【转】Tesseract-OCR 字符识别
网上看到的这篇文章,自己试了一试:

自己手写了一个,识别的结果是: “s6 7” 不能说一模一样,那也是相当靠谱啊。
这还是没通过jTessBoxEditorFX训练的情况下。
如果不是手写,用标准的数字测试,就能识别正确。厉害了
以下是转载内容:
转载地址:
Windows安装Tesseract-OCR 4.00并配置环境变量 - SegmentFault 思否
一、前言
Tesseract-OCR 是一款由HP实验室开发由Google维护的开源OCR(Optical Character Recognition , 光学字符识别)引擎。与Microsoft Office Document Imaging(MODI)相比,我们可以不断的训练的库,使图像转换文本的能力不断增强;如果团队深度需要,还可以以它为模板,开发出符合自身需求的OCR引擎。
GitHub 地址:https://github.com/tesseract-...
安装包官方下载地址:https://digi.bib.uni-mannheim...
安装包百度云盘下载地址:https://pan.baidu.com/s/1AOsJ...
二、安装 Tesseract-OCR
直接执行下载好的 exe 文件,下一步、下一步默认安装即可。
三、配置环境变量
3.1 进入环境变量配置界面
右键点击此电脑--属性--高级系统设置--环境变量--系统变量--Path
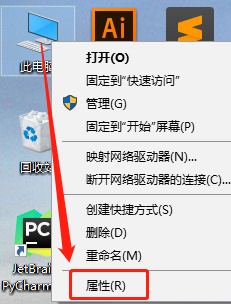
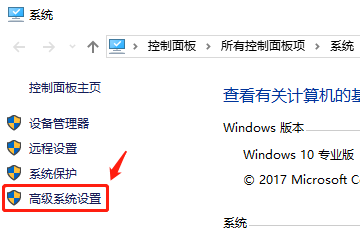

3.2 添加系统变量
找到系统变量的 Path ,将 Tesseract-OCR 的安装目录添加进去:

3.3 添加 tessdata 系统变量
如下图新建系统变量 : TESSDATA_PREFIX
变量值为 tessdata 文件夹的路径(在Tesseract-OCR的安装目录下):
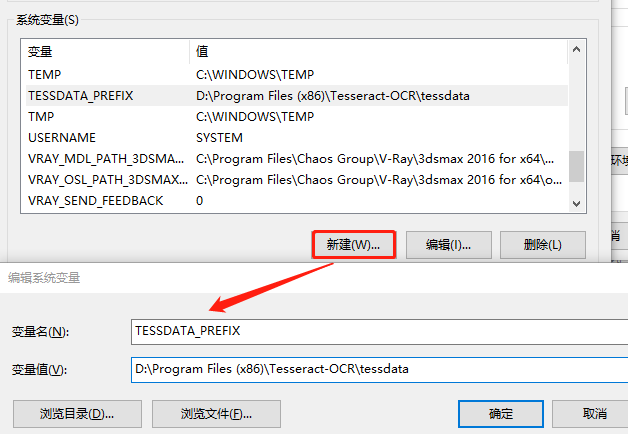
四、使用 Tesseract-OCR
4.1 进入cmd 输入下面的命令查看版本,正常运行则安装成功:
tesseract --version

4.2 使用下面命令识别图片

tesseract 图片路径 输出文件

查看输出的 result.txt文件:
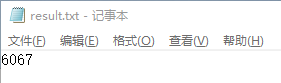
结果正确!
作者:宋桓公
出处:http://www.cnblogs.com/douzi2/
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!欢迎各位转载,但是未经作者本人同意,转载文章之后必须在文章页面明显位置给出作者和原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号