
并发编程----操作系统详解和进程的介绍
操作系统详解和进程的介绍
一,操作系统详解
-
为什么要有操作系统
程序员无法把所有的硬件操作细节都了解到,管理这些硬件并且加以优化使用是非常繁琐的工作,这个繁琐的工作就是操作系统来干的,有了他,程序员就从这些繁琐的工作中解脱了出来,只需要考虑自己的应用软件的编写就可以了,应用软件直接使用操作系统提供的功能来间接使用硬件
-
什么是操作系统
-
操作系统就是一个协调,管理,控制计算机硬件资源和软件资源的控制程序
-
操作系统位于计算机硬件与应用软件之间,本质也是一个软件.操作系统由操作系统的内核(运行于内核态,管理硬件资源)以及系统调用(运行于用户态,为应用程序员写的应用程序提供系统调用接口)两部分组成,所以,单纯的说操作系统是运行于内核态的,是不准确的.
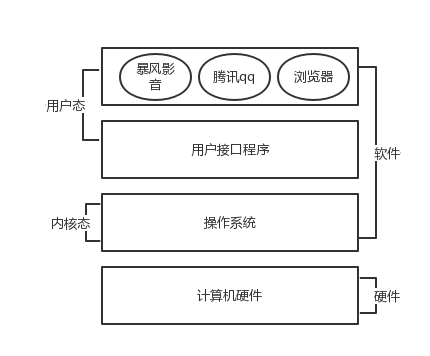
-
操作系统的作用:
-
隐藏了丑陋的硬件调用接口,为应用程序猿提供调用硬件资源的更好,更简单,更清晰的模型(系统调用接口),应用程序员有了这些接口后,就不用再考虑操作硬件的细节,专心开发自己的应用程序即可.
例如:操作系统提供了文件这个抽象概念,对文件的操作就是对磁盘的操作,有了文件我们无需再去考虑关于磁盘的读写控制(比如控制磁盘转动,移动磁头读写数据等细节) -
合理的调度分配多个进程与CPU的关系,让其有序化
例如:同一台计算机上同时运行三个程序,它们三个想在同一时刻在同一台计算机上输出结果,那么开始的几行可能是程序1的输出,接着几行是程序2的输出,然后又是程序3的输出,最终将是一团糟(程序之间是一种互相竞争资源的过程)
操作系统将打印机的结果送到磁盘的缓冲区,在一个程序完全结束后,才将暂存在磁盘上的文件送到打印机输出,同时其他的程序可以继续产生更多的输出结果(这些程序的输出没有真正的送到打印机),这样,操作系统就将由竞争产生的无序变得有序化.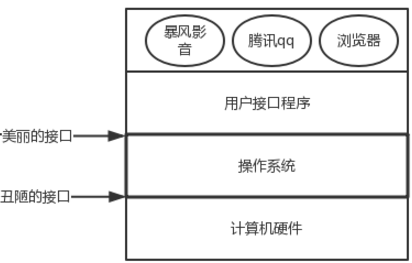
-
操作系统与普通软件的区别
- 操作系统由硬件保护,不能被用户修改
- 特别地,操作系统是一个大型、复杂、长寿的软件
二, 操作系统的发展史
-
第一代(1940~1955):手工操作----穿孔卡片
-
特点:
没有操作系统的概念
所有的程序设计都是直接操控硬件 -
工作过程:
程序员在墙上的机时表预约一段时间,然后程序员拿着他的插件版到机房里,将自己的插件板接到计算机里,这几个小时内他独享整个计算机资源,后面的一批人都得等着(两万多个真空管经常会有被烧坏的情况出现)
后来出现了穿孔卡片,可以将程序写在卡片上,然后读入计算机而不用插件板:
程序员将对应于程序和数据的已穿孔的纸带(或卡片)装入输入机,然后启动输入机把程序和数据输入计算机内存,接着通过控制台开关启动程序针对数据运行;计算完毕,打印机输出计算结果;用户取走结果并卸下纸带(或卡片)后,才让下一个用户上机
-
优点:
程序员在申请的时间段内独享整个资源,可以即时地调试自己的程序(有bug可以立刻处理)
-
缺点:
- 浪费计算机资源,一个时间段内只有一个人用
- 同一时刻只有一个程序在内存中,被cpu调用执行,所有程序都是串行的
