
Hadoop配置运行常见错误总结
hadoop最头疼各种各样的问题了,把遇到的问题以及解决办法大致整理一下:
一、hadoop集群在namenode格式化(bin/hadoop namenode -format)后重启集群会出现如下
Incompatible namespaceIDS in ... :namenode namespaceID = ... ,datanode namespaceID=...
错误,原因是格式化namenode后会重新创建一个新的namespaceID,以至于和datanode上原有的不一致。
解决方法:
- 删除datanode dfs.data.dir目录(默认为tmp/dfs/data)下的数据文件
- 修改dfs.data.dir/current/VERSION 文件,把namespaceID修成与namenode上相同即可(log错误里会有提示)
- 重新指定新的dfs.data.dir目录
二、hadoop集群启动start-all.sh的时候,slave总是无法启动datanode,并会报错:
... could only be replicated to 0 nodes, instead of 1 ...
就是有节点的标识可能重复(个人认为这个错误的原因)。也可能有其他原因,一下解决方法请依次尝试,我是解决了。
解决方法:
- 删除所有节点dfs.data.dir和dfs.tmp.dir目录(默认为tmp/dfs/data和tmp/dfs/tmp)下的数据文件;然后重新hadoop namenode -format 格式化节点;然后启动。
- 如果是端口访问的问题,你应该确保所用的端口都打开,比如hdfs://machine1:9000/、50030、50070之类的。执行#iptables -I INPUT -p tcp --dport 9000 -j ACCEPT 命令。如果还有报错:hdfs.DFSClient: Exception in createBlockOutputStream java.net.ConnectException: Connection refused;应该是datanode上的端口不能访问,到datanode上修改iptables:#iptables -I INPUT -s machine1 -p tcp -j ACCEPT
- 还有可能是防火墙的限制集群间的互相通信。尝试关闭防火墙。/etc/init.d/iptables stop
- 最后还有可能磁盘空间不够了,请查看 df -al
- 我在解决这个问题的时候还有人说:先后启动namenode、datanode可以解决这个问题(本人尝试发现没用,大家可以试试)$hadoop-daemon.sh start namenode ; $hadoop-daemon.sh start datanode
三、程序执行出现Error: java.lang.NullPointerException
空指针异常,确保java程序的正确。变量什么的使用前先实例化声明,不要有数组越界之类的现象。检查程序。
四、执行自己的程序的时候,(各种)报错,请确保一下情况:
- 前提都是你的程序是正确通过编译的
- 集群模式下,请把要处理的数据写到HDFS里,并且确保HDFS路径正确
- 指定执行的jar包的入口类名(我不知道为什么有时候不指定也是可以运行的)
正确的写法类似:
$ hadoop jar myCount.jar myCount input output
五、ssh无法正常通信的问题,这个问题我在搭建篇里有详细提到过。
六、程序编译问题,各种包没有的情况,请确保你把hadoop目录下 和hadoop/lib目录下的jar包都有引入。详细情况也是看搭建篇里的操作。
七、Hadoop启动datanode时出现Unrecognized option: -jvm 和 Could not create the Java virtual machine.
在hadoop安装目录/bin/hadoop中有如下一段shell:
1 2 3 4 5 6 |
CLASS='org.apache.hadoop.hdfs.server.datanode.DataNode'
if [[ $EUID -eq 0 ]]; then
HADOOP_OPTS="$HADOOP_OPTS -jvm server $HADOOP_DATANODE_OPTS"
else
HADOOP_OPTS="$HADOOP_OPTS -server $HADOOP_DATANODE_OPTS"
fi
|
$EUID 这里的用户标识,如果是root的话,这个标识会是0,所以尽量不要使用root用户来操作hadoop就好了。这也是我在配置篇里提到不要使用root用户的原因。
八、如果出现终端的错误信息是:
ERROR hdfs.DFSClient: Exception closing file /user/hadoop/musicdata.txt : java.io.IOException: All datanodes 10.210.70.82:50010 are bad. Aborting...
还有jobtracker log的报错信息
Error register getProtocolVersion
java.lang.IllegalArgumentException: Duplicate metricsName:getProtocolVersion
和可能的一些警告信息:
WARN hdfs.DFSClient: DataStreamer Exception: java.io.IOException: Broken pipe
WARN hdfs.DFSClient: DFSOutputStream ResponseProcessor exception for block blk_3136320110992216802_1063java.io.IOException: Connection reset by peer
WARN hdfs.DFSClient: Error Recovery for block blk_3136320110992216802_1063 bad datanode[0] 10.210.70.82:50010 put: All datanodes 10.210.70.82:50010 are bad. Aborting...
