

17-时间戳顺序并发控制
17-时间戳顺序并发控制
并发控制介绍了两种思路:
- 二阶段锁
- 悲观方法:在问题出现之前, 采取措施阻止问题的发生
- 缺点
- 锁会影响性能,锁意味着等待,
- Time stamp Ordering(T/0)
- 时间戳顺序并发控制 :根据时间戳确定顺序,决定出问题如何处理

如果事务\(TS(T_i)\)发生时间小于\(TS(T_j)\),数据库要保证\(T_i\) 一定比\(T_j\) 先发生.

时间戳如何而来?
- 时间戳要求单调递增
时间戳多种实现策略:
- 全局系统时钟
- 问题:电脑的时间不是完全精确的。之所以表现精确是因为网络矫正,在线同步
- 全局逻辑计数器
- 问题:分布式也存在同步问题
- 混合方法(Hybrid)

首先介绍 基础时间戳协议,其次介绍进阶版本 OCC,最后研究隔离级别

BASIC T/O

时间戳方法不需要给object加锁。
每一行记录都要附上两个时间戳:
-
读时间戳:上一次被修改的事务的时间戳
-
写时间戳:上一次被读的事务的时间戳
每一次操作都要检查时间戳
-
宗旨是不能操作未来的数据

读的流程如下:
如果发现事务的时间戳 比目标object X的时间戳还要大,说明 object X 被一个时间戳大的事务修改过。(比如一个事务先发生,但是去做其他的事情了,在这个期间,记录X另外一个刚开始的事务修改了。此时就会发生上述现象,这就叫做来自未来的数据)
- 此时该事务要回滚,更换一个新的时间戳重新开始
反之:如果该事务的时间戳比较object x的时间戳要新
- 允许该事务\(T_i\)读记录X
- 更新X对应的读时间戳
- 将记录X拷贝一个副本,方便事务\(T_i\)后续再读(副本就是版本)

写的流程如下:
如果 事务\(T_i\)的时间戳 小于记录X的读时间戳和写时间戳:
- 根据不能操作未来数据的原则,直接回滚
反之:如果 事务\(T_i\)的时间戳 大于记录X的读时间戳和写时间戳
- 允许事务\(T_i\) 修改X,同时更新X的写时间戳
- 同时,copy一个副本去保证事务\(T_i\)的后续读
从上面可以得出时间戳算法的基本操作原则:事务不能对时间戳大于自己的记录进行操作,只能操作时间戳小的。只能更新过去的数据。
上面简单的规则就能保证对于并发的事务,产生一个可执行的、正确的调度?
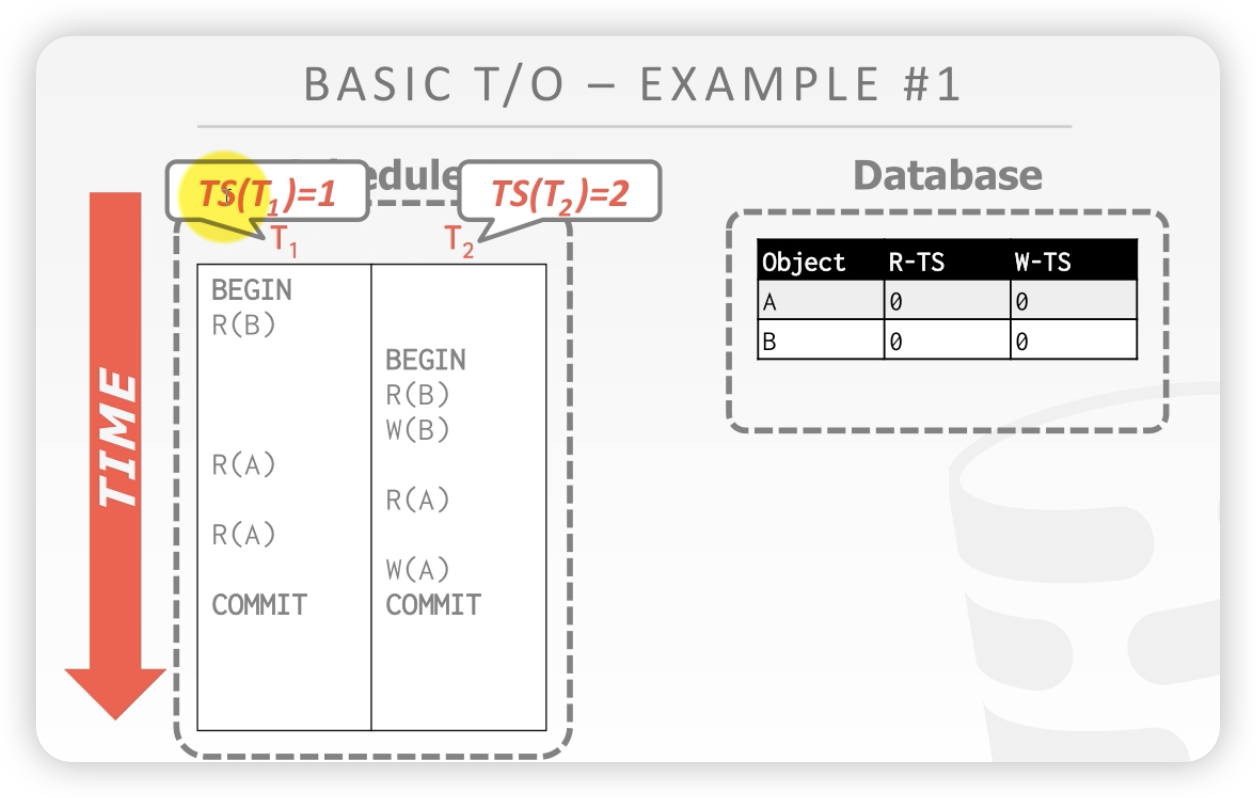
案例:
下图有两条记录:A和B,后面是读时间戳和写时间戳。假设事务T1时间戳是1,事务T2的时间戳是2。T1先开始。
时间线
-
T1 :读B,因为T1时间戳更新,所以可以读。 同时更新B的读时间戳为1
-
T2 : 读B,T2时间戳为2,比B的时间戳要大,所以可以读。更新B的时间戳为2
-
T2: 写B,T2时间戳新,更新B的时间戳为2
-
T1 读A,更新A读时间戳为1
-
T2 读A,更新A读时间戳为2
-
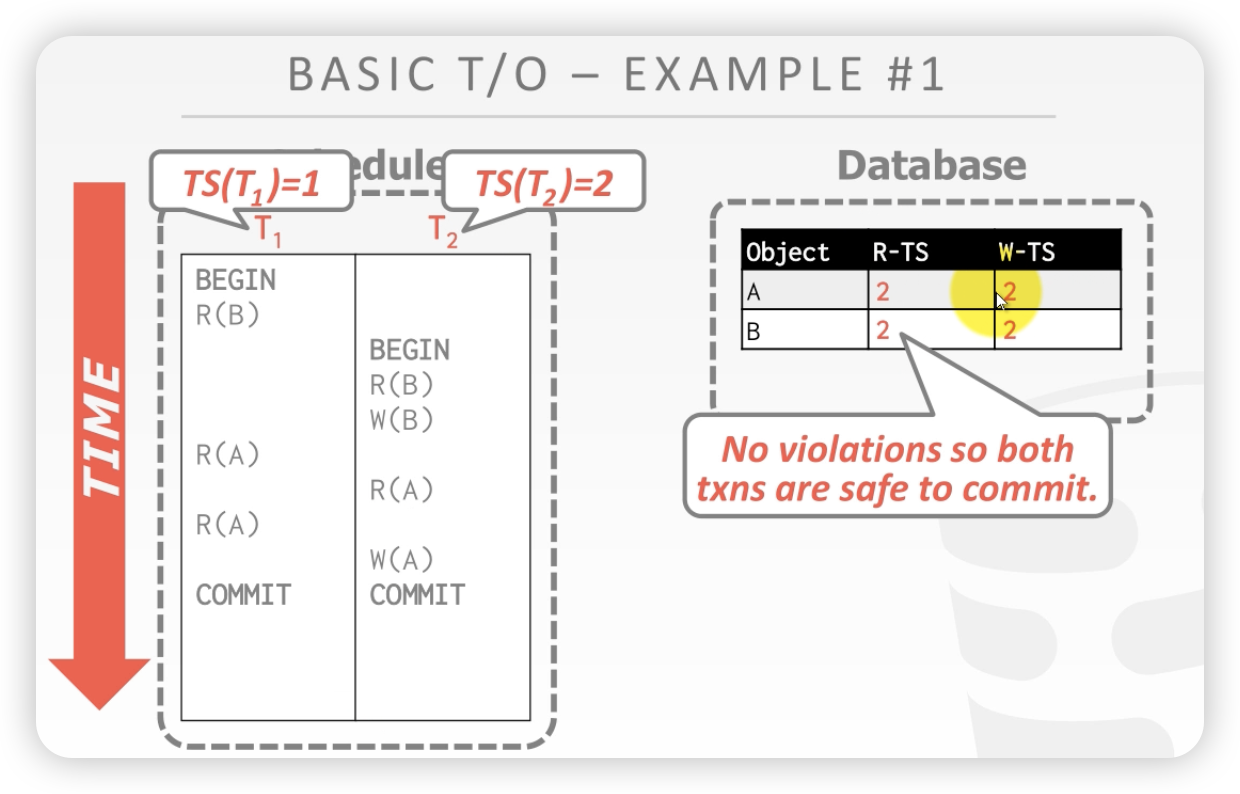
T1 再次读A,因为T1的时间戳 小雨 A的写时间戳,所以可以读。此时更新读时间戳,因为读时间戳比T1的时间戳更新,所以A的读时间戳并未改变
案例1 两个事务没有发生冲突,所以 时间戳算法没有起作用/
初始状态:
最终状态:
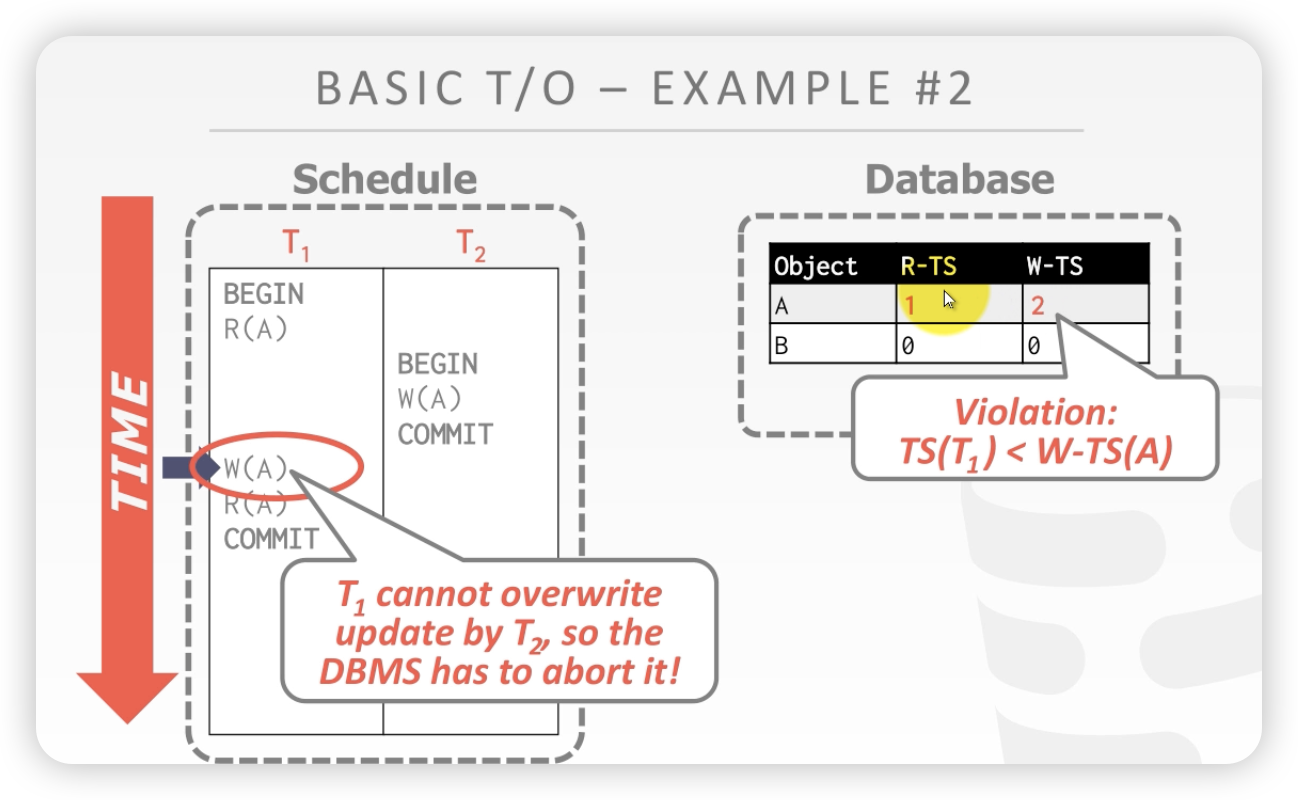
案例2:
时间线
- T1读A,更新A的读时间戳
- T2写A,因为T2的时间戳 大于 A的读时间戳和写时间戳,所以可以读A,更新A的时间戳
- T1写A,因为A的时间戳 小雨 A的读、写时间戳,不能写未来的数据,所以 A回滚
开始状态:

T1写A触发时间戳算法,A回滚
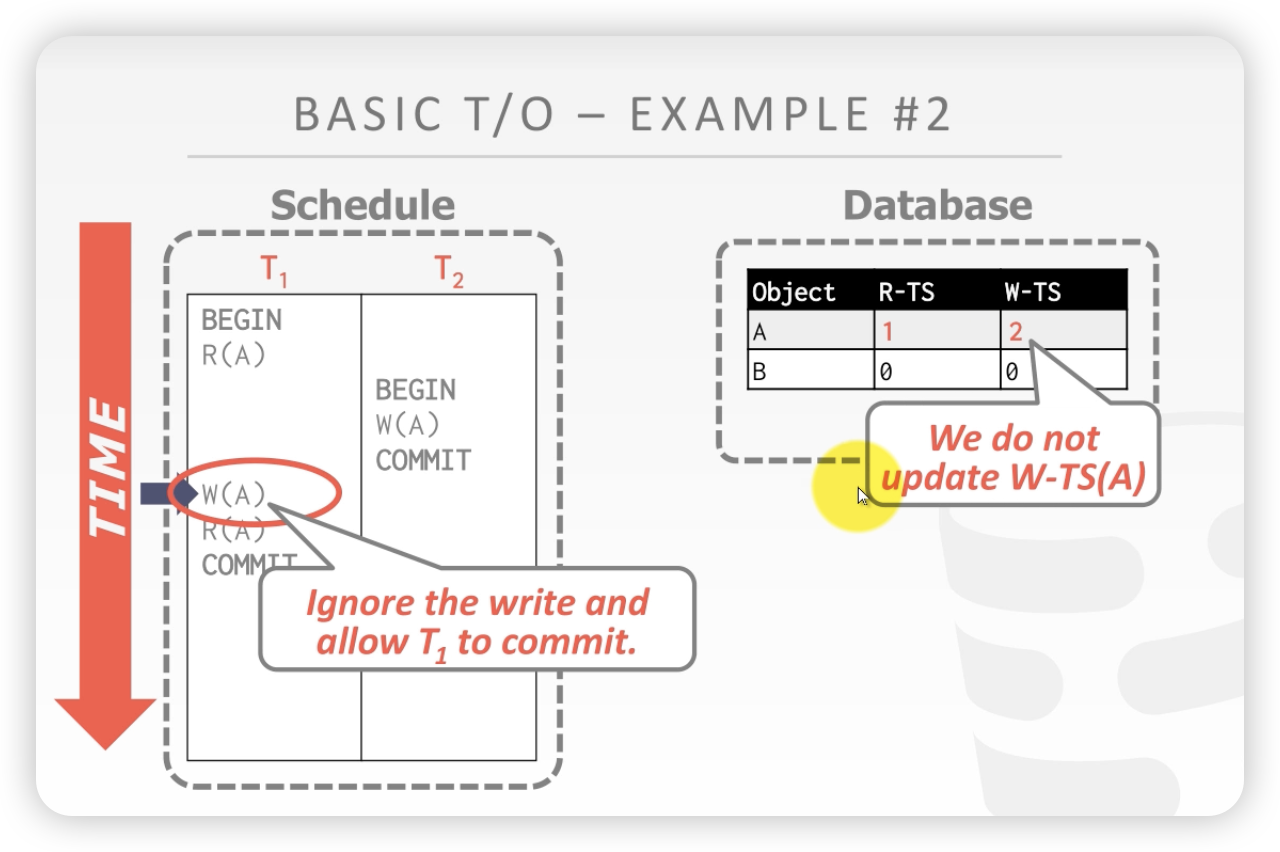
上述案例2,按照T O的方法是要回滚的,但是在T1 写A这步是可以优化的。即T先写A,然后保证T1发生在T2之间,相当于T1写的数据会被T2进行覆盖。
这个可以优化的点,称之为 托马斯规则。
当T1的时间戳 小于X的写时间戳,说明X被一个新的事务进行写操作了,托马斯规则说,针对这种情况也可以写,可以先写,然后被新的事务再覆盖(反正未来也会被覆盖掉)。
一个数据如果之后都没有人读,但是后面会有人修改,那我在自己的事务内就可以当成我完成了修改。 (存疑)