-
-
第二代(1955~1965): 磁带存储---批处理系统
-
特点:
不需要程序员本人进行硬件的操作,所有的硬件的操作都已经是成型的机器了.每个程序员将自己的程序刻在磁盘上,就可以走了,中间有专业人员将你的代码磁盘运行,最后打印结果,有了操作系统的概念
-
工作过程:
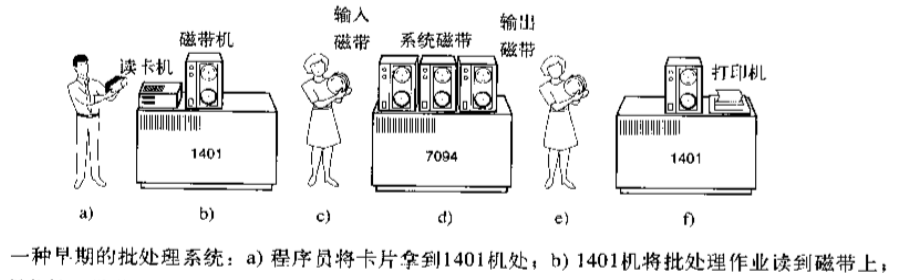
-
优点:
批处理,节省了机时(省去了每个程序员调试机器的时间)
-
缺点:
- 整个流程需要人参与控制
- cpu仍然是串行处理
- 不能独享计算机,无法及时调试程序
-
-
第三代(1955~1965): 集成电路,多道程序系统
-
第三代计算机的产生背景:
20世纪60年代初期,大多数计算机厂商都有两条完全不兼容的生产线
一条是面向字的:大型的科学计算机,主要用于科学计算和工程计算(计算密集型)
另外一条是面向字符的:商用计算机,主要用于银行和保险公司从事磁带归档和打印服务(I/O密集型)
开发和维护完全不同的产品是昂贵的,同时不同的用户对计算机的用途不同
IBM公司试图通过引入system/360系列来同时满足科学计算和商业计算,第一个采用了(小规模)芯片(集成电路)的主流机型,与采用晶体管的第二代计算机相比,性价比有了很大的提高. -
多道技术
-
cpu在执行一个任务的过程中,若需要操作硬盘,则发送操作硬盘的指令,指令一旦发出,硬盘上的机械手臂滑动读取数据到内存中,这一段时间,cpu需要等待,时间可能很短,但对于cpu来说已经很长很长,长到可以让cpu做很多其他的任务,如果我们让cpu在这段时间内切换到去做其他的任务,这样cpu不就充分利用了吗,这正是多道技术产生的技术背景.
-
多道技术中的多道指的是多个程序,多道技术的实现是为了解决多个程序竞争或者说共享同一个资源(比如cpu)的有序调度问题,解决方式即多路复用,多路复用分为时间上的复用和空间上的复用
-
空间上的复用: 将内存分为几部分,每个部分放入一个进程,这样,同一时间内存中就有了多道进程
-
时间上的复用:当一个程序在等待i/o时,另一个程序可以使用CPU,如果内存中可以同时存放足够多的作业,则CPU的利用率可以接近100%(操作系统采用了多道技术后,可以控制进程的切换,或者说进程之间争抢CPU的执行权限,这种切换不仅会在一个进程遇到I/O时进行,一个进程占用CPU时间过长也会被切换,或者被操作系统夺走CPU的执行权限,所以进程如果没有I/O阻塞,多道技术就会影响最终执行效率
-
详细解释
现代计算机或者网络都是多用户的,多个用户不仅共享硬件,而且共享文件,数据库等信息,共享意味着冲突和无序. 操作系统主要使用来 1.记录哪个程序使用什么资源 2.对资源请求进行分配 3.为不同的程序和用户调解互相冲突的资源请求 可将上述操作系统的功能总结为: 处理来自多个程序发起的多个(多个即多路)共享(共享即复用)资源的请求,简称多路复用 多路复用有两种实现方式: 1.时间上的复用 当一个资源在时间上复用时,不同的程序或用户轮流使用它,第一个程序获取该资源使用结束后,在轮到第二个。。。第三个。。。 