解决办法:
- 查看dfs.data.dir属性所指的路径是否磁盘已经满了,如果满了则进行处理后再次尝试hadoop fs -put数据。
- 如果相关磁盘没有满,则需要排查相关磁盘没有坏扇区,需要检测。
九、如果在执行hadoop的jar程序时得到报错信息:
java.io.IOException: Type mismatch in key from map: expected org.apache.hadoop.io.NullWritable, recieved org.apache.hadoop.io.LongWritable
或者类似:
Status : FAILED java.lang.ClassCastException: org.apache.hadoop.io.LongWritable cannot be cast to org.apache.hadoop.io.Text
那么你需要学习hadoop数据类型和 map/reduce模型的基本知识。我的这篇读书笔记里边中间部分有介绍hadoop定义的数据类型和自定义数据类型的方法(主要是对writable类的学习和了解);和这篇里边说的MapReduce的类型和格式。也就是《hadoop权威指南》这本书的第四章Hadoop I/O和第七章MapReduce的类型和格式。如果你急于解决这个问题,我现在也可以告诉你迅速的解决之道,但这势必影响你以后开发:
确保一下数据的一致:
... extends Mapper...
public void map(k1 k, v1 v, OutputCollector output)...
...
...extends Reducer...
public void reduce(k2 k,v2 v,OutputCollector output)...
...
job.setMapOutputKeyClass(k2.class);
job.setMapOutputValueClass(k2.class);job.setOutputKeyClass(k3.class);
job.setOutputValueClass(v3.class);
...
注意 k* 和 v*的对应。建议还是看我刚才说的两个章节。详细知道其原理。
十、如果碰到datanode报错如下:
ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: java.io.IOException: Cannot lock storage /data1/hadoop_data. The directory is already locked.
根据错误提示来看,是目录被锁住,无法读取。这时候你需要查看一下是否有相关进程还在运行或者slave机器的相关hadoop进程还在运行,结合linux这俩命令来进行查看:
netstat -nap
ps -aux | grep 相关PID
如果有hadoop相关的进程还在运行,就使用kill命令干掉即可。然后再重新使用start-all.sh。
十一、如果碰到jobtracker报错如下:
Shuffle Error: Exceeded MAX_FAILED_UNIQUE_FETCHES; bailing-out.
解决方式,修改datanode节点里/etc/hosts文件。
简单介绍下hosts格式:
每行分为三个部分:第一部分网络IP地址、第二部分主机名或域名、第三部分主机别名
操作的详细步骤如下:
1、首先查看主机名称:
cat /proc/sys/kernel/hostname
会看到一个HOSTNAME的属性,把后边的值改成IP就OK,然后退出。
2、使用命令:
hostname ***.***.***.***
星号换成相应的IP。
3、修改hosts配置类似内容如下:
127.0.0.1 localhost.localdomain localhost
::1 localhost6.localdomain6 localhost6
10.200.187.77 10.200.187.77 hadoop-datanode
如果配置后出现IP地址就表示修改成功了,如果还是显示主机名就有问题了,继续修改这个hosts文件,
如下图: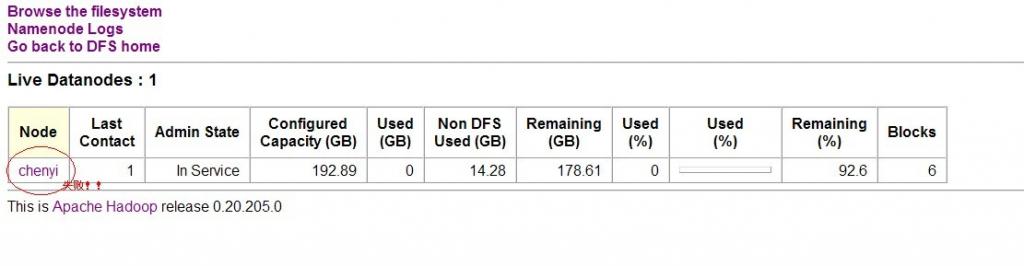
