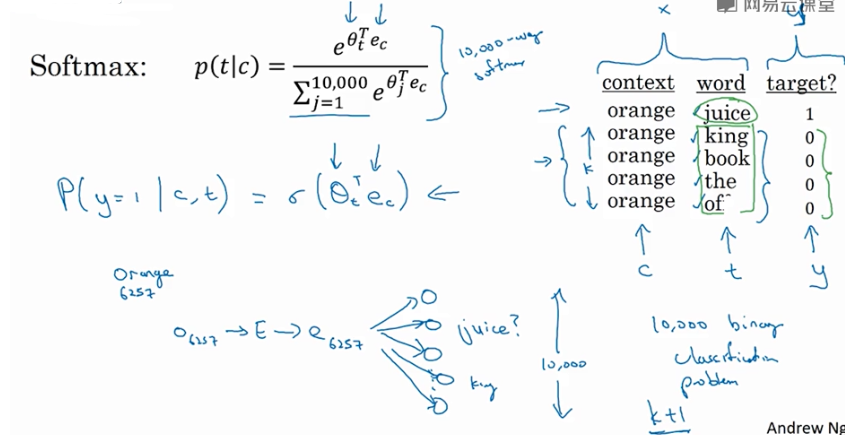
Negative sampling:
-
是另外一种有效的求解embedding matrix \(E\) 的方法。
-
方法:判断选取的context word 和 target word 是否构成一组正确的context-target对,一般包含一个正样本 和 k个负样本。
-
例如,“orange” 为 context word,“juice” 为 target word,很明显“orange juice”是一组context-target对,为正样本,相应的target label为1。
-
若“orange”为 context word不变,target word随机选择“king”、“book”、“the”或者“of”等,这些都不是正确的context-target对,为负样本,相应的target label为0。
-
-
一般地,固定某个 context word 对应的 负样本个数k 一般遵循:
-
若训练样本较小,k一般选择 5~20;
-
若训练样本较大,k一般选择 2~5。
-
Negative sampling 的数学模型为:
其中,\(\sigma\) 表示sigmoid激活函数。
-
negative sampling某个固定的正样本对应k个负样本,即模型总共包含了 k+1个binary classification。
-
对比之前介绍的10000个输出单元的softmax分类,negative sampling转化为 k+1 个二分类问题,计算量要小很多,提高了模型运算速度。
如何选择负样本对应的target单词:
-
随机选择的方法
-
根据该词出现的频率进行选择(更实用),相应的概率公式为:
其中,\(f(w_i)\) 表示单词 \(w_i\) 在单词表中出现的概率。
8. GloVe word vectors
GLOVE的工作原理类似于Word2Vec。上面可以看到Word2Vec是一个“预测”模型,它预测给定单词的上下文,GLOVE通过构造一个共现矩阵(words X context)来学习,该矩阵主要计算单词在上下文中出现的频率。因为它是一个巨大的矩阵,我们分解这个矩阵来得到一个低维的表示。
GloVe算法引入了一个新的参数:
-
\(X_{ij}\): 表示 单词i 在 单词j 上下文中出现的次数,即单词i和单词j共同出现在一个窗口中的次数。
-
其中,i表示context,j表示target。一般地,如果不限定context一定在target的前面,则有对称关系 \(X_{ij}=X_{ji}\);
-
如果有限定先后,则 \(X_{ij}\neq X_{ji}\)。下面默认存在对称关系 \(X_{ij}=X_{ji}\)
GloVe模型的loss function为:
从上式可以看出,若两个词的embedding vector越相近,同时出现的次数越多,则对应的loss越小。
- 为了防止出现“log 0”,即两个单词不会同时出现,无相关性的情况,对loss function引入一个权重因子 \(f(X_{ij})\):
-
当 \(X_{ij}=0\)时,权重因子 \(f(X_{ij})=0\)。该方法 忽略了无任何相关性的context和target,只考虑 \(X_{ij}>0\) 的情况。
-
出现频率较大的单词相应的权重因子 \(f(X_{ij})\) 较大,出现频率较小的单词相应的权重因子 \(f(X_{ij})\) 较小。
一般地,引入偏移量,则loss function表达式为:
注意,参数 \(\theta_i\) 和 \(e_j\) 是对称的。使用优化算法得到所有参数之后,最终的 \(e_w\) 可表示为:
无论使用Skip-Gram模型还是GloVe模型等,不能保证嵌入向量的独立组成部分是能够理解的,计算得到的embedding matrix \(E\) 的 每一个特征值不一定对应有实际物理意义的特征值,如gender,age等。

9. 情感分类(Sentiment Classification)
情感分类一般是根据一句话来判断其喜爱程度,例如1~5星分布。如下图所示:

