团队作业5——测试与发布(Alpha版本)
| 软件工程 | 班级链接 |
|---|---|
| 作业要求 | 作业要求 |
| 作业目标 | 测试与发布团队开发项目的Alpha版本 |
| github仓库 | 团队项目 |
队名:P人大联盟
团队成员
| 姓名 | 学号 |
|---|---|
| 王睿娴 | 3222003968 |
| 张颢严 | 3222004426 |
| 梁恬(组长) | 3222004467 |
| 潘思言 | 3222004423 |
本篇博客目录
1.1.1目录索引无法响应
1、Alpha版本测试报告
1.1、测试过程和测试结果
- 在此次Alpha版本的测试过程中,总共发现了 9个Bug,具体分类如下:
| Bug类别 | 数量(单位:个) |
|---|---|
| 修复的Bug | 4 |
| 不能重现的Bug | 1 |
| 设计问题(不是Bug) | 1 |
| 延迟到下一个版本修复的Bug | 3 |
1.1.1、修复的Bug
- 输入相同微博cookie,关键词,时间段,微博内容选区类型和不同地区但收集的文本数据相同,已修复
- 生成提问的句子无法正确上传并发送给AI,已修复
- 输入格式正确日期无法成功进行情感分析,已修复
- 情感分析模型接收空值无法进行正常分析,已修复
1.1.2、不能重现的Bug
- 数据收集模块的爬虫settings程序文件在运行时变为空
1.1.3、设计问题
- 无法鉴别输入微博地区是否有效
1.1.4、延迟到下一个版本修复的Bug
- 不确定输入微博cookie是否有效
- 收集处理分析文本数据需要的时间随用户指定的范围而变化,且难以预测
- 分析时占用用户本身电脑的内存与cpu资源,进而也使得分析处理文本数据也受限于用户本身电脑的内存与cpu资源,导致可能由于内存与cpu资源情感分析失败
1.2、场景测试
1.2.1、用户使用预期与功能组合
| 使用用户 | 使用预期 | 需求 | 目标 | 提软件提供的功能组合 |
|---|---|---|---|---|
| 产品/品牌营销经理 | 获取微博网友对品牌/产品本身或营销的情感分析结果 | 收集分析提取大量微博网友发布内容中对品牌/产品本身或营销的情感态度 | 获取情感倾向分布与不同情感的关键文本反馈,并结合gpt对情感分析结果的分析说明建议,调整品牌/产品的营销策略 | 对指定关键词,地区,时间,内容类型和筛选类型的微博发布中文文本情感分析功能 + AI交流功能 |
| 微博平台舆情管理者 | 获取微博网友对热门事件的情感分析结果 | 收集分析提取大量微博网友发布内容中对热门事件的情感态度 | 获取情感倾向分布与不同情感的关键文本反馈,并结合gpt对情感分析结果的分析说明建议,调整微博内容的推送策略,引导平台舆情走向积极与正面 | 对指定关键词,地区,时间,内容类型和筛选类型的微博发布中文文本情感分析功能 + AI交流功能 |
