数据结构之树—B、B+、B-
感谢作者,本文来源https://blog.csdn.net/qq_22613757/article/details/81218741
B树
先介绍二叉搜索树
1. 一个节点有两个儿子
2. 每个节点存放一个关键字
3. 所有的非子节点做指针只想小于其关键字的树,而右指针指向大于关键字的树
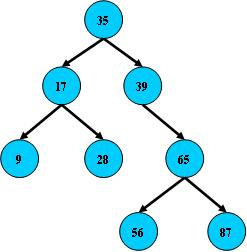
二叉搜索树,从根节点开始,如果查询的关键字与节点的关键字相等,那么命中;否则,如果查询关键字比节点关键字小,就进入左儿子,如果节点关键字大,那么就进入右儿子;如果左儿子或右儿子的指针为空,则报找不到相应的关键字
如果二叉搜索树的所有非叶子节点左右子树的节点保持差不多(平衡)那么二叉收索树的收索新能逼近二分查找;但是他比二分查找的优点是改变二叉搜索树的结构,不需要移动大量的内存,甚至通常是常数开销。
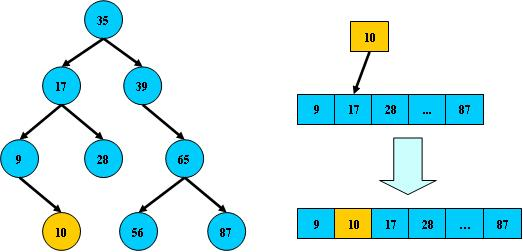
但是二叉搜索树经过多次插入与删除后,有可能导致不同的结构。
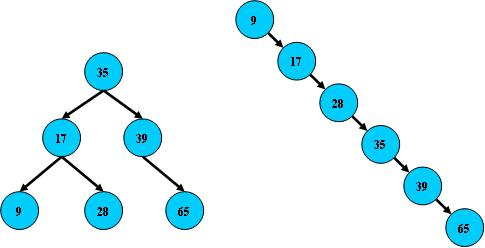
右边也是一个B树,但他的搜索性能已经是线性的了。同样的关键字结合,有可能导致不同的树结构索引;所以B树还要考虑尽可能让B树保持左图的结构,和避免有图的结构。也就是所谓的平衡问题。实际上B树都是在源树的基础上加上平衡算法,也就是平衡二叉树。保持B树节点分补均匀的平衡二叉树的管家你。
B+树,B-树
是一种多路搜索树(并不是二叉的)
1. 定义任意的非叶子节点最多只有M个儿子且M>2
2. 根节点的儿子数为【2,M】
3. 除去根节点外非叶子节点的儿子数位【M/2,M】
4. 每个节点至少存放M/2-1(取上整)和之多M-1个关键字,至少两个关键字。
5. 非叶子节点的关键字个数=指向叶子节点的儿子指针的个数-1
6. 非叶子节点的关键字:k[1],k[2],k[3];并k[i]<k[i+1]
7. 非叶子节点指针,P[1],P[2],P[3],其中P[1]只想小于K[1]的子树,P[i]指向(K[i-1],K[i])的子树;
8. 所有的叶子节点在同一层。
B-数的搜索,从根节点开始,对节点内的关键字(有序)进行二分查找。如果命中则结束,否则进入查询关键字所属范围的儿子节点。重复上诉操作,知道好到想要的结果。
B-数的特点:
1. 关键字集合分布在整课树中。
2 任何一个关键字出现且只出现在一个节点中。
3. 搜索哟可能在非叶子节点结束
4.其搜索的性能等价于在管家你子全集内左一次二分查找
5. 自动层次控制
右于现在了除跟姐点外的非叶子节点,至少有M/2个儿子,却奥了至少的利用率他的最低的性能位:
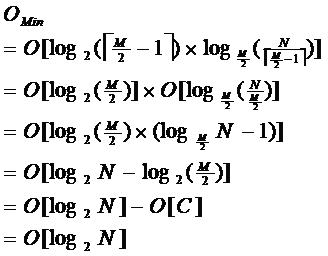
其中M为最多子树的个数,N为关键字总数;
所以B-树的性能总时等价于二分查找,也就没有B树平衡问题;
由于M/2的限制,在删除节点时,需要将两个不足的兄弟节点结合起来。
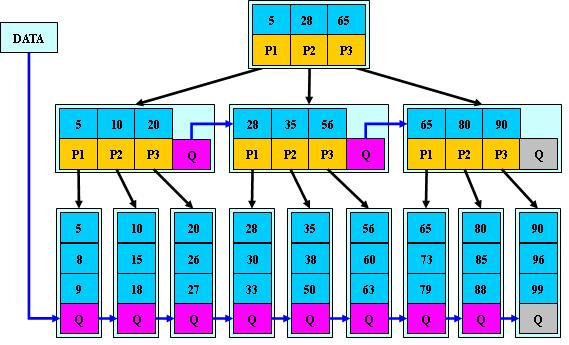
B+树
B+树时B-树的一种变体,也是一种多路搜索树,
1. 其定义域B-树同,除了;
2. 非叶子节点的子树指针域关键字个数相同;
3. 非叶子节点的子树指针P[i],指向关键字值属性值属于K[i],K[i+1]的子树开区间。
4. 所有关键字节点都在叶子节点出现
5. 为叶子节点增加一个链指针
B+树与B-树基本相同,区别时B+树只有达到叶子节点才会命中,其性能也等价于一次二分查找。
B+树的特点
所有关键字都出现在叶子节点的链表中,
更适合文件索引系统
B*树
B*树时B+数的变体
如果Java语言要用到B树需要弄清概念:引用和指针的区别

 浙公网安备 33010602011771号
浙公网安备 33010602011771号