归一化Normalization、标准化Standardization和正则化Regularization
一、归一化Normalization和标准化Standardization
标准化和归一化都是将原始数据缩放到一定范围,都属于特征缩放的方法。
特征缩放的作用是:
(1)使不同量纲的特征处于同一数值量级,减少方差大的特征的影响,使模型更准确。
(2)加快学习算法的收敛速度。在使用梯度下降的方法求解最优化问题时, 归一化/标准化后可以加快梯度下降的求解速度。
归一化:
通常将特征缩放到【0,1】
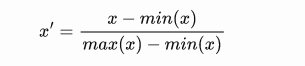
from sklearn.preprocessing import MinMaxScaler MinMaxScaler().fit_transform(iris.data)
标准化:
标准化被广泛用作许多学习算法中的预处理步骤,以将特征重新调整为零均值和单位方差。
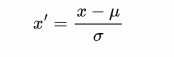
μ和σ分别是样本数据的均值(mean)和标准差(std)。标准化的作用是将原始数据映射到均值为 0,标准差为 1 的分布上,得到的结果分布和原分布是一样的,不一定是标准正态分布。标准化并不能使数据处于[0,1]之间。
使用sklearn.preprocessing.scale()函数,可以直接将给定数据进行标准化。
X_scaled = preprocessing.scale(X)
使用sklearn.preprocessing.StandardScaler类,使用该类的好处在于可以保存训练集中的参数(均值、方差)直接使用其对象转换测试集数据。
scaler = preprocessing.StandardScaler().fit(X) scaler.transform(X) # 可以直接使用训练集对测试集数据进行转换 print(scaler.transform([[-1., 1., 0.]]))
二、差异
(1)归一化(Normalization)会严格的限定变换后数据的范围,比如最大最小值处理的Normalization,它的范围严格在[ 0 , 1 ]之间;而Standardization就没有严格的区间,变换后的数据没有范围,只是其均值是0,标准差为1 。
(2)归一化(Normalization)对数据的缩放比例仅仅和极值有关,就是说比如100个数,你除去极大值和极小值其他数据都更换掉,缩放比例是不变的;反观,对于标准化如果除去极大值和极小值其他数据都更换掉,那么均值和标准差大概率会改变,这时候,缩放比例自然也改变了。
三、归一化和标准化选择:
(1) 归一化:
要求数据范围;
使用PCA技术进行降维;
在不涉及距离度量、协方差计算、数据不符合正太分布的时候。
(2) 标准化:
数据不稳定,存在极端的最大最小值,不能使用归一化;
在分类、聚类算法中,需要使用距离来度量相似性的时候。
当原始数据不同维度特征的尺度(量纲)不一致时,需要标准化步骤对数据进行标准化或归一化处理,反之则不需要进行数据标准化。也不是所有的模型都需要做归一的,比如模型算法里面有没关于对距离的衡量,没有关于对变量间标准差的衡量。比如决策树,他采用算法里面没有涉及到任何和距离等有关的,所以在做决策树模型时,通常是不需要将变量做标准化的;另外,概率模型不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率。
四、适用场景:
不是所有的模型都需要做归一的,比如模型算法里面有没关于对距离的衡量,没有关于对变量间标准差的衡量。比如决策树,他采用算法里面没有涉及到任何和距离等有关的,所以在做决策树模型时,通常是不需要将变量做标准化的;另外,概率模型不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率。
正则化Regularization
与上面提到的特征缩放技术不同,正则化旨在解决过拟合问题。通过在损失函数中增加额外的部分,学习算法中的参数更有可能收敛到较小的值,这可以显着减少过拟合。正则化主要有两种基本类型:L1-范数和L2-范数(岭回归)。
L1-范数:原始损失函数表示为 f(X),而新的是 F(X).
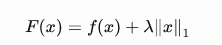
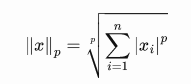
当我们想要训练稀疏模型时,L1 正则化更好,因为绝对值函数在 0 处不可微。
L2-范数:在不适定问题中首选 L2 正则化以进行平滑处理。

# 使用L1正则化 from sklearn.preprocessing import Normalizer normalizer = Normalizer(norm= 'l1') X2 = normalizer.fit_transform(X) # 使用L2正则化 from sklearn.preprocessing import normalize X1 = normalize(X, norm = 'l2'
参考资料:
https://maristie.com/2018/02/Normalization-Standardization-and-Regularization
https://blog.csdn.net/keeppractice/article/details/109280623
https://blog.csdn.net/weixin_36604953/article/details/102652160

 浙公网安备 33010602011771号
浙公网安备 33010602011771号