1.3、测试矩阵
T表示通过,F表示未通过
1.3.1、数据收集模块测试
测试软硬件配置
- 处理器:13th Gen Intel(R) Core(TM) i9-13980HX 2.20 GHz
- 机带RAM:16.0 GB (15.6 GB 可用)
- 操作系统:Windows 11 家庭中文版
- IDE:PyCharm 2024.2.1 (Professional Edition)
| 测试项 | 检验点 | 预期结果 | Windows 11 + Pycharm | 截图 |
|---|---|---|---|---|
| 是否生成符合预期的URL | 输入关键词列表,起止日期后检查函数返回的URL | URL格式正确,含关键字、日期参数,地区参数匹配 | T | 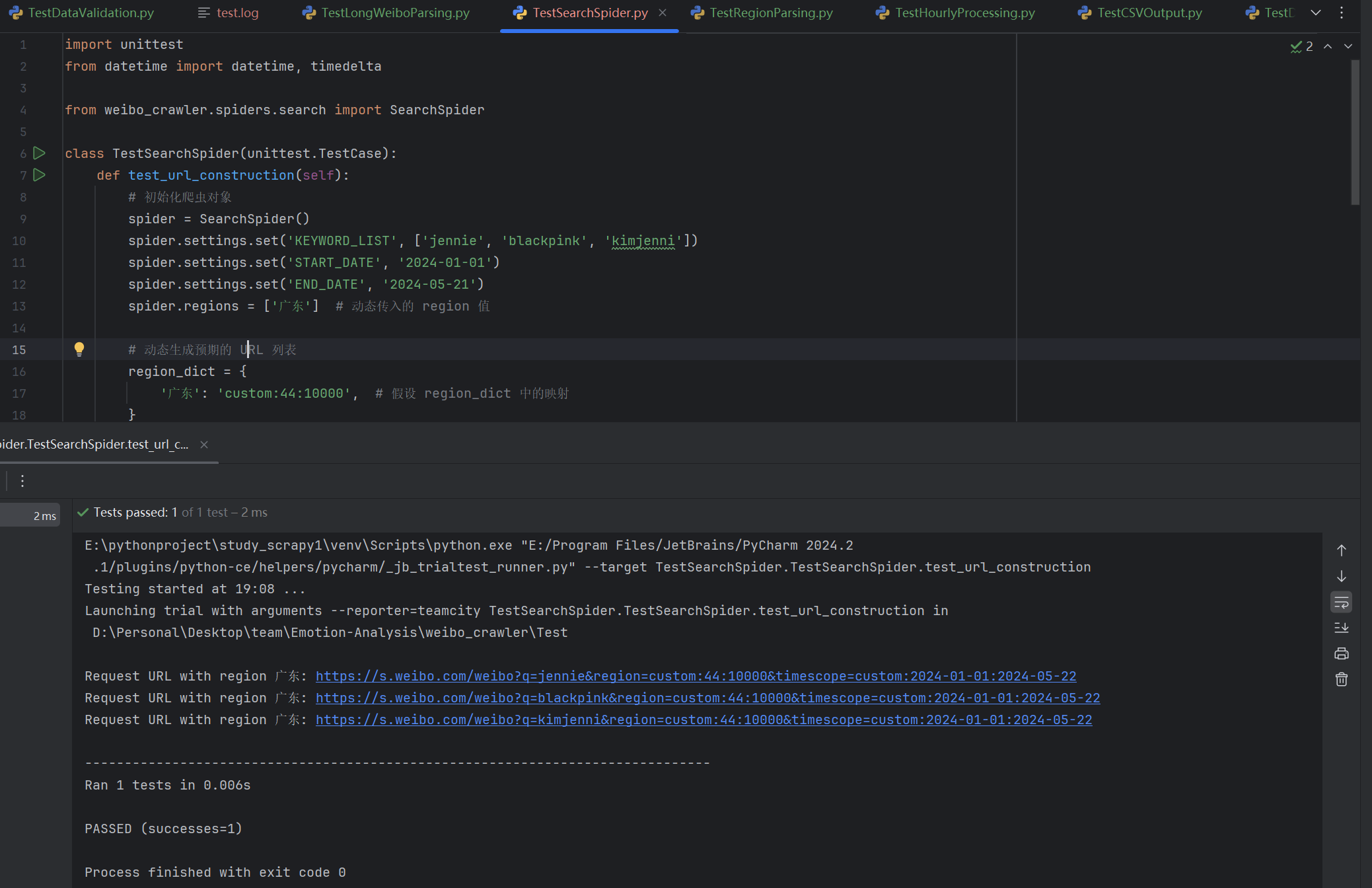 |
| 是否爬取包含完整字段数据 | 读取爬取结果检验数据字段 | 爬取的数据包含字段:keyword,region,id,user,text,created_at,source |
T | 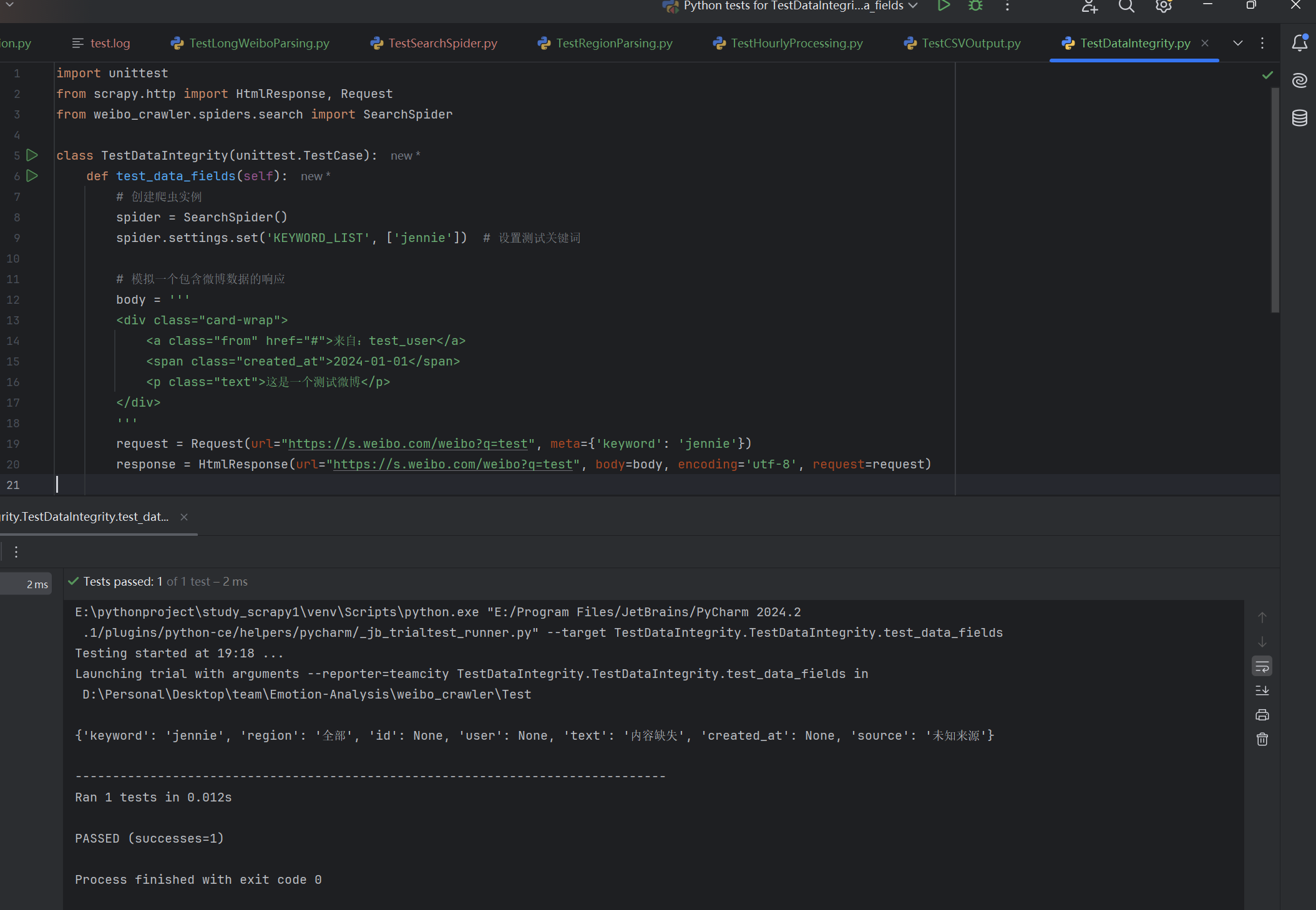 |
| 是否正确处理并爬取分页 | 读取爬取结果检验是否包含多页数据 | 爬取所有页面数据,分页解析完整 | T | 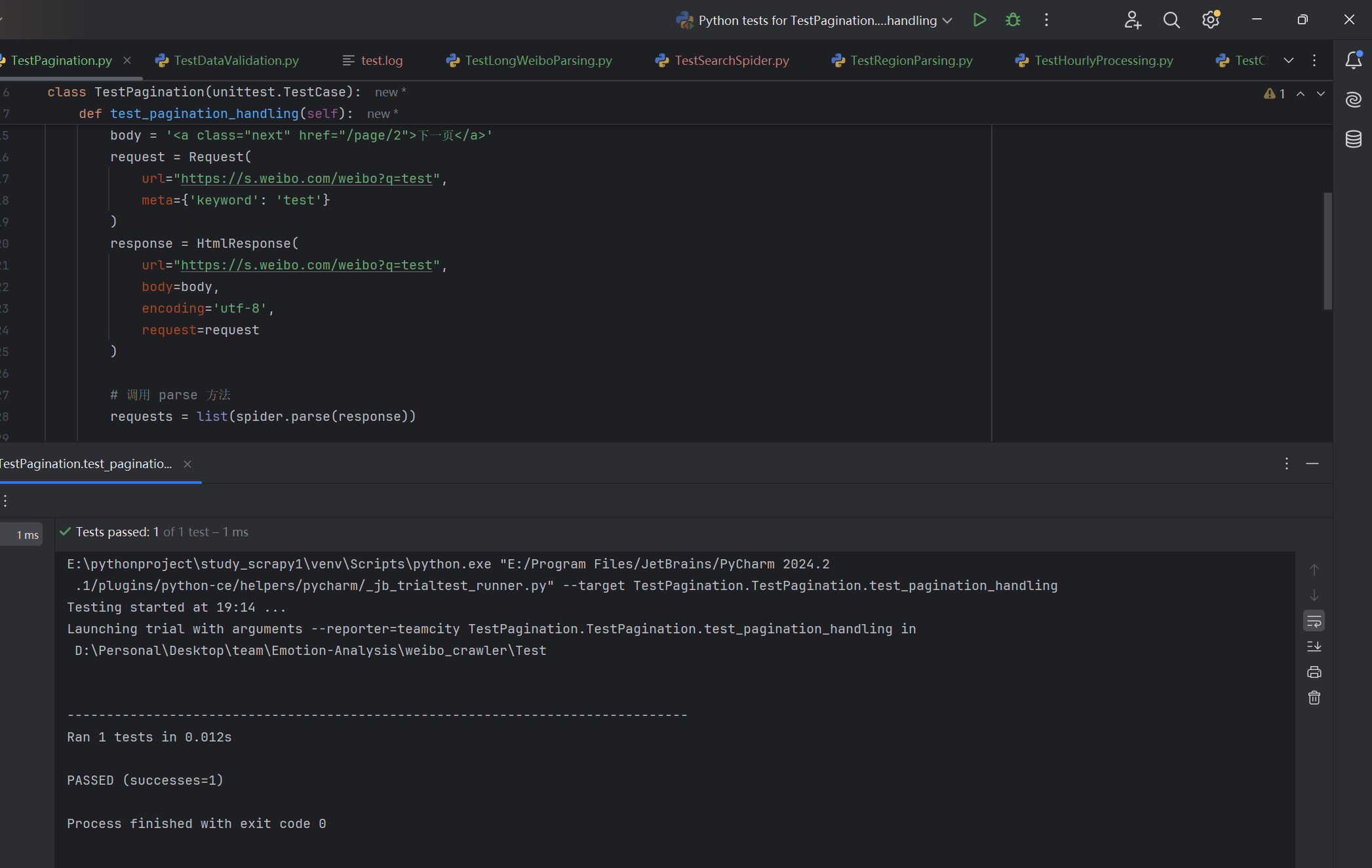 |
| 是否在起止日期设置错误时程序正常退出 | 输入的起始日期大于结束日期,查看后续程序反应 | 程序正常退出,提示错误信息 | T | 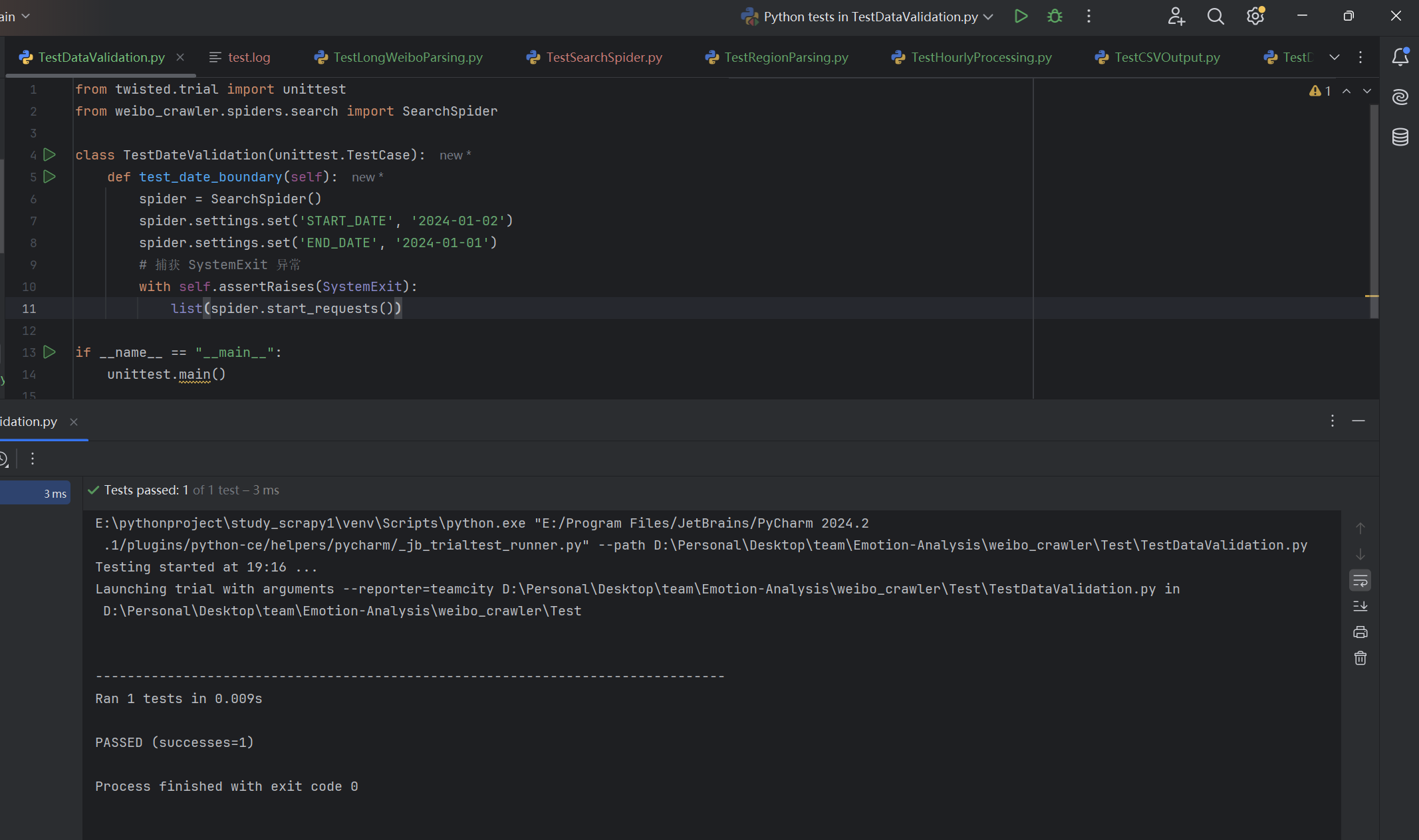 |
| 是否正确解析长微博的完整内容 | 输入含长微博的URL检查最终的爬取结果 | 爬取的对应长微博内容完整,已去掉省略符 | T | 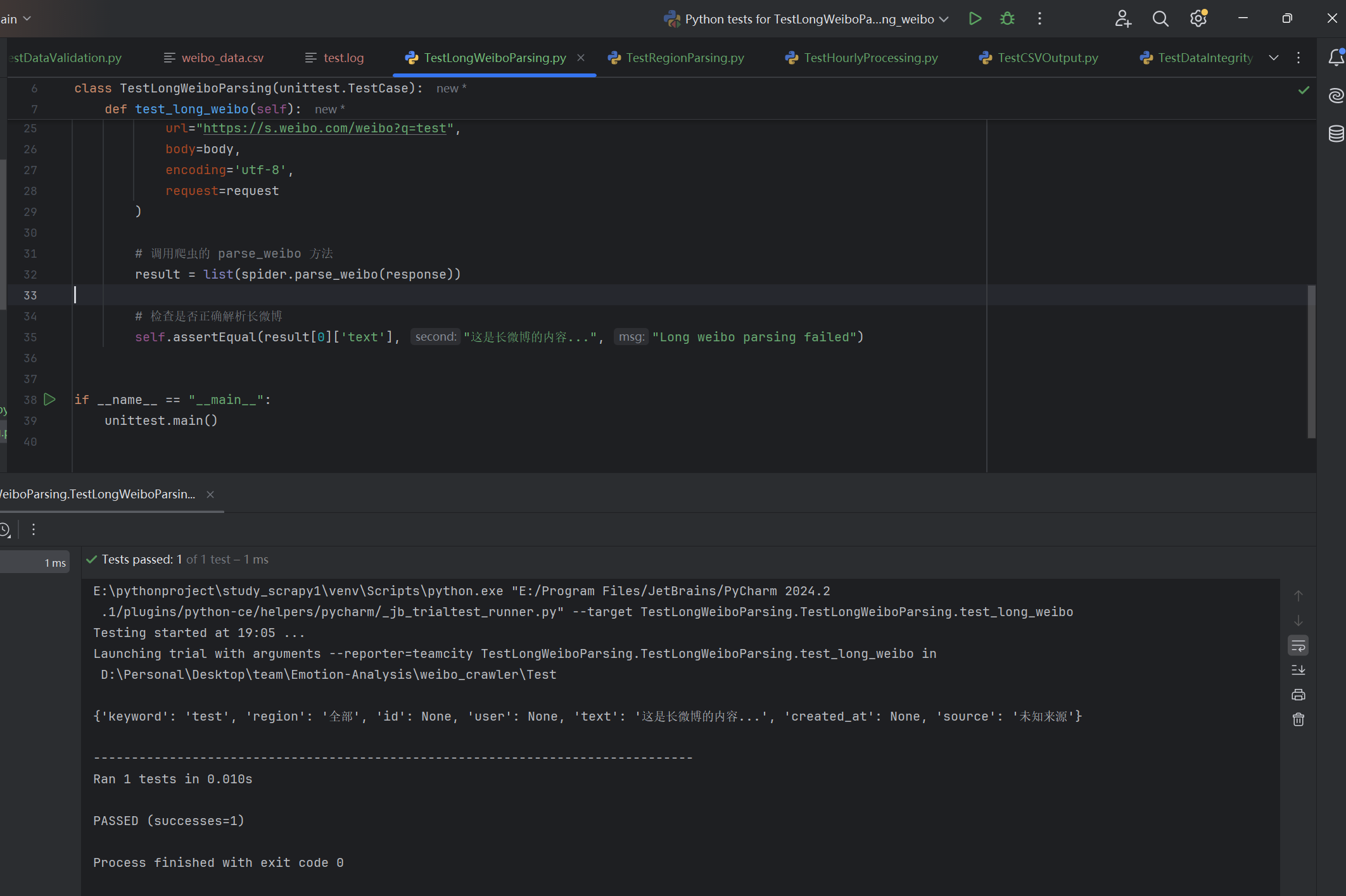 |
| 是否正确按指定地区抓取对应的URL和数据 | 输入指定地区名称列表检查生成的URL和爬取结果 | 按输入地区列表生成正确的请求URL,爬取数据中包含指定的地区字段 | T | 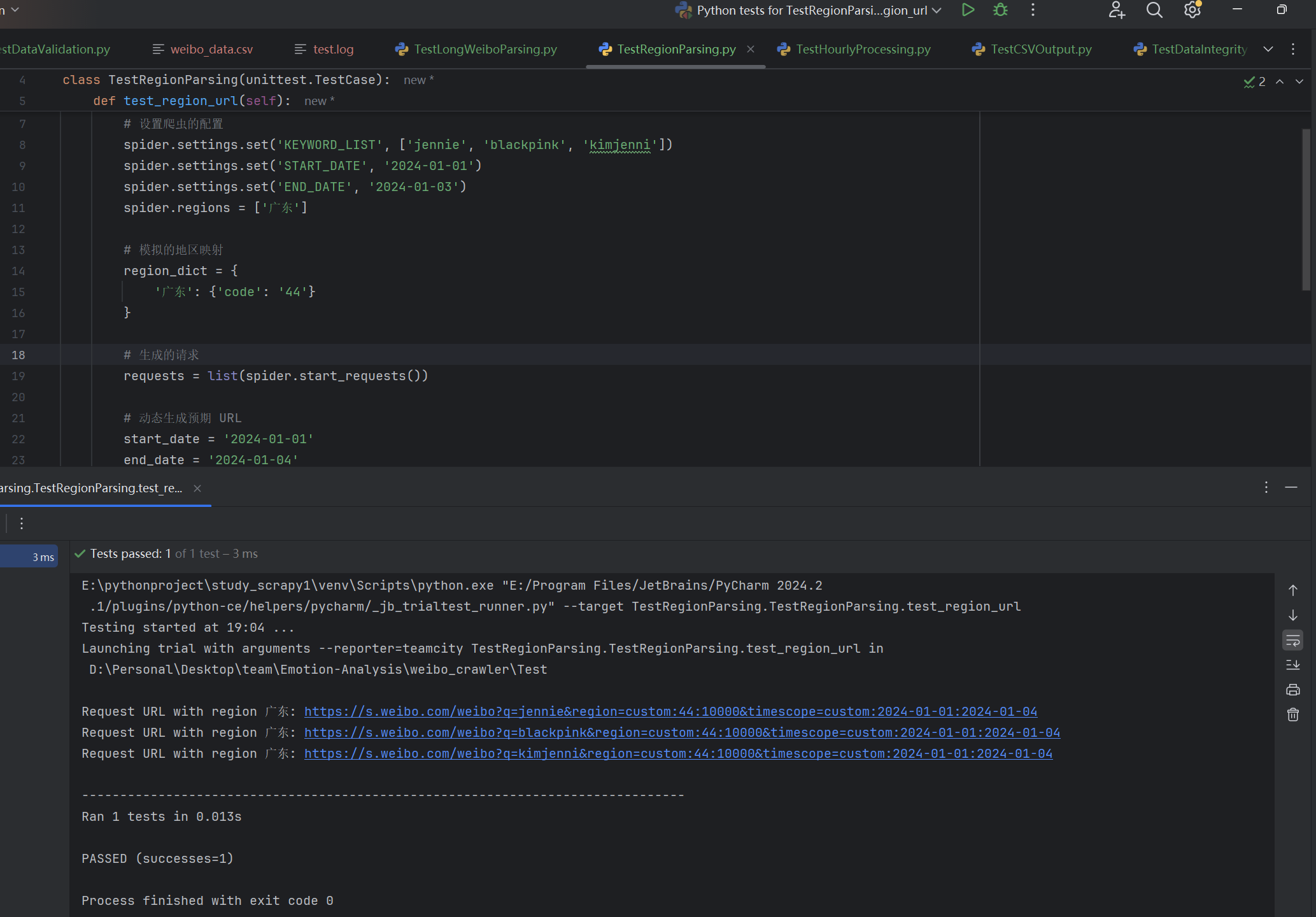 |
| 按小时细分逻辑是否正确实现 | 输入一定日期范围内检查生成请求 | 生成的请求是完整且按小时细分的 | T | 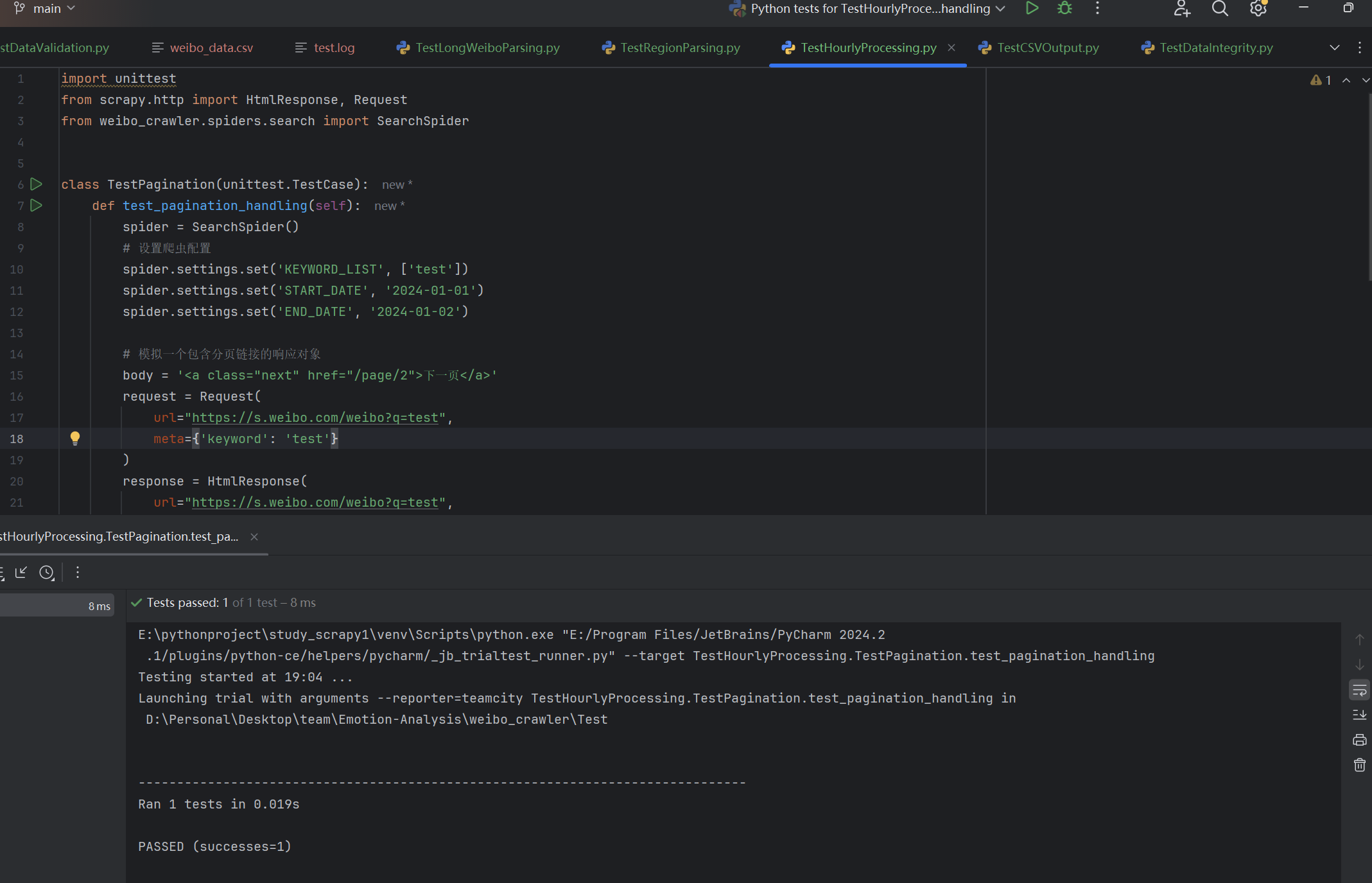 |
