Bagging和Boosting
集成学习
在集成学习中,我们会训练多个模型(通常称为「弱学习器」)解决相同的问题,并将它们结合起来以获得更好的结果。最重要的假设是:当弱模型被正确组合时,我们可以得到更精确和/或更鲁棒的模型。Baggging 和Boosting都属于集成学习的方法,模型融合,将弱分类器融合之后形成一个强分类器,而且融合之后的效果会比最好的弱分类器更好。
bagging
Bagging算法 (英语:Bootstrap aggregating,引导聚集算法),又称装袋算法。Bagging算法可与其他分类、回归算法结合,提高其准确率、稳定性的同时,通过降低结果的方差,避免过拟合的发生。
基本思想
算法步骤
Bagging算法特性
boosting
提升方法(Boosting),是一种可以用来减小监督式学习中偏差的机器学习算法。弱学习者一般是指一个分类器,它的结果只比随机分类好一点点;强学习者指分类器的结果非常接近真值。
大多数提升算法使用弱学习分类器组成,并将其结果加入一个最终的成强学习分类器。加入的过程中,通常根据它们的分类准确率给予不同的权重。加和弱学习者之后,数据通常会被重新加权,来强化对之前分类错误数据点的分类。Boosting会减小在上一轮训练正确的样本的权重,增大错误样本的权重。(对的残差小,错的残差大)梯度提升的Boosting方式是使用代价函数对上一轮训练出的模型函数f的偏导来拟合残差。
经典Boosting方法
1.AdaBoost算法
2.GBDT算法
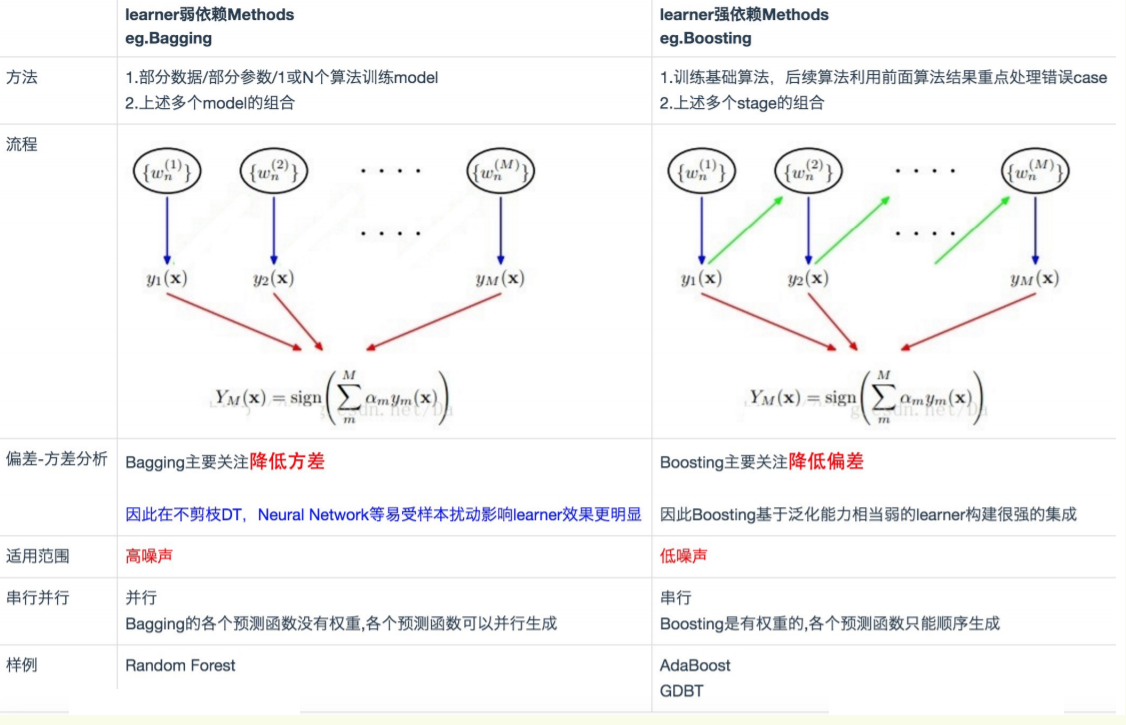
Bagging,Boosting二者之间的区别
1)样本选择:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
为什么说bagging是减少variance,而boosting是减少bias?
Bagging对样本重采样,对每一重采样得到的子样本集训练一个模型,最后取平均。由于子样本集的相似性以及使用的是同种模型,因此各模型有近似相等的bias和variance(事实上,各模型的分布也近似相同,但不独立)。由于所以bagging后的bias和单个子模型的接近,一般来说不能显著降低bias。另一方面,若各子模型独立,则有
,此时可以显著降低variance。若各子模型完全相同,则
,此时不会降低variance。bagging方法得到的各子模型是有一定相关性的,属于上面两个极端状况的中间态,因此可以一定程度降低variance。为了进一步降低variance,Random forest通过随机选取变量子集做拟合的方式de-correlated了各子模型(树),使得variance进一步降低。(用公式可以一目了然:设有i.d.的n个随机变量,方差记为
,两两变量之间的相关性为
,则
的方差为
,bagging降低的是第二项,random forest是同时降低两项。详见ESL p588公式15.1)。boosting从优化角度来看,是用forward-stagewise这种贪心法去最小化损失函数
。例如,常见的AdaBoost即等价于用这种方法最小化exponential loss:
。所谓forward-stagewise,就是在迭代的第n步,求解新的子模型f(x)及步长a(或者叫组合系数),来最小化
,这里
是前n-1步得到的子模型的和。因此boosting是在sequential地最小化损失函数,其bias自然逐步下降。但由于是采取这种sequential、adaptive的策略,各子模型之间是强相关的,于是子模型之和并不能显著降低variance。所以说boosting主要还是靠降低bias来提升预测精度。
参考:
https://www.cnblogs.com/earendil/p/8872001.html
https://www.cnblogs.com/mantch/p/10203143.html
https://baike.baidu.com/item/bagging/15454674?fr=aladdin
https://baike.baidu.com/item/Boosting/1403912?fr=aladdin

 浙公网安备 33010602011771号
浙公网安备 33010602011771号