例如: 只有一个cpu,多个程序需要在该cpu上运行,操作系统先把cpu分给第一个程序,在这个程序运行的足够长的时间(时间长短由操作系统的算法说了算)或者遇到了I/O阻塞,操作系统则把cpu分配给下一个程序,以此类推,直到第一个程序重新被分配到了cpu然后再次运行,由于cpu的切换速度很快,给用户的感觉就是这些程序是同时运行的,或者说是并发的,或者说是伪并行的.至于资源如何实现时间复用,或者说谁应该是下一个要运行的程序,以及一个任务需要运行多长时间,这些都是操作系统的工作 2.空间上的复用 每个客户都获取了一个大的资源中的一小部分资源,从而减少了排队等待资源的时间 例如: 多个运行的程序同时进入内存,硬件层面提供保护机制来确保各自的内存是分割开的,且由操作系统控制,这比一个程序独占内存一个一个排队进入内存效率要高的多 有关空间复用的其他资源还有磁盘,在许多系统中,一个磁盘同时为许多用户保存文件.分配磁盘空间并且记录谁正在使用哪个磁盘块是操作系统资源管理的典型任务 这两种方式合起来便是多道技术- 空间上的复用最大的问题是: 程序之间的内存必须分割,这种分割需要在硬件层面实现,由操作系统控制.如果内存彼此不分割,则一个程序可以访问另外一个程序的内存,丧失安全性和稳定性
- 缺点: 无法独享计算机资源,无法即时调试自己的程序
- 分时操作系统: 多个联机终端 + 多道技术
- 计算机能够为许多用户提供快速的交互式服务,所有的用户都以为自己独享了计算机资源
- CTSS: 麻省理工(MIT)在一台改装过的7094机上开发成功的,CTSS兼容分时系统,第三代计算机广泛采用了必须的保护硬件(程序之间的内存彼此隔离)之后,分时系统才开始流行
-
-
-
第四代(1980~至今): 现代计算机
-
进入20世纪80年代,大规模集成电路工艺技术的飞跃发展,微处理机的出现和发展,掀起了计算机大发展大普及的浪潮.一方面迎来了个人计算机的时代,同时又向计算机网络、分布式处理、巨型计算机和智能化方向发展.于是,操作系统有了进一步的发展,如: 个人计算机操作系统、网络操作系统、分布式操作系统等
-
个人计算机操作系统:
个人计算机上的操作系统是联机交互的单用户操作系统,它提供的联机交互功能与通用分时系统提供的功能很相似.由于是个人专用,因此一些功能会简单得多.然而,由于个人计算机的应用普及,对于提供更方便友好的用户接口和丰富功能的文件系统的要求会愈来愈迫切.
-
网络操作系统:
计算机网络: 通过通信设施,将地理上分散的、具有自治功能的多个计算机系统互连起来,实现信息交换、资源共享、互操作和协作处理的系统.
网络操作系统: 在原来各自计算机操作系统上,按照网络体系结构的各个协议标准增加网络管理模块,其中包括: 通信、资源共享、系统安全和各种网络应用服务. -
分布式操作系统:
- 表面上看,分布式系统与计算机网络系统没有多大区别.分布式操作系统也是通过通信网络,将地理上分散的具有自治功能的数据处理系统或计算机系统互连起来,实现信息交换和资源共享,协作完成任务.
- 分布式: 将一个大的任务拆分成几个小的任务,分配给不同的任务处理机制,具体怎么分配是由系统中的算法决定的,大家同时来运行自己的任务,然后各自将任务的结果再返回给你这个大的任务.