情感分类问题的一个主要挑战:缺少足够多的训练样本。 Word embedding 可以帮助 解决训练样本不足的问题。
首先介绍使用word embedding解决情感分类问题的一个简单模型算法。
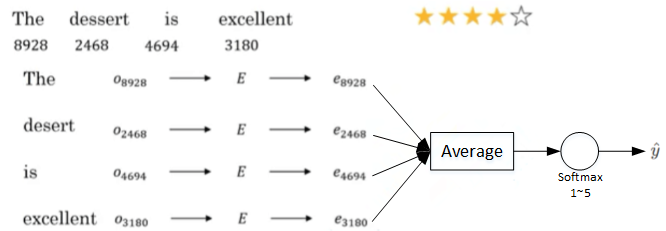
没有考虑单词出现次序,如:Completely lacking in good taste, good service, and good ambience. good出现很多次,但是在good之前加上lacking,则变成消极意思。
情感分类的RNN模型:
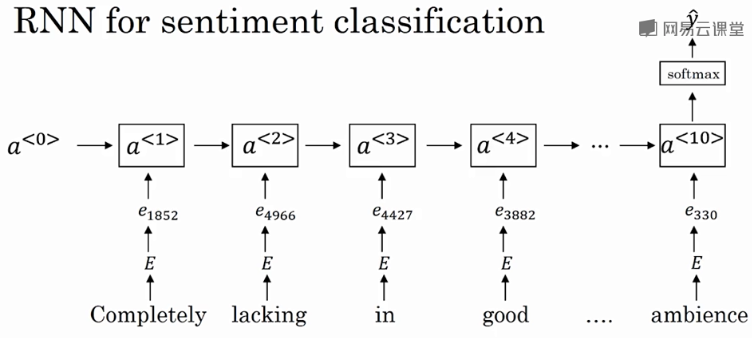
该RNN模型是典型的many-to-one模型,考虑单词出现的次序,能够有效识别句子表达的真实情感。
使用word embedding,能够有效提高模型的泛化能力,即使训练样本不多,也能保证模型有不错的性能。
10. 词嵌入除偏(Debiasing word embeddings)
Word embeddings中存在一些性别、宗教、种族等偏见或者歧视。例如:

第二句话和第三句话存在性别偏见,因为Woman和Mother也可以是Computer programmer和Doctor。
以性别偏见为例,我们来探讨下如何消除word embeddings中偏见。
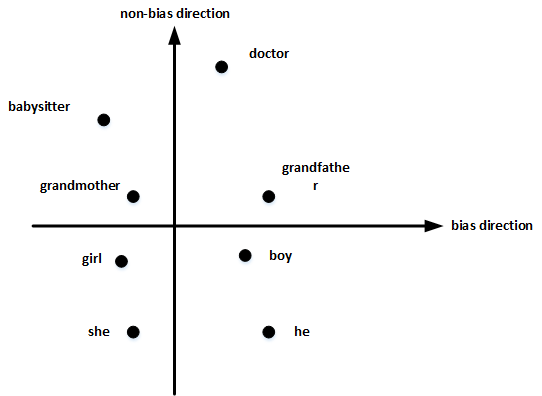
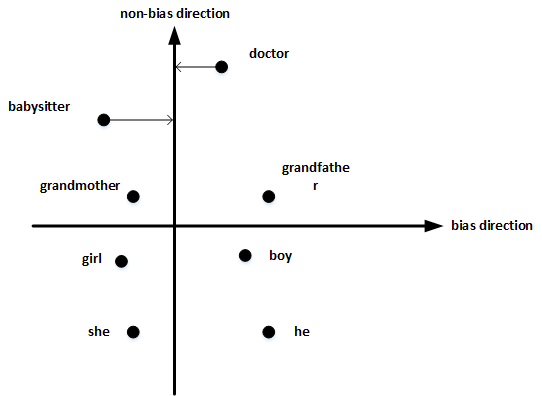
首先,确定偏见bias的方向:
- 方法是对 所有性别对立的单词 求差值,再平均。上图展示了 bias direction 和 non-bias direction。
然后,单词中立化(Neutralize):
- 将需要消除性别偏见的单词投影到non-bias direction上去,消除bias维度,例如babysitter,doctor等。
最后,均衡对(Equalize pairs):
- 让性别对立单词 与 上面的中立词 距离相等,具有同样的相似度。例如让 grandmother 和 grandfather 与 babysitter 的距离同一化。
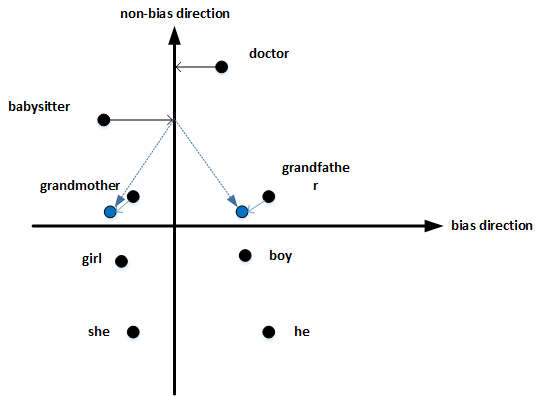
通常,大部分英文单词,例如职业、身份等都需要中立化,消除embedding vector中 性别 这一维度的影响。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号