千万级数据的表,我把慢sql优化后性能提升30倍!
分享技术,用心生活
背景:系统中有一个统计页面加载特别慢,前端设置的40s超时时间都加载不出来数据,因为是个统计页面,基本上一猜就知道是mysql的语句有问题,遗留了很久没有解决,正好趁不忙的时候,下定决心一定把它给搞定!
1. 分析原因
(mysql5.7)
执行一下问题sql,可以看到单表查就需要61s 这怎么能忍受?

通过explain看一下执行计划

挑重点,可以看到用命中了名为idx_first_date的索引,但是rows中扫描了1000多万行的数据,这显然是sql慢的根源。我们来查一下表数据量:
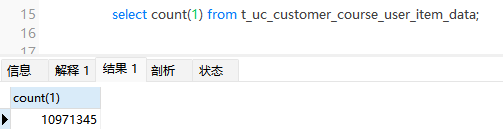
真真的千万级的大表!
找到原因后,那么就需要明确优化方向
- 通过设置分区
- 通过水平分表
- 通过优化sql
我们大概会有以上三种思路
分区方案会有诸多限制,比如可能会索引失效,占用内存,有主键限制等,故不采纳
分表方案看来可行,通过缩小热点数据,把非热点数据全部放入分表。是可以达到效果。不过查询表写入日期后,发现最早在2021年。目前系统内查询统计还会经常用到2021年数据。如果贸然分表后,带来的连表查询,数据管理问题等,现有代码可能会出大问题。
那么就只剩下优化sql这一条路了,虽然是千万级数据的表,但是你要相信mysql是可以支撑的。
确定方向后,那就需要解决如何通过减少数据的扫描来实现提升性能。
通过sql可以看到,这个统计sql是根据日期查询的,而且也命中了索引,那么为什么还会扫描这么多数据呢?我们再去看下表的索引

发现猫腻了吧,idx_first_date是个联合索引,再根据上图key_len长度为67和最左匹配原则可知,mysql执行器是优先使用customer_id去扫描数据。所以几乎全表扫描了。
我们把idx_first_date修改一下联合索引的字段顺序,把first_date放在第一位,我们再来执行一下sql看下结果

1.6s!大呼!性能直接提升30倍!
你以为到这里就结束了吗?不不不!再看一张图

发现了吗,因为用了联合索引,导致索引占用空间过大,比数据占用都大。我认为这里存在滥用索引的现象。索引本身不止会占用空间,而且也会降低写入性能,维护更新索引成本过高等。
把idx_first_date中的customer_id字段去掉,再看下索引占用情况
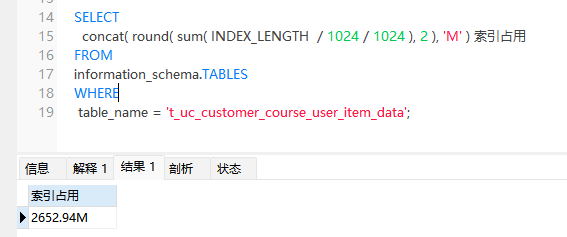
下降至2.6G,减少了将近1.4G的索引占用。
至此,这张千万数据的大表慢sql已优化完,不仅提升了查询性能,也减少了索引带来的空间占用过大的问题。
本文由mdnice多平台发布

 浙公网安备 33010602011771号
浙公网安备 33010602011771号