Coursera Deep Learning笔记 结构化机器学习项目 (下)
1. error analysis
举个例子,猫类识别问题,已经建立的模型的错误率为10%。为了提高正确率,我们发现该模型会将一些狗类图片错误分类成猫。一种常规解决办法是扩大狗类样本,增强模型对够类(负样本)的训练。但是,这一过程可能会花费几个月的时间,耗费这么大的时间成本到底是否值得呢?也就是说扩大狗类样本,重新训练模型,对提高模型准确率到底有多大作用?这时候我们就需要进行error analysis,帮助我们做出判断。
我们可以从分类错误的样本中统计出狗类的样本数量。根据狗类样本所占的比重,判断这一问题的重要性。
假如狗类样本所占比重仅为5%,即时我们花费几个月的时间扩大狗类样本,提升模型对其识别率,改进后的模型错误率最多只会降低到9.5%。相比之前的10%,并没有显著改善。我们把这种性能限制称为ceiling on performance。
相反,假如错误样本中狗类所占比重为50%,那么改进后的模型错误率有望降低到5%,性能改善很大。因此,值得去花费更多的时间扩大狗类样本。

2. Cleaning up incorrectly labeled data
如果这些label标错的情况是随机性的(random errors),DL算法对其包容性是比较强的,即健壮性好,一般可以直接忽略
然而,如果是系统错误(systematic errors),这将对DL算法造成影响,降低模型性能。
如果是dev/test sets中出现incorrectly labeled data:
利用上节内容介绍的error analysis,统计dev sets中所有分类错误的样本中incorrectly labeled data所占的比例。

根据该比例的大小,决定是否需要修正所有incorrectly labeled data,还是可以忽略。举例说明,若:
-
Overall dev set error: 10%
-
Errors due incorrect labels: 0.6%
-
Errors due to other causes: 9.4%
上面数据表明Errors due incorrect labels所占的比例仅为0.6%,占dev set error的6%,而其它类型错误占dev set error的94%。因此,此时,可以忽略incorrectly labeled data。
优化DL算法后,出现如下情况:
-
Overall dev set error: 2%
-
Errors due incorrect labels: 0.6%
-
Errors due to other causes: 1.4%
上面数据表明Errors due incorrect labels所占的比例依然为0.6%,但是却占dev set error的30%,而其它类型错误占dev set error的70%。因此,这种情况下,incorrectly labeled data不可忽略,需要手动修正。
dev set的主要作用是在不同算法之间进行比较,选择错误率最小的算法模型。如果有incorrectly labeled data的存在,当不同算法错误率比较接近的时候,我们无法仅仅根据Overall dev set error准确指出哪个算法模型更好,必须修正incorrectly labeled data。
一般只修复 dev/test data上的标签
关于修正incorrect dev/test set data,有几条建议:
-
Apply same process to your dev and test sets to make sure they continue to come from the same distribution
-
Consider examining examples your algorithm got right as well as ones it got wrong
-
Train and dev/test data may now come from slightly different distributions
3. Build your first system quickly then iterate
-
Set up dev/test set and metric
-
Build initial system quickly
-
Use Bias/Variance analysis & Error analysis to prioritize next steps
4. Training and testing on different distribution
当train set与dev/test set不来自同一个分布的时候,我们应该如何解决这一问题,构建准确的机器学习模型呢?