用托马斯规则修改案例2

如果不考虑托马斯规则,基础TO算法可以产生一个冲突串行化的调度,
- 它的优点是没有死锁,因为不需要加锁等待
- 问题是:
- 长的事务可能会一直处于饥饿状态
- 如果一个事务几百条sql,那么不断的回滚,可不就一直饥饿吗
- 长的事务可能会一直处于饥饿状态
一个事务是可恢复的 当切仅当 它修改的数据都是在已经提交的事务的基础之上去修改。
否则,数据库很难保证当数据库发生崩溃之后再给你恢复过来

案例解释:可恢复调度
时间线:
- T1写A
- T2 读A,因为T2更新,所以可以读老数据,所以可以读A
- 但是T1一直到T2commit之后,回滚了。此时T2就是不可恢复的,因为T2已经commit了。
- 数据库崩溃的时候,先恢复T1才能恢复T2,因为T2读的数据是T1写进去的。T1都没有了,那么T2怎没恢复?(我不理解)

上述说明了BASIC TO 会导致不能恢复的事务。
TO 还有性能问题:
- TO算法在读或者写的数据的数据,要往本地copy,代价很大
- 长事务有可能会饥饿
由基础TO进阶而来的一些思考:为了优化基础TO算法,引出了OCC

如果你可以确认事务之间的重复比较少 并且 大多数的事务比较短,那么这种无锁的方法相比较有锁的方法要好。
一个更好的方法是在针对一些具体的confilct的例子上做优化。大模型+小模型的方法
解决方案:OCC 乐观的并发控制方法

OCC也是基于TO算法的。其基本思想如下:
数据库为每一个事务创立了一个私有本地空间
- 任何事物读取的数据,都可以copy到这个私有本地空间。
- 修改操作直接在该私有空间中进行,不直接写入数据库底层
当一个txn提交之后,数据库会比较你提交的数据和别的事务进行比较,如果没有冲突,会让你提交。如果有问题,怎么解决?
具体来讲:
OCC方法有三个阶段:
- 读阶段:对数据库来说的是只读,不写,comit之后再写
- 将事务读取的数据写入私有空间
- 校验阶段
- 要提交的时候,跟别的事务相比较,有没有冲突 (跟git很像)
- 写阶段:对于数据库来说,是写入
- 真正的将私有空间要记录的东西写入数据库;如果有冲突,直接回滚

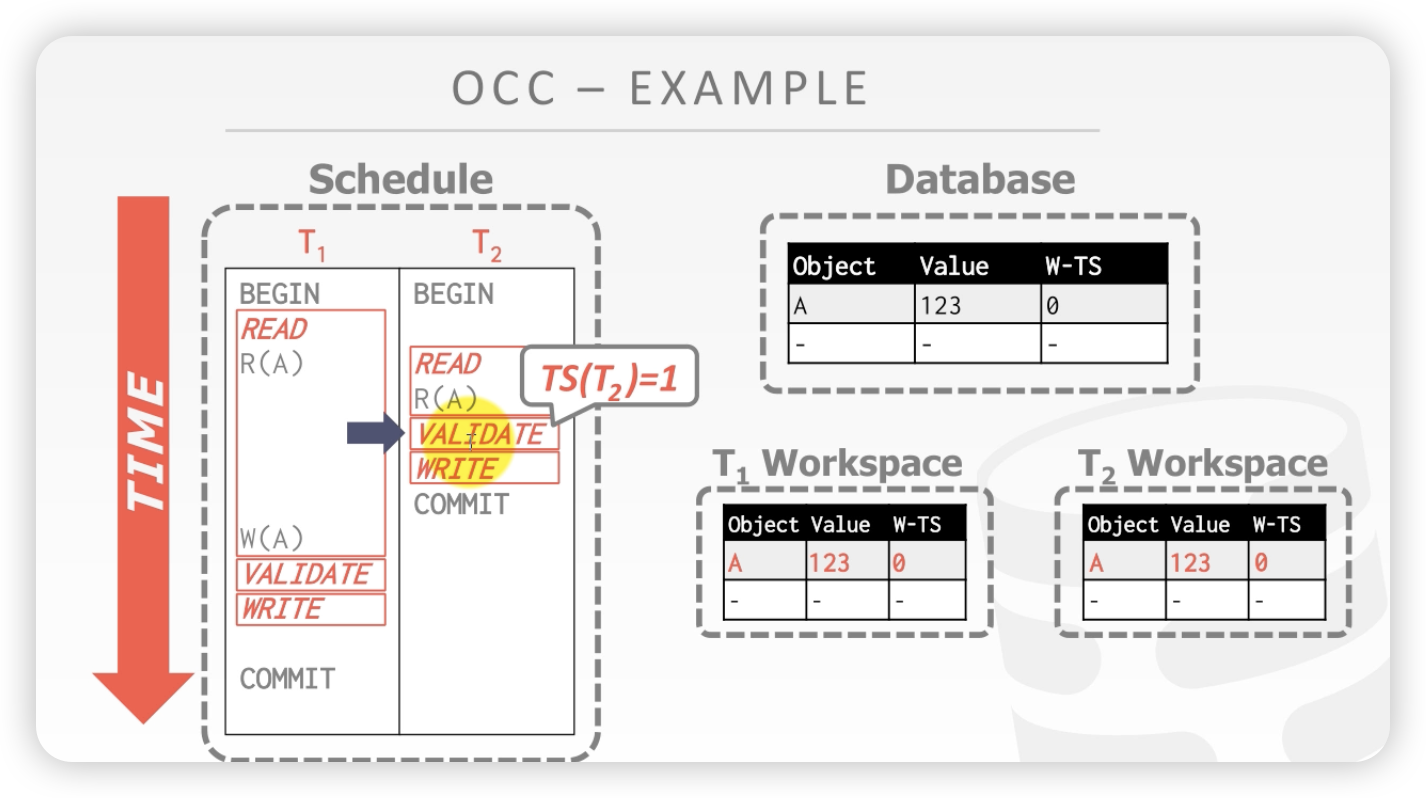
案例1:
时间线:注意T1和T2开始都没有时间戳
- T1读A 复制到私有空间T1 workspace
- T2开始读,复制到T2的私有空间。注意这里是检验之后,才给事务复制时间戳
- 校验通过,T2将其写入数据库
开始状态:
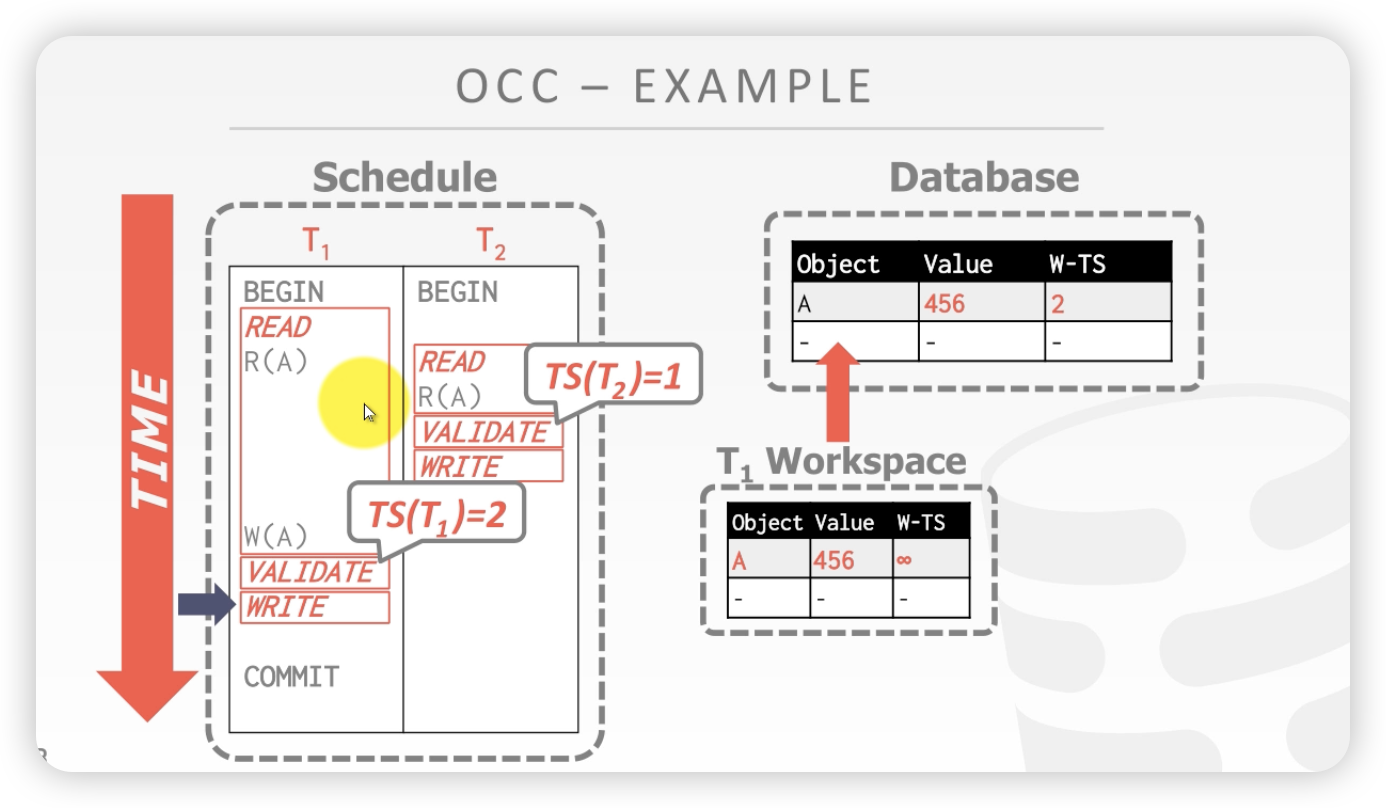
时间线:
- T1发来一个写的SQL
- T1进入校验,给T2 一个时间戳,校验,写入数据库