上图提醒下,chenyi是主机名。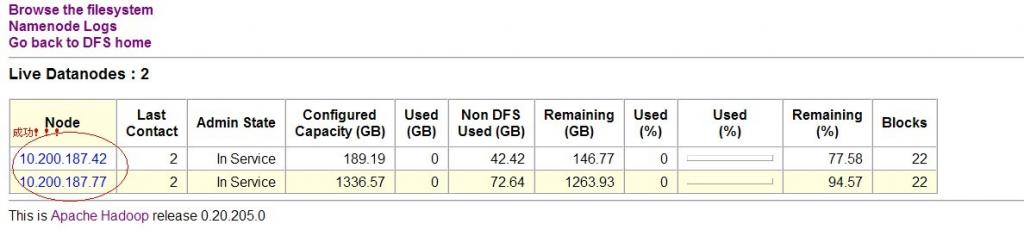
当在测试环境里,自己再去部署一个域名服务器(个人觉得很繁琐),所以简单地方式,就直接用IP地址比较方便。如果有了域名服务器的话,那就直接进行映射配置即可。
如果还是出现洗牌出错这个问题,那么就试试别的网友说的修改配置文件里的hdfs-site.xml文件,添加以下内容:
dfs.http.address
*.*.*.*:50070 端口不要改,星号换成IP,因为hadoop信息传输都是通过HTTP,这个端口是不变的。
十一、如果碰到jobtracker报错如下:
java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code *
我这里是些streaming的php程序时遇到的,遇到的错误码是code 2: No such file or directory。即找不到文件或者目录。发现命令竟然忘记使用'php ****' 很坑,另外网上看到也可能是include、require等命令造成。详细的请根据自身情况和错误码修改。
十二、如果遇到如下错误:
FAILED java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI:***
就是URI里边出现了不允许出现的字符,比如冒号:之类的,操作系统不允许的文件命名字符。详细的可以根据提示的部分(星号部分)来进行grep匹配查看。消除掉就可以解决了。
十三、遇到tasktracker无法启动,tasktracker日志报错如下:
ERROR org.apache.hadoop.mapred.TaskTracker: Can not start task tracker because java.net.BindException: Address already in use ***
是端口被占用或者已经有相应的进程启动了,这时候你先停止集群,然后使用ps -aux | grep hadoop 命令,来看看相关的hadoop进程,把hadoop相关的守护进程kill掉即可。
十四、遇到datanode无法启动的情况,datanode日志报错如下:
ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: java.io.IOException: No locks available
网上有许多说需要format,个人感觉是扯淡,因为我同样的添加节点,添加的其他节点没有问题,只有一个有问题,所以问题一定不在是否format身上,而且如果format后hdfs内的数据就会全部丢失,我也不会去尝试这种方法。详细看了一下,apache的邮件列表有这样一段内容:
No locks available can mean that you are trying to use hadoop on a filesystem that does not support file level locking. Are you trying to run your name node storage in NFS space?
这里提到文件级锁的情况,使用
$ /etc/init.d/nfs status
命令查看网络文件系统的情况,都是关闭的。另外使用df -Th或者mount命令可以查看文件系统的类型,得到的结果确实是NFS文件系统的问题。不能使用挂在的网络文件系统,因为又貌似只读的情况,即便不是只读情况,也像上边说的,是不支持file级锁的。
最后解决办法,可以尝试给nfs添加文件级的锁。我这里就是修改dfs.data.dir,不使用nfs完事了。
十五、datanode died,并且无法启动该进程,log报如下错误:
2017-06-04 10:31:34,915 INFO org.apache.hadoop.hdfs.server.common.Storage: Cannot access storage directory /data5/hadoop_data
2017-06-04 10:31:34,915 INFO org.apache.hadoop.hdfs.server.common.Storage: Storage directory /data5/hadoop_data does not exist.
