理解 YOLOV1 第一篇 预测阶段
首先看YOLOV1的网络结构,感觉就是普通的卷积神经网络:
最终输出是一个7*7*30的黑盒子,把它想象成一本7*7大小的有着30页的一本书。
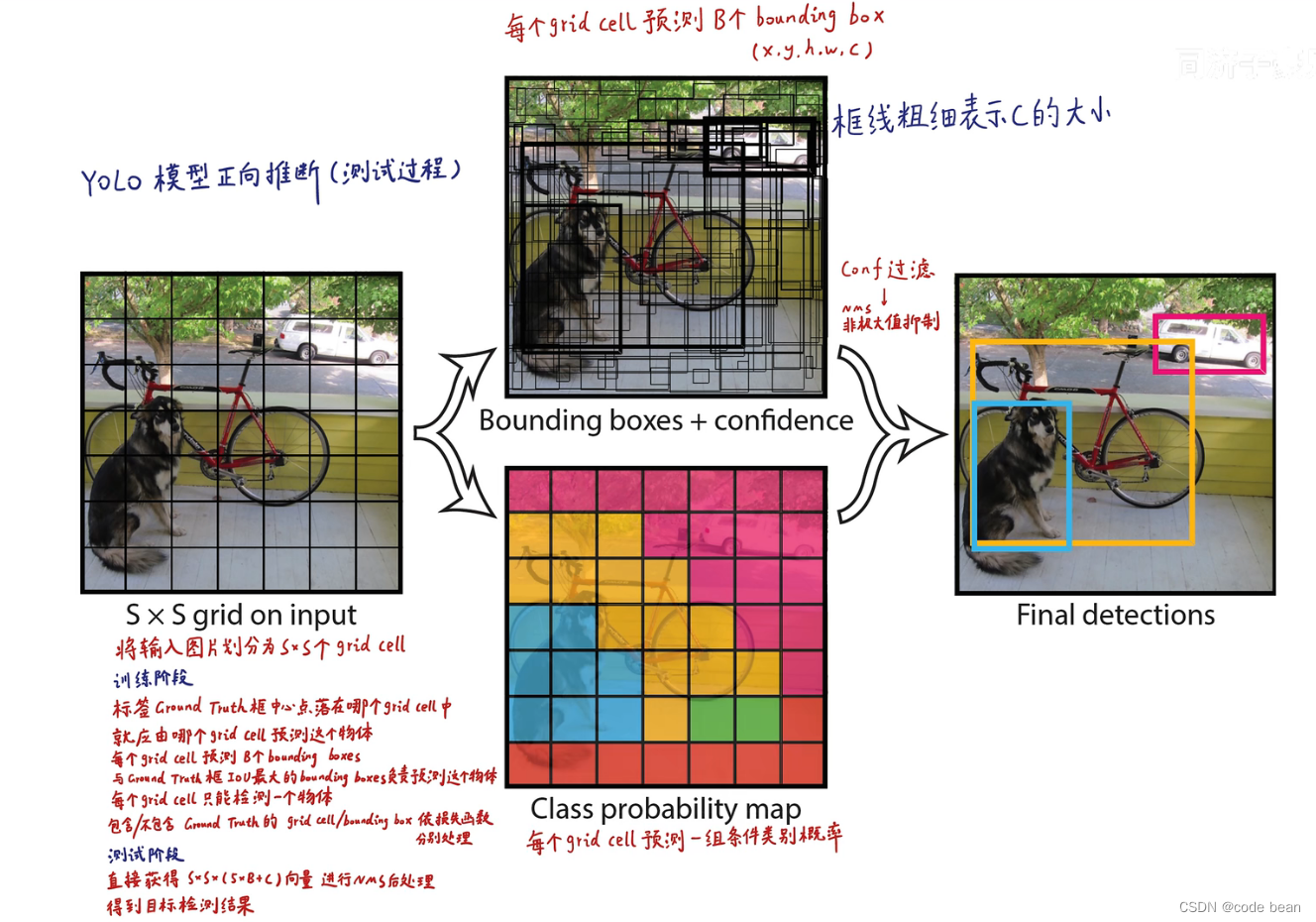
书的每一页,由49个方格(grid cell)组成, V1版本中每个grid cell预测2个选框(bounding box,bounding box的中心落于该gridcell)所以一共可以生成98个bounding box。
每个bounding box,含5个参数:
1 x,y bounding box的中心点的位置
2 h,w bounding box的宽高
3 c 是否包含目标物体的置信度(这个置信度,应该就是交并比)
视角在切回grid cell,grid cell还包含每个类别的概率,用grid cell的类别概率,乘以grid cell自己生成的bounding box的置信度,就获得该bounding box对应各个类别的概率。
这样的话,过滤掉概率低的,这个含有位置信息和类别信息的框框就可以画出来了。
再次整体看看这个黑盒子:

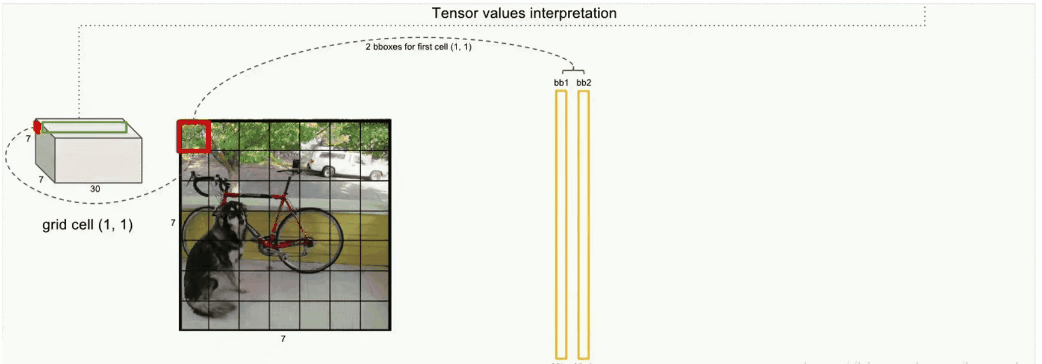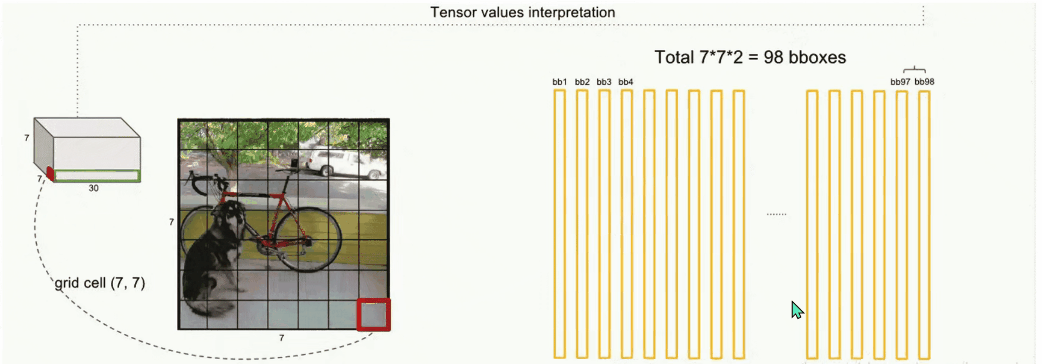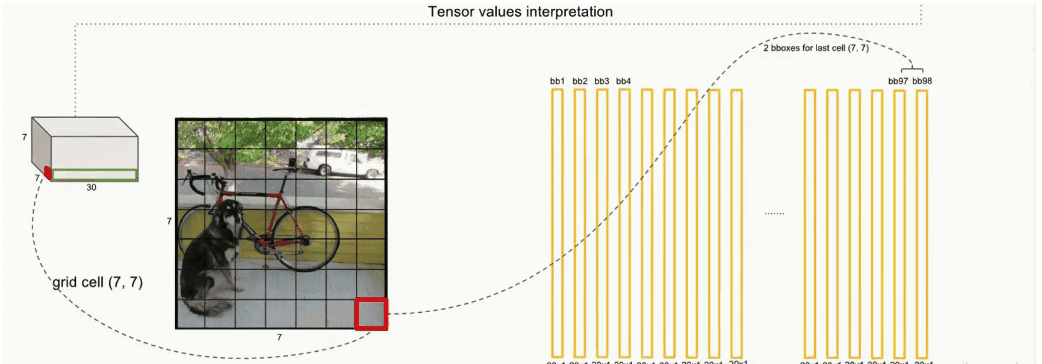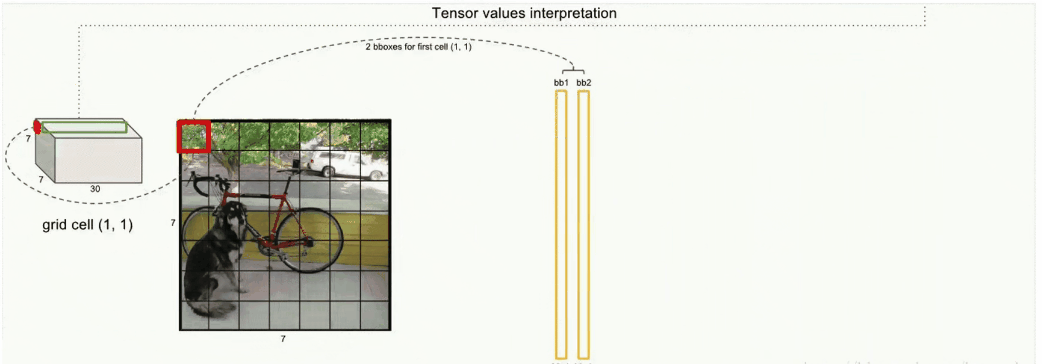
那,刚刚我们看的是黑盒子的左视图,那刚刚也提到了每个grid cell也包含了 很多的信息。那么看这幅图的正视图将更加的清楚(及每个或者说49个grid cell都是由深度的,这个深度是30)。
这里,我们就专注看,其实一个grid cell 和它包含的深度信息:
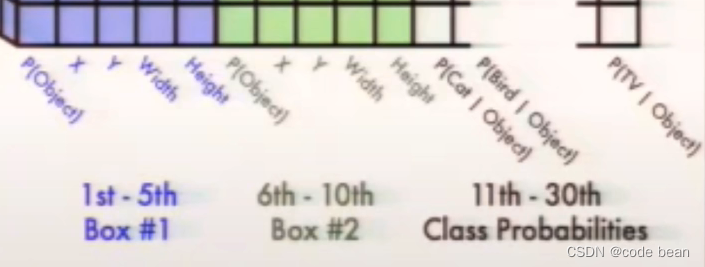
之前讲到 ,每个grid cell可预测2个选框(bounding box),紫色和绿色就是这两个bounding box部分,每个bounding box含5个参数,没错就是上面提到的5个参数。最后20个维度存放的是该grid cell对应的20种类别的概率。看到这里我们就大概知道了。V1版本一张图片最多能生成98个选框,最多能分20种类别。
小结
为了更好的理解,这里强调几点:
- grid cell和bounding box是有着对应关系的:每个grid cell对应两个bounding box