接下来,详细介绍三个步骤的具体过程:
写阶段
- 从数据库中读取数据写入本地数据库,方便后续重复读取

注意:长事务要修改的行很多,那么性能是不是很大?所以说应该是有试用范围的
校验阶段:
- 当事务调用commit时候,数据库会校验该数据和其他的事务是否有冲突,校验原则如下:
- 数据库要保证串行化(小时间戳先发生,大时间戳后发生)
- 检验当前事务和其他的事务是否存在 读写冲突和写写冲突 单向不要成环(不懂)
校验有两种实现方案
- 前向校验
- 后向校验

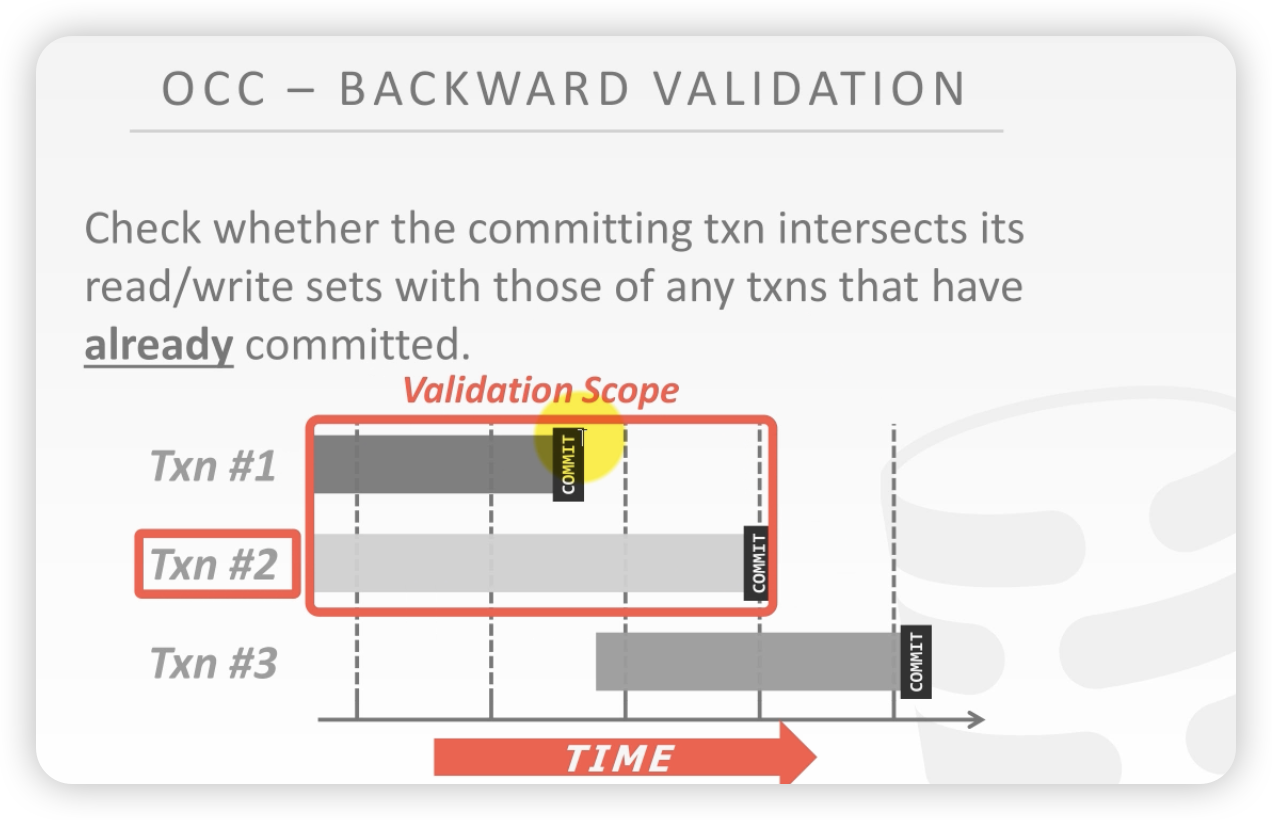
后向校验:
- 2号事务向历史上已经提交过的事务进行校验 ,看看和历史提交的事务有没有成环的冲突。如果没有,就直接提交;如果有,T2就自杀
前向校验:
- 未来的事务还未发生,所以校验的是和未来事务交叠的部分。没发生的无法校验
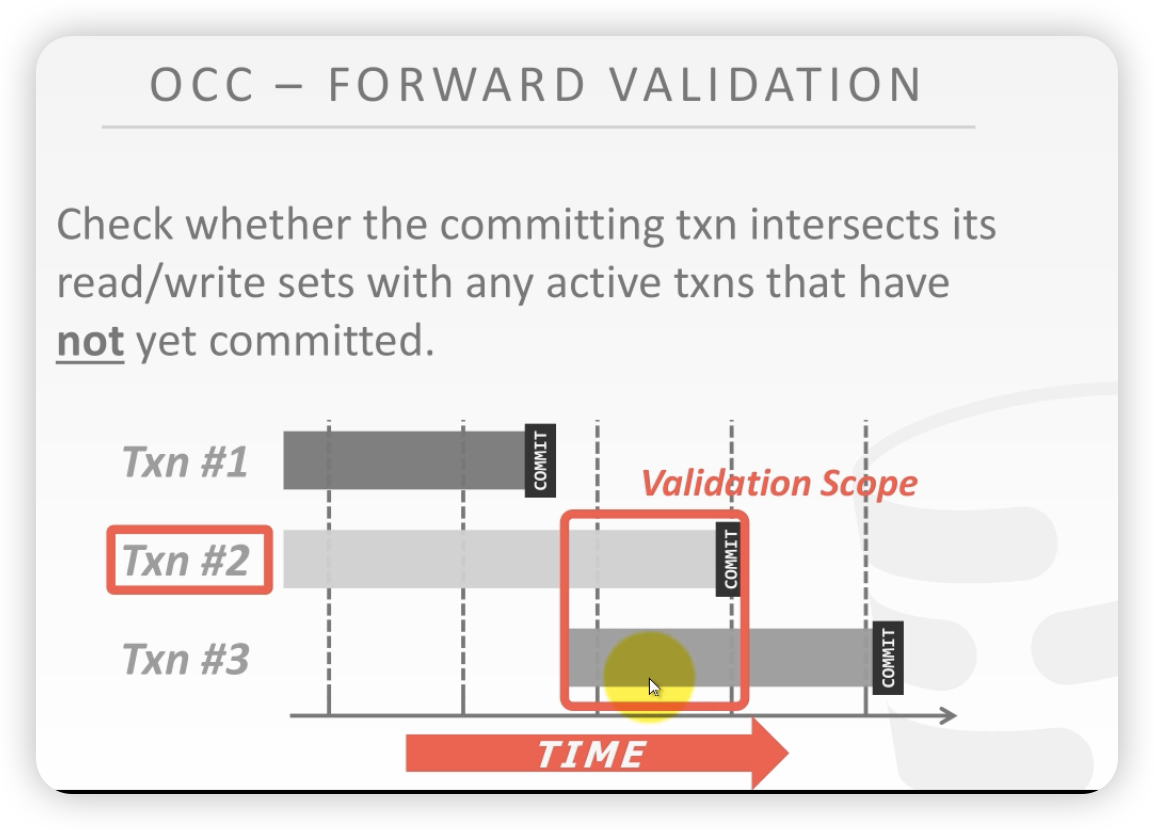
未来的事务没有commit,T2也没有commit,此时如果有冲突,就可以灵活的选择kill掉哪个