| 爬取数据是否按预期格式写入输出CSV文件 | 检查存储爬取结果的csv文件中的爬取数据格式 | CSV文件中的爬取数据包含要求所有字段,格式正确 | T | 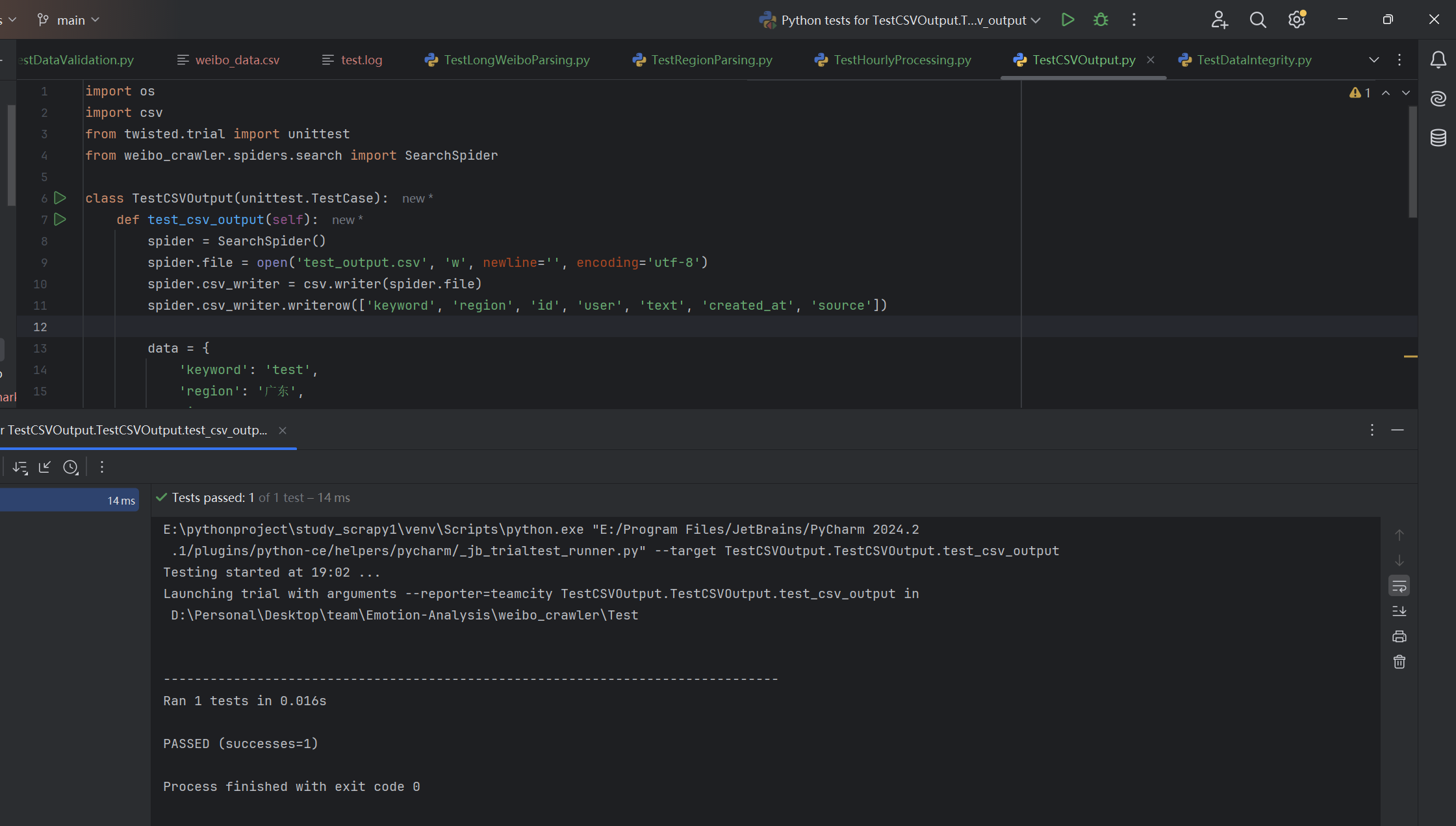 |
1.3.2、文本预处理模块测试
测试软硬件配置
- 处理器:11th Gen Intel(R) Core(TM) i5-11320H @ 3.20GHz 3.19 GHz
- 机带RAM:16.0 GB (15.8 GB 可用)
- 操作系统:Windows 11
- IDE:PyCharm 2023.3.3 (Community Edition)
| 测试项 | 检验点 | 预期结果 | Windows 11 + Pycharm | 截图 |
|---|---|---|---|---|
加载爬取数据load_scraped_data函数能否正确读取爬取数据 |
函数运行后返回的数据列表 | 返回数据列表与测试文件中的数据长度相同 | T | 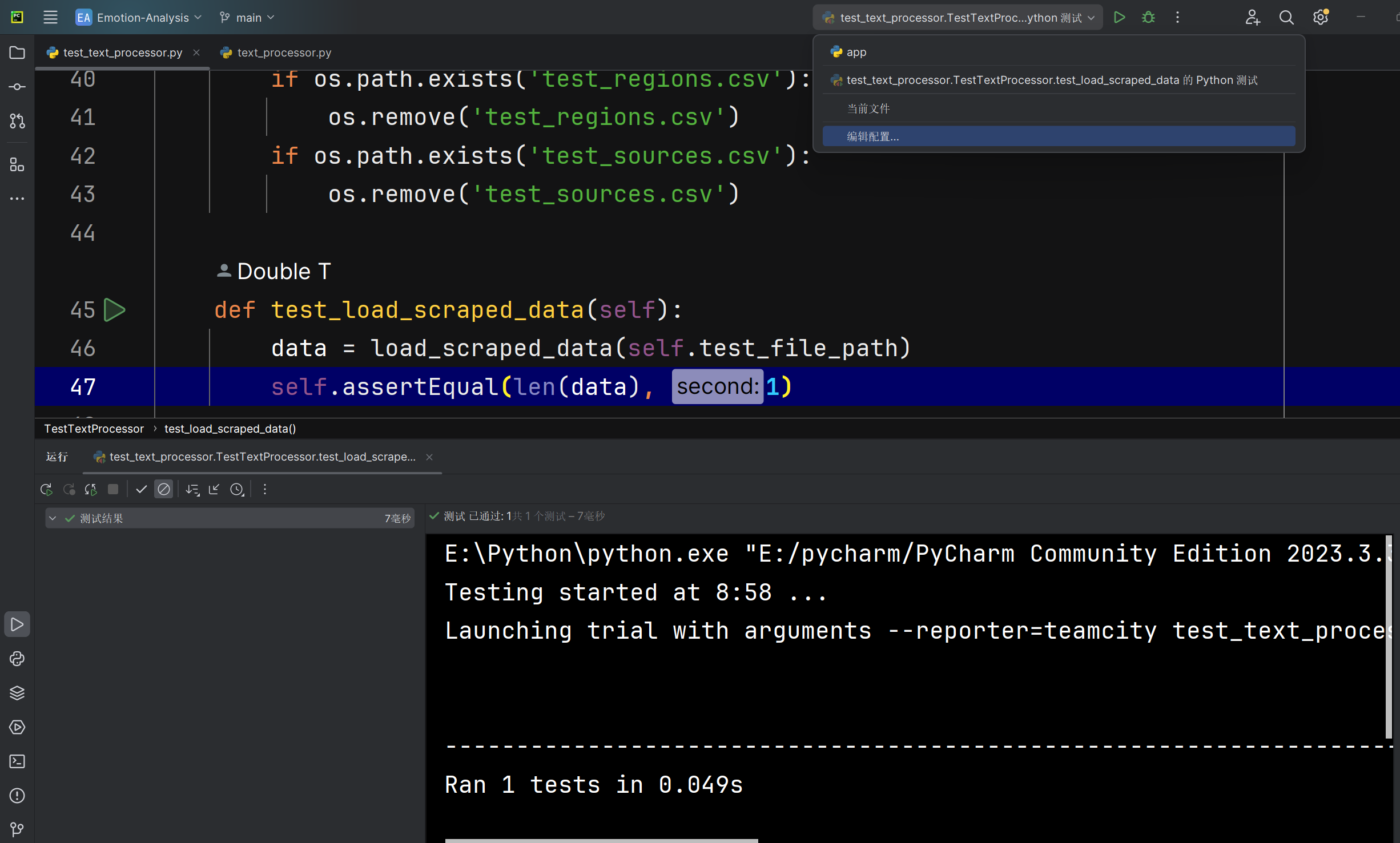 |
将表情转换为中文explain_emojis函数能否正常转换表情为中文文字 |
函数运行后返回的文本 | 文本中的指定表情被转换为对应的指定中文 | T | 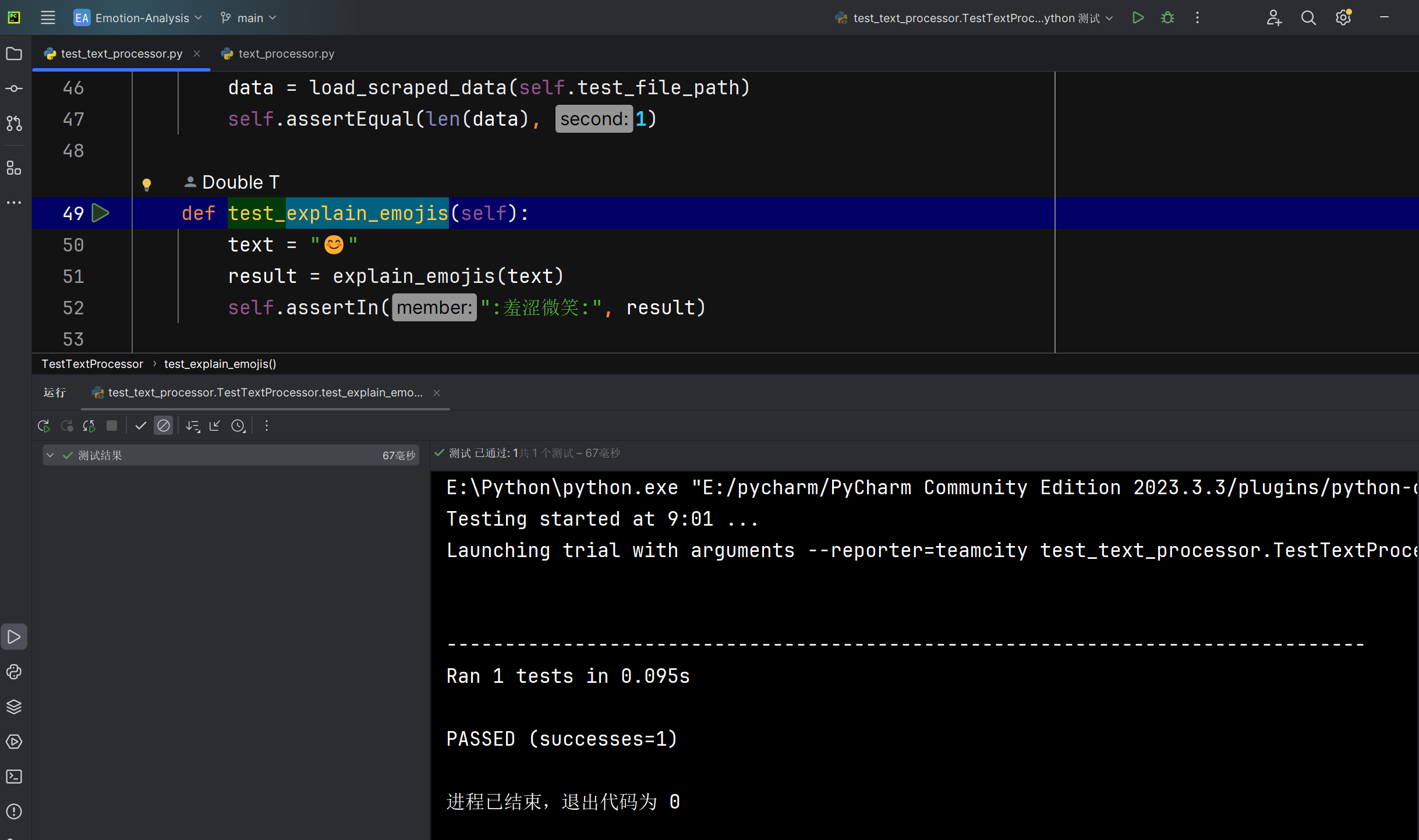 |
中文分词cut_words函数能否正确将中文句子转变为对应分词 |
函数运行后返回的分词结果 | 返回的分词结果与预测结果相同 | T | 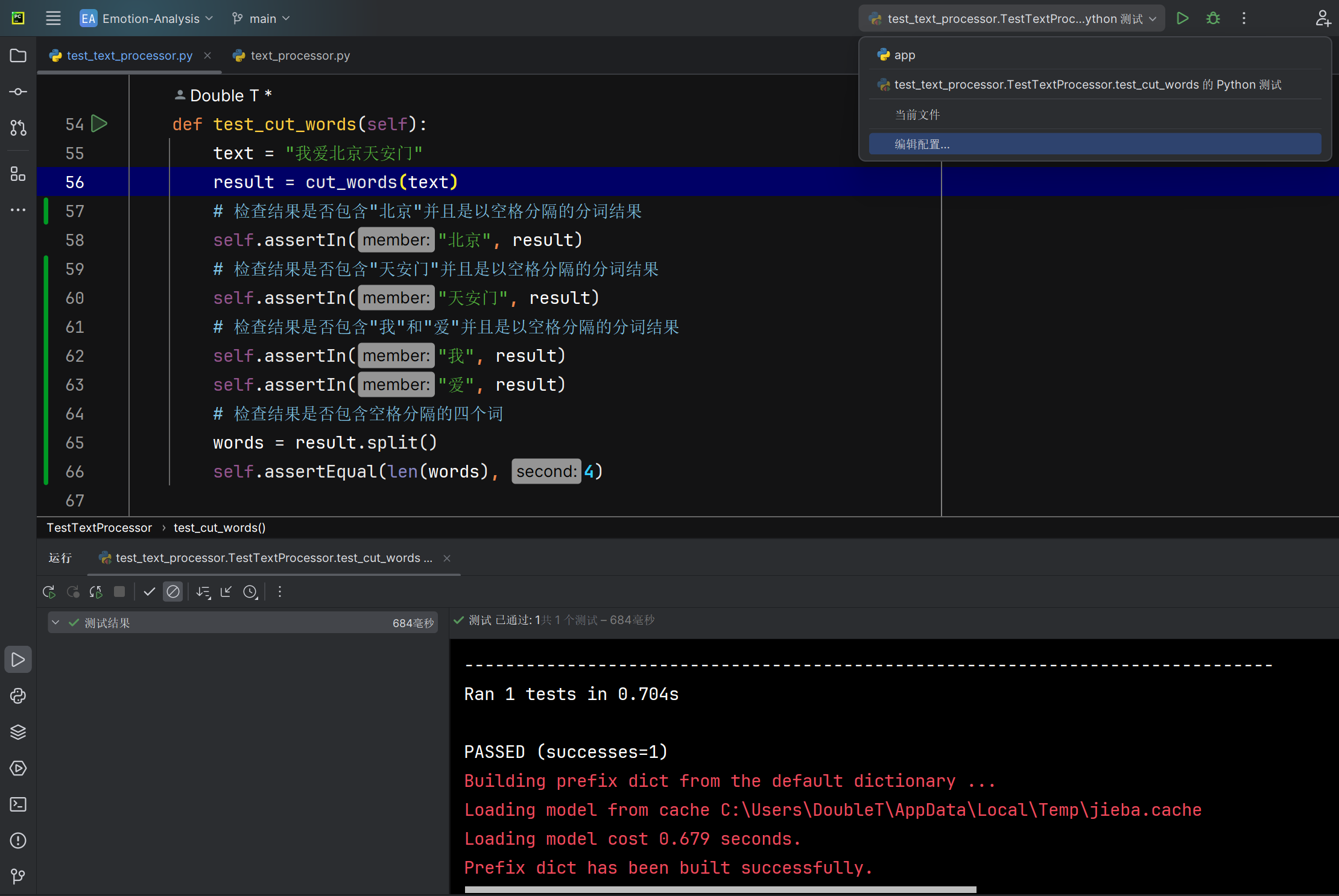 |
清洗url,htmlrm_url_html函数能否正确将爬取文本中的url,html数据去除 |
函数运行后返回的文本 | 文本中的URL和HTML标签被清洗掉 | T | 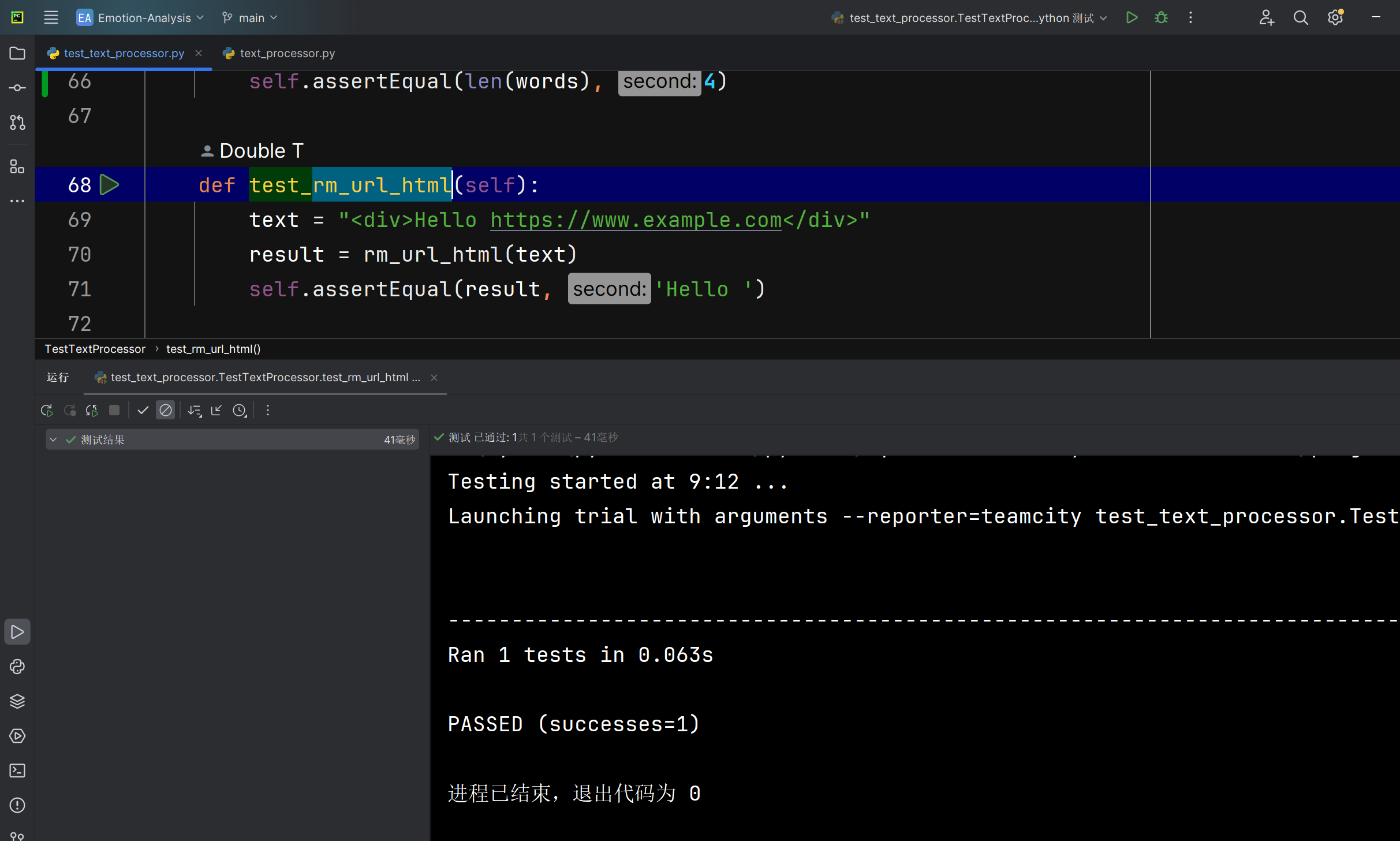 |
清洗标点符号和符号rm_punctuation_symbols函数能否正确将爬取文本中的标点符号和符号数据去除 |
函数运行后返回的文本 | 文本中的标点符号和符号被清洗掉 | T | 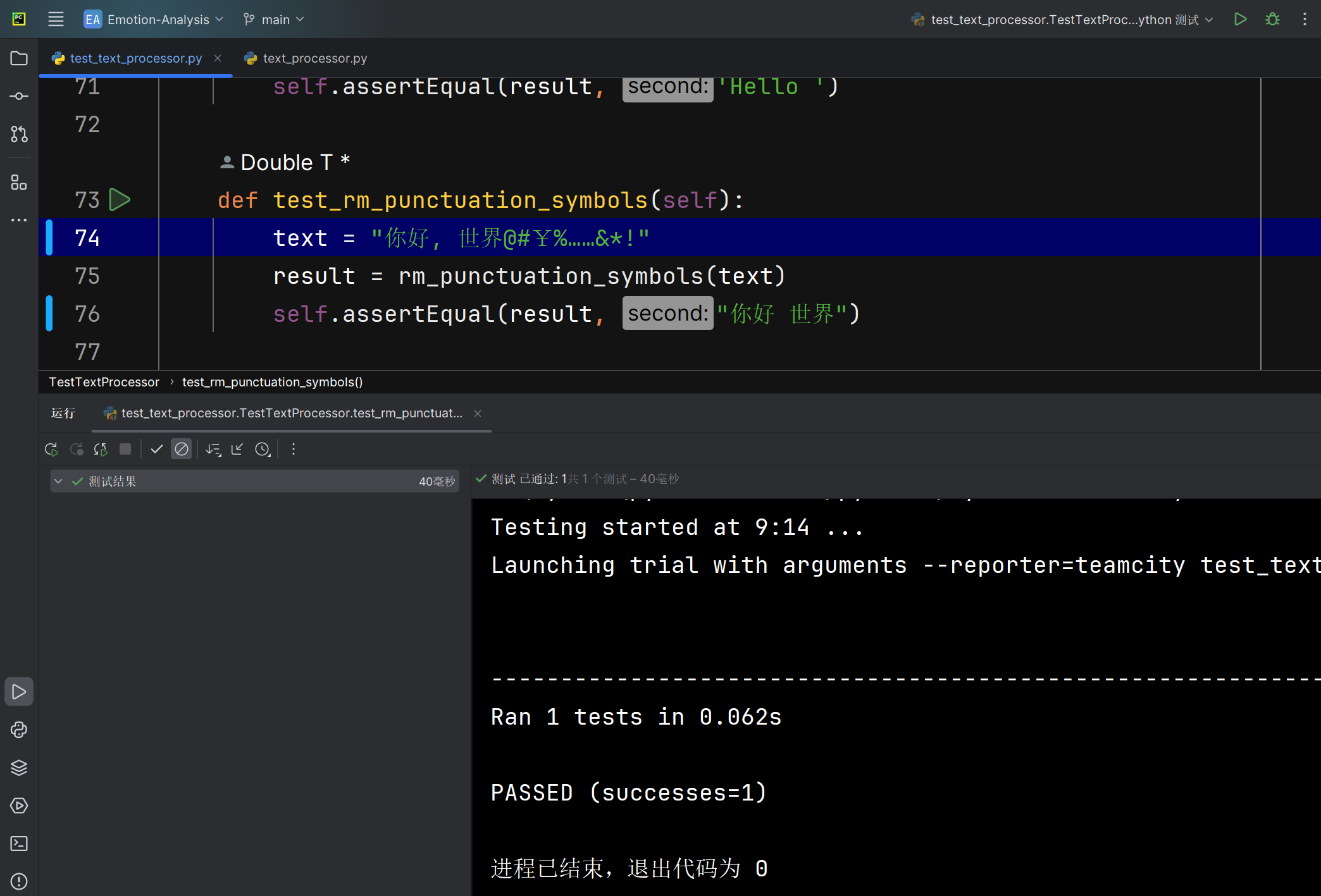 |
清洗多余的空行rm_extra_linebreaks函数能否正确将爬取文本中的多余的空行去除 |
函数运行后返回的文本 | 文本中的多余空行被清洗掉 | T | 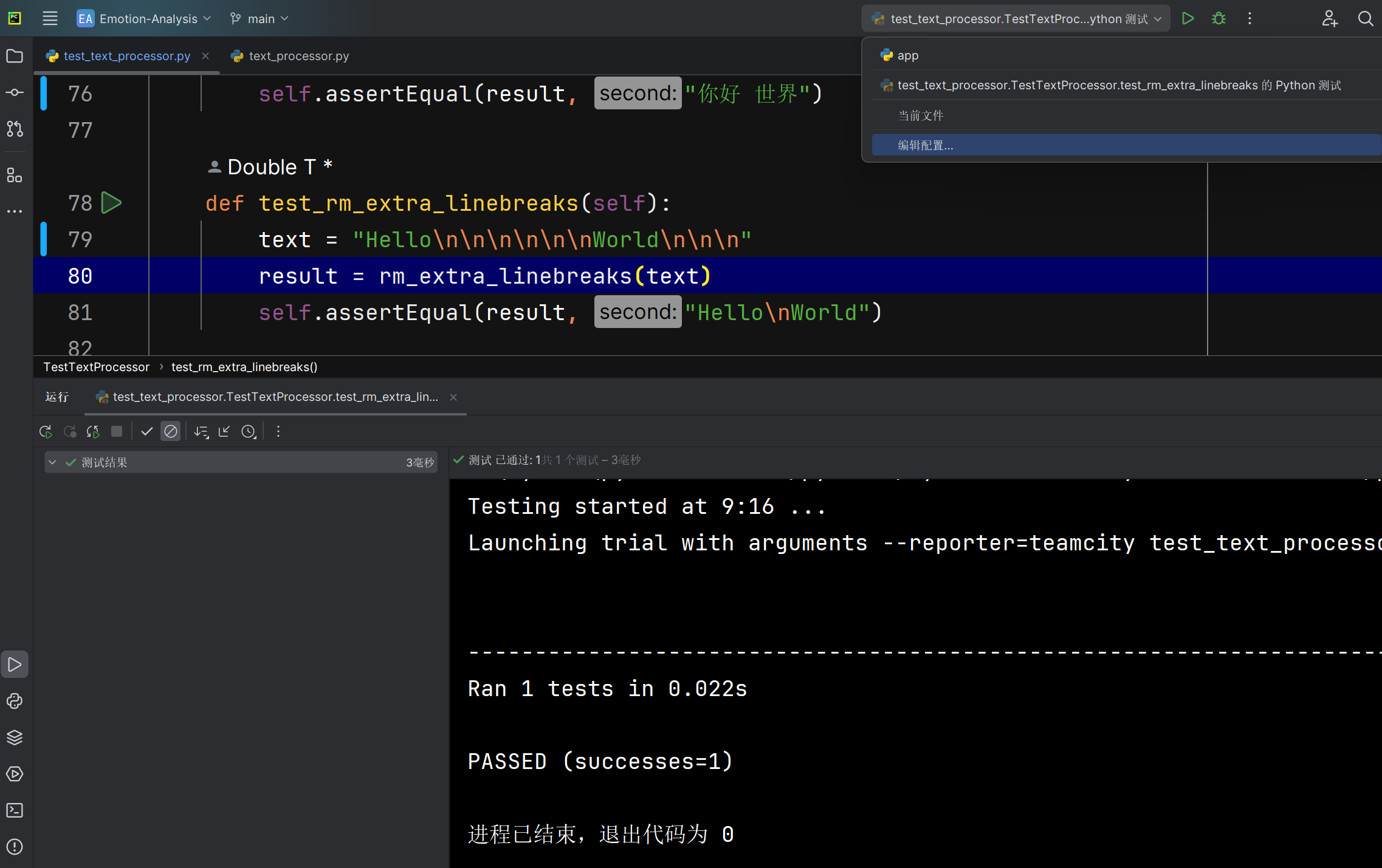 |
清洗微博评论中特有的无意义字符rm_meaningless函数能否正确将爬取文本中的关于微博发布内容中无意义的去除 |
