前馈和反向传播
前馈和反向传播
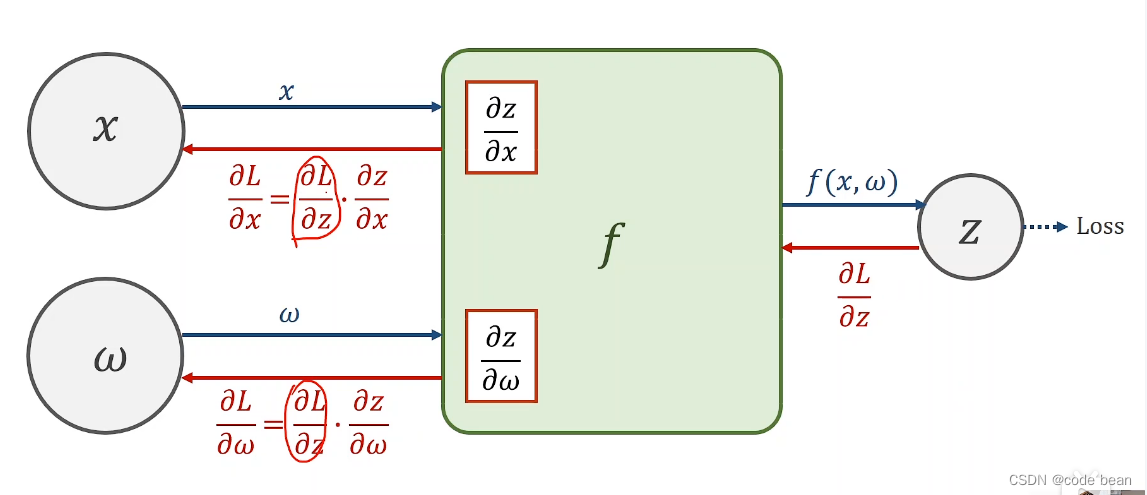
x: 样本
w: 权重
f: 模型函数
z: 预测值
loss: 损失函数
正向传播时,函数为f,x,w是变量z是因变量。
反向传播时,函数为loss(L),z是变量x,w是因变量。
正向和反向的过程
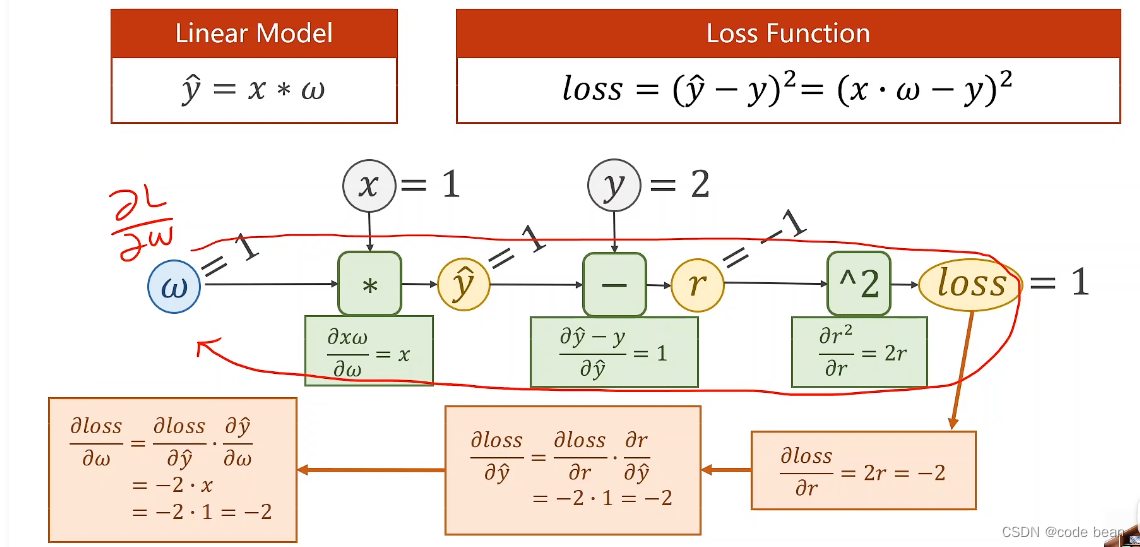
从这张图我们可以看到,整个过程是先预测,有了预测值之后就可以计算loss,那么其实loss函数其实是包含了预测模型函数的。那反向传播的过程其实loss对权重w求导,在求导的过程中w是未知数,x和y是已知数。
反向传播就是一个链式求导的过程!
pytorch函数实现
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
# 给一个初始化的w值
w = torch.Tensor([1.0])
w.requires_grad = True
def forward(x):
return x * w
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
if __name__ == '__main__':
print("predict (before training)", 4, forward(4).item())
for epoch in range(10):
for x, y in zip(x_data, y_data):
l = loss(x, y) # 构建计算图
l.backward() # 注意这里计算的是梯度,w再根据梯度更新自己(反向传播后,会释放计算图)
print('\tgrad:', x, y, w.grad.item())
w.data = w.data - 0.01 * w.grad.data # w根据梯度更新自己
w.grad.data.zero_() # 注意这里是梯度清零!避免下次反向传播的时候别积累
print("progress:", epoch, l.item())
print("predict (after training)", 4, forward(4).item())代码过程解析
- 代码中的loss函数,其实是构建了上方的计算图(输入+模块+输出),看到这个函数就立马能画出计算图!
- l.backward()为反向传播的计算过程!在运行该句代码之前,w.grad为空!运行了l.backward()之后w.grad才有值。所以这里的w.grad存储的梯度为L对w的倒数(见图1)。有了这个倒数之后,我们通过梯队下降法,就可以一步步迭代找到那个w, 那个能使得L最小的W!
- 用data计算不会构建计算图
- 这里有个疑问,既然w.grad每次都是从新计算的,为啥在backward后还要清零?这是因为backward函数是这么设计的:
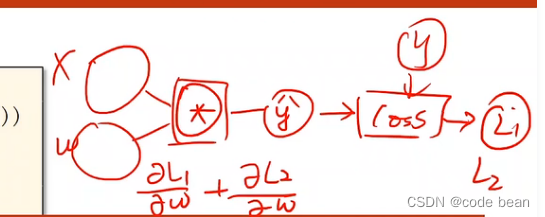
他会将每一轮的梯度进行累加(有的时候需要这样操作),在这里我们不希望累加,所以要进行清零!
小结:
- 构建loss计算图
- 前馈算损失,反向传播的时候作为输入要用!
- 反向传播算梯度
- 根据梯度更新权重w,梯度清零
- 根据新的w,构建计算图。
- 。。循环往复,直到loss的值越来越小。
作者:宋桓公
出处:http://www.cnblogs.com/douzi2/
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!欢迎各位转载,但是未经作者本人同意,转载文章之后必须在文章页面明显位置给出作者和原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号