python爬虫笔记(六)网络爬虫之实战(1)——淘宝商品比价定向爬虫(解决淘宝爬虫限制:使用cookies)
1. 淘宝商品信息定向爬虫

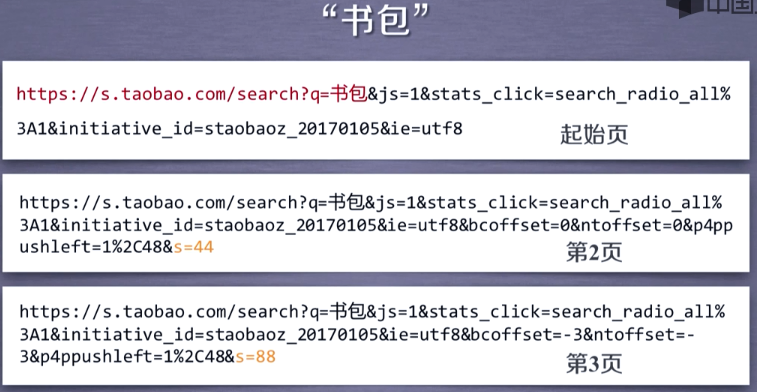

2. 实例编写
2.1 整体框架
# -*- coding: utf-8 -*- import requests import re def getHTMLText(url): print("") # 对获得的每个页面进行解析 def parsePage(ilt, html): print("") #将商品信息输出 def printGoodsList(ilt): print("") def main(): goods = '书包' depth = 2 start_url = 'http://s.taobao.com/search?q=' + goods infoList = [] # 输出结果 for i in range(depth): try: url = start_url + '&s=' + str(44*i) # 44*i对于第一个页面,以44为倍数 html = getHTMLText(url) parsePage(infoList, html) except: continue # 异常,就下一页继续 printGoodsList(infoList) if __name__ == '__main__': main()
2.2 获取HTML
def getHTMLText(url): # print("") try: coo = 'cna=tdBCFfDBNAMCAd9okXkZ1GL3; miid=112621671462202524; t=44589a73c162d6acda521ff61a2b0495; tracknick=%5Cu90AA%5Cu8272%5Cu73AB%5Cu7470; tg=0; thw=cn; cookie2=118b55b0763bd8b114d620eea8d4aad6; v=0; _tb_token_=e63a37eb038d7; _samesite_flag_=true; _m_h5_tk=bd2dfdb57cb705d14afac8d51692b104_1580480469597; _m_h5_tk_enc=75684835cca4377aa7705414649de248; hng=CN%7Czh-CN%7CCNY%7C156; lgc=%5Cu90AA%5Cu8272%5Cu73AB%5Cu7470; dnk=%5Cu90AA%5Cu8272%5Cu73AB%5Cu7470; enc=jeabZ6RdKJ8atsmP5bmmuXkTQIp4FisJU2OrrhnHtayrgkI%2FtsUaeXsHutbc9MTCk7L0WNdijmNDWJn0o%2BwwBA%3D%3D; mt=ci=99_1; unb=2617536763; uc3=lg2=UIHiLt3xD8xYTw%3D%3D&vt3=F8dBxdsSHEeVKcK%2BsbM%3D&nk2=szhk0QwZbYg%3D&id2=UU6gZj%2FUOeRMbg%3D%3D; csg=6543b61f; cookie17=UU6gZj%2FUOeRMbg%3D%3D; skt=62568256db860084; existShop=MTU4MDQ3NzcyMw%3D%3D; uc4=id4=0%40U2xt%2FitdilP1ZJbCdQFicNBGxduQ&nk4=0%40sUfhym96bE66xp4J20CKNNRngg%3D%3D; _cc_=WqG3DMC9EA%3D%3D; _l_g_=Ug%3D%3D; sg=%E7%91%B036; _nk_=%5Cu90AA%5Cu8272%5Cu73AB%5Cu7470; cookie1=BqFmPYV0x44r%2B8hbYizr0wdfD9zXP0li9qt4M4pSNa8%3D; uc1=cookie16=VFC%2FuZ9az08KUQ56dCrZDlbNdA%3D%3D&cookie21=V32FPkk%2FgihF%2FS5nr3O5&cookie15=Vq8l%2BKCLz3%2F65A%3D%3D&existShop=false&pas=0&cookie14=UoTUOqS7BqUalw%3D%3D&tag=8&lng=zh_CN; JSESSIONID=D22BBFCCE2F2B773FEA135474CDD5226; l=cBSJI40nvVoOfFrbBOfaourza77T0IRb4sPzaNbMiICPOz1H5hTfWZ0-wSYMCnGVp6KwR3kJG73QBeYBqImBfdW22j-la; isg=BL-_QNde3cIt5tswh2xd6wxtTpNJpBNGRC0kIFGMxG61YN_iWXQFli1yojCeOOu-' cookies = {} for line in coo.split(';'): # 浏览器伪装 name, value = line.strip().split('=', 1) cookies[name] = value headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"} r = requests.get(url, cookies=cookies, headers=headers, timeout=30) r.raise_for_status r.encoding = r.apparent_encoding print(r.request.url) return r.text except: print("获取失败") return ""
2.3 对每个页面进行解析

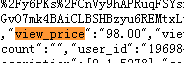