函数运行后返回的文本 | 文本中的无意义字符被清洗掉 | T | 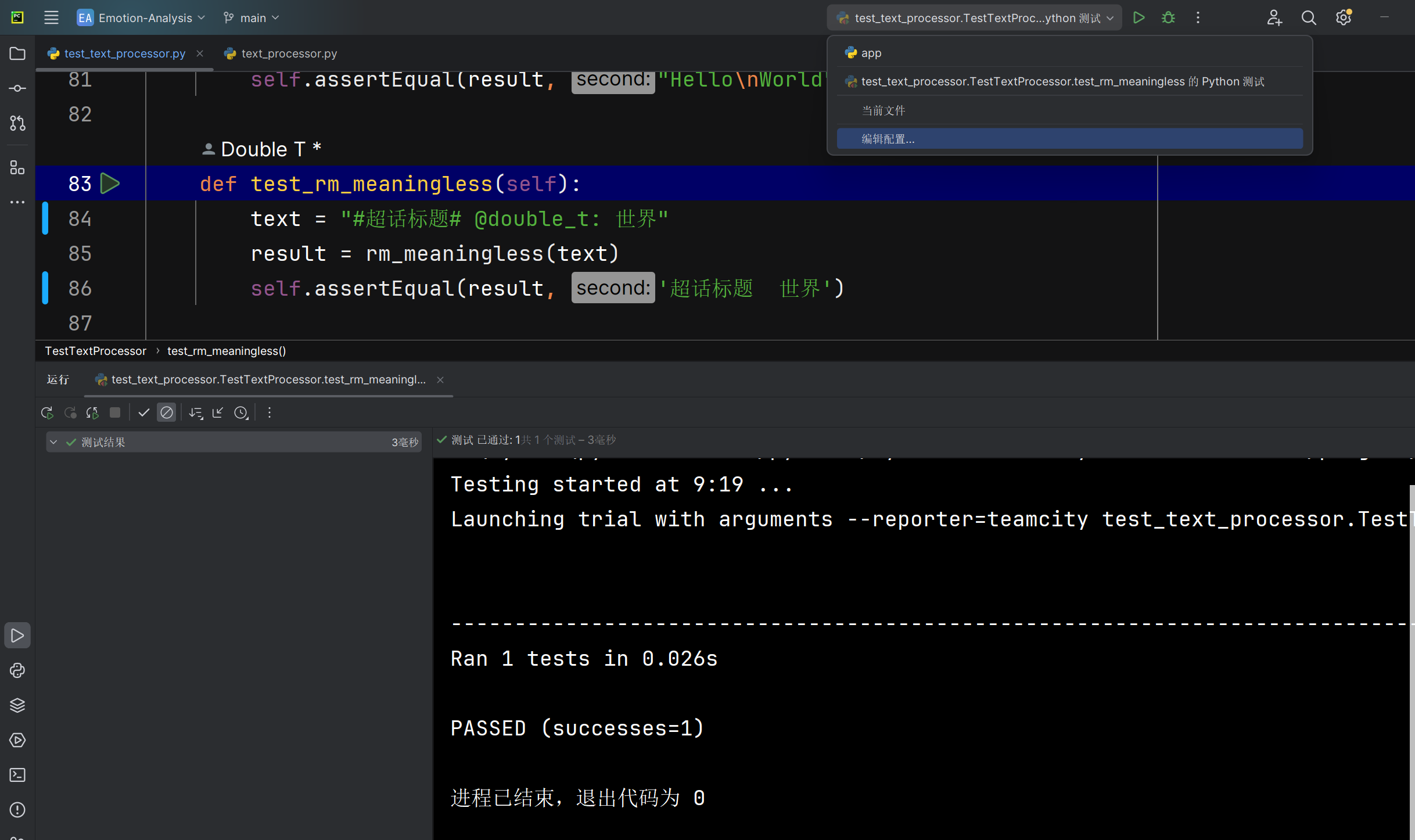 |
清洗英文跟数字rm_english_number函数能否正确将爬取文本中的英文与数据的去除 (备注:英文与数据对于中文文本情感分析无关) |
函数运行后返回的文本 | 文本中的英文和数字被清洗掉 | T | 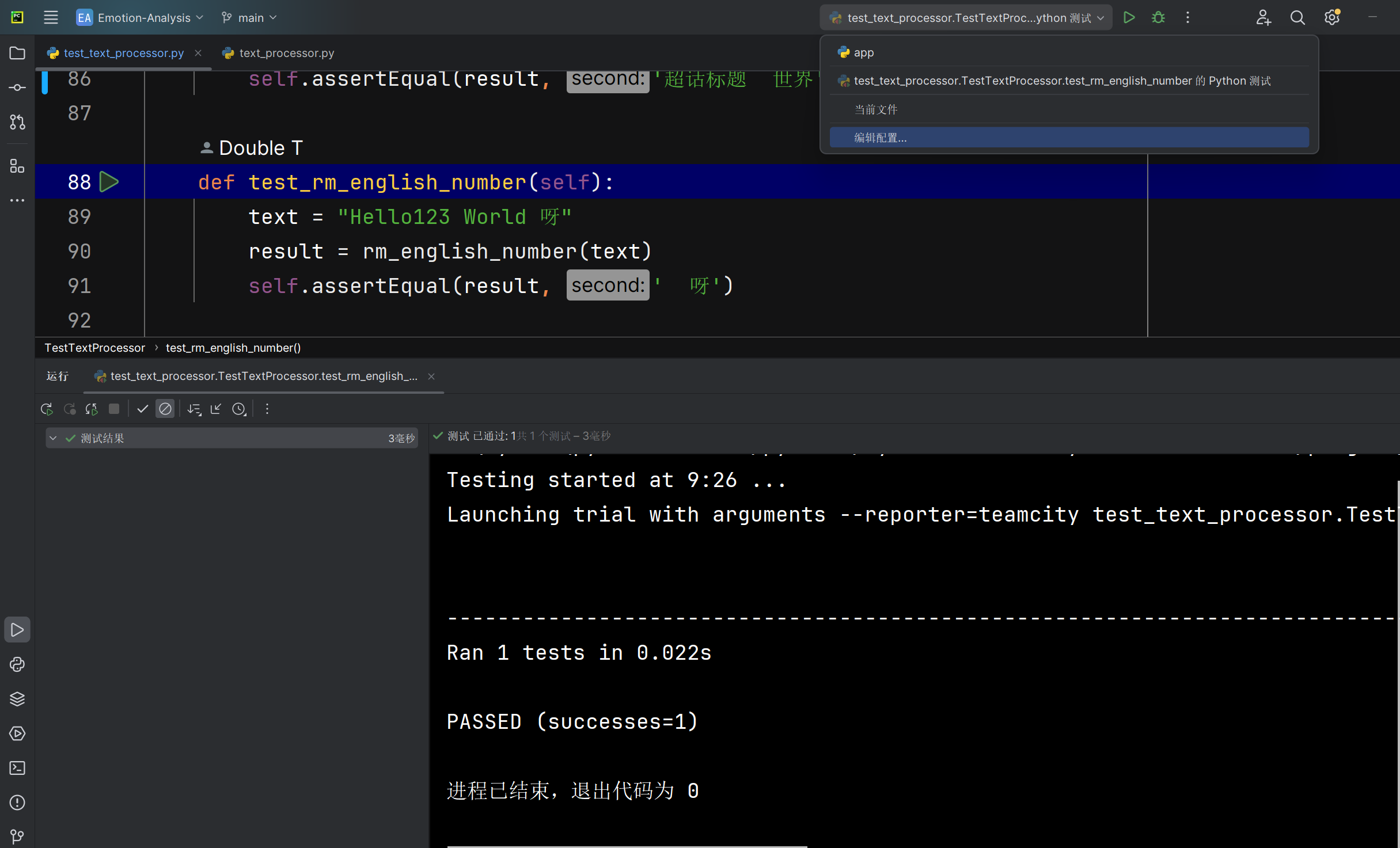 |
清洗为只有中文keep_only_chinese函数能否正确将爬取文本中的中文外其他文本数据的去除 |
函数运行后返回的文本 | 文本中只包含中文字符 | T | 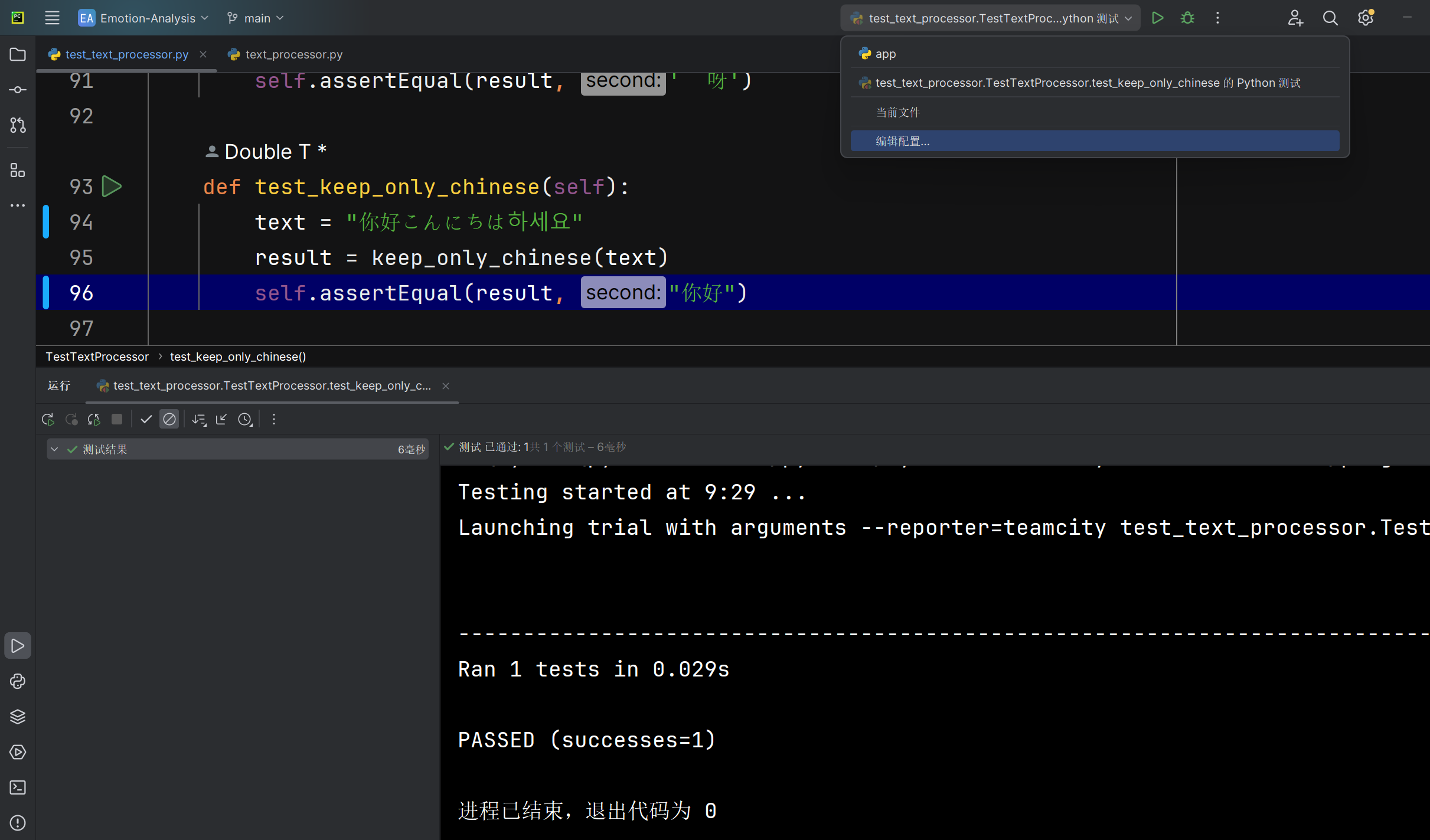 |
移除停用词rm_stopwords函数能否正确将爬取文本中的停用词数据的去除 |
函数运行后返回的词汇列表 | 词汇列表中不包含停用词 | T | 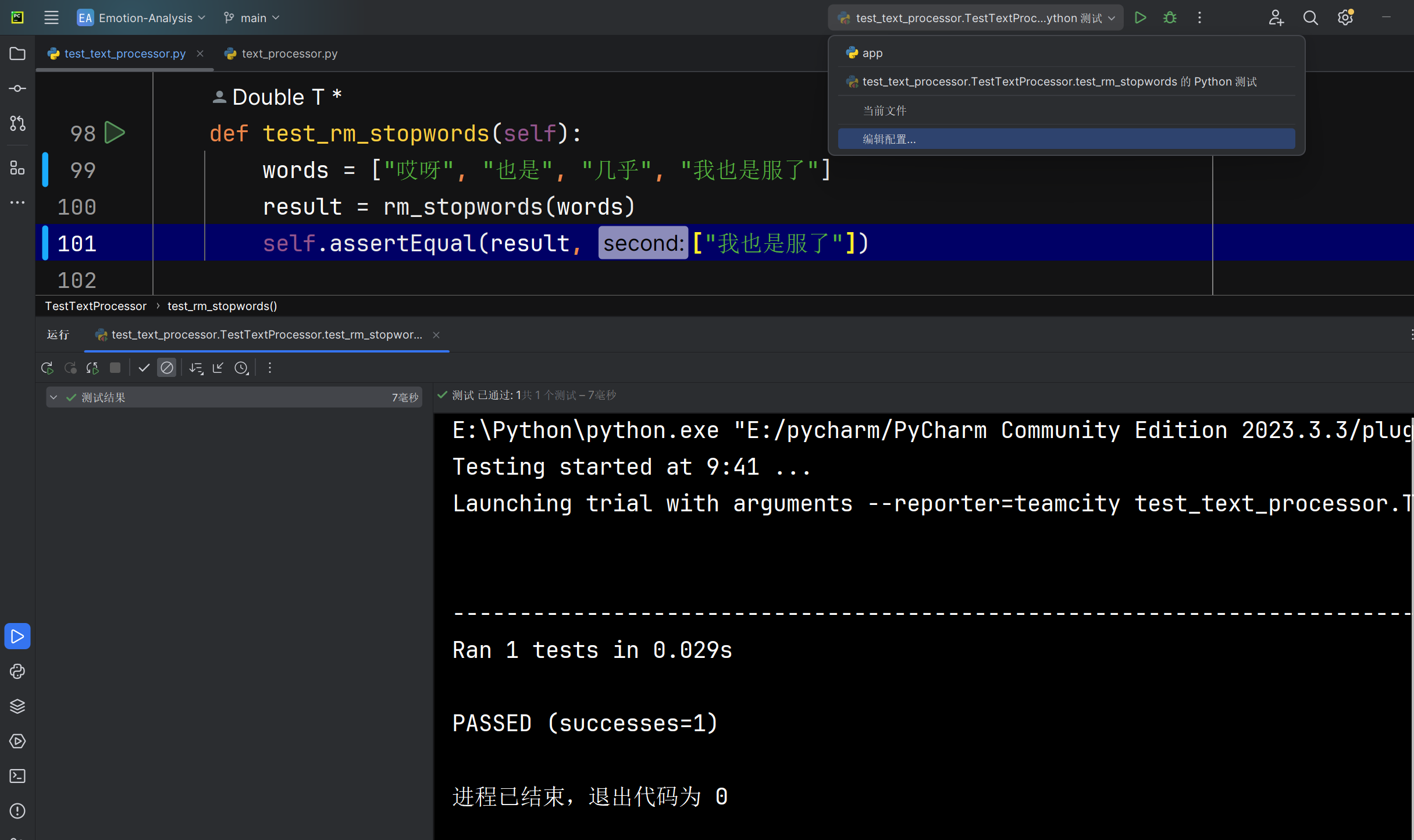 |
清理文本clean函数能否正确将爬取文本中的跟情感分析无关的文本数据去除 |
函数运行后返回的文本 | 文本经过全面清理 | T | 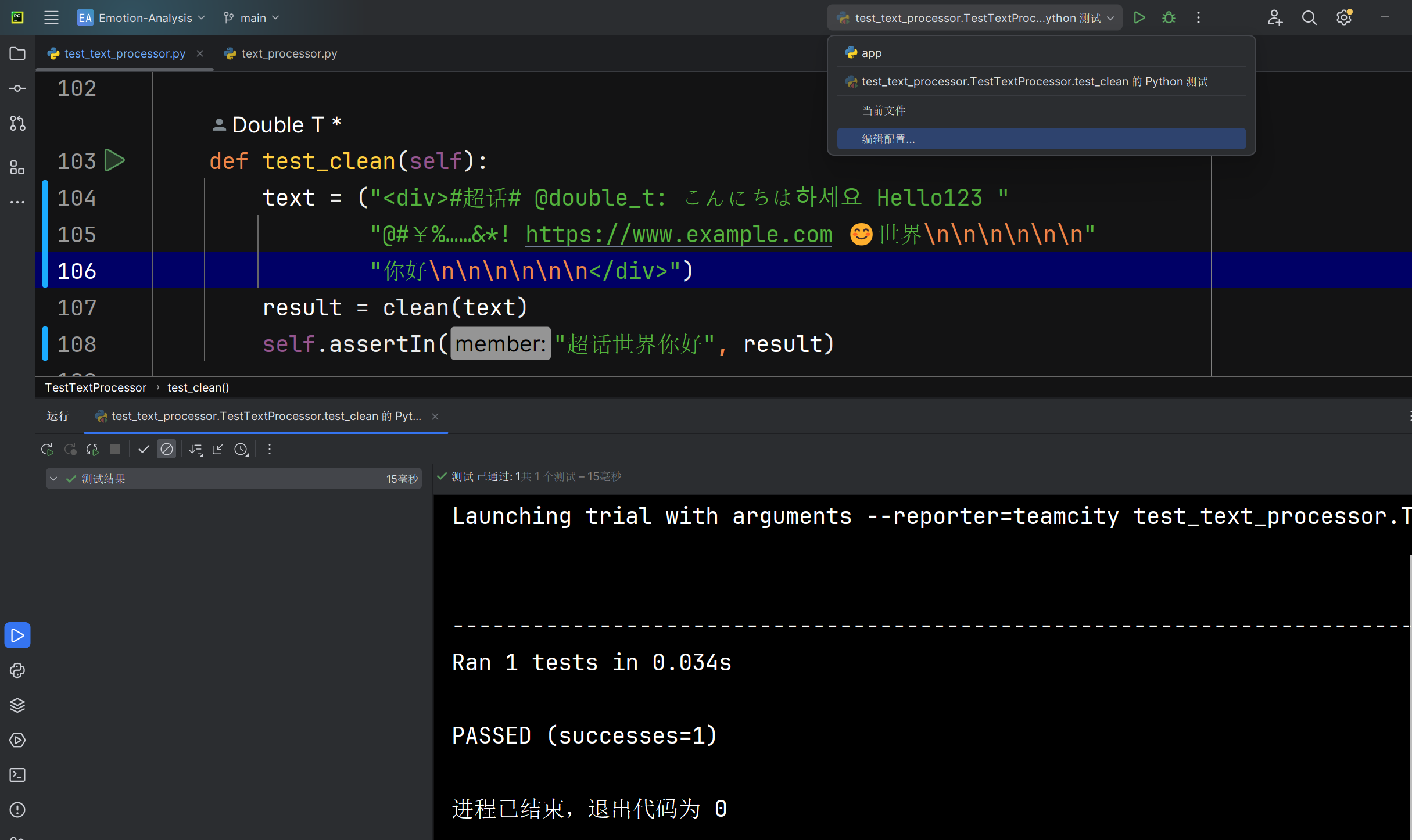 |
文本数据预处理process_data函数能否正确将每条爬取文本进行清洗分词 |
函数运行后返回的数据和词汇列表 | 数据和词汇列表符合预期 | T | 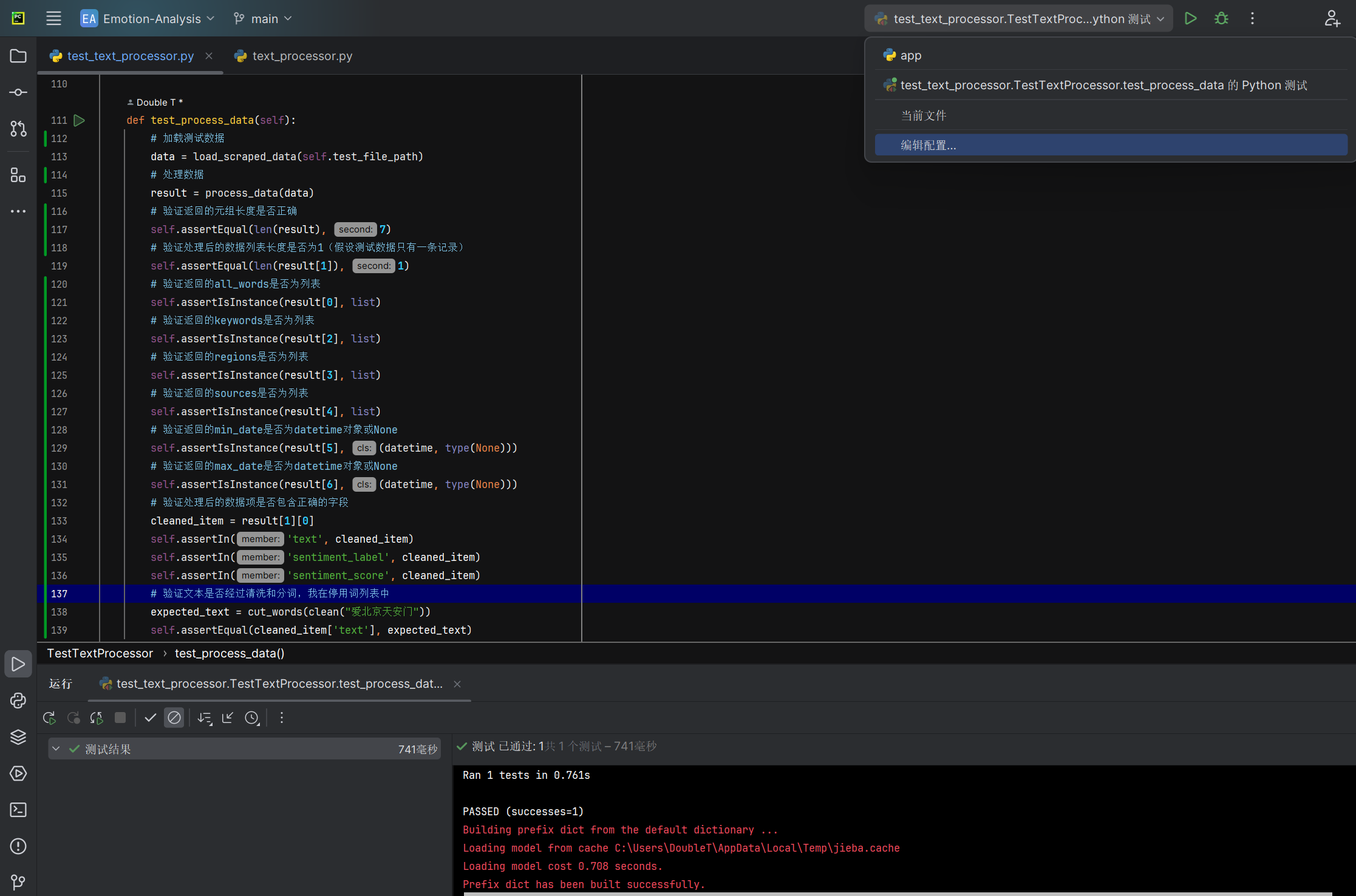 |
存储整体文本数据字典save_to_csv函数能否正确将预处理后的文本数据以字典的形式存储输出文件中 |
函数运行后检查文件系统中的文件 | 文件存在且包含正确的数据 | T | 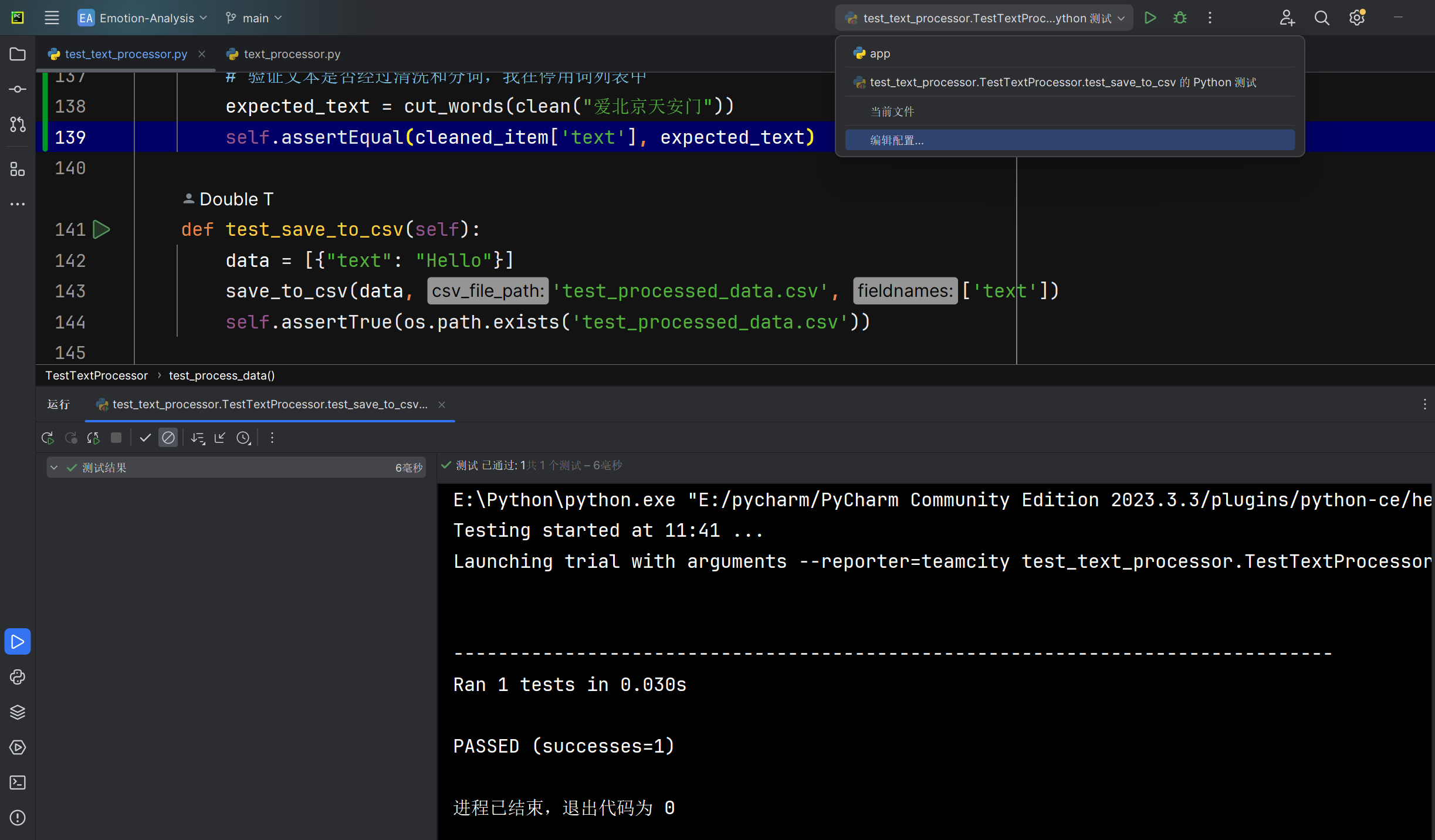 |
存储整体分词后的文本数据save_words_to_csv函数能否正确将分词后的文本数据存储输出文件中 |
函数运行后检查文件系统中的文件 | 文件存在且包含正确的数据 | T |  |
全部文本预处理text_processor函数能否正常存储正确最早和最晚时间到对应文件 |
函数运行后检查文件系统中的文件 | 文件存在且包含正确的最早和最晚的时间字符串 | T | 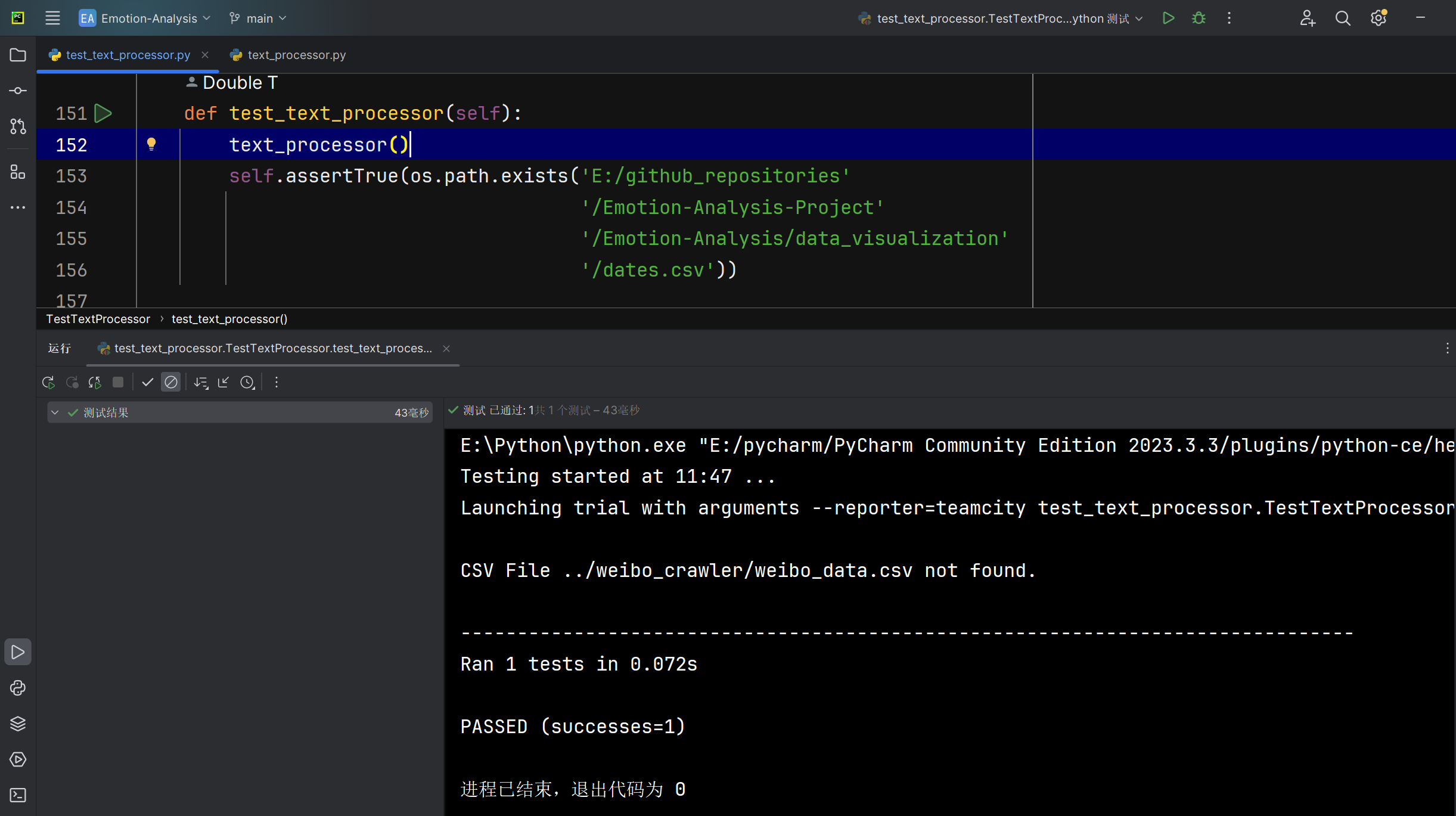 |
1.3.3、情感分析模型模块测试
测试软硬件配置
- 处理器:13th Gen Intel(R) Core(TM) i7-13620H 2.40 GHz
- 机带RAM:16.0 GB (15.8 GB 可用)