- 区别:
- 分布式系统要求一个统一的操作系统,实现系统操作的统一性
- 分布式操作系统管理分布式系统中的所有资源,它负责全系统的资源分配和调度、任务划分、信息传输和控制协调工作,并为用户提供一个统一的界面
- 用户通过这一界面,实现所需要的操作和使用系统资源,至于操作定在哪一台计算机上执行,或使用哪台计算机的资源,则是操作系统完成的
- 分布式系统更强调分布式计算和处理,因此对于多机合作和系统重构、坚强性和容错能力有更高的要求,希望系统有: 更短的响应时间、高吞吐量和高可靠性
-
-
三, 进程的介绍
一,程序和进程
-
进程:正在进行的一个过程或者说是一个任务,而负责执行任务的是CPU
-
单核+多道,实现多个进程的并发
-
程序:一堆代码,一堆文件
-
同一个程序执行两次,那也是两个进程,比如打开暴风影音虽然都是同一个软件,但是一个可以播放天空之城,一个可以播放七龙珠
二, 并发与并行
- 无论是并行还是并发,在用户看来都是'同时'运行的,不管是进程还是线程,都只是一个任务而已,真是干活的是cpu,cpu来做这些任务,而一个cpu同一时刻只能执行一个任务
- 串行: 所有的进程由cpu一个一个的解决
- 并发: 单个cpu,同时执行多个进程(多道技术),看起来像是同时运行
- 并行: 多个cpu,真正的同时运行多个进程

三, 同步\异步and阻塞\非阻塞
- 同步: 所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不会返回.按照这个定义,其实绝大多数函数都是同步调用.但是一般而言,我们在说同步、异步的时候,特指那些需要其他部件协作或者需要一定时间完成的任务
- 异步: 异步的概念和同步相对.当一个异步功能调用发出后,调用者不能立刻得到结果.当该异步功能完成后,通过状态、通知或回调来通知调用者.如果异步功能用状态来通知,那么调用者就需要每隔一定时间检查一次,效率就很低.如果是使用通知的方式,效率则很高,因为异步功能几乎不需要做额外的操作.至于回调函数,其实和通知没太多区别.
- 阻塞: 阻塞调用是指调用结果返回之前,当前线程会被挂起(如遇到I/O操作 ,recv, accept, read input,write, sleep等等),函数只有在得到结果之后才会将阻塞的线程激活.有人也许会把阻塞调用和同步调用等同起来,实际上他是不同的.对于同步调用来说,很多时候当前线程还是激活的,只是从逻辑上当前函数没有返回而已
- 注: 当没有阻塞的进程被计算机强制挂起的时候,不叫阻塞
- 非阻塞: 非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前也会立刻返回,同时该函数不会阻塞当前线程.
- 总结:
- 同步与异步针对的是函数/任务的调用方式: 同步就是当一个进程发起一个函数(任务)调用的时候,一直等到函数(任务)完成,而进程继续处于激活状态.而异步情况下是当一个进程发起一个函数(任务)调用的时候,不会等函数返回,而是继续往下执行,当函数返回的时候通过状态、通知、事件等方式通知进程任务完成.
- 阻塞与非阻塞针对的是进程或线程: 阻塞是当请求不能满足的时候就将进程挂起,而非阻塞则不会阻塞当前进程.
四, 进程的创建
-
对于通用系统(跑很多应用程序),需要有系统运行过程中创建或撤销进程的能力,主要分为四种形式创建新的进程
-
系统初始化
-
一个进程在运行过程中开启了子进程
-
用户的交互式请求,而创建一个新进程(如用户双击暴风影音)
-
一个批处理作业的初始化(只在大型机的批处理系统中应用)
-
-
新进程的创建都是由一个已经存在的进程执行了一个用于创建进程的系统调用而创建的:
- python中,如果一次想开启多个进程,必须是一个主进程,开启多个子进程
# 开启进程的2种方式
# 第一种方式
from multiprocessing import Process
import time
def task(name):
print(f'{name} is running')
time.sleep(9)
print(f'{name} is done')
if __name__ == '__main__': # windows必须在main下开启多进程
p = Process(target=task, args=('子进程',)) # args一定是一个元组
p.start() # 通知操作系统在内存种开辟一个空间,将p这个进程放进去,让cpu执行
print('===>主进程')
----------------------------------------------------
# 第二种方式
from multiprocessing import Process
import time
class MyProcess(Process):
def __init__(self, name):
super().__init__() # 必须继承父类的init
self.name = name
def run(self): # 必须是run
print(f'{self.name} is running')
time.sleep(9)
print(f'{self.name} is done')
if __name__ == '__main__':
p = MyProcess('子进程')
p.start()
print('===>主进程')
- 关于创建的子进程,UNIX和windows
- 相同的是: 进程创建后,父进程和子进程有各自不同的地址空间(多道技术要求物理层面实现进程之间内存的隔离),任何一个进程在其地址空间中的修改都不会影响到另外一个进程.
- 不同的是: 在UNIX中,子进程的初始地址空间是父进程的一个副本,子进程和父进程是可以有只读的共享内存区的.但是对于windows系统来说,从一开始父进程与子进程的地址空间就是不同的.

