
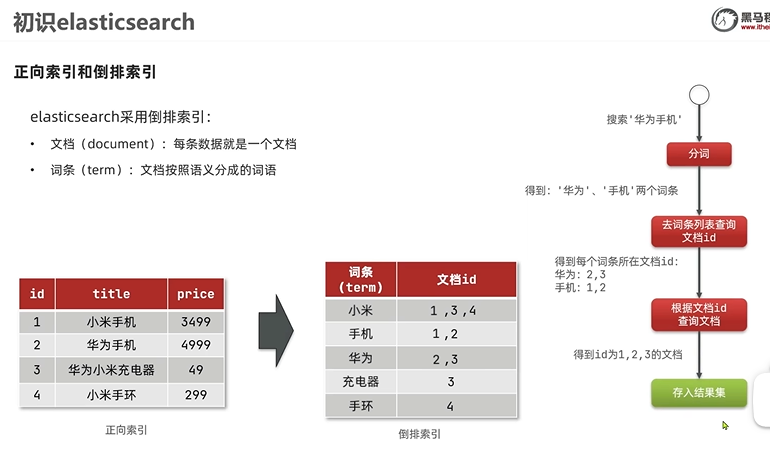
ES采用倒排索引,用分词器把文本分成词条,放入索引库,并且会赋上文档ID,词条不重复,所以相同词条的文档ID会放在一起,搜索的时候就很快能拿到所有相关的文档ID,这样就一下能找到所有包含相关词语的文档,速度很快。擅长海量数据的搜索
ES的索引就是一类文档的集合,相当于Mysql里的表。
ES的一条数据就相当于一个文档。DSL相当于SQL,是json格式的请求语句,实现CRUD。映射是文档的约束
IK分词器有扩展词典(自定义添加扩展词语)和停止词典(禁用一些敏感词语)。分词器的底层是词典,里面已经存在很多词语了,分词的时候根据这个词典来进行分。
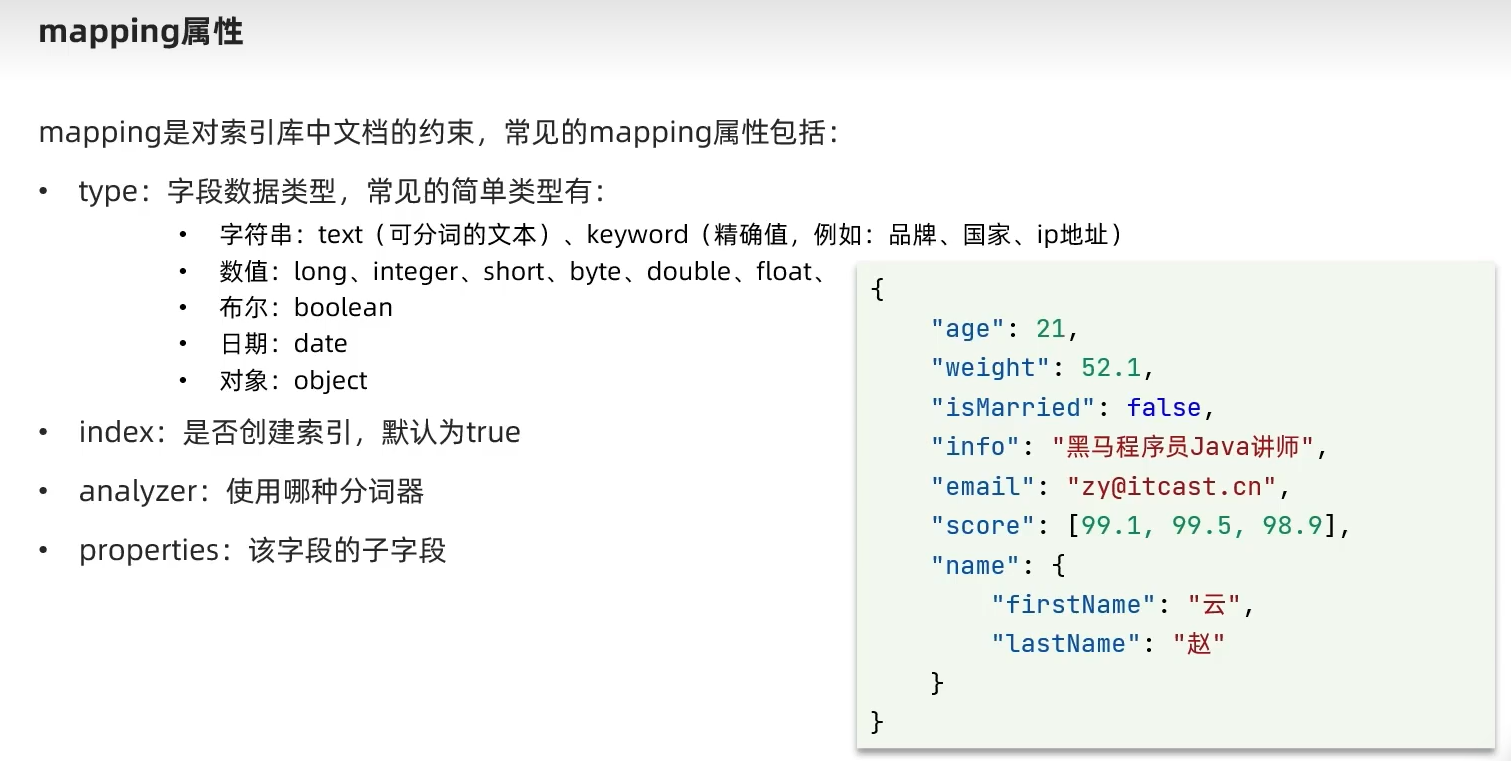
索引库用来对每个字段进行一些约束,是否参与搜索,是否要分词,用什么分词器。创建索引库一般需要考虑字段的type(如果是text那么需要分词,如果是keyword那么不需要分词),以及index(既是否需要参与搜索,默认为true,可以改),以及analyzer(分词器类型):smart(细度粗,maxword细度细)

restClient在Java里使用ES。
查询类型:

全文检索(部分匹配,找需要分词的,多用于搜索框的搜索,比如酒店信息,商品名称),精确查询(完全匹配,需要精确的找到的,比如范围,id等)
员工信息表-----(多对一)部门表,职位表,
搜索结果处理:
排序:默认根据相关度排序,可以排序的字段有数值排序,地理坐标排序(订酒店时输入一个坐标,会根据距离列出附近酒店),日期排序(根据日期来排)
分页:通过修改from和size来分页

 浙公网安备 33010602011771号
浙公网安备 33010602011771号