python--字符串
一、字符串
字符串是 Python 中最常用的数据类型。我们可以使用引号('或")来创建字符串。
创建字符串很简单,只要为变量分配一个值即可;访问子字符串,可以使用方括号来截取字符串:
1 var1 = 'Hello World!' 2 var2 = "Runoob" 3 4 print ("var1[0]: ", var1[0]) 5 print ("var2[1:5]: ", var2[1:5])
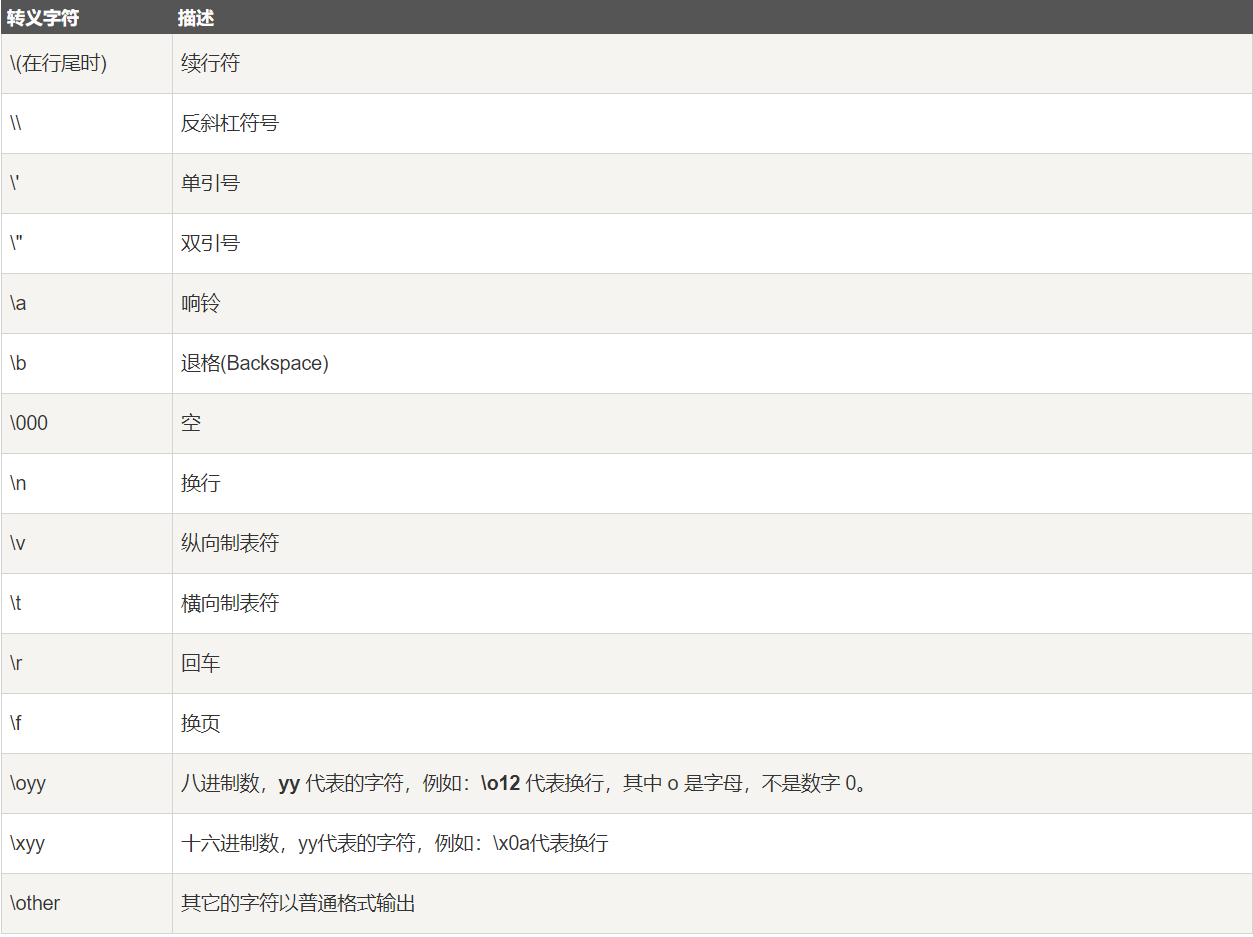
1、Python转义字符
在需要在字符中使用特殊字符时,python用反斜杠(\)转义字符。如下表:
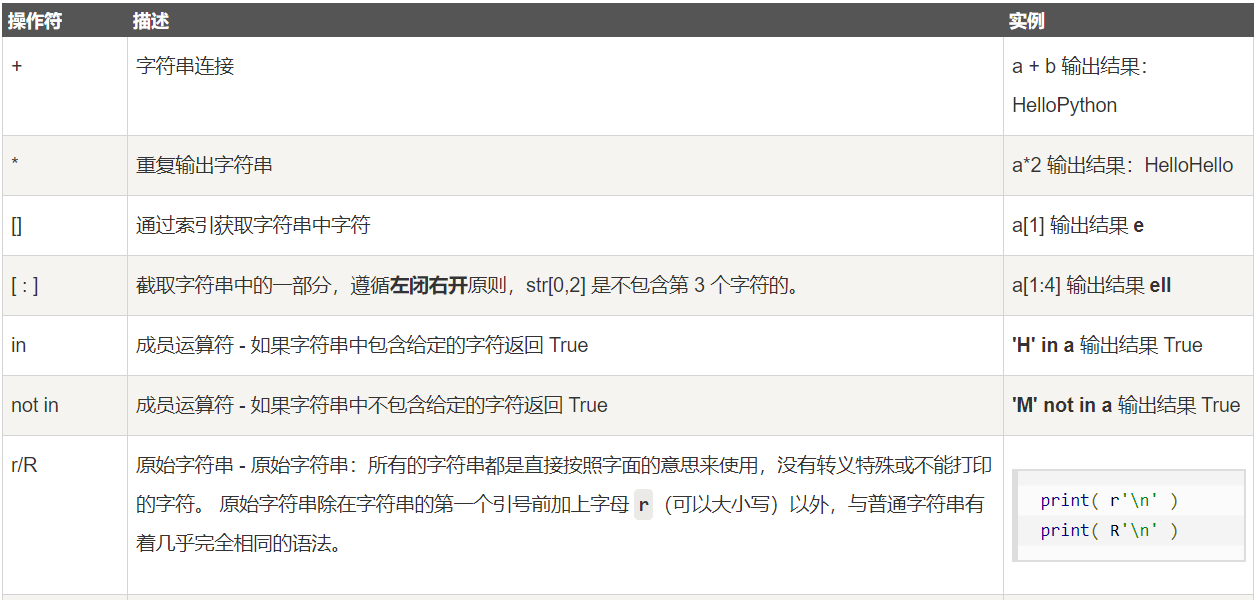
2、字符串运算符
变量a值为字符串 "Hello",b变量值为 "Python":
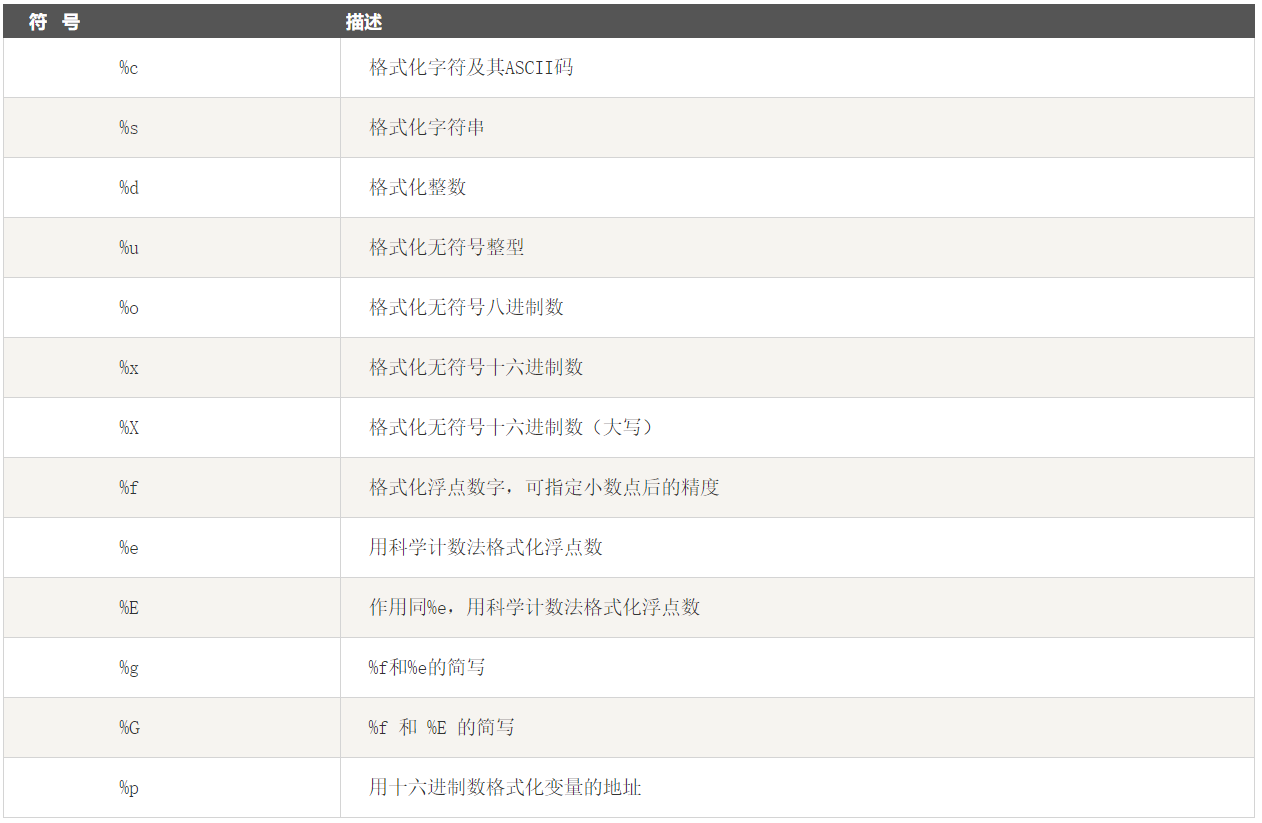
3、字符串格式化
print ("我叫 %s 今年 %d 岁!" % ('小明', 10)) #输出结果: 我叫 小明 今年 10 岁!
4、字符串内置方法


1 #capitalize()将首字母大写 2 >>> name = "san zhang" 3 >>> print(name.capitalize()) 4 #输出结果: 5 'San zhang' 6 7 8 #----------------------------------------------------------------------------------- 9 ''' 10 count(sub,start=None,end=None)统计 11 sub:统计的字符 12 start:开始位,默认为第一个字符,第一个字符索引值为0 13 end:结束位,字符中第一个字符的索引为 0。默认为字符串的最后一个位置 14 start和end默认为空时,则表示全部字符中去统计 15 ''' 16 17 >>> name = "san zhangz" 18 #有开始和结束符 19 >>> print(name.count('z',1,10)) 20 #从整个字符串中统计字符 21 >>> print(name.count('z')) 22 23 24 #----------------------------------------------------------------------------------- 25 ''' 26 center(width,fillchar) 27 28 width -- 字符串的总宽度 29 fillchar -- 填充字符 30 如果width(字符宽度)小于等于(<=)字符串的长度,则返回原字符串,如果大于(>)字符串的,则用fillchar(填满字符)填满,处理结果等于width,字符串位于fillchar的中间 31 ''' 32 33 >>> name = "san zhangz" 34 >>> len(name) 35 #10小于等于字符串宽度 36 >>> print(name.center(10,'-')) 37 #输出结果: 38 'san zhang-' 39 40 #51大于字符串长度,并且字符串位于填充字符的中间 41 >>> print(name.center(51,'-')) 42 #输出结果: 43 '--------------------san zhangz-------------------' 44 45 print(len(name.center(51,'-'))) 46 #输出结果: 47 '51' 48 49 50 #----------------------------------------------------------------------------------- 51 ''' 52 ljust(width,fillchar)原字符串左对齐 53 54 width -- 指定字符串长度 55 fillchar -- 填充字符,默认为空格 56 