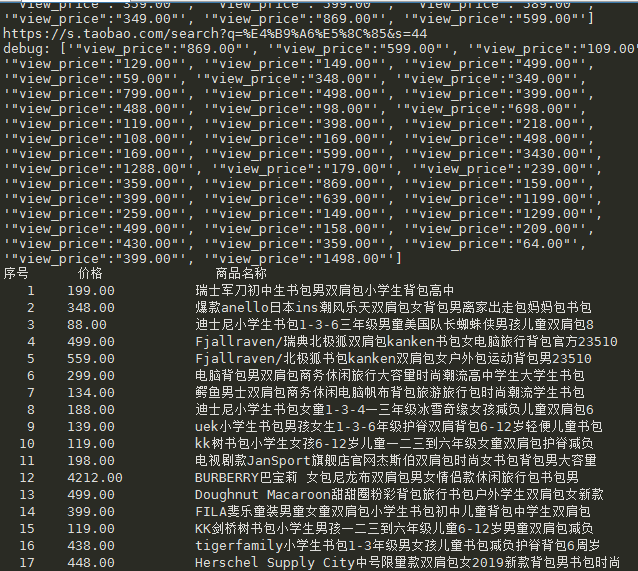
# 对获得的每个页面进行解析 def parsePage(ilt, html): try: # 获得价格 plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html) print("debug:", plt) # 获得标题 tlt = re.findall(r'\"raw_title\"\:\".*?\"', html) for i in range(len(plt)): price = eval(plt[i].split(':')[1]) # eval去掉字符串外面的双引号或单引号 title = eval(tlt[i].split(':')[1]) ilt.append([price, title]) except: print("")
3. 完整代码
# -*- coding: utf-8 -*- import requests import re def getHTMLText(url): # print("") try: coo = 'cna=tdBCFfDBNAMCAd9okXkZ1GL3; miid=112621671462202524; t=44589a73c162d6acda521ff61a2b0495; tracknick=%5Cu90AA%5Cu8272%5Cu73AB%5Cu7470; tg=0; thw=cn; cookie2=118b55b0763bd8b114d620eea8d4aad6; v=0; _tb_token_=e63a37eb038d7; _samesite_flag_=true; _m_h5_tk=bd2dfdb57cb705d14afac8d51692b104_1580480469597; _m_h5_tk_enc=75684835cca4377aa7705414649de248; hng=CN%7Czh-CN%7CCNY%7C156; lgc=%5Cu90AA%5Cu8272%5Cu73AB%5Cu7470; dnk=%5Cu90AA%5Cu8272%5Cu73AB%5Cu7470; enc=jeabZ6RdKJ8atsmP5bmmuXkTQIp4FisJU2OrrhnHtayrgkI%2FtsUaeXsHutbc9MTCk7L0WNdijmNDWJn0o%2BwwBA%3D%3D; mt=ci=99_1; unb=2617536763; uc3=lg2=UIHiLt3xD8xYTw%3D%3D&vt3=F8dBxdsSHEeVKcK%2BsbM%3D&nk2=szhk0QwZbYg%3D&id2=UU6gZj%2FUOeRMbg%3D%3D; csg=6543b61f; cookie17=UU6gZj%2FUOeRMbg%3D%3D; skt=62568256db860084; existShop=MTU4MDQ3NzcyMw%3D%3D; uc4=id4=0%40U2xt%2FitdilP1ZJbCdQFicNBGxduQ&nk4=0%40sUfhym96bE66xp4J20CKNNRngg%3D%3D; _cc_=WqG3DMC9EA%3D%3D; _l_g_=Ug%3D%3D; sg=%E7%91%B036; _nk_=%5Cu90AA%5Cu8272%5Cu73AB%5Cu7470; cookie1=BqFmPYV0x44r%2B8hbYizr0wdfD9zXP0li9qt4M4pSNa8%3D; uc1=cookie16=VFC%2FuZ9az08KUQ56dCrZDlbNdA%3D%3D&cookie21=V32FPkk%2FgihF%2FS5nr3O5&cookie15=Vq8l%2BKCLz3%2F65A%3D%3D&existShop=false&pas=0&cookie14=UoTUOqS7BqUalw%3D%3D&tag=8&lng=zh_CN; JSESSIONID=D22BBFCCE2F2B773FEA135474CDD5226; l=cBSJI40nvVoOfFrbBOfaourza77T0IRb4sPzaNbMiICPOz1H5hTfWZ0-wSYMCnGVp6KwR3kJG73QBeYBqImBfdW22j-la; isg=BL-_QNde3cIt5tswh2xd6wxtTpNJpBNGRC0kIFGMxG61YN_iWXQFli1yojCeOOu-' cookies = {} for line in coo.split(';'): # 浏览器伪装 name, value = line.strip().split('=', 1) cookies[name] = value headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"} r = requests.get(url, cookies=cookies, headers=headers, timeout=30) r.raise_for_status r.encoding = r.apparent_encoding print(r.request.url) return r.text except: print("获取失败") return "" # 对获得的每个页面进行解析 def parsePage(ilt, html): try: # 获得价格 plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html) print("debug:", plt) # 获得标题 tlt = re.findall(r'\"raw_title\"\:\".*?