每一个事务的时间戳是校验阶段开始的时候才会赋予的。
比较当前事务与未来事务已经发生的部分。
如果\(T_i\)的时间遭遇战\(T_j\), 有如下三种情况:
第一种情况:
- \(T_i\)完成三个阶段之后,\(T_j\)才发生。 这两个事务是完全串行化的。这个就不需要等觉串行化,因为它是真的串行化。
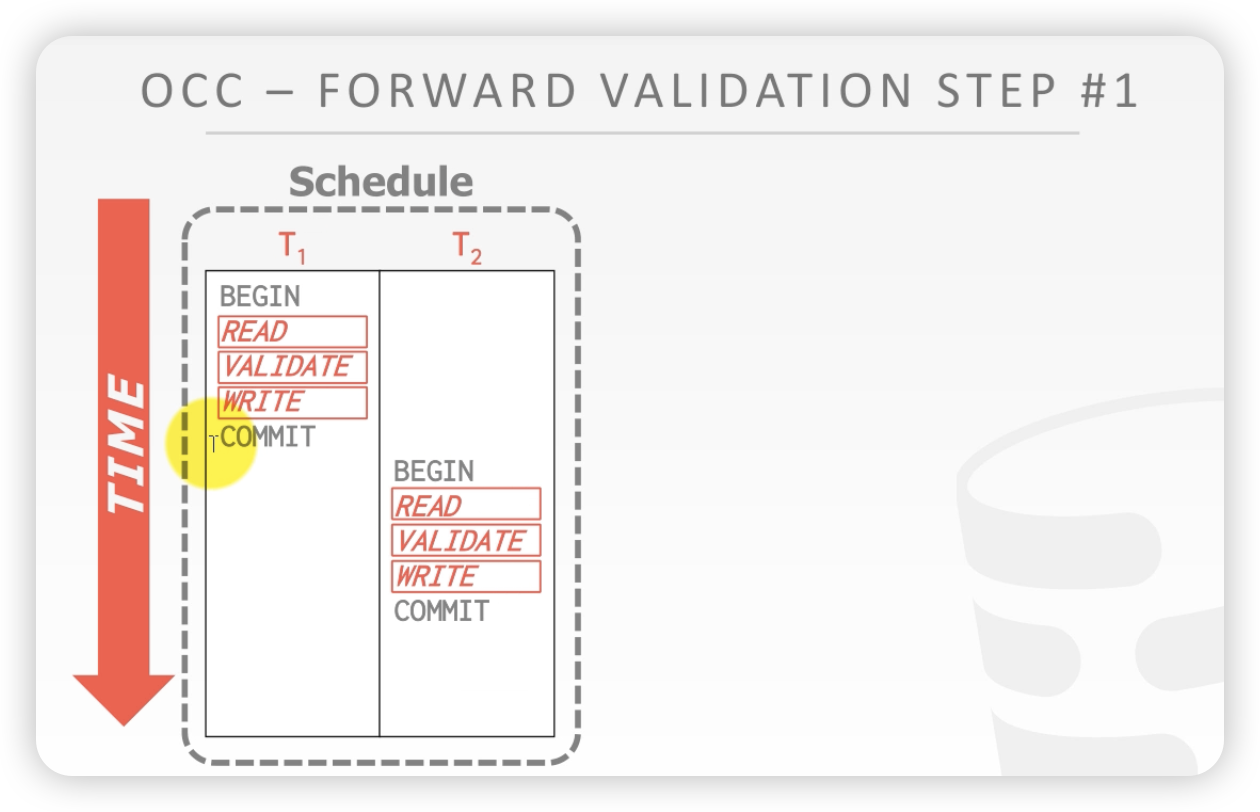
第二种情况
- Ti再Tj进行写阶段之前完成, Ti进入validation阶段,Tj开始写
- Ti要提交的数据没有被Tj读过

案例:
在T1 validate阶段,因为T2 在T1validat之前读了A,但是T1 在T2读之前读并且写了A。等于数据库中的数据copy了两份。现在T1要提交,假设提交上去,那么T2读的A就是错误的,此时T1要回滚。

T2 早于T1进入validate阶段,
T1进入validate的时候,T2还没有write。T1的write set和T2 的read set没有交集(这里没有讲清楚)
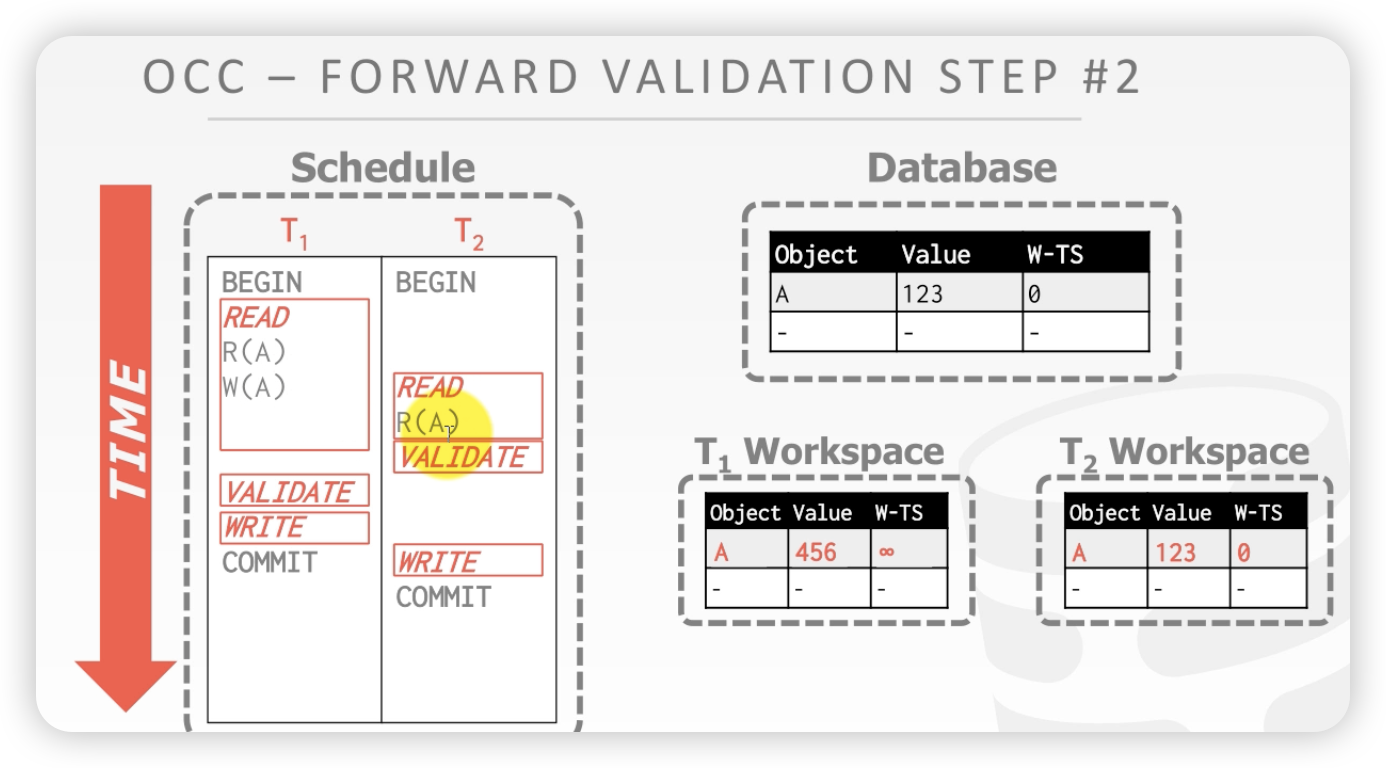
第三种情况:
- Ti完成读阶段,之前Tj也已经完成了读阶段
- Ti写的东西和Tj读的东西不能有交集
- Ti写的东西和Tj写的东西不能有交集

