会员
周边
新闻
博问
闪存
赞助商
Chat2DB
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
douzi
博客园
首页
新随笔
联系
订阅
管理
python爬虫笔记(四)网络爬虫之提取—Beautiful Soup库(2)基于bs4库的HTML内容遍历方法
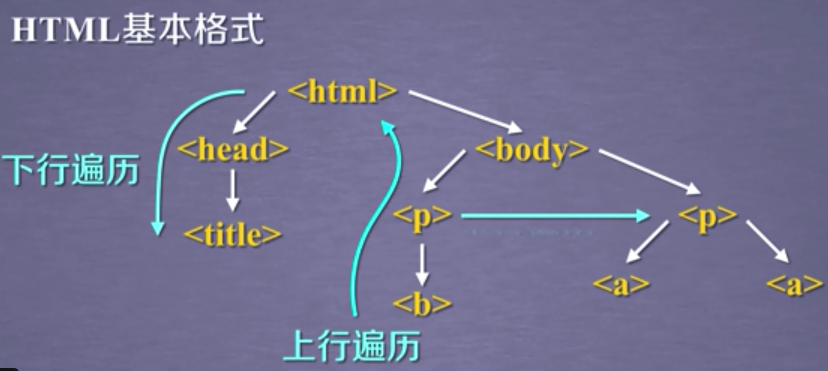
1. 基于bs4库的HTML内容遍历方法
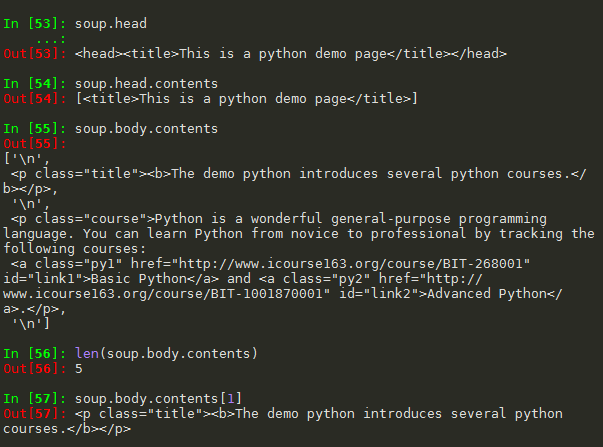
1.1 .contents 举例
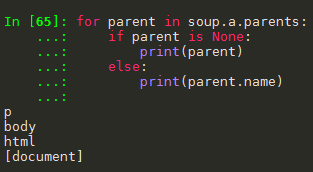
1.2 结点的父亲标签
1.3 标签树的上行遍历(parents)
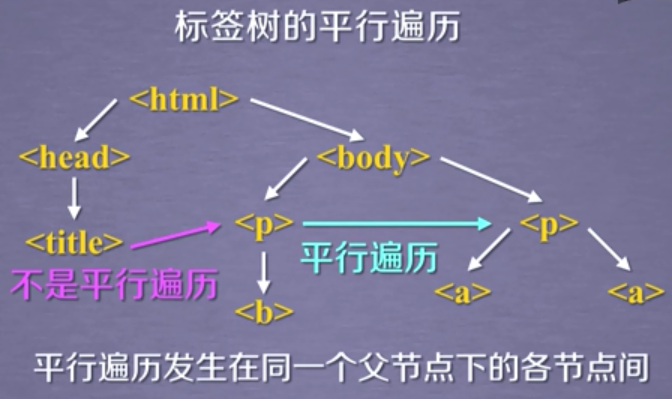
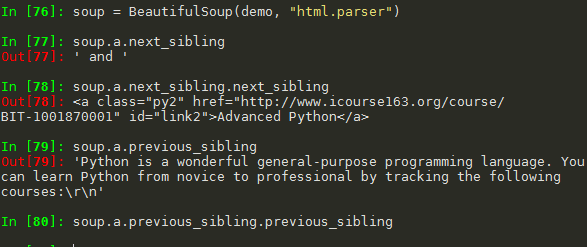
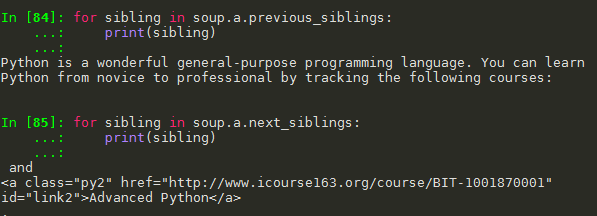
1.4 标签树的平行遍历
注意:标签的儿子结点可能是 NavigableString
posted @
2020-01-22 18:06
douzujun
阅读(
257
) 评论(
0
)
收藏
举报
刷新页面
返回顶部
公告








 浙公网安备 33010602011771号
浙公网安备 33010602011771号