\"', html) for i in range(len(plt)): price = eval(plt[i].split(':')[1]) # eval去掉字符串外面的双引号或单引号 title = eval(tlt[i].split(':')[1]) ilt.append([price, title]) except: print("") #将商品信息输出 def printGoodsList(ilt): tplt = "{:4}\t{:8}\t{:16}" print(tplt.format("序号", "价格", "商品名称")) count = 0 for g in ilt: count = count + 1 print(tplt.format(count, g[0], g[1])) print("") def main(): goods = '书包' depth = 2 start_url = 'http://s.taobao.com/search?q=' + goods infoList = [] # 输出结果 for i in range(depth): try: url = start_url + '&s=' + str(44*i) # 44*i对于第一个页面,以44为倍数 html = getHTMLText(url) parsePage(infoList, html) except: continue # 异常,就下一页继续 printGoodsList(infoList) if __name__ == '__main__': main()
MOOC视频里会出错,因为响应的界面是需要登录的界面,这里我们需要设置cookies,来解决淘宝爬虫限制(需要登录验证)
在 getHTMLText()函数里添加 header和cookies,这里添加:
coo = 'cna=tdBCFfDBNAMCAd9okXkZ1GL3; miid=112621671462202524; t=44589a73c162d6acda521ff61a2b0495; tracknick=%5Cu90AA%5Cu8272%5Cu73AB%5Cu7470; tg=0; thw=cn; cookie2=118b55b0763bd8b114d620eea8d4aad6; v=0; _tb_token_=e63a37eb038d7; _samesite_flag_=true; _m_h5_tk=bd2dfdb57cb705d14afac8d51692b104_1580480469597; _m_h5_tk_enc=75684835cca4377aa7705414649de248; hng=CN%7Czh-CN%7CCNY%7C156; lgc=%5Cu90AA%5Cu8272%5Cu73AB%5Cu7470; dnk=%5Cu90AA%5Cu8272%5Cu73AB%5Cu7470; enc=jeabZ6RdKJ8atsmP5bmmuXkTQIp4FisJU2OrrhnHtayrgkI%2FtsUaeXsHutbc9MTCk7L0WNdijmNDWJn0o%2BwwBA%3D%3D; mt=ci=99_1; unb=2617536763; uc3=lg2=UIHiLt3xD8xYTw%3D%3D&vt3=F8dBxdsSHEeVKcK%2BsbM%3D&nk2=szhk0QwZbYg%3D&id2=UU6gZj%2FUOeRMbg%3D%3D; csg=6543b61f; cookie17=UU6gZj%2FUOeRMbg%3D%3D; skt=62568256db860084; existShop=MTU4MDQ3NzcyMw%3D%3D; uc4=id4=0%40U2xt%2FitdilP1ZJbCdQFicNBGxduQ&nk4=0%40sUfhym96bE66xp4J20CKNNRngg%3D%3D; _cc_=WqG3DMC9EA%3D%3D; _l_g_=Ug%3D%3D; sg=%E7%91%B036; _nk_=%5Cu90AA%5Cu8272%5Cu73AB%5Cu7470; cookie1=BqFmPYV0x44r%2B8hbYizr0wdfD9zXP0li9qt4M4pSNa8%3D; uc1=cookie16=VFC%2FuZ9az08KUQ56dCrZDlbNdA%3D%3D&cookie21=V32FPkk%2FgihF%2FS5nr3O5&cookie15=Vq8l%2BKCLz3%2F65A%3D%3D&existShop=false&pas=0&cookie14=UoTUOqS7BqUalw%3D%3D&tag=8&lng=zh_CN; JSESSIONID=D22BBFCCE2F2B773FEA135474CDD5226; l=cBSJI40nvVoOfFrbBOfaourza77T0IRb4sPzaNbMiICPOz1H5hTfWZ0-wSYMCnGVp6KwR3kJG73QBeYBqImBfdW22j-la; isg=BL-_QNde3cIt5tswh2xd6wxtTpNJpBNGRC0kIFGMxG61YN_iWXQFli1yojCeOOu-' cookies = {} for line in coo.split(';'): # 浏览器伪装 name, value = line.strip().split('=', 1) cookies[name] = value
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"}
r = requests.get(url, cookies=cookies, headers=headers, timeout=30)
coo里是你网页的cookies(本地先登录一下)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号