- 操作系统:Windows 11
- IDE:PyCharm 2023.3.2 (Professional Edition)
| 测试项 | 检验点 | 预期结果 | Windows 11 + Pycharm | 截图 |
|---|---|---|---|---|
| 测试情感分析模型在不同输入下的预测结果是否合理 | 模型能够正确区分正面和负面情感,并给出合理分数 | 模型预测结果准确,正面和负面情感得分合理 | T |  |
| 验证模型的加载与运行效率 | 模型加载时间较短,运行效率符合需求 | 模型加载迅速,运行效率达到预期标准 | T | 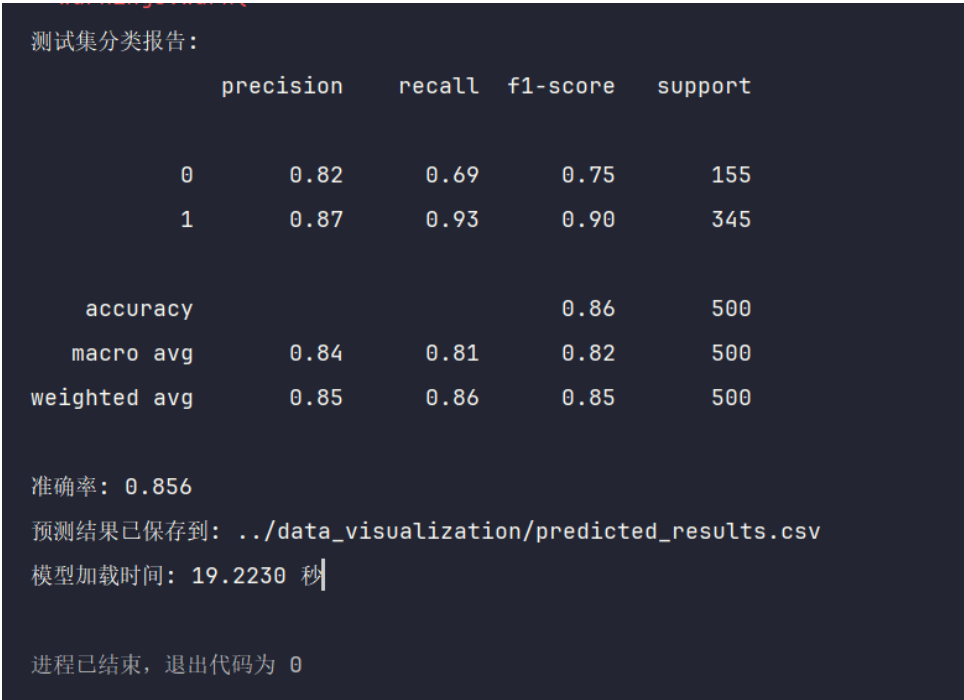 |
1.3.4、数据可视化模块测试
测试软硬件配置
- 处理器:11th Gen Intel(R) Core(TM) i5-11320H @ 3.20GHz 3.19 GHz
- 机带RAM:16.0 GB (15.8 GB 可用)
- 操作系统:Windows 11
- IDE:PyCharm 2023.3.3 (Community Edition)
| 测试项 | 检验点 | 预期结果 | Windows 11 + Pycharm | 截图 |
|---|---|---|---|---|
加载文本数据load_text_data函数能否正确读取CSV文件 |
函数运行后返回的列表数据 | 列表数据与测试文件中所有行的第一列数据相同 | T | 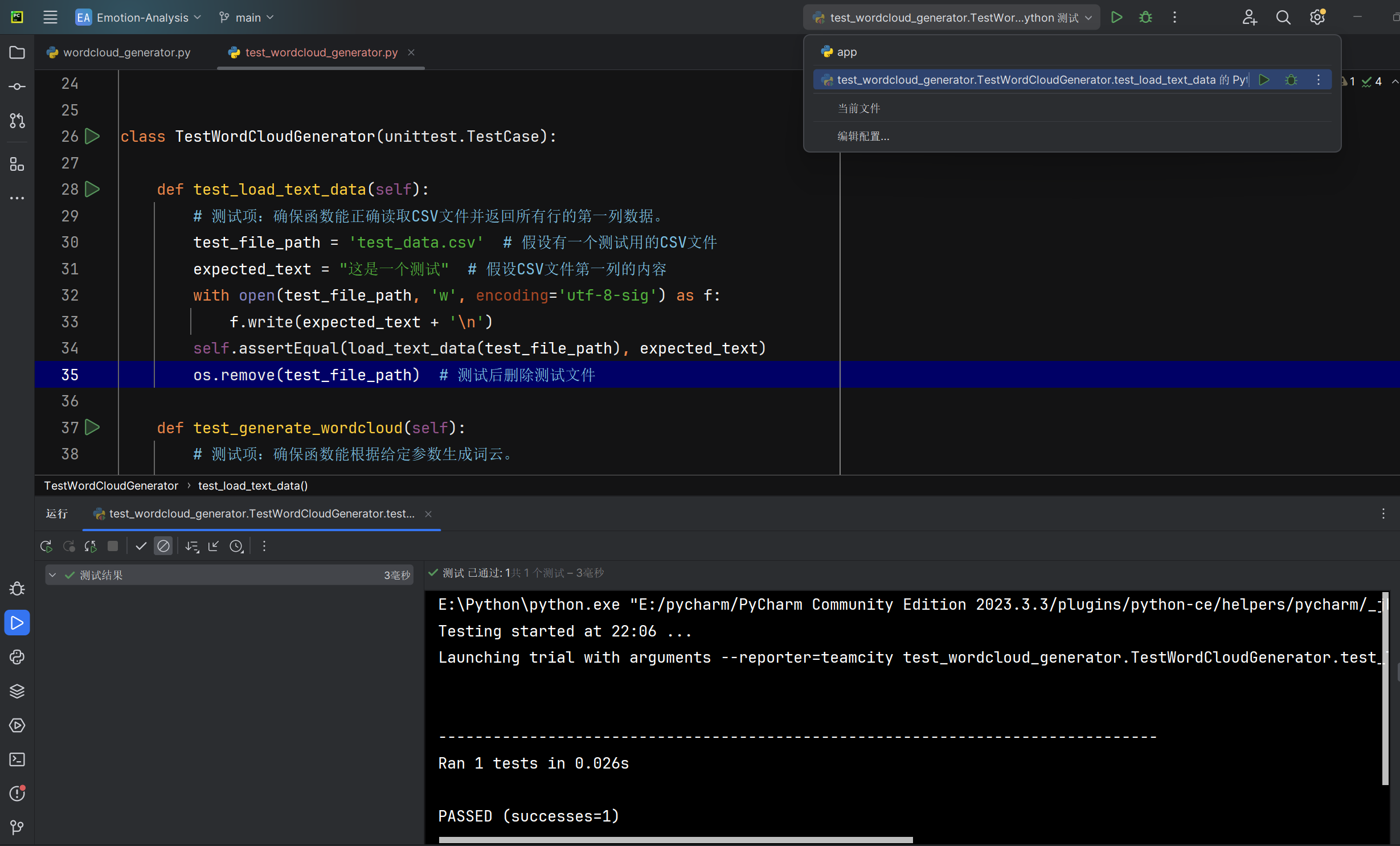 |
生成单个词云generate_wordcloud函数能根据给定参数生成词云 |
函数运行后返回的词云数据 | 词云数据不为空 | T | 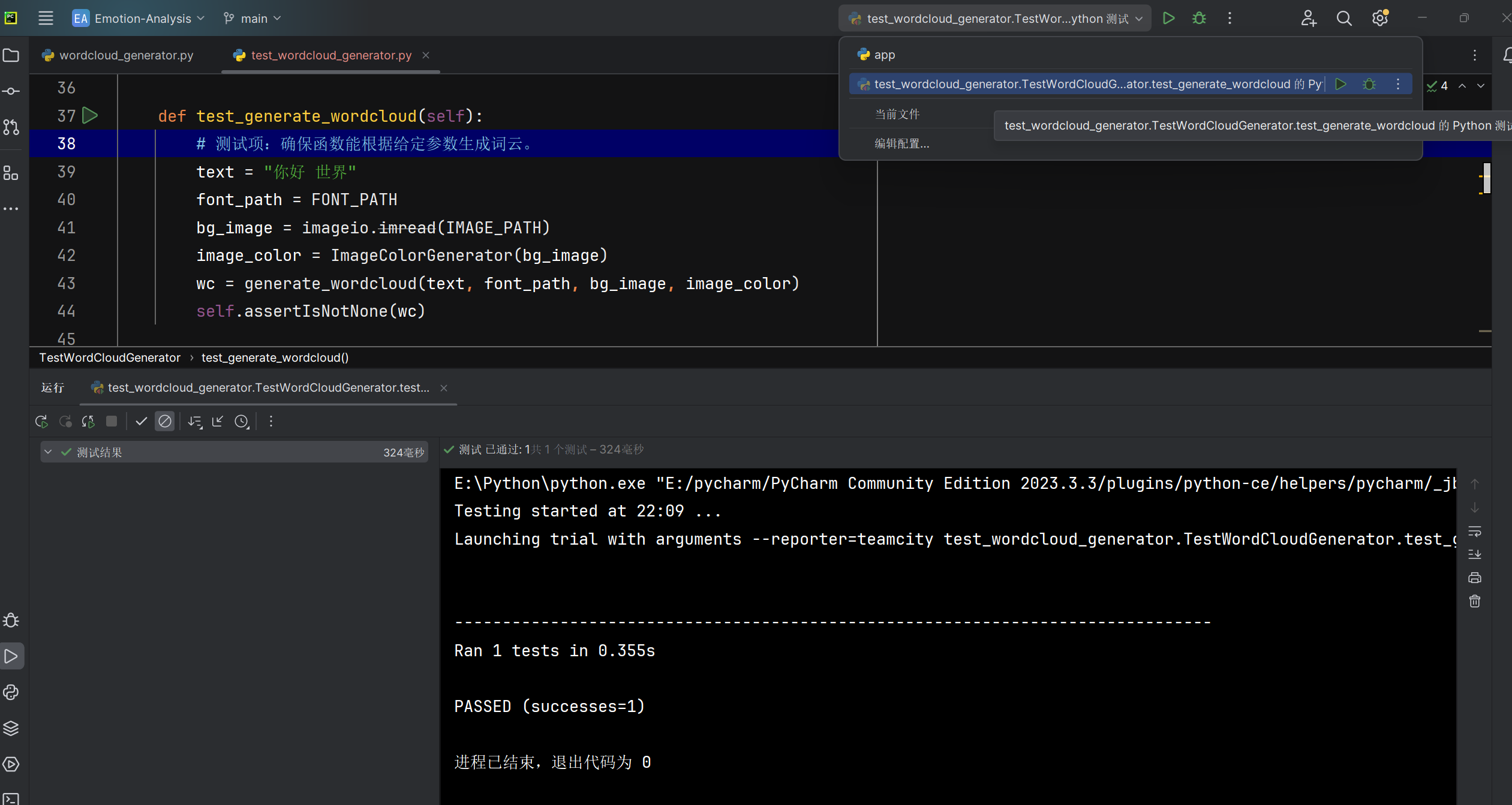 |
保存词云图为图像文件save_wordcloud函数能否正确保存词云图 |
函数运行后检查文件系统中的词云图文件 | 词云图文件存在于指定路径 | T | 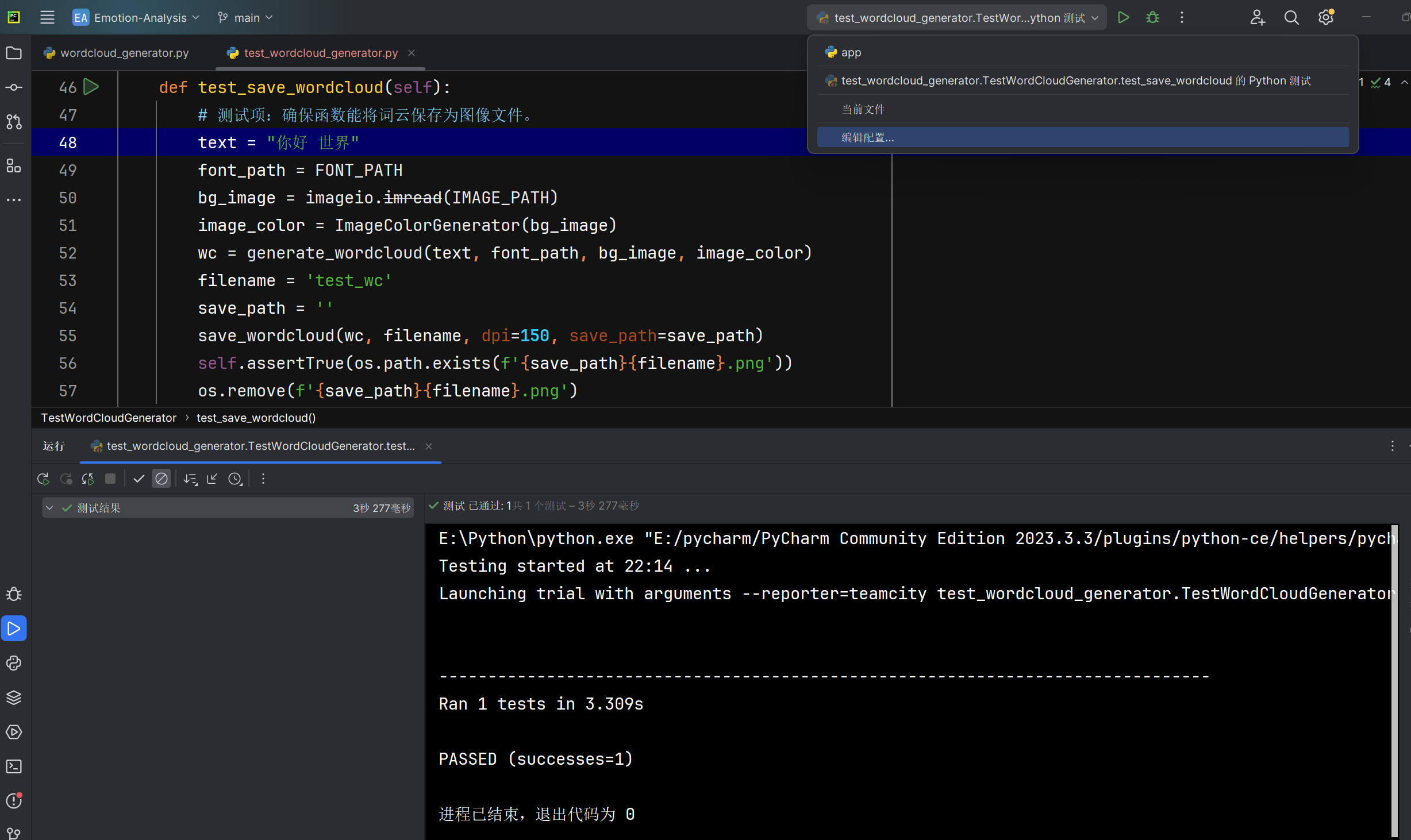 |
美化词云图beautify_images函数能否正确美化词云图 |
函数运行后检查文件系统中美化后的词云图文件 | 美化后的词云图文件存在于指定路径 | T | 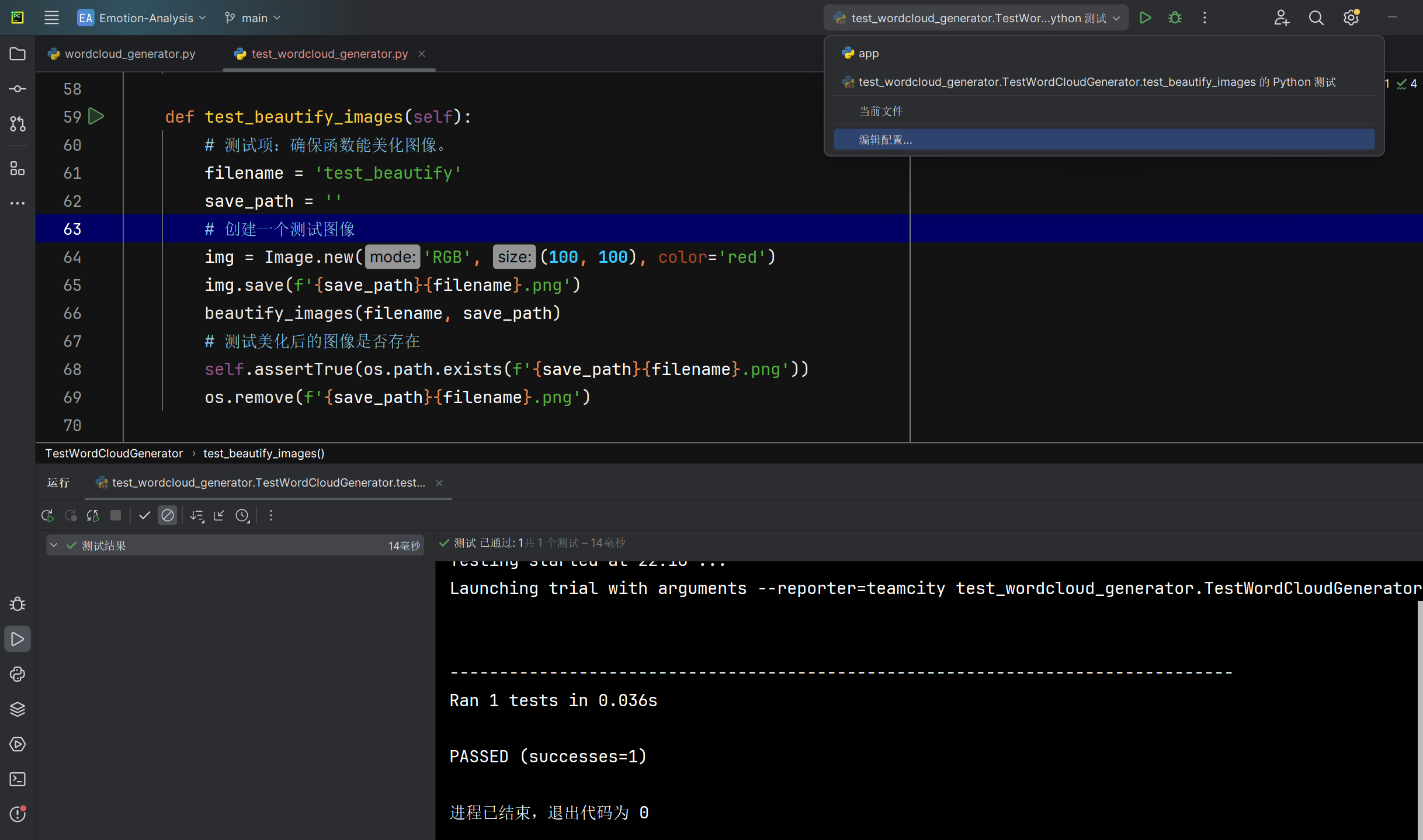 |
保存词云图高频词汇save_top_words函数能否正确保存高频词汇 |
函数运行后检查文件系统中包含高频词汇的文件 | 高频词汇文件存在于指定路径 | T |  |