以猫类识别为例,train set来自于网络下载(webpages),图片比较清晰;
dev/test set来自用户手机拍摄(mobile app),图片比较模糊。假如train set的大小为200000,而dev/test set的大小为10000,显然train set要远远大于dev/test set。
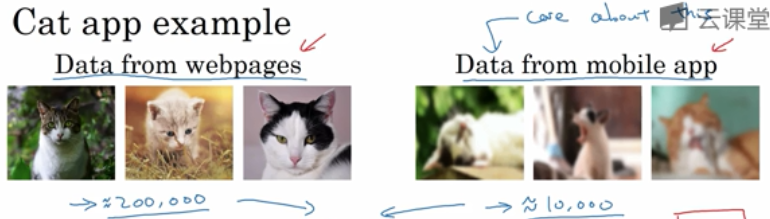
将原来的train set和一部分dev/test set组合当成train set,剩下的dev/test set分别作为dev set和test set。
例如,200000例webpages图片和5000例mobile app图片组合成train set,剩下的2500例mobile app图片作为dev set,2500例mobile app图片作为test set。其关键在于dev/test set全部来自于mobile app。这样保证了验证集最接近实际应用场合。这种方法较为常用,而且性能表现比较好。
5. Bias and Variance with mismatched data distributions
如果train set和dev/test set来源于不同分布,则无法直接根据相对值大小来判断。例如某个模型human-level error为0%,training error为1%,dev error为10%。
根据我们之前的理解,显然该模型出现了variance。但是,training error与dev error之间的差值9%可能来自算法本身(variance),也可能来自于样本分布不同。比如dev set都是很模糊的图片样本,本身就难以识别,跟算法模型关系不大。因此不能简单认为出现了variance。
方法:
-
从原来的train set中分割出一部分作为train-dev set,train-dev set不作为训练模型使用,而是与dev set一样用于 验证。
-
此时,有training error、training-dev error和dev error。其中,training error与training-dev error的差值反映了variance(方差);
-
training-dev error与dev error的差值反映了data mismatch problem,即样本分布不一致。
举例:
-
如果training error为1%,training-dev error为9%,dev error为10%,则variance问题比较突出。
-
如果training error为1%,training-dev error为1.5%,dev error为10%,则data mismatch problem比较突出。
-
通过引入train-dev set,能够比较准确地定位出现了variance还是data mismatch。
总结:(参考)

-
通常,human-level error、training error、training-dev error、dev error以及test error的数值是递增的
-
但是也会出现dev error和test error下降的情况。这主要可能是因为 训练样本 比 验证/测试样本 更加复杂,难以训练。
6. Addressing data mismatch
如何解决train set与dev/test set样本分布不一致:
-
手动进行误差分析,尝试了解training dev/test sets的具体差异
-
尝试把training data变得更像dev sets一点,或收集更多类似 dev/test sets 的数据
- 人工合成数据
7. 迁移学习
将已经训练好的模型的一部分知识(网络结构)直接应用到另一个类似模型中去。比如我们已经训练好一个猫类识别的神经网络模型,那么我们可以直接把该模型中的一部分网络结构应用到使用X光片预测疾病的模型中去。这种学习方法被称为迁移学习(Transfer Learning)。
如果已有一个训练好的神经网络,用来做图像识别。现在,我们想要构建另外一个通过X光片进行诊断的模型。
迁移学习的做法是无需重新构建新的模型,而是利用之前的神经网络模型,只改变样本输入、输出以及输出层的权重系数\(W^{[L]}, b^{[L]}, W^{[L]}, b^{[L]}\)。
也就是说对新的样本(X,Y),重新训练输出层权重系数\(W^{[L]}, b^{[L]}, W^{[L]}, b^{[L]}\),而其它层所有的权重系数 \(W^{[l]}, b^{[l]}, W^{[l]}, b^{[l]}\)保持不变。
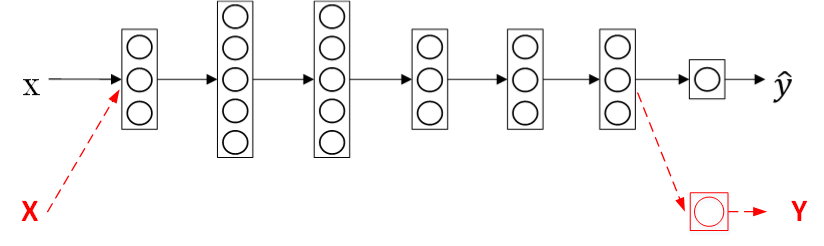
迁移学习可以保留原神经网络的一部分,再添加新的网络层。可以去掉输出层后再增加额外一些神经层。
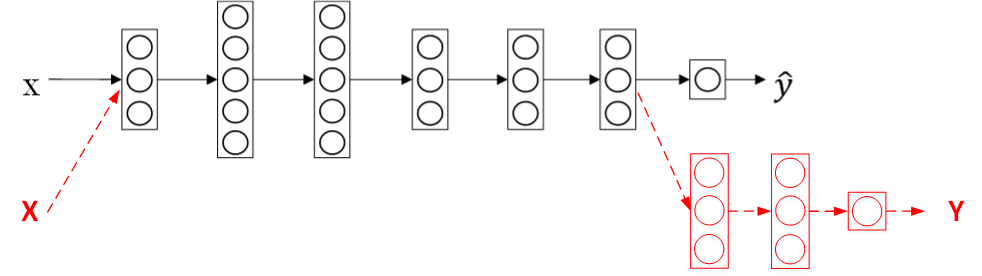
迁移学习的应用场合主要包括三点:
-
Task A 和 B 有同样的 input x.