- bounding box包含是否含有物体的置信度(这里有待进一步确认具体是什么的置信度)
- grid cell包含每个类别的概率.
- 两个bounding box分别有一个置信度,如果下图所示:

红色的框框代表grid cell,两个黑色的框框代表grid cell生成的两个bounding boxes,线越粗代表置信度越高。两个bounding box共享该grid cell类别的概率。概率和置信度相乘,将得到这个类别判断的全概率。
看看这种动图,应该能更好的理解:
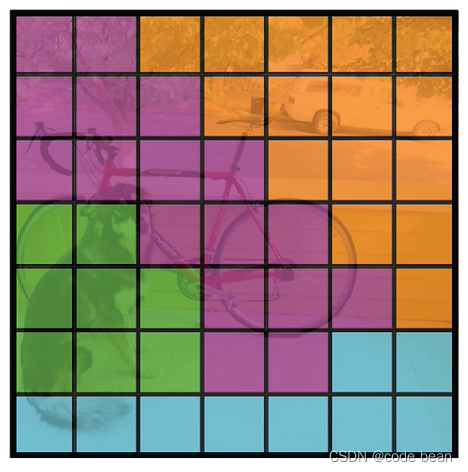
继续分析:如果规定每个grid中类别概率最大值涂上自己的专属颜色,那么就可能得到如下效果:
参考资料
作者:宋桓公
出处:http://www.cnblogs.com/douzi2/
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!欢迎各位转载,但是未经作者本人同意,转载文章之后必须在文章页面明显位置给出作者和原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号