生成特定情感词云wordcloud_generator函数能否正确生成并保存特定情感词云 |
函数运行后检查文件系统中特定情感的词云图文件 | 特定情感词云图文件存在于指定路径 | T | 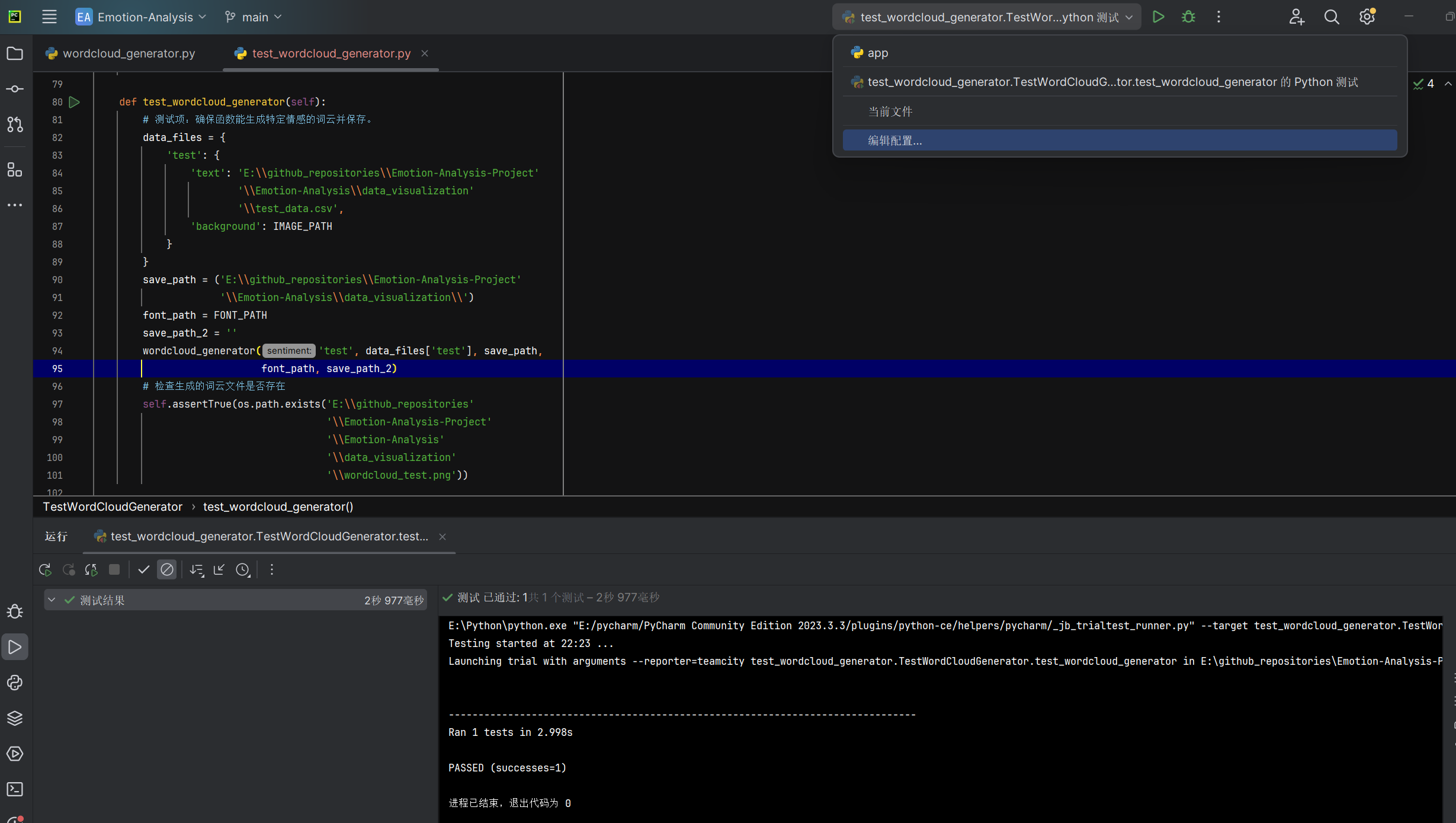 |
生成所有情感词云wordclouds_generator函数能否正确生成并保存所有情感词云 |
函数运行后检查文件系统中存在所有情感的词云图文件(备注:该测试项需要预先生成函数指定的文本数据文件) | 所有情感词云图文件存在于指定路径 | T | 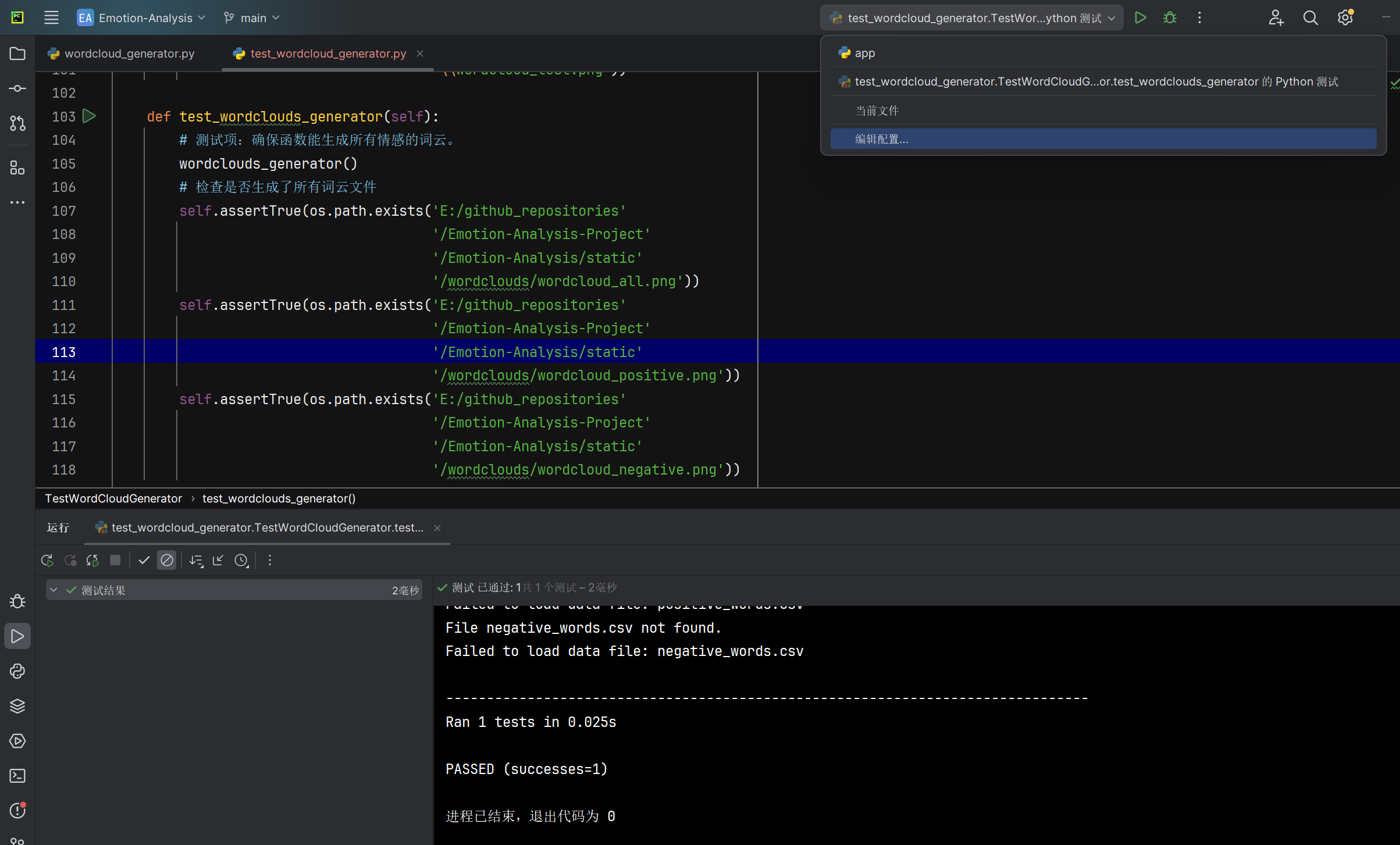 |
情感结果分类classifcation函数能否正确加载预测结果并分类对应情感极性文本 |
函数运行后对比正面和负面情感文本文件的内容与预期结果 | 正面情感文本文件包含正面文本,负面情感文本文件包含负面文本,跳过空文本 | T | 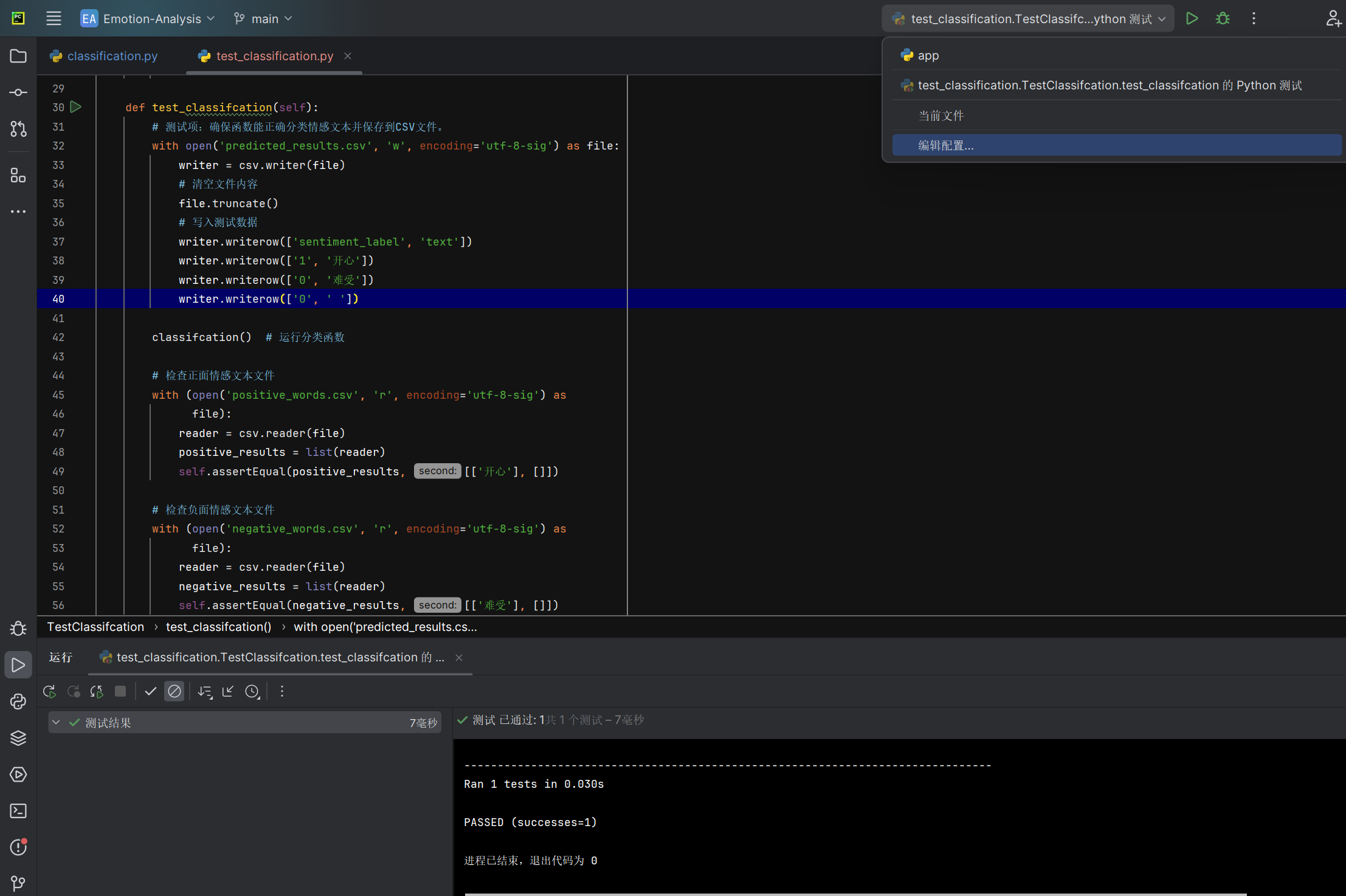 |
饼图生成并保存百分比数据pie_chart_generator函数能否正常生成饼图与存储情感极性分布数据 |
函数运行后检查饼图文件和百分比数据文件是否存在于指定位置(备注:原函数中的存储路径和字体路径在测试时使用了绝对路径) | 饼图文件存在于指定路径,百分比数据文件存在于指定路径且包含正确的情感和百分比数据 | T | 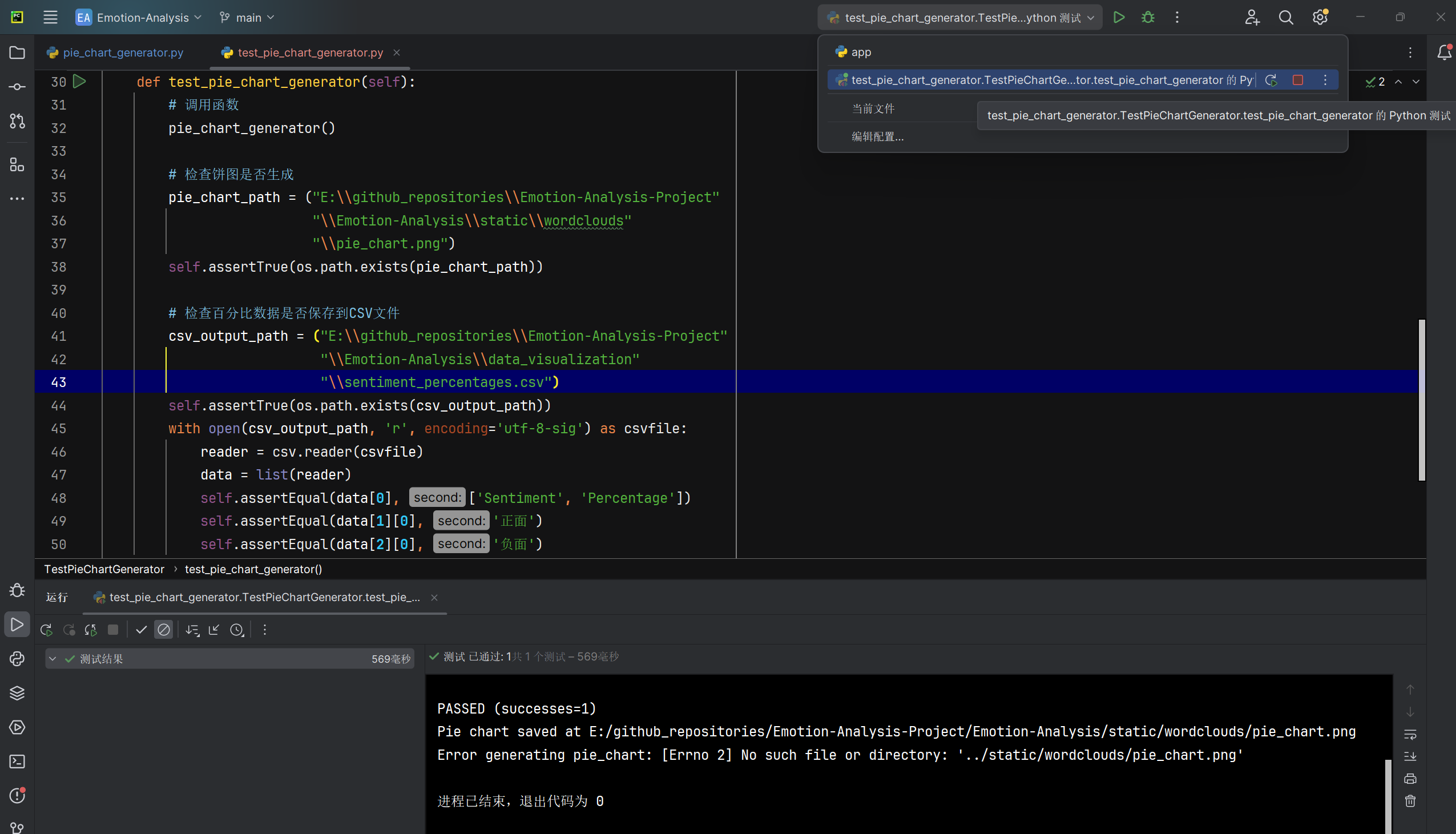 |
1.3.5、用户交互模块测试
测试软硬件配置
- 处理器:12th Gen Intel(R) Core(TM) i9-12900H 2.50 GHz
- 机带RAM:16.0 GB (15.7 GB 可用)
- 操作系统:Windows 11
- IDE:PyCharm 2024.1.1(Professional Edition)
| 测试项 | 检验点 | 预期结果 | Windows 11 + Pycharm + edge浏览器 | 截图 |
|---|---|---|---|---|
| 输入错误格式关键词 | 输入界面中的关键词输入框 | 在输入框之下提示关键词输入格式错误 | T |  |
| 输入错误格式关键词 | 输入界面中的关键词输入框 | 在输入框之下提示关键词输入格式错误 | T | |
| 输入错误格式的微博内容地区 | 输入界面中的微博内容地区输入框 | 在输入框之下提示微博内容地区输入格式错误 | T |  |
| 选择的起始日期晚于截止日期 | 输入界面中的时间选择 | 在时间选择之下提示起始日期晚于截止日期 | T | 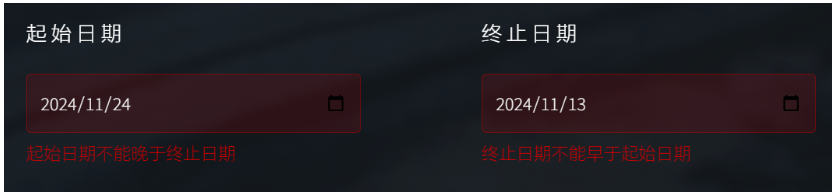 |
