python爬虫笔记(四)网络爬虫之提取—Beautiful Soup库(3)基于bs4库的格式化和编码
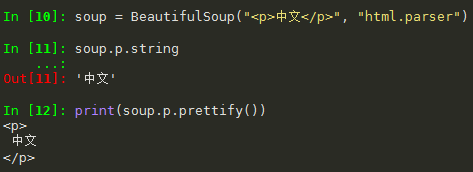
1. prettify()
import requests from bs4 import BeautifulSoup r = requests.get("http://python123.io/ws/demo.html") demo = r.text print(demo, "\n") soup = BeautifulSoup(demo, "html.parser") print(soup.prettify())

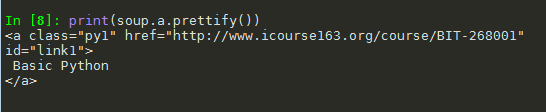
2. 打印标签
3. 总结