案例解释:
T1validate更早。
初始状态:

站在T1validate的时间点上,T2读的A是提交的A,就没有问题。(这里没有讲清楚)
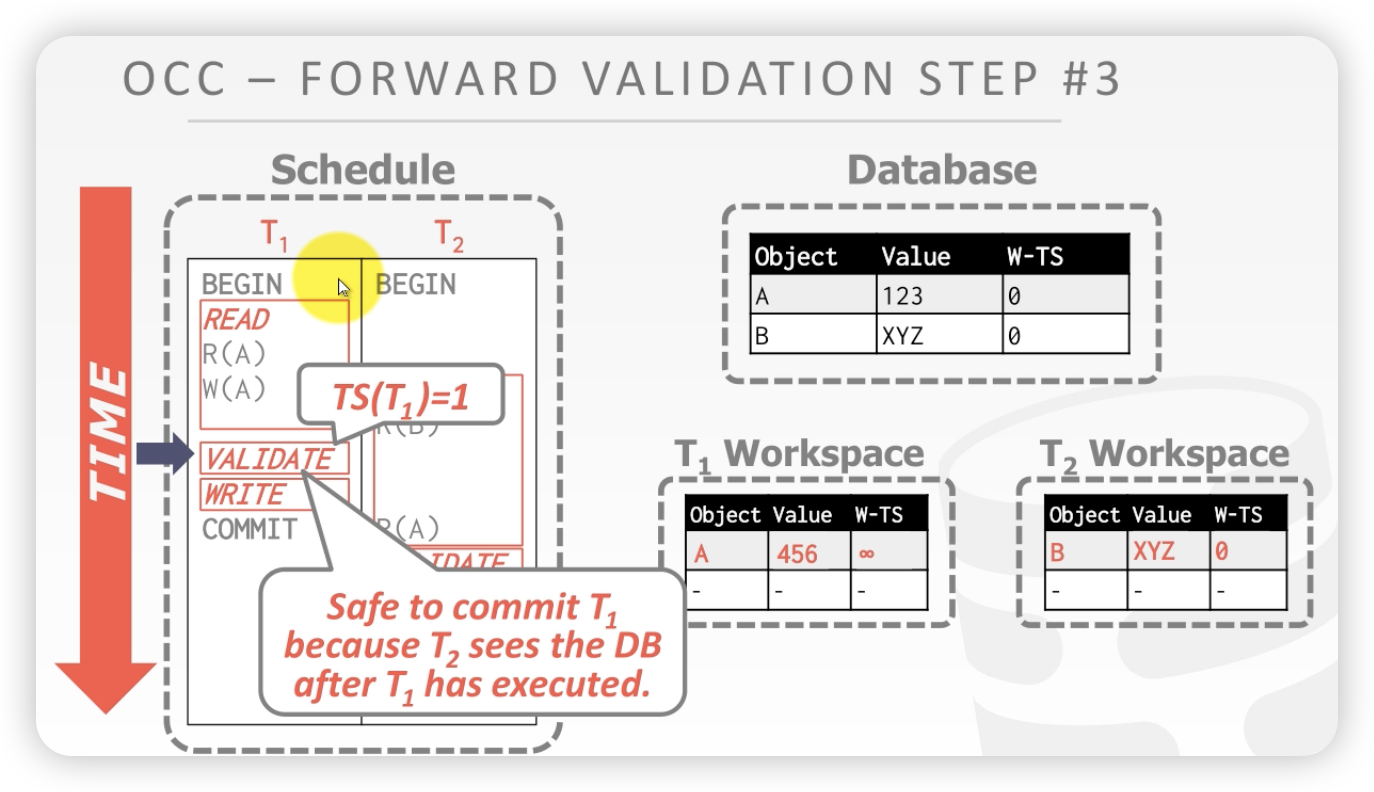

OCC的第三大步骤:
写阶段
- 要锁全表,怕并发问题

OCC的思考:
OCC的适用场景
- 冲突比较少
- 所有的事务都是只读是最好的,跟二阶段锁相比,性能提高很多
- 或者 事务要提交的数据之间没有交集,这就没什么好校验的,速度当然快
当数据库非常大的时候,查询是非倾斜的,查询是均匀的话,这时候冲突的概率非常小,比较适合OCC

OCC的问题:
- 复制到本地,开销很大
- 校验逻辑复杂。write 阶段由于锁表,不能并发可能成为瓶颈
- OCC出问题是当所有的事务活都干完了,才知道有问题,所以只要一出问题,干的活全部浪费了。浪费很大。2阶段一旦发生死锁,直接就干掉了。浪费的比较少
隔离级别
二阶段和TO都 可以产生等效串行化的调度序列,这两种东西防止不了幻读。
前面写讨论的都是update的问题,没有讨论过insertion和delete时候的问题。
案例
脏读问题:
- T1事务 读了两次 people表中的最大值,但是第二次读的数据已经被修改了
之前的二阶段锁和OCC都没有考虑到这个问题,这叫幻读,读到了第一次不存在的东西
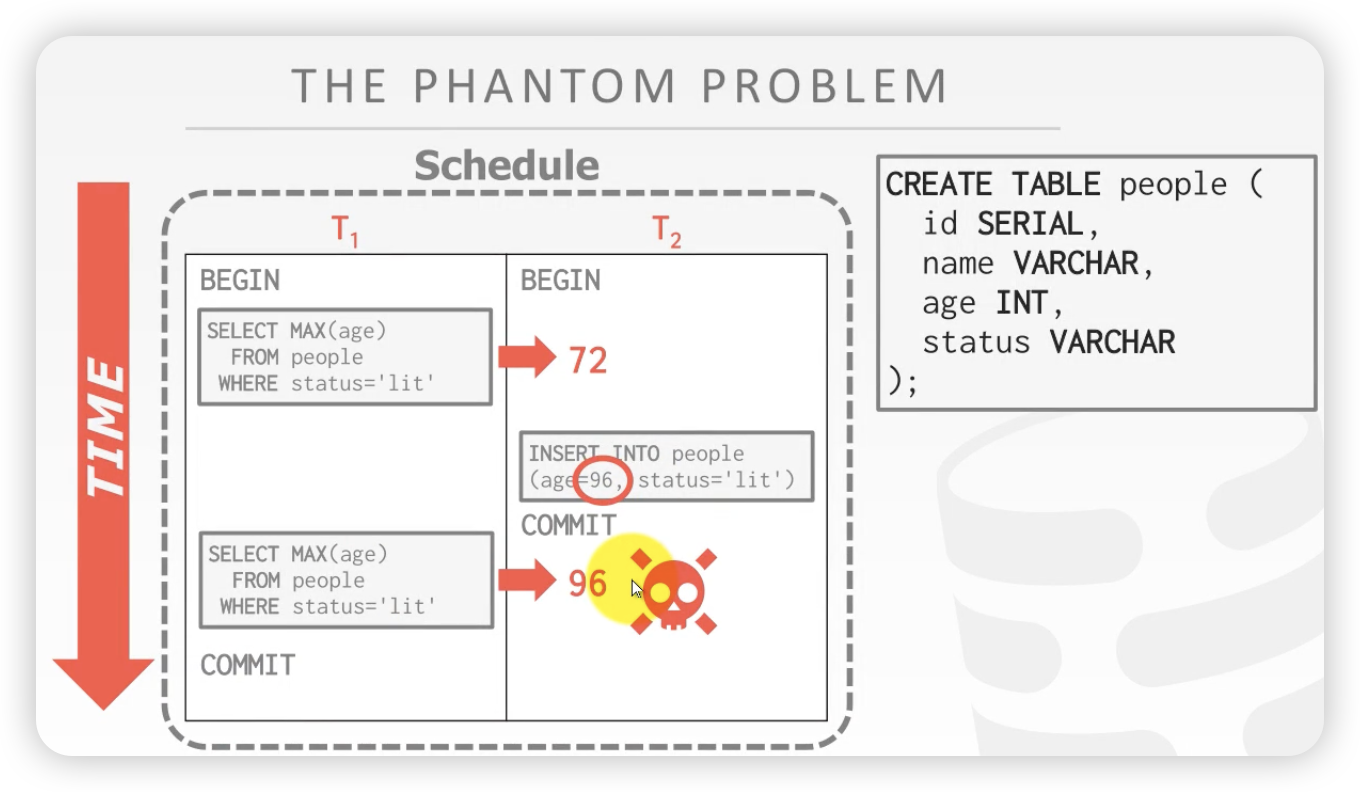
研究二阶段锁和OCC为什么预防不了上述的问题:
加了锁,只能锁现存的东西,控制不了你插入新的东西