如果字符串的长度大于width(字符宽度),则返回原字符串,如果小于width,则用fillchar(填满字符)填满,处理结果等于width,fillchar位于字符串的最右边 57 ''' 58 59 >>> name = "san zhang" 60 >>> len(name) 61 #小于等于字符串的长度 62 >>> print(name.ljust(11,'-')) 63 #输出结果: 64 'san zhang--' 65 66 #大于字符串的长度 67 >>> print(name.ljust(50,'-')) 68 #输出结果: 69 'san zhang-----------------------------------------' 70 71 >>> len(name.ljust(50,'-')) 72 #输出结果: 73 '50' 74 注:ljust中的l表示left的意思,表示从右向左 75 76 77 #----------------------------------------------------------------------------------- 78 ''' 79 rjust(width,fillchar)原字符串右对齐 80 81 width -- 指定填充指定字符后中字符串的总长度 82 fillchar -- 填充的字符,默认为空格 83 如果字符串的长度大于width(字符宽度),则返回原字符串,如果小于width,则用fillchar(填满字符)填满,处理结果等于width,fillchar位于字符串的最左边 84 ''' 85 86 >>> name = "san zhang" 87 >>> len(name) 88 >>> print(name.rjust(11,'-')) 89 #输出结果: 90 '--san zhang' 91 92 >>> print(name.rjust(50,'-')) 93 #输出结果: 94 '-----------------------------------------san zhang' 95 96 >>> print(len(name.rjust(50,'-'))) 97 #输出结果: 98 '50' 99 注:rjust中的l表示left的意思,表示从左向右 100 101 102 #----------------------------------------------------------------------------------- 103 #编码(encode) 104 105 #字符串的编码和解码 106 107 >>> str = "python"; 108 >>> str_utf8 = str.encode("UTF-8") 109 >>> str_gbk = str.encode("GBK") 110 111 >>> print(str) 112 113 >>> print("UTF-8 编码:", str_utf8) 114 >>> print("GBK 编码:", str_gbk) 115 116 >>> print("UTF-8 解码:", str_utf8.decode('UTF-8','strict')) 117 >>> print("GBK 解码:", str_gbk.decode('GBK','strict')) 118 119 120 #----------------------------------------------------------------------------------- 121 ''' 122 endswith(suffix,start=None,end=None)判断字符串是否以指定后缀结尾 123 124 判断是否已suffix结尾,是返回True,否返回Fales 125 126 suffix:表示字符,start:开始位,end:结束位,start和end默认为空是,表示从整个字符串的结尾去判断 127 ''' 128 129 >>> name = "san zhang" 130 #start和end不为空 131 >>> print(name.endswith('g',1,5)) 132 False 133 #默认为空 134 >>> print(name.endswith('g')) 135 True 136 137 138 #----------------------------------------------------------------------------------- 139 ''' 140 find(sub,start=None,end=None)检测字符串中是否包含子字符串 141 142 全文查找sub中第一个字符所在整个字符串中的索引值,没有找到则返回-1 143 144 sub:字符或者字符串,start:开始位,end:结束位,start和end默认为空时,则在整个字符串中查找 145 ''' 146 147 >>> name = "san zhang" 148 #没找到,则返回-1 149 >>> print(name.find('zh',1,5)) 150 #输出结果: 151 '-1' 152 153 >>> print(name.find('zh')) 154 #输出结果: 155 '4' 156 157 158 #----------------------------------------------------------------------------------- 159 ''' 160 rfind(sub,start=None,end=None)字符串最后一次出现的位置 161 162 从左向右查找sub中第一个字符所在整个字符串中的索引值,没有找到则返回-1 163 164 sub -- 查找的字符串 165 start -- 开始查找的位置,默认为0 166 end -- 结束查找位置,默认为字符串的长度。 167 ''' 168 169 >>> name = "san zhang" 170 #找到 171 >>> print(name.rfind('z')) 172 #输出结果: 173 '4' 174 175 #未找到 176 >>> print(name.rfind('z',1,2)) 177 #输出结果: 178 '-1' 179 180 181 #----------------------------------------------------------------------------------- 182 format() 183 指定方式格式化 184 185 186 #----------------------------------------------------------------------------------- 187 #format_map() 188 189 #数据格式,以字典形式传入 190 191 >>> name = "name:{name},age:{age}" 192 >>> print(name.format_map({'name':'zhangsan','age':23}) 193 #输出结果 194 'name:zhangsan,age:23' 195 196 197 #----------------------------------------------------------------------------------- 198 ''' 199 isalnum()测字符串是否由字母和数字组成 200 201 是否是一个阿拉伯数字和字母,它包含因为英文字符+(1-9)数字,中间不能有特殊字符 202 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False 203 ''' 204 205 >>> age = '23' 206 >>> print(age.isalnum()) 207 #输出结果: 208 True 209 210 #有特殊字符的 211 >>> age = '2.3' 212 >>> print(age.isalnum()) 213 #输出结果: 214 False 215 216 >>> age = 'ab23' 217 >>> print(age.isalnum()) 218 #输出结果: 219 True 220 221 >>> age = 'ab' 222 >>> print(age.isalnum()) 223 #输出结果: 224 True 225 226 227 #----------------------------------------------------------------------------------- 228 ''' 229 isalpha()检测字符串是否只由字母或文字组成 230 231 是否是一个纯的英文字符,包含大写 232 如果字符串至少有一个字符并且所有字符都是字母或文字则返回 True,否则返回 False。 233 ''' 234 235 >>> age = 'ab' 236 >>> print(age.isalpha()) 237 #输出结果:True 238 239 #字母加数字 240 >>> age = 'ab23' 241 >>> print(age.isalpha()) 242 #输出结果:False 243 244 #大写 245 >>> age = 'Ab' 246 >>> print(age.isalpha()) 247 #输出结果:True 248 249 250 #----------------------------------------------------------------------------------- 251 ''' 252 isdigit()检测字符串是否只由数字组成 253 254 判断是否是一个整数 255 如果字符串只包含数字则返回 True 否则返回 False 256 ''' 257 258 #数字 259 >>> age = '123' 260 >>> print(age.isalpha()) 261 #输出结果:True 262 263 #字母 264 age = 'ab' 265 print(age.isdigit()) 266 #输出结果:False 267 268 #数字加字母 269 >>> age = '123ad' 270 >>> print(age.isalpha()) 271 #输出结果:False 272 273 274 #----------------------------------------------------------------------------------- 275 ''' 276 isspace()判断是否是一个空格 277 278 如果字符串中只包含空格,则返回 True,否则返回 False 279 ''' 280 281 #不是空格 282 >>> age = ' age' 283 >>> age.isspace() 284 #输出结果:False 285 286 #是空格 287 >>> age = ' ' 288 >>> age.isspace() 289 #输出结果:True 290 291 292 #----------------------------------------------------------------------------------- 293 ''' 294 istitle()判断是否是一个空格 295 检测字符串中所有的单词拼写首字母是否为大写,且其他字母为小写 296 如果字符串中所有的单词拼写首字母是否为大写,且其他字母为小写则返回 True,否则返回 False 297 ''' 298 299 #每个单词的首字母是大写 300 >>> name = "Zhang San" 301 >>> print(name.istitle()) 302 #输出结果:True 303 304 #每个单词的首字母是小写 305 >>> name = "zhang san" 306 >>> print(name.istitle()) 307 #输出结果:False 308 309 310 #----------------------------------------------------------------------------------- 311 ''' 312 isupper()所有的字母是否都为大写 313 314 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False 315 ''' 316 317 #全部大写 318 >>> name="ZHANG" 319 >>> print(name.isupper()) 320 #输出结果:True 321 322 #小写 323 >>> name="Zhang" 324 >>> print(name.isupper()) 325 #输出结果:False 326 327 328 #----------------------------------------------------------------------------------- 329 ''' 330 join()将序列中的元素以指定的字符连接生成一个新的字符串 331 332 sequence -- 要连接的元素序列 333 序列用某个字符拼接成一个字符串,注意的是,序列的元素必须是str类型 334 ''' 335 336 >>> a = ['1','2','3'] 337 >>> print('+'.join(a1)) 338 #输出结果:'1+2+3' 339 340 >>> a="" 341 >>> a1 = ('1','2','3') 342 >>> print(a.join(a1)) 343 #输出结果:'123' 344 345 346 #----------------------------------------------------------------------------------- 347 ''' 348 lower() 349 350 字符串中的大写字母转换为小写字母 351 ''' 352 353 >>> name = "Zhangsan" 354 >>> print(name.lower()) 355 #输出结果:'zhangsan' 356 357 358 #----------------------------------------------------------------------------------- 359 ''' 360 upper() 361 362 字符串中的小写字母转换为大写字母 363 ''' 364 365 >>> name = "Zhangsan" 366 >>> print(name.upper()) 367 #输出结果:'ZHANGsan 368 369 370 #----------------------------------------------------------------------------------- 371 ''' 372 strip() 373 374 去掉左右两边的空格(space)和回车(\n) 375 ''' 376 377 >>> name = " \n zhangsan \n" 378 >>> print(name.strip()) 379 #输出结果:'zhangsan' 380 381 382 #----------------------------------------------------------------------------------- 383 ''' 384 lstrip() 385 386 删掉左边到右的空格(space)和回车(\n) 387 ''' 388 389 >>> name = " \n zhangsan \n" 390 >>> print(name.lstrip()) 391 #输出结果:'zhangsan ' 392 393 394 #----------------------------------------------------------------------------------- 395 ''' 396 rstrip() 397 398 删掉右边到左边的空格(space)和回车(\n) 399 ''' 400 401 >>> name = " \n zhangsan \n" 402 >>> print(name.rstrip()) 403 #输出结果:' zhangsan' 404 至此,方法前有l(left)和r(right)的函数,都是对之前函数的一个扩展,带l的表示至始至终从右到左操作,记住左边才是最终目的地,而带r的至始至终都是从左到右,因为右边才是它的终极目标 405 406 407 #----------------------------------------------------------------------------------- 408 ''' 409 split() 410 411 分割函数,默认是以空格分割(space)生成一个列表,如果其他字符分割,输入其他字符参数 412 ''' 413 414 >>> name = "san zhang" 415 #默认为空,按空格分割 416 >>> print(name.split()) 417 #输出结果:['san', 'zhang'] 418 419 #以'+'字符分割 420 >>> name = "san+zhang" 421 >>> print(name.split("+")) 422 #输出结果:['san', 'zhang'] 423 424 #以'\n'分割 425 >>> name = "san\nzhang" 426 >>> print(name.split("\n")) 427 #输出结果:['san', 'zhang'] 428 429 430 #----------------------------------------------------------------------------------- 431 ''' 432 splitlines() 433 434 以换行符分割,这个一般在windows上开发,移到Linux上执行,或者在Linux上开发,移到Windows上执行,因为换行在windows上是"\r\n",linux上是'\n' 435 ''' 436 437 >>> name = "san\nzhang" 438 >>> print(name.splitlines()) 439 #输出结果:['san', 'zhang'] 440 441 442 #----------------------------------------------------------------------------------- 443 ''' 444 swapcase() 445 446 把大写换成小写,把小写换成大写 447 ''' 448 449 >>> name = "ZHang" 450 >>> name.swapcase() 451 #输出结果:'zhANG' 452 453 454 #----------------------------------------------------------------------------------- 455 ''' 456 startswith(prefix, start=None,end=None) 457 458 判断是否已prefix结尾,是返回True,否返回Fales 459 460 prefix:表示字符或者字符或者字符串,start:开始位,end:结束位,start和end默认为空是,表示从整个字符串的结尾去判断 461 ''' 462 463 >>> name = "zhang san" 464 >>> name.startswith("zhang") #开头找到"zhang" 字符串 465 #输出结果:True 466 467 >>> name.startswith("h",3,5) #在索引3到5之间没有找到以字符'h'开头 468 #输出结果:False 469 470 471 #----------------------------------------------------------------------------------- 472 ''' 473 replace(old,new[, max]) 474 475 old:将被替换的子字符串; new:新字符串,用于替换old子字符串;max:可选字符串, 替换不超过 max 次 476 ''' 477 478 >>> name = "zhang san" 479 >>> print(name.replace("san","si")) 480 #输出结果:'zhang si' 481 #原字符串没有改变 482 >>> print(name) 483 #输出结果:'zhang san' 484 485 >>> print(name.replace("san","si",0)) 486 #输出结果:'zhang san' 487 >>> print(name.replace("san","si",1)) 488 #输出结果:'zhang si' 489 490 491 #----------------------------------------------------------------------------------- 492 ''' 493 zfill(width) 494 495 字符的长度是否大于等于(>=)with,如果比width小,则在字符串钱用0填充,如果>=width,则返回原字符串 496 ''' 497 498 >>> name = "zhang san" 499 #width大于字符串长度 500 >>> print(name.zfill(10)) 501 #输出结果:'0zhang san' 502 503 #width小于等于字符串长度 504 >>> print(name.zfill(9)) 505 #输出结果:'zhang san'
format()
字符串的函数 str.format(),它增强了字符串格式化的功能。
基本语法是通过 {} 和 : 来代替以前的 % 。
format 函数可以接受不限个参数,位置可以不按顺序。
>>> print("{} {}".format("hello","world")) # 不设置指定位置,按默认顺序 #输出结果:'hello world' >>> print("{0} {1}".format("hello", "world")) # 设置指定位置 #输出结果:'hello world' >>> print("{1} {0} {1}".format("hello", "world")) # 设置指定位置 #输出结果:'world hello world'
也可以设置参数:
print("网站名:{name}, 地址 {url}".format(name="QQ", url="www.QQ.com")) # 通过字典设置参数 site = {"name": "QQ", "url": "www.QQ.com"} print("网站名:{name}, 地址 {url}".format(**site)) # 通过列表索引设置参数 my_list = ['QQ', 'www.QQ.com'] print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是可选的
数字格式化:
str.format() 格式化数字的多种方法
>>> print("{:.2f}".format(3.1415926)); #输出结果:3.14

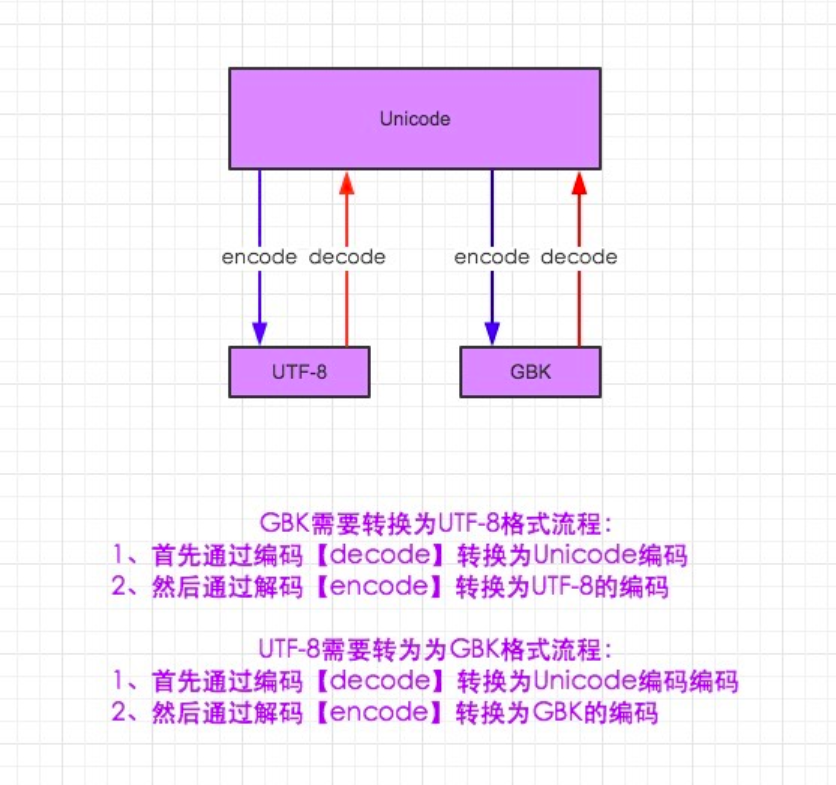
二、字符编码与转码
总结:
1.在python2默认编码是ASCII, python3里默认是unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
详细文章:
http://www.cnblogs.com/yuanchenqi/articles/5956943.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号