| 要求填写的输入未全部完成 | 输入界面中的提交按钮 | 提交按钮保持熄灭状态 | T | 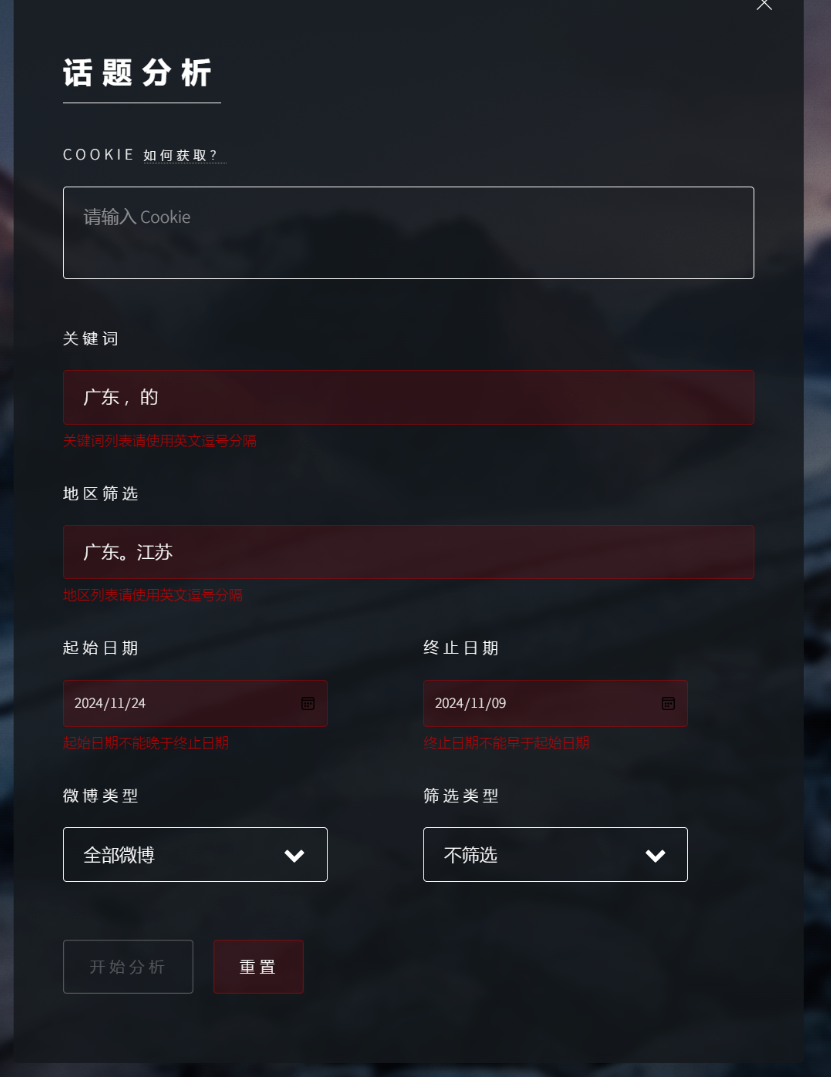 |
1.3.6、建议模块测试
测试软硬件配置
- 处理器:11th Gen Intel(R) Core(TM) i5-11320H @ 3.20GHz 3.19 GHz
- 内存:16.0 GB (15.8 GB 可用)
- 操作系统:Windows 11
- IDE:PyCharm 2023.3.3 (Community Edition)
| 测试项 | 检验点 | 预期结果 | Windows 11 + Pycharm | 截图 |
|---|---|---|---|---|
当sources文件内容不足20行时,读取文本文件read_text_file函数能否正确返回全部文件内容 |
返回的文本内容 | 与测试sources文件内容相同 |
T | 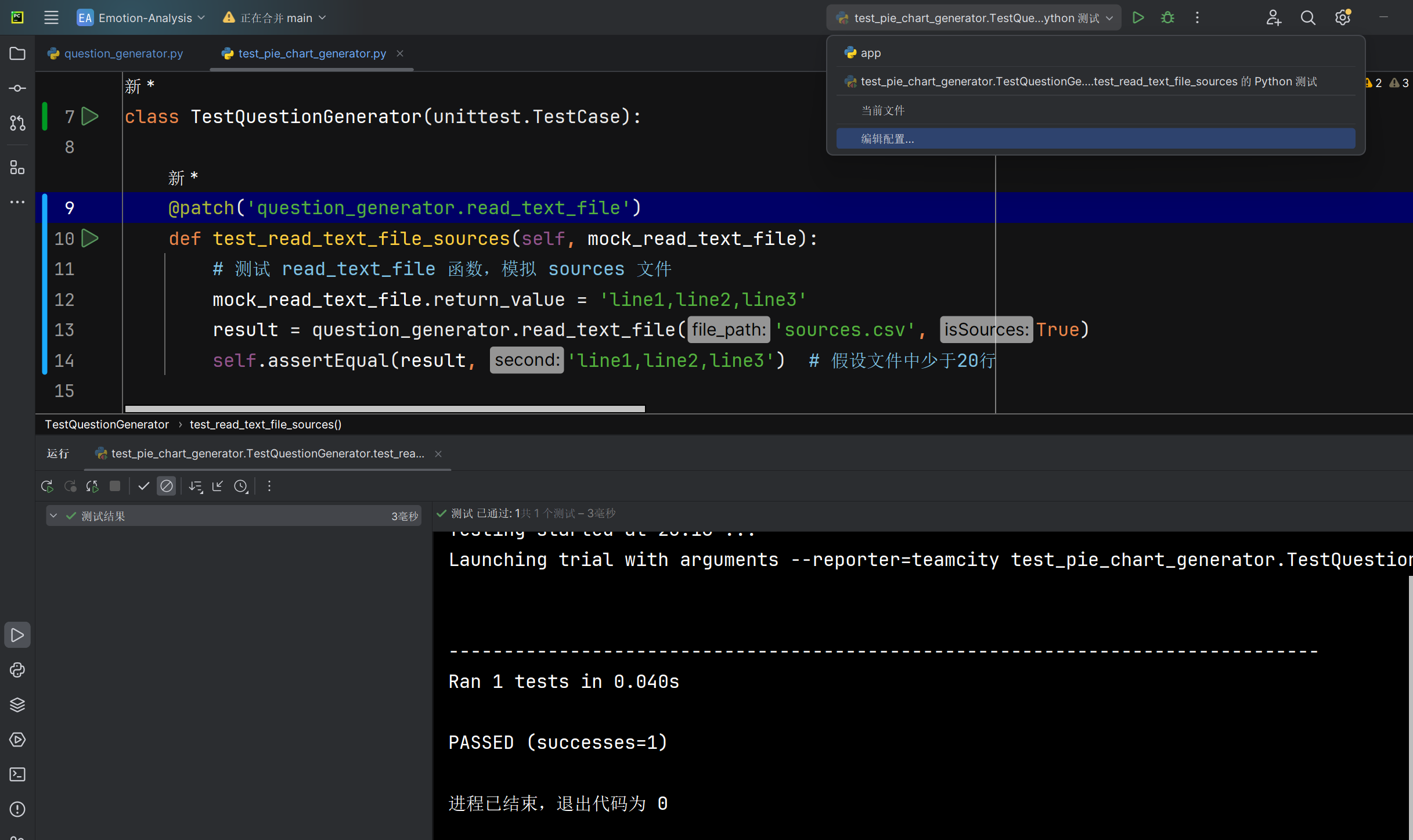 |
当sources文件内容大于20行时,读取文本文件read_text_file函数能否正确返回前20行文件内容 |
返回的文本内容 | 与测试sources文件前20行内容相同 |
T | 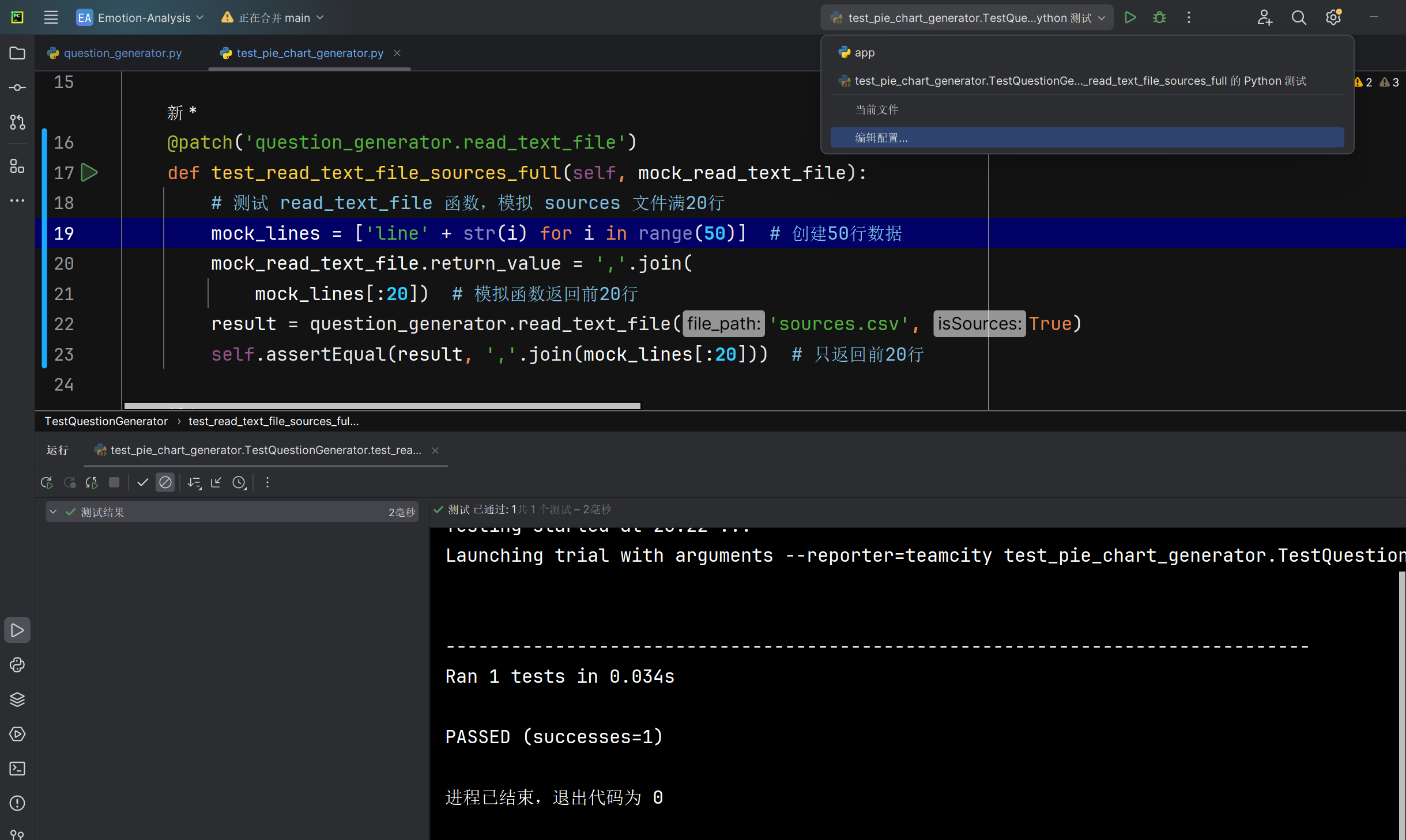 |
当读取文本文件read_text_file函数读取sources文件时,能否正确返回全部文件内容 |
返回的文本内容 | 与测试的非sources文件内容相同 |
T | 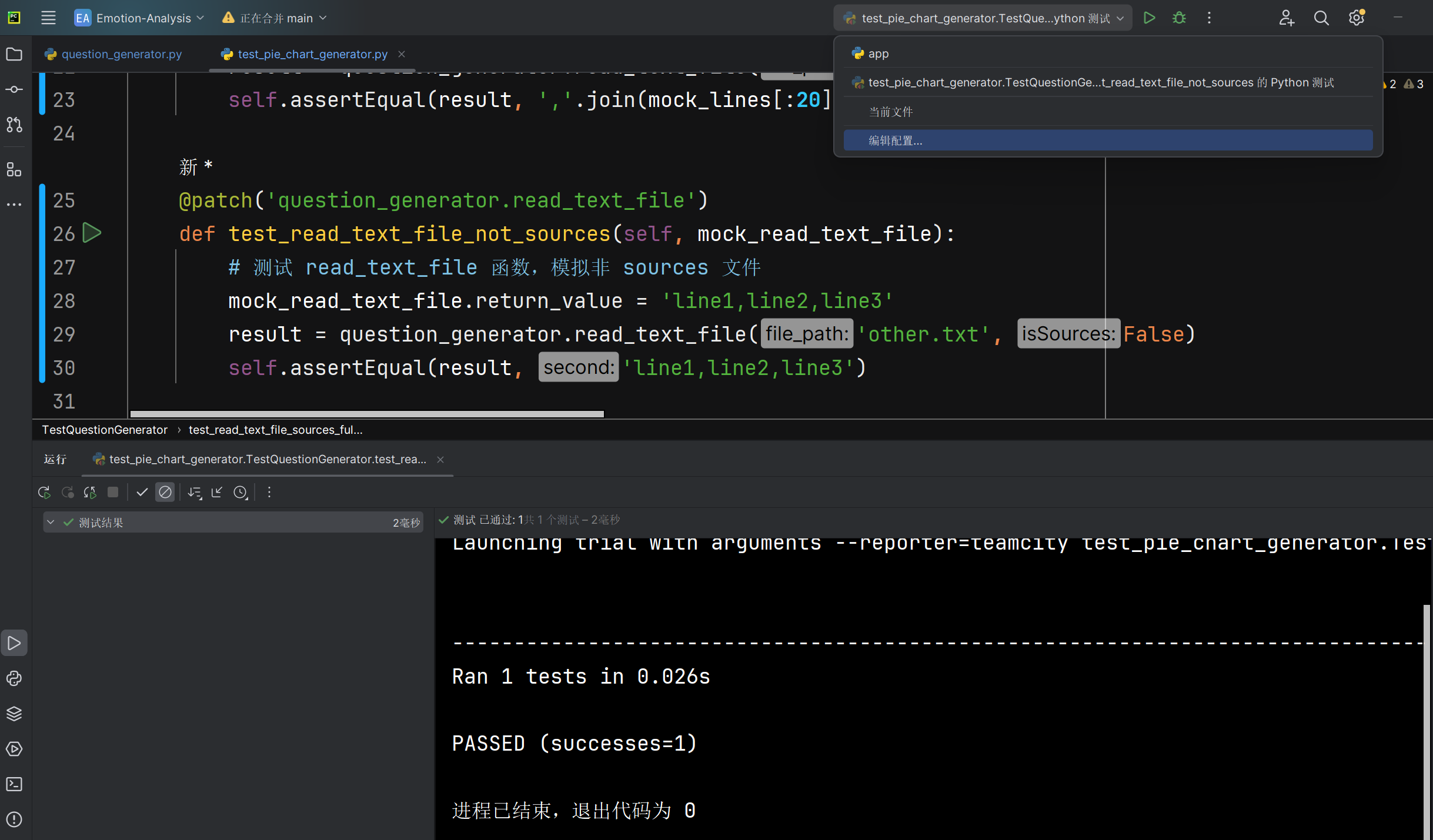 |
单行文本文件read_text_file函数能否正确返回文件内容 |
返回的文本内容 | 与测试单行文本内容相同 | T | 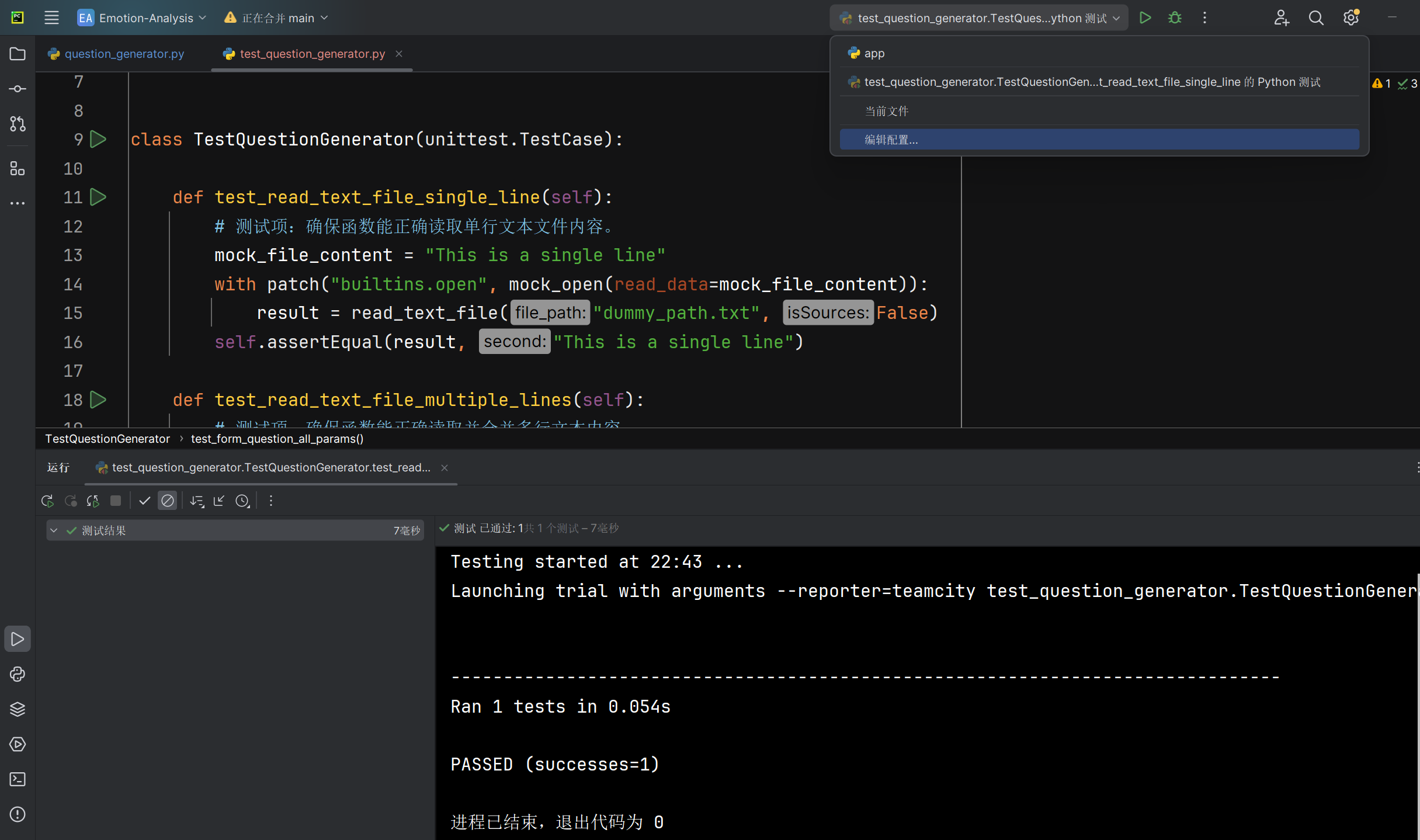 |
多行文本文件read_text_file函数能否正确返回合并后的文件内容 |
返回的文本内容 | 与测试多行文本内容相同,以逗号分隔 | T | 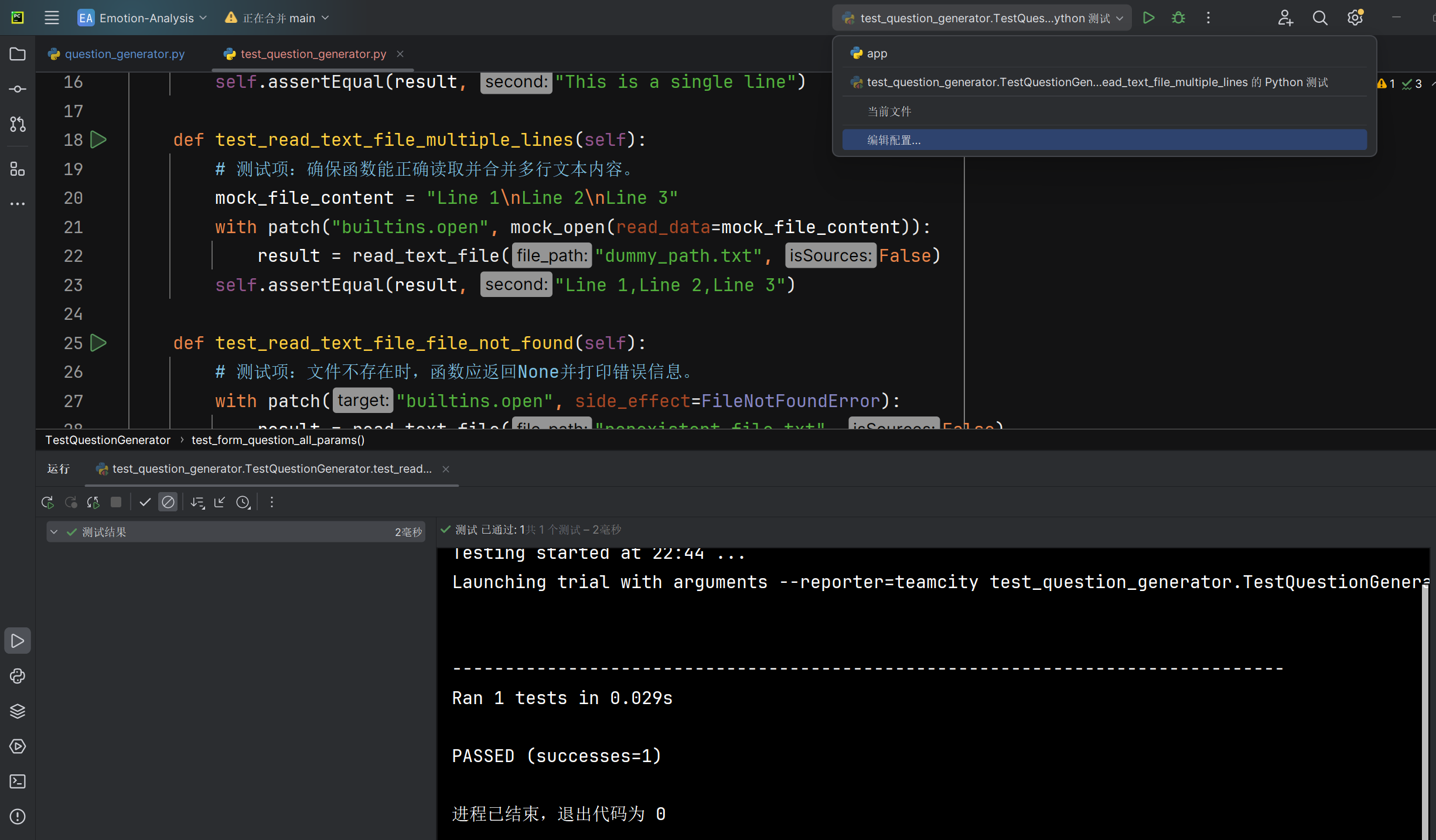 |
文件不存在时read_text_file函数能否正确处理 |
函数返回值 | 返回None | T | 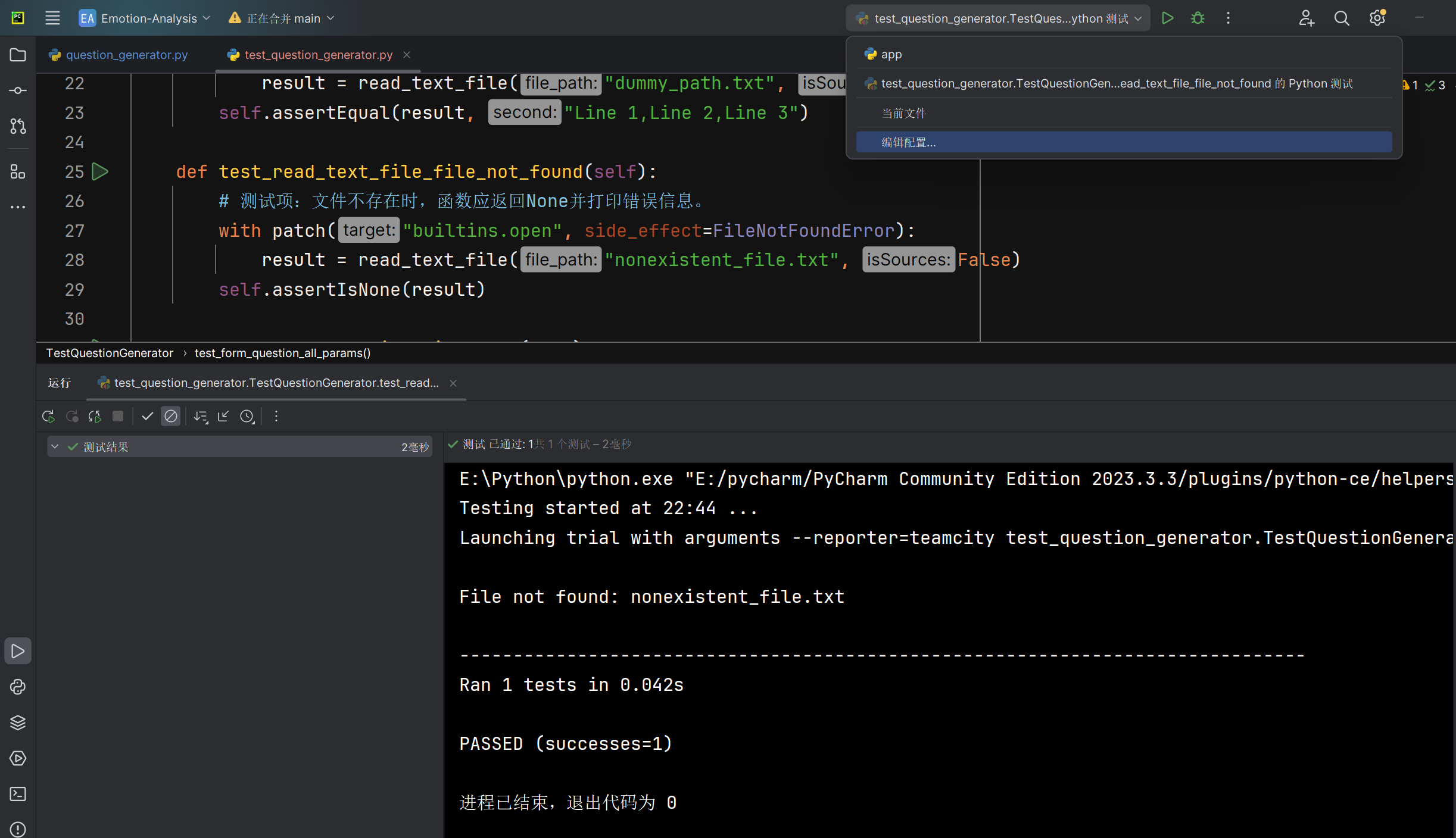 |
CSV文件read_csv_file函数能否正确解析为字典 |
返回的字典内容 | 与测试CSV文件内容相同 | T | 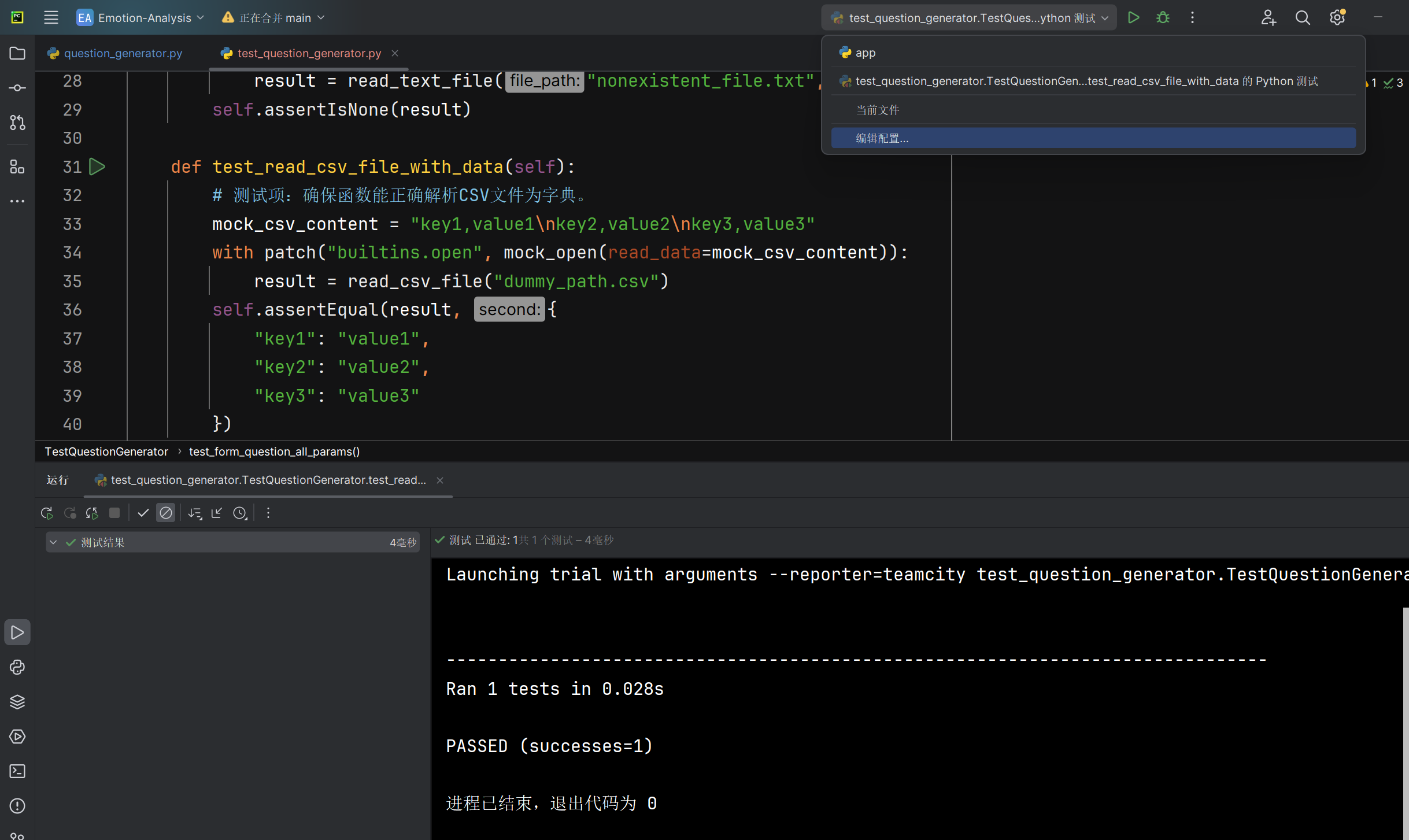 |