幻读的解决方案

方法1:重新扫描

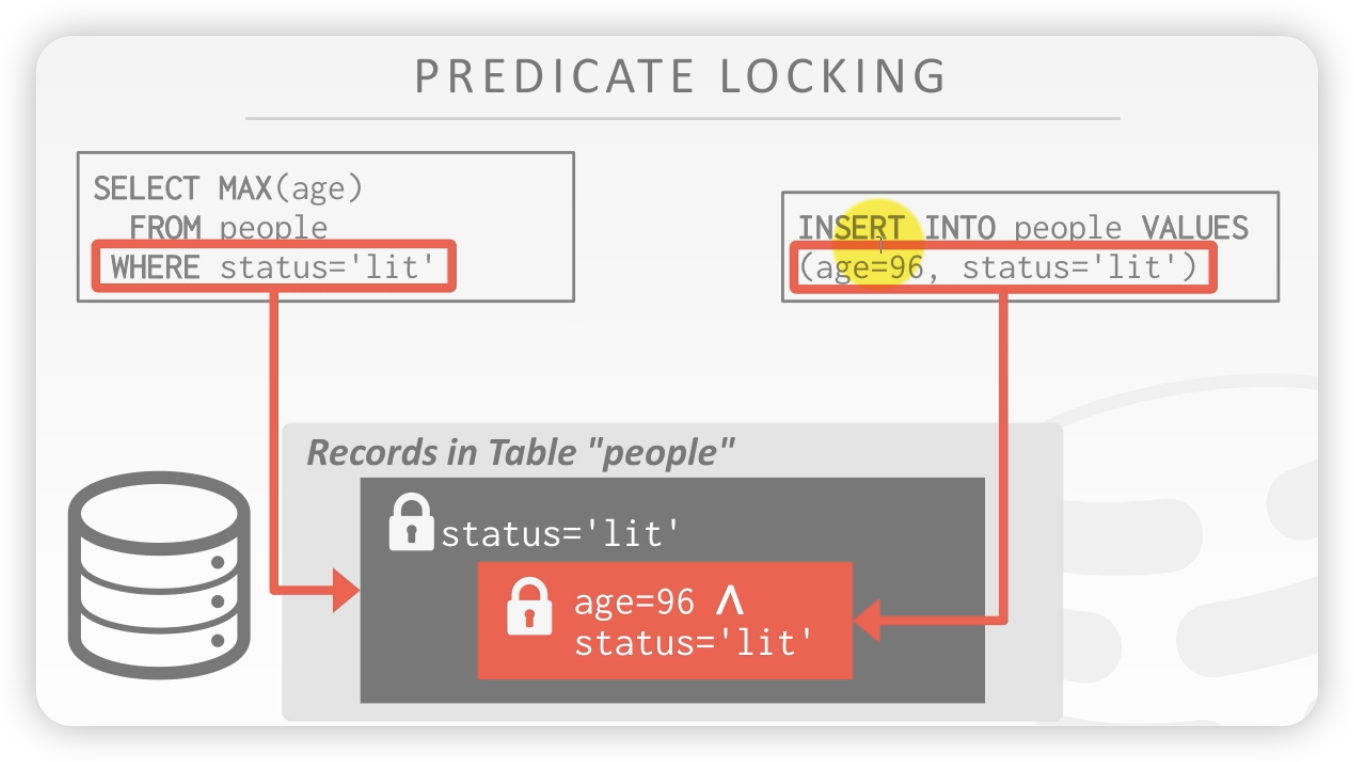
方案2: predicate locling 谓词锁
- 给select语句后,where的谓词加共享锁
- 给update、insert、delete 语句,where之后加 拍他锁

加锁之后,你想写入,你插不进去
方法3:索引锁
谓词中有索引,锁索引页

就是不让你插入进去或者删除。如果没有索引,那么就加表锁。

mysql 的方案是间隙锁。
前面的工作都是致力于将一个并发的事务变成可串行化的

serializable是一个很高的隔离级别。有时候并不需要,有些业务允许并发发生错误。
所以有了隔离级别的想法。

控制事务之间隔离的程度。
- 脏读问题:读未提交
- 不可重复读:两次读的数据不一样
- 幻读:两次读的数据发生了变化
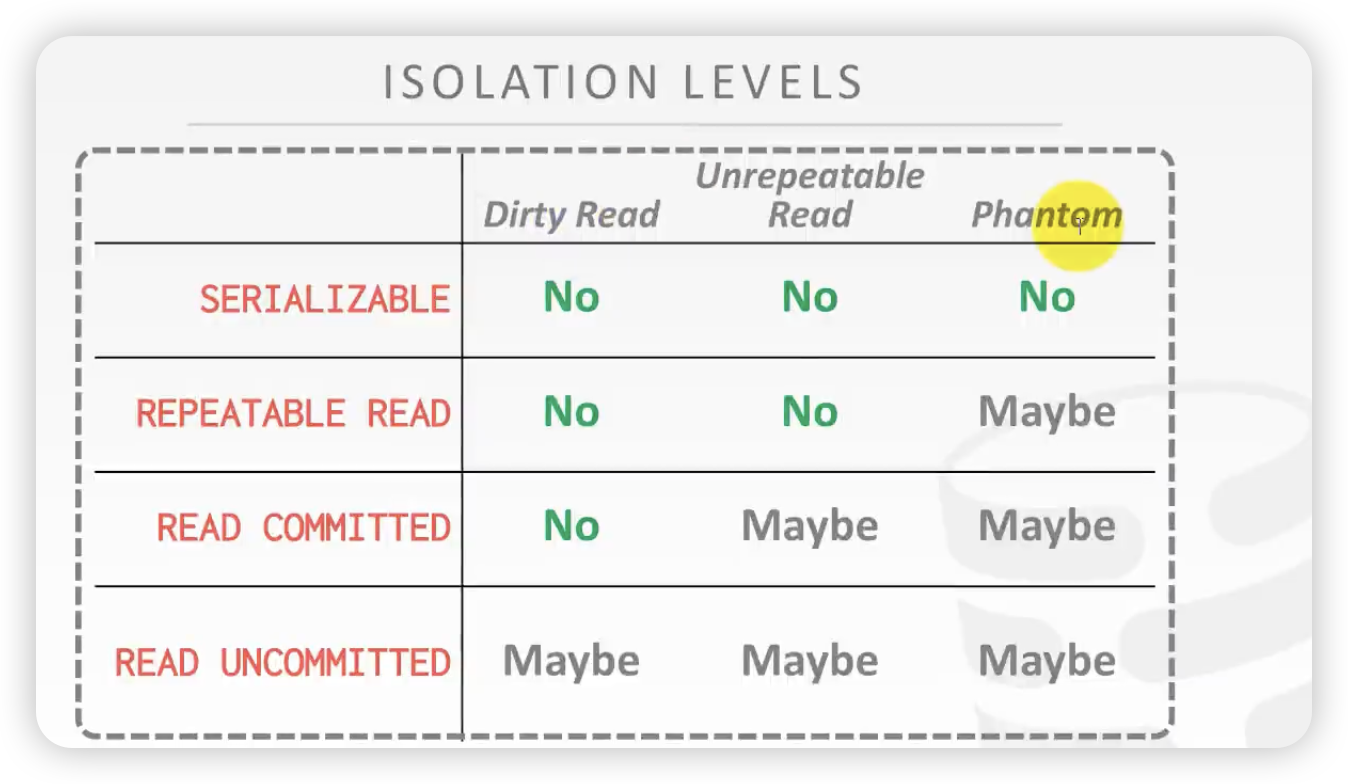
隔离级别:

隔离级别问题矩阵:
隔离级别的实现:

串行化:严格二阶段锁
可重复读:放开索引锁
读已经提交:S锁实时放开
读未提交:不增加S锁
逐渐的退化,性能会越来越高

sql92 标准规定如何设定隔离级别。
不是所有的数据库都支持上述四种级别,也不仅仅只有这4种级别
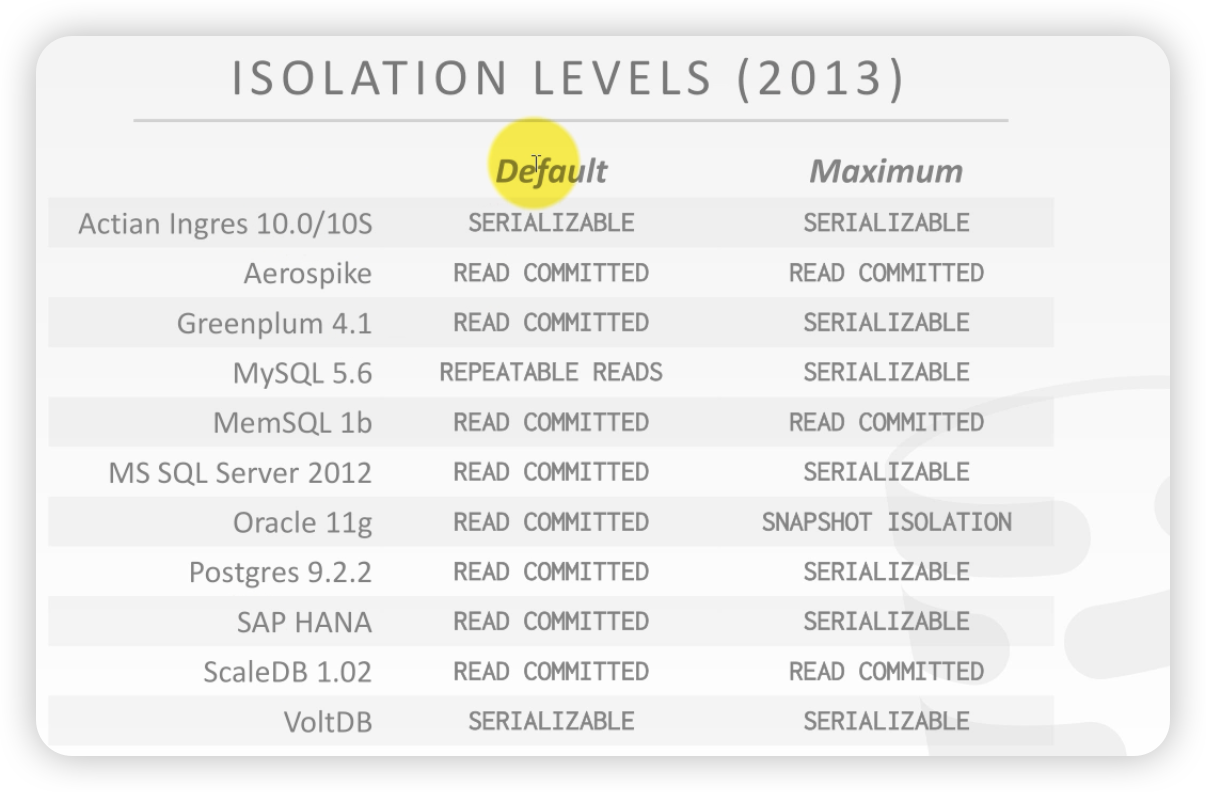
统计:当前数据库默认隔离级别和最高隔离级别
MVCC会研究快照隔离
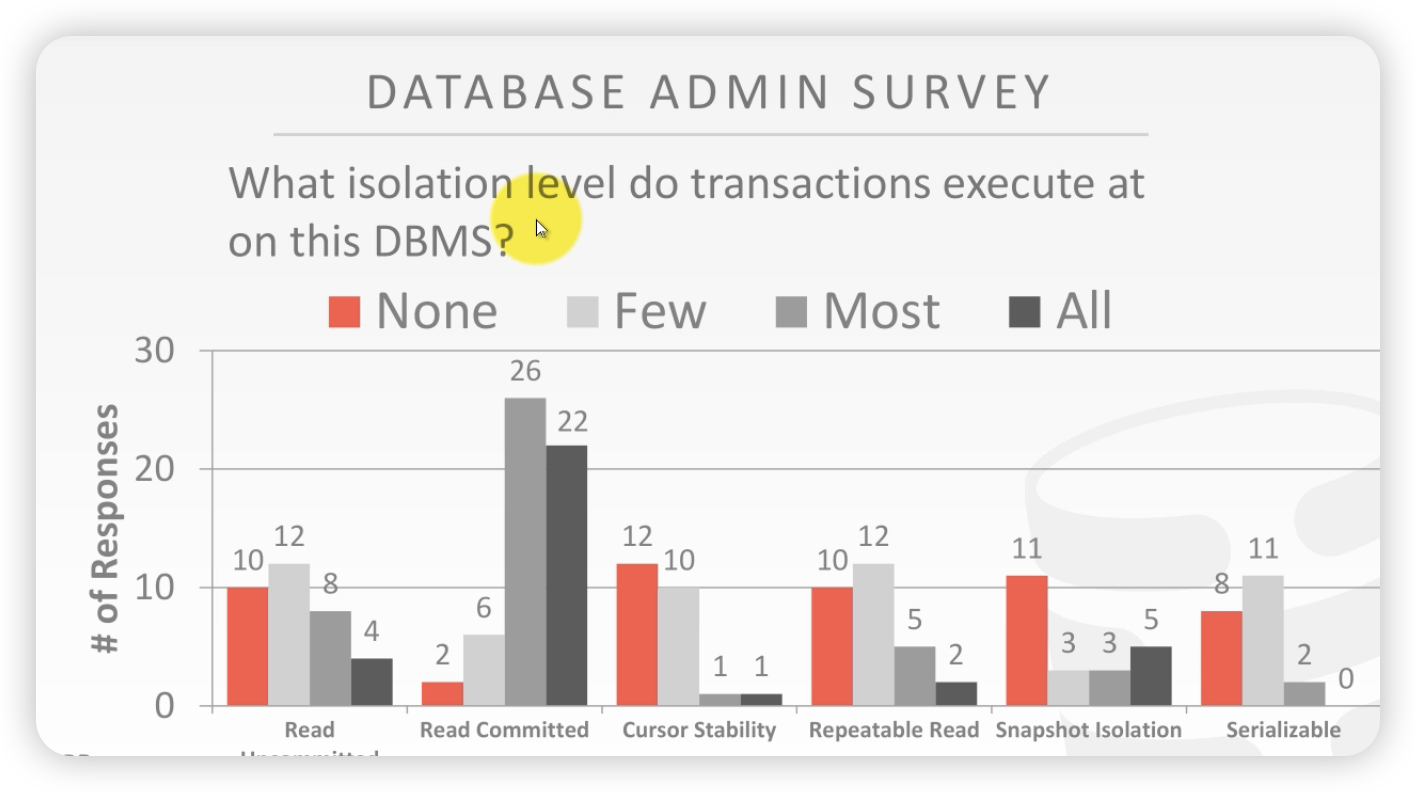
从用户角度调查哪个隔离级别用的最多。
92标准还规定了其他

总结

下一节课研究MVCC,多版本控制


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!