《Large-Scale Training System for 100-Million Classification at Alibaba》阅读笔记
Extreme Classification介绍
0. Abstract
极端分类系统体系结构:
1)KNN softmax损失模块--->作用:快速计算和推导
2)通信模块-------------->包括:混合管道(hybrid pipeline)和梯度稀疏化
3)快速收敛模块---------->包括:大型批处理优化器和学习率调度器
1. Introduction
1)极端分类:
来源:香草多类别分类问题
应用:企业级别的数据集上人脸识别、语言建模
2)研究背景:
原因:阿里巴巴的零售产品数据集,类别数达到亿级,图像数数十亿张;每个图像以库存单位(SKU)级别标记
目标:亿级的极端分类系统,为了提高视觉系统的识别能力
3)问题挑战:
内存和计算能力开销
通讯开销:多GPU之间的通信
收敛:并行训练中,同步随机梯度下降节点数量增加的时候,大批量训练的精度会降低
4)以往解决办法:
特征嵌入方法:将inputs和class投到小尺寸的子空间中,而不是最后使用大的全连接层。缺点:需要成对损失函数,以及精心设计的负采样
分层softmax:扩展性差;不能保证图像分类的准确性;对并行不友好(使用基于交叉熵的分类器的标准softmax可以解决这个问题)
5)本文提出的解决方法(下图所示):
使用混合并行框架减轻GPU集群中的模型分配
使用具有交叉熵损失的标准softmax训练这样的“big head”神经网络
6)具体贡献:
引入KNN softmax,可以直接对1亿个图像类别进行分类,节省了计算量和GPU内存,提高速度
提出新的通信策略,包括重叠的管道和梯度稀疏化方法,减少了开销并加快了训练速度
提出新的训练策略,来更新模型参数,并自适应调整学习率。可以减少训练迭代次数的同时达到和纯softmax同样的精度
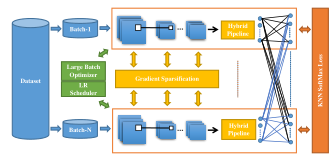
0)极端分类系统有4个主要部分:
并行计算方法
无损失精度的softmax函数
在大型GPU集群中构建通信策略
快速收敛
1)paralle training(并行训练)
[14]提出训练方案,用数据并行化和模型并行化,一起并行化去训练具有随机梯度下降(SGD)卷积神经网络
[6]在一台机器上,并行训练百万级别的身份识别
[本文]将混合并行方案扩展到更大的GPU集群上;优化训练管道以加速训练
2)softmax variations(softmax函数)
①选择性softmax:
[29]基于动态类级别的有效方法来接近最优选择。缺点有二:一是不能完全GPU实现;二是选择性softmax性能低于完整softmax,尤其在大型实验中
②通过哈希的合并平均分类器:
[]
3)efficient communication(通信策略)
4)fast convergence(快速下降)
3. 100 Million Classification
3.1 系统结构
1)模型并行方式:将大的全连接层分成划分成不同的子层,将子层送到不同GPU训练;减少同步梯度的通信开销
3.2 KNN softmax
3.3 通信策略
3.4 快速持续的收敛算法
4. Experiments
4.1 数据集
1)3个量级的数据集:SKU-1M,SKU-10M,SKU-100M
2)发布了全新数据集AliProducts:3百万个图像,5万SKU个产品种类
3)混合并行训练中,ResNet-50作为特征抽取部分的基本模型,最后的特征维度是512
4)默认将混合精度训练方法作为训练框架
5)GPU集群(32*8),GPU之间通过NVLink通信;25Gbit网卡联网通信
6)用PyTorch
4.2 KNN softmax的评估
分别评估【精度】和【吞吐量】,与SOTA方法进行对比分析。
1)精度评估
selective softmax
2)吞吐量评估
4.3 通信策略的评估
4.4 快速持续收敛算法的评估
1)混合并行管线
2)梯度稀疏化
4.5 极端分类系统的评估
1)提高吞吐量
方法:KNN softmax,混合平行重叠,逐层的top-k梯度稀疏化
结果:51800 images/sec,提高了3.9倍
2)提高速度
方法:快速持续收敛
结果:迭代次数变化 20->8,提升2.5倍
3)整体评价
训练时间从45d到5d的情况下,精度相差不多
4.6 部署
5. Conclusion
1)部署KNN softmax以减少GPU内存消耗和计算成本
2)设计新的通信策略,包含混合并行重叠管线和逐层的top-k梯度稀疏化,减少通信开销
3)提出快速持续收敛策略,通过自适应调整学习率、更新参数来加快训练速度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号