空CSV文件read_csv_file函数能否返回空字典 |
返回的字典内容 | 空字典 | T | 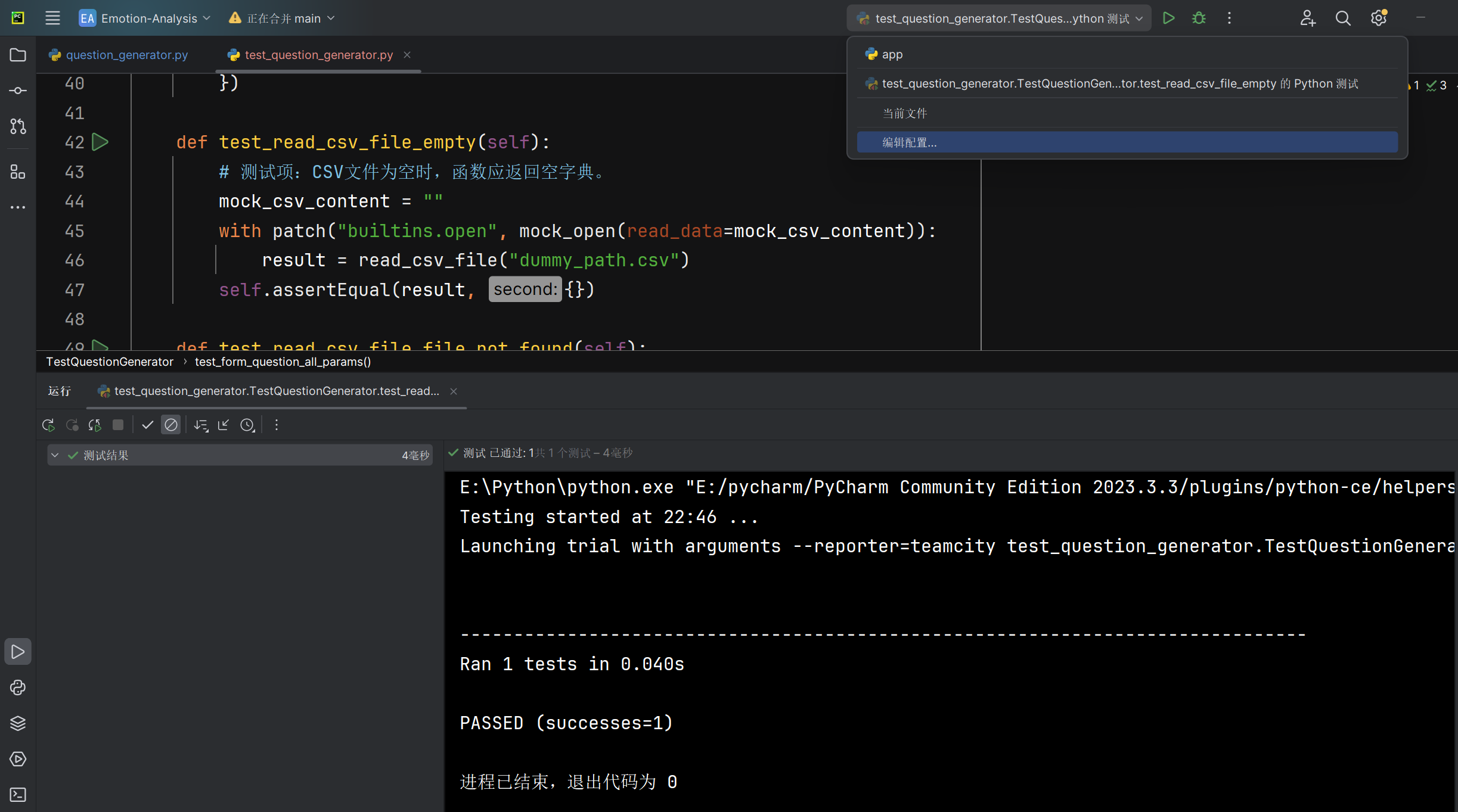 |
文件不存在时read_csv_file函数能否正确处理 |
函数返回值 | 返回空字典 | T | 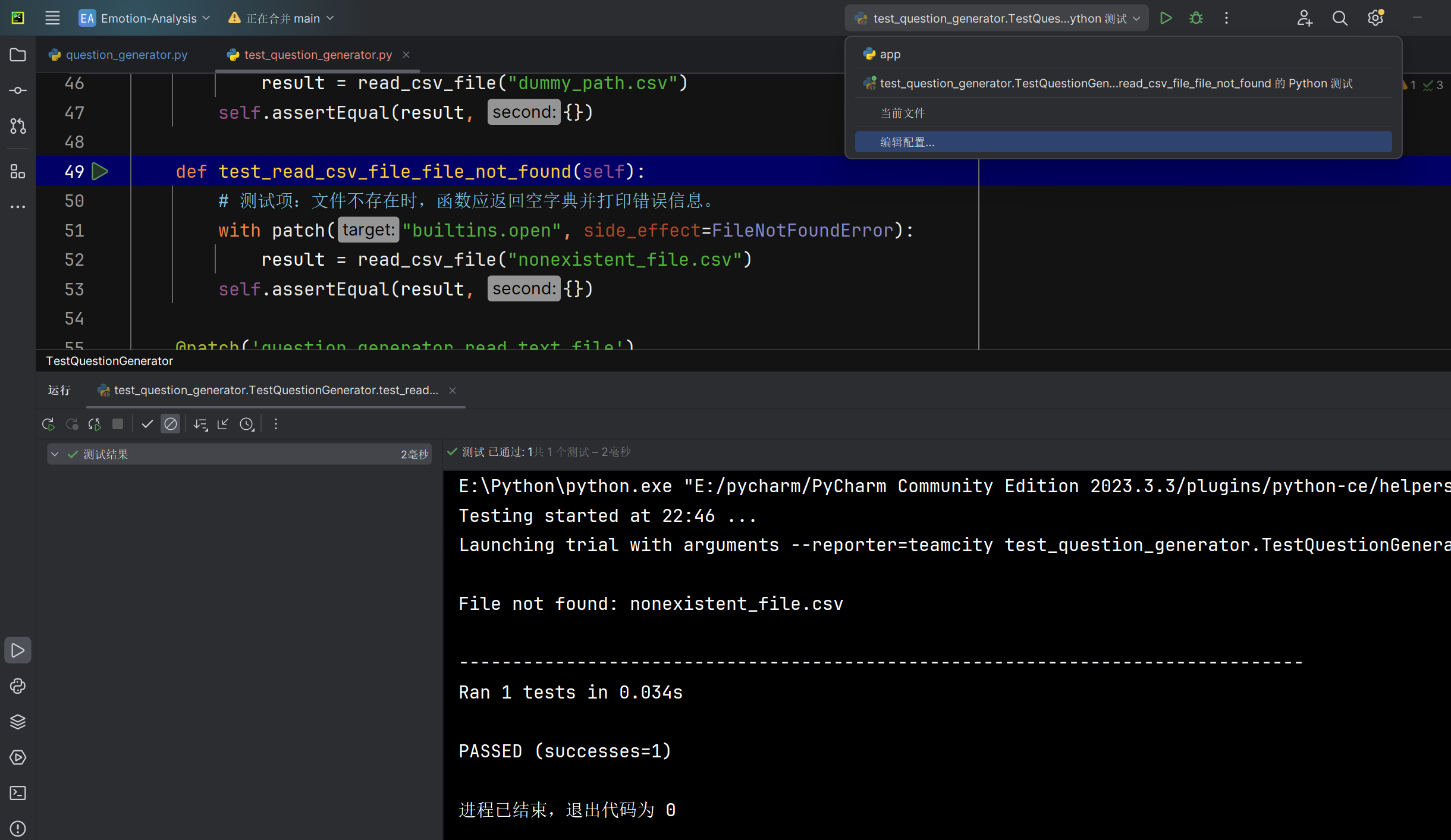 |
加载分析结果参数load_params函数能否正确加载生成字符串类型的与分析结果相关的参数 |
返回的参数值 | 与预期的参数值相同 | T | 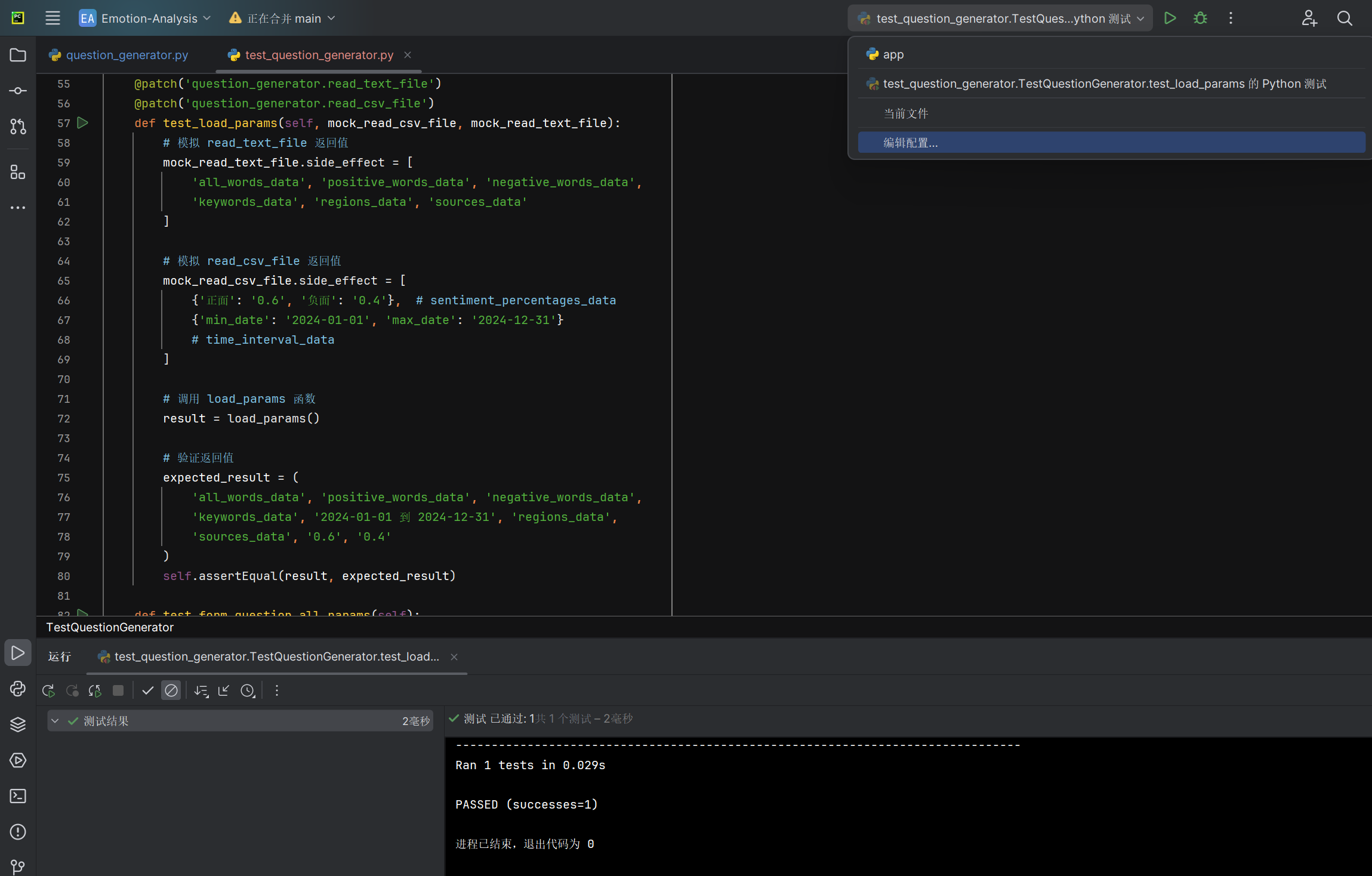 |
所有参数均有值时form_question函数能否生成完整的问题描述 |
生成的问题描述 | 包含所有参数值 | T | 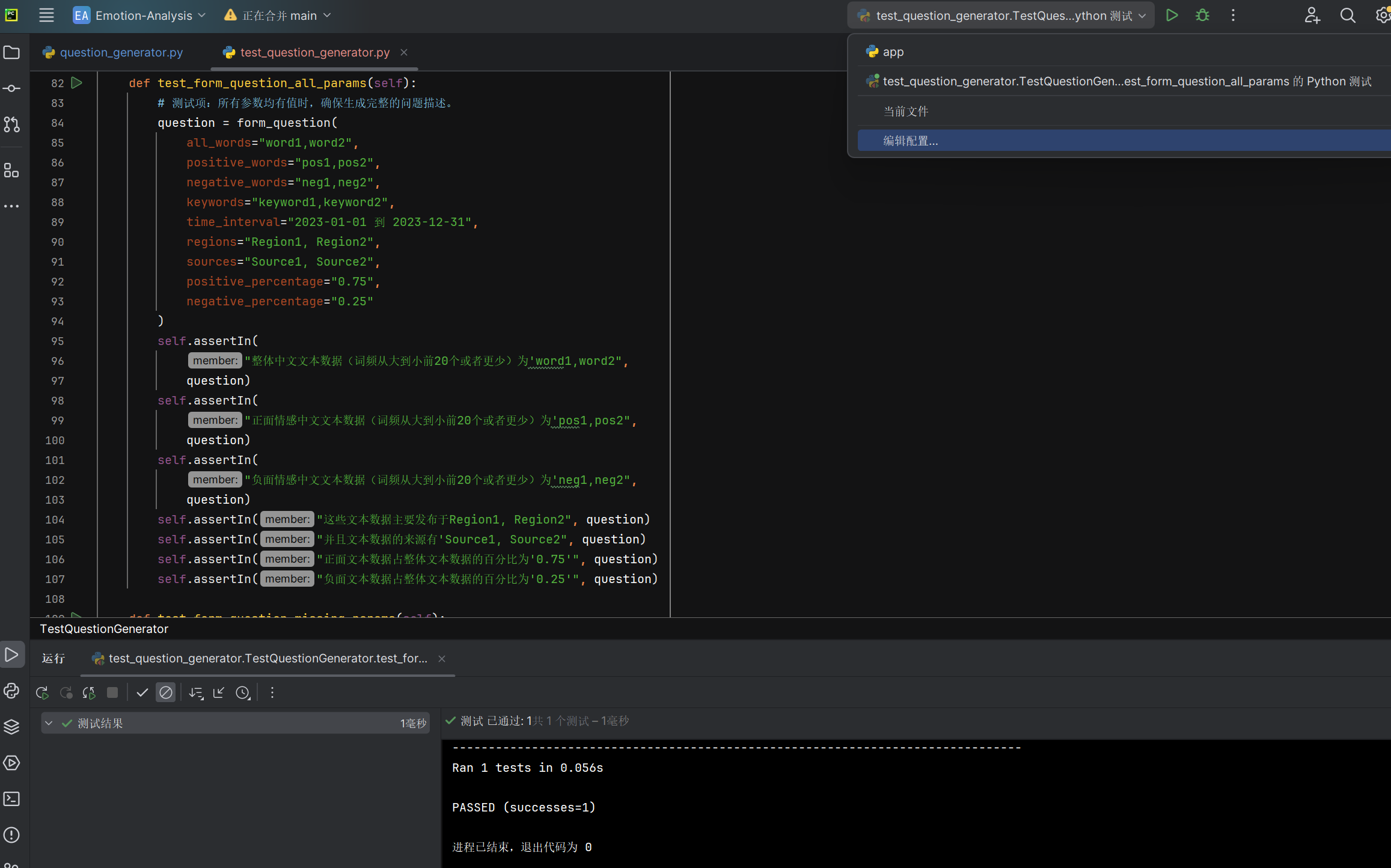 |
部分参数缺失时form_question函数能否使用默认文本填充 |
生成的问题描述 | 包含默认文本 | T | 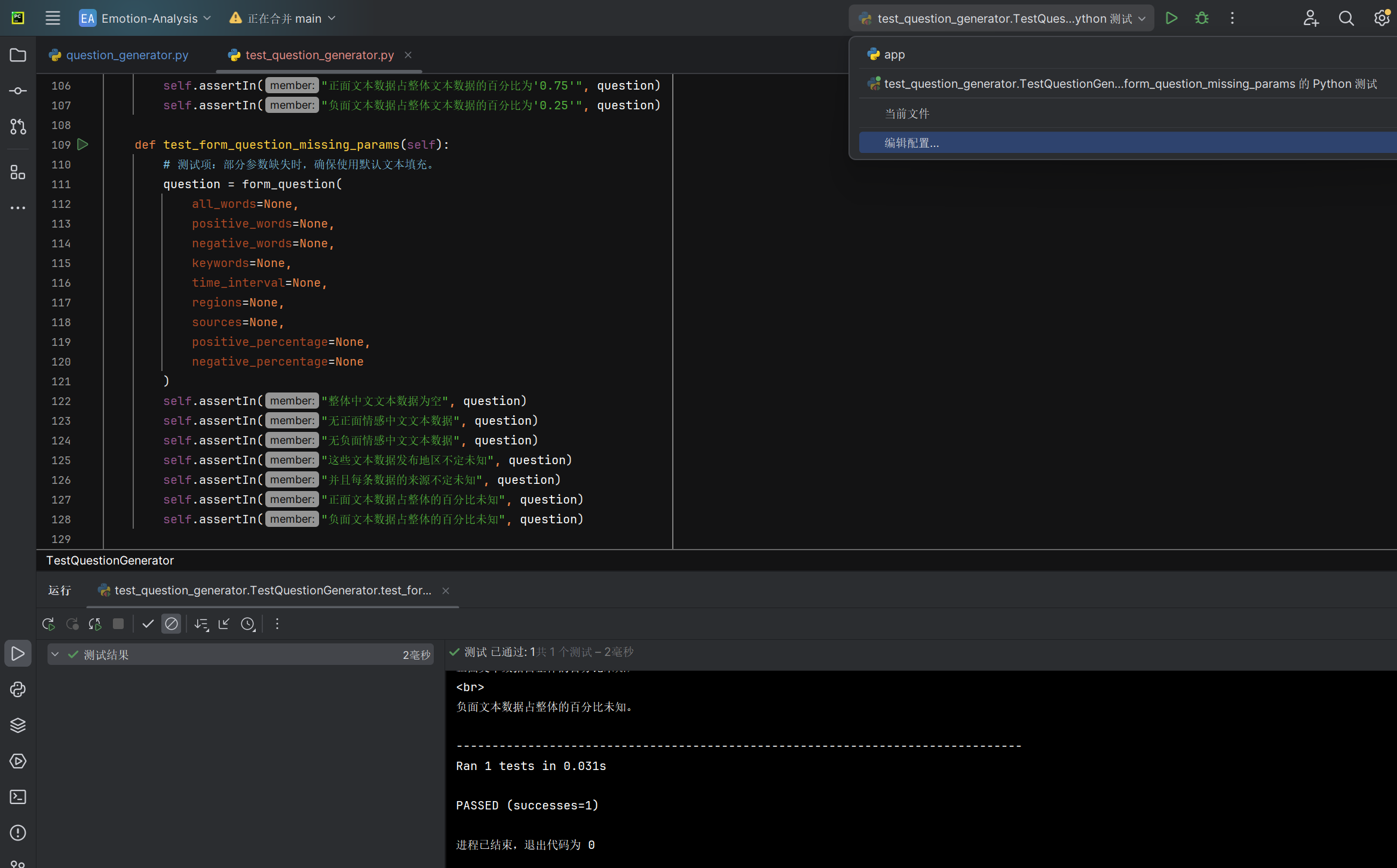 |
1.3.7、系统测试
测试软硬件配置
- 处理器:11th Gen Intel(R) Core(TM) i5-11320H @ 3.20GHz 3.19 GHz
- 内存:16.0 GB (15.8 GB 可用)
- 操作系统:Windows 11
- IDE:PyCharm 2023.3.3 (Community Edition)
- 浏览器:联想浏览器,edge浏览器,chorme浏览器
| 测试项 | 检验点 | 预期结果 | Windows 11 + Pycharm + 联想浏览器 | 截图 | Windows 11 + Pycharm + edge浏览器 | 截图 | Windows 11 + Pycharm + chorme浏览器 | 截图 |
|---|---|---|---|---|---|---|---|---|
| 微博指定范围中文文本情感分析功能 | “话题分析”界面和“AI建议”界面 | “话题分析”界面出现对应的词云和分布扇形图,总体文字分析,可向AI提问建议,“AI建议”界面输入信息框中有提问语句,AI会回复相关结论建议 | T | 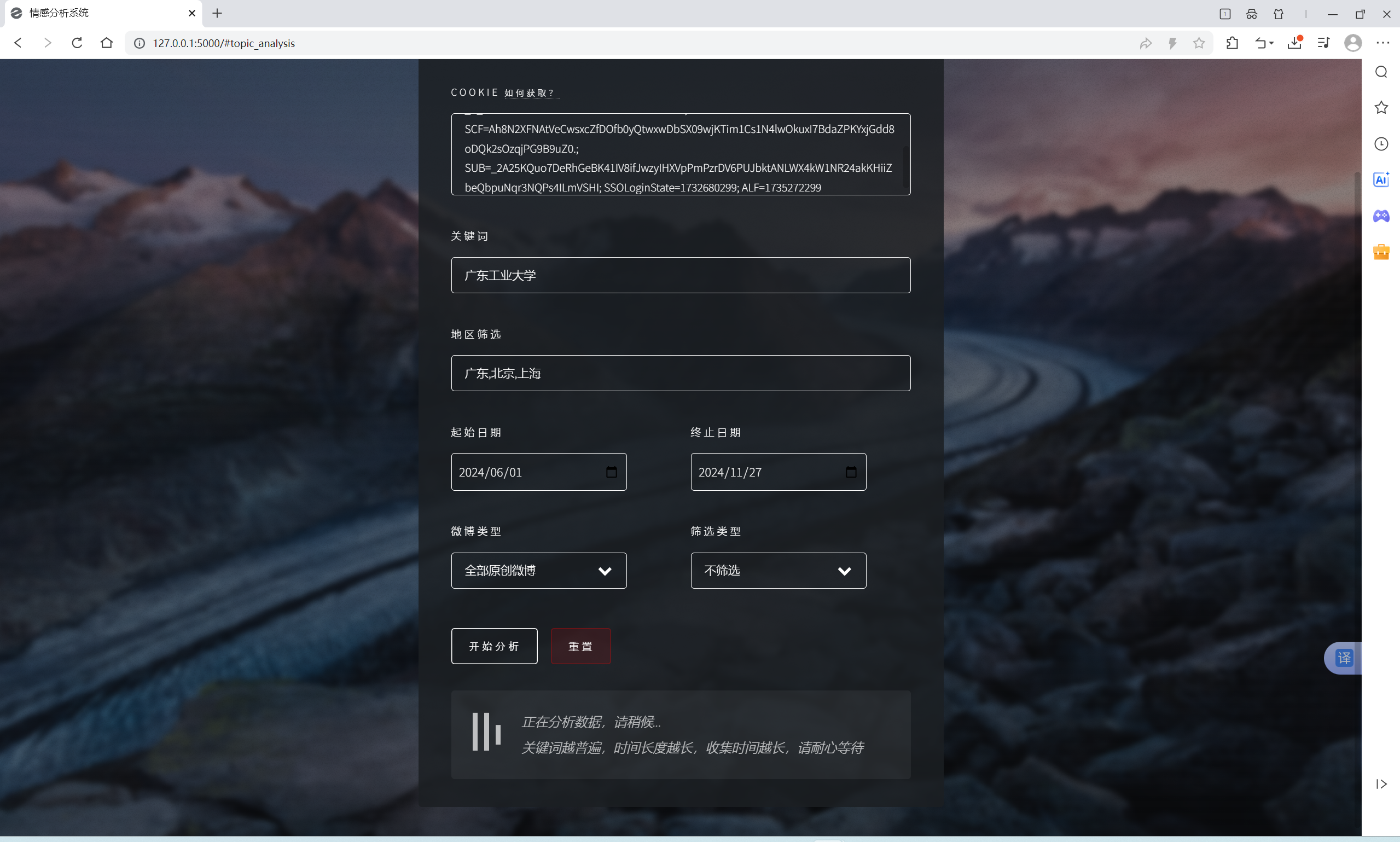 , ,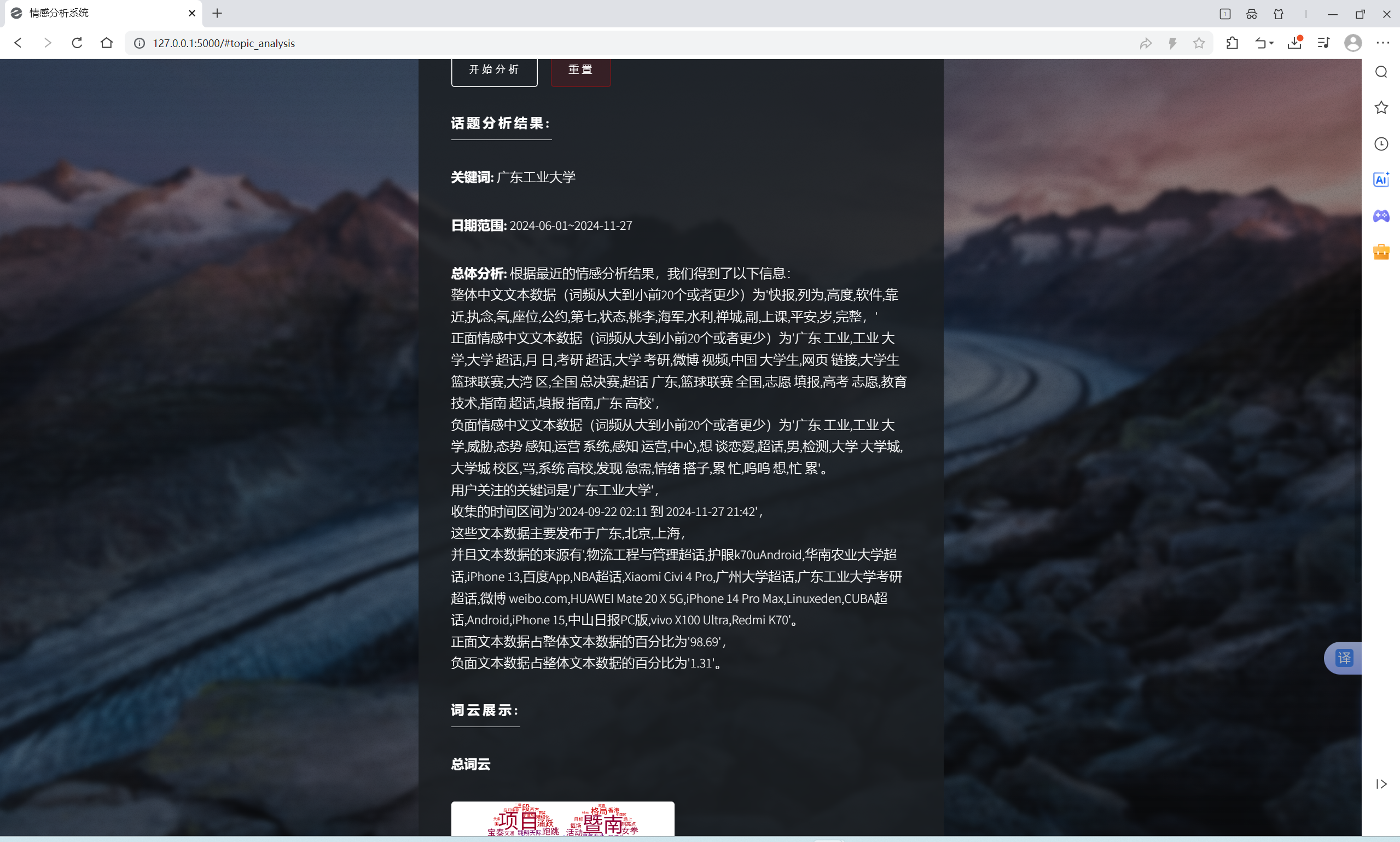 , ,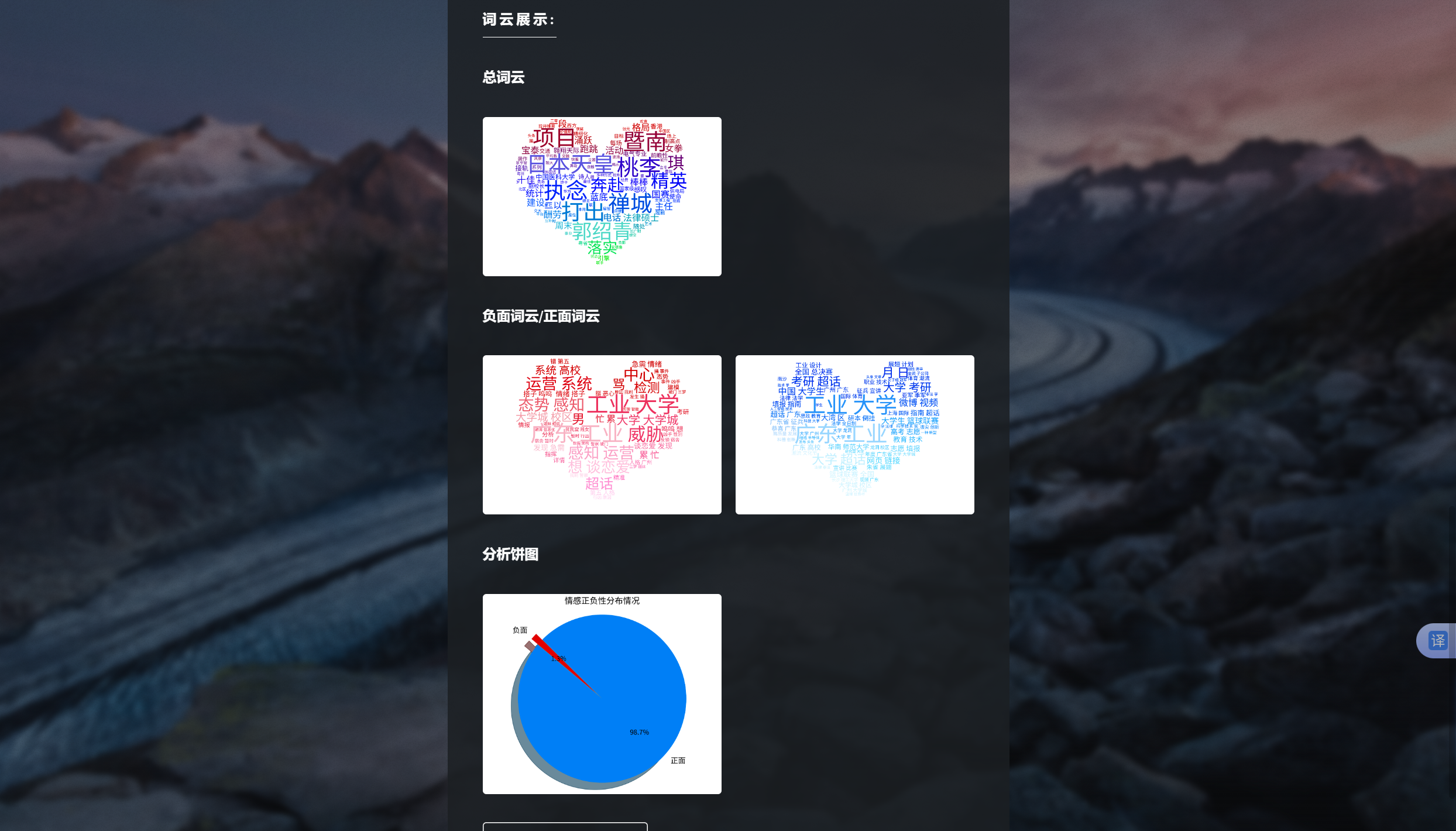 , ,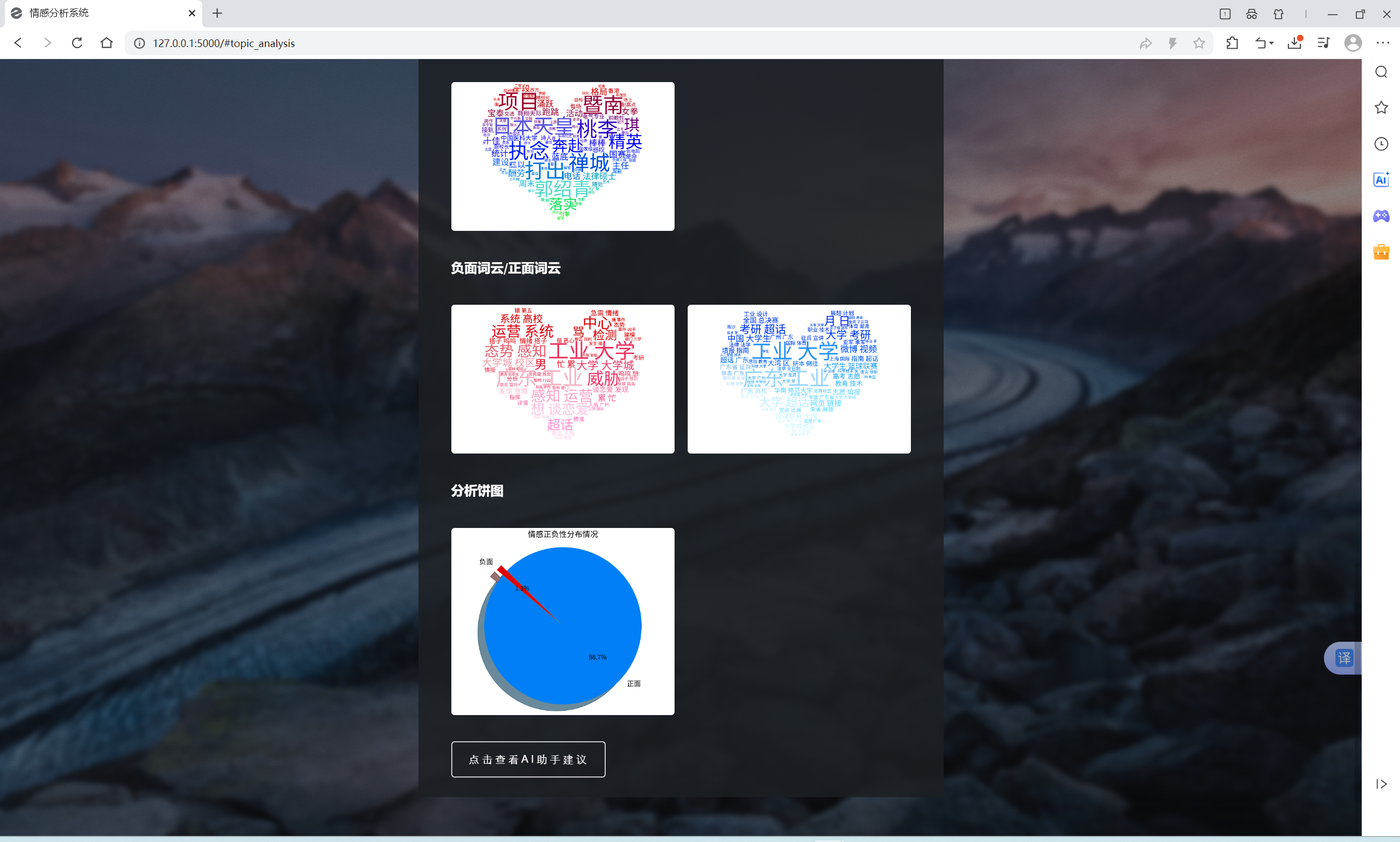 , ,