-
Task A 的数据比 Task B 的数据多很多.(希望提高B的性能,B的数据很少)
-
A的低层次特征(Low level features) 可以帮助任务B的学习,那么迁移学习更有意义.
8. 多任务学习
多任务学习(multi-task learning)就是构建神经网络同时执行多个任务。
这跟二元分类或者多元分类都不同,多任务学习:类似将多个神经网络融合在一起,用一个网络模型来实现多种分类效果。
如果有C个,那么输出y的维度是 \((C,1)\).
例如汽车自动驾驶中,需要实现的多任务为行人、车辆、交通标志和信号灯。如果检测出汽车和交通标志,则y为:
多任务学习模型的cost function为:
其中,j表示任务下标,总有c个任务。对应的loss function为:
Multi-task learning与Softmax regression的区别
-
Softmax regression是single label的,即输出向量y只有一个元素为1;
-
而Multi-task learning是multiple labels的,即输出向量y可以有多个元素为1。
多任务学习是使用单个神经网络模型来实现多个任务。实际上,也可以分别构建多个神经网络来实现。
如果各个任务之间是相似问题(例如都是图片类别检测),则可以使用多任务学习模型。另外,多任务学习中,可能存在训练样本Y某些label空白的情况,这并不影响多任务模型的训练。
多任务学习的应用场合主要包括三点:
-
Training on a set of tasks that could benefit from having shared lower-level features.
-
Usually: 每个任务的数据量很接近
-
Can train a big enough neural network to do well on all the tasks.
迁移学习和多任务学习在实际应用中,迁移学习使用得更多一些。
9. 什么是端到端的深度学习
端到端(end-to-end)深度学习:
- 将所有不同阶段的数据处理系统 或 学习系统模块 组合在一起,用一个** 单一的神经网络模型** 来实现所有的功能。它将所有模块混合在一起,只关心输入和输出。
以语音识别为例,传统的算法流程和end-to-end模型的区别如下:
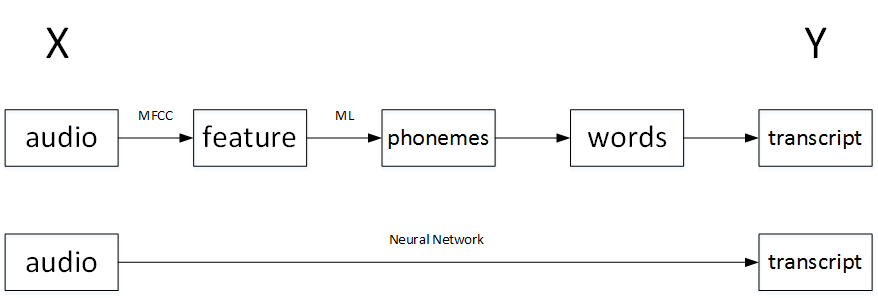
如果训练样本足够大,神经网络模型足够复杂,那么end-to-end模型性能比传统机器学习分块模型更好。
- end-to-end让神经网络模型内部去 自我训练 模型特征,自我调节,增加了模型整体契合度。
10. 是否要使用端到端的深度学习
end-to-end深度学习:
优点:
-
Let the data speak
-
Less hand-designing of components needed
缺点:
-
May need large amount of data
-
Excludes potentially useful hand-designed