2017-06-04 10:31:35,033 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: org.apache.hadoop.util.DiskChecker$DiskErrorException: Invalid value for volsFailed : 2 , Volumes tolerated : 0
我的这个问题,查到原因是该节点的磁盘变成的只读(only read)模式,网上搜了一下发现这种情况还蛮多,Linux机器的硬盘本来都是设置成读写(Read/Write)方式的,不过偶尔会发现自动变成了只读(Read Only),查了一些资料,发生这种情况的原因有多种,可能的问题:
- 文件系统错误
- 内核相关硬件驱动bug
- FW固件类问题
- 磁盘坏道
- 硬盘背板故障
- 硬盘线缆故障
- HBA卡故障
- RAID卡故障
- inode资源耗尽
解决的办法:
- 重启服务器(命令reboot)
- 重新mount硬盘
- fsck尝试修复
- 更换硬盘
附一个详细的解决办法(未尝试,看着挺靠谱的)。
十六、jps无法查看到hadoop、hbase的daemon守护进程,但是hadoop、hbase均工作正常,web页面也能访问,用ps -ef|grep java 也能看到启动的java进程。
造成这个情况的原因是java程序启动后,默认(请注意是默认)会在/tmp/hsperfdata_userName目录下以该进程的id为文件名新建文件,并在该文件中存储jvm运行的相关信息,其中的userName为当前的用户名,/tmp/hsperfdata_userName目录会存放该用户所有已经启动的java进程信息。对于windows机器/tmp用Windows存放临时文件目录代替。而jps、jconsole、jvisualvm等工具的数据来源就是这个文件(/tmp/hsperfdata_userName/pid)。所以当该文件不存在或是无法读取时就会出现jps无法查看该进程号,jconsole无法监控等问题。
所以如果你的tmp有定期清空、磁盘满、写入权限等情况,均会造成jps无法查看java进程的情况,需要解决的可以设置缓存的保存位置。关于设置该文件位置的参数为-Djava.io.tmpdir
另外:
/tmp/hsperfdata_userName/pid文件会在对应java进程退出后被清除。如果java进程非正常退出(如kill -9),那么pid文件会被保留,直到执行一次java命令或是加载了jvm程序的命令(如jps、javac、jstat),会将所有无用的pid文件都清除掉
十七、执行mapreduce任务的时候报错如下:
2017-05-21 10:50:43,290 WARN org.mortbay.log: /mapOutput: org.apache.hadoop.util.DiskChecker$DiskErrorException: Could not find taskTracker/hadoop/jobcache/job_201705191809_0004/attempt_201705191809_0004_m_000006_0/output/file.out.index in any of the configured local directories
2017-05-21 10:50:45,592 WARN org.apache.hadoop.mapred.TaskTracker: getMapOutput(attempt_201705191809_0004_m_000006_0,0) failed : org.apache.hadoop.util.DiskChecker$DiskErrorException: Could not find taskTracker/ha.doop/jobcache/job_201705191809_0004/attempt_201705191809_0004_m_000006_0/output/file.out.index in any of the configured local directories
虽然是两个warn,但是也影响作业效率,所以还是尝试解决一下,错误原因是无法找到作业的中间输出文件。需要作如下检查:
a、配置mapred.local.dir属性
b、df -h 看看缓存路径下的空间是否足够
c、free 看看内存空间是否足够
d、确保缓存路径可写权限
e、检查磁盘损坏
namenode循环报错如下:
2017-05-21 09:20:24,486 WARN org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Cannot roll edit log, edits.new files already exists in all healthy directories:
/data/work/hdfs/name/current/edits.new
/backup/current/edits.new
2017-05-21 09:20:25,357 ERROR org.apache.hadoop.security.UserGroupInformation: PriviledgedActionException as:hadoop cause:java.net.ConnectException: Connection refused
2017-05-21 09:20:25,357 ERROR org.apache.hadoop.security.UserGroupInformation: PriviledgedActionException as:hadoop cause:java.net.ConnectException: Connection refused
2017-05-21 09:20:25,359 WARN org.mortbay.log: /getimage: java.io.IOException: GetImage failed. java.net.ConnectException: Connection refused
secondarynamenode也有相关错误。
搜到一个说法原因是:
With 1.0.2, only one checkpoint process is executed at a time. When the namenode gets an overlapping checkpointing request, it checks edit.new in its storage directories. If all of them have this file, namenode concludes the previous checkpoint process is not done yet and prints the warning message you've seen.
这样的话如果你确保edits.new文件是之前错误操作残留下的没有用的文件的话,那么可以删掉,检测之后是否还有这样的问题。
另外请确保namenode的hdfs-site.xml的配置有如下项:
<property>
<name>dfs.secondary.http.address</name>
<value>0.0.0.0:50090</value>
</property>
将上述的0.0.0.0修改为你部署secondarynamenode的主机名。
secondarynamenode的hdfs-site.xml有如下项:
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
将上述的0.0.0.0修改为你部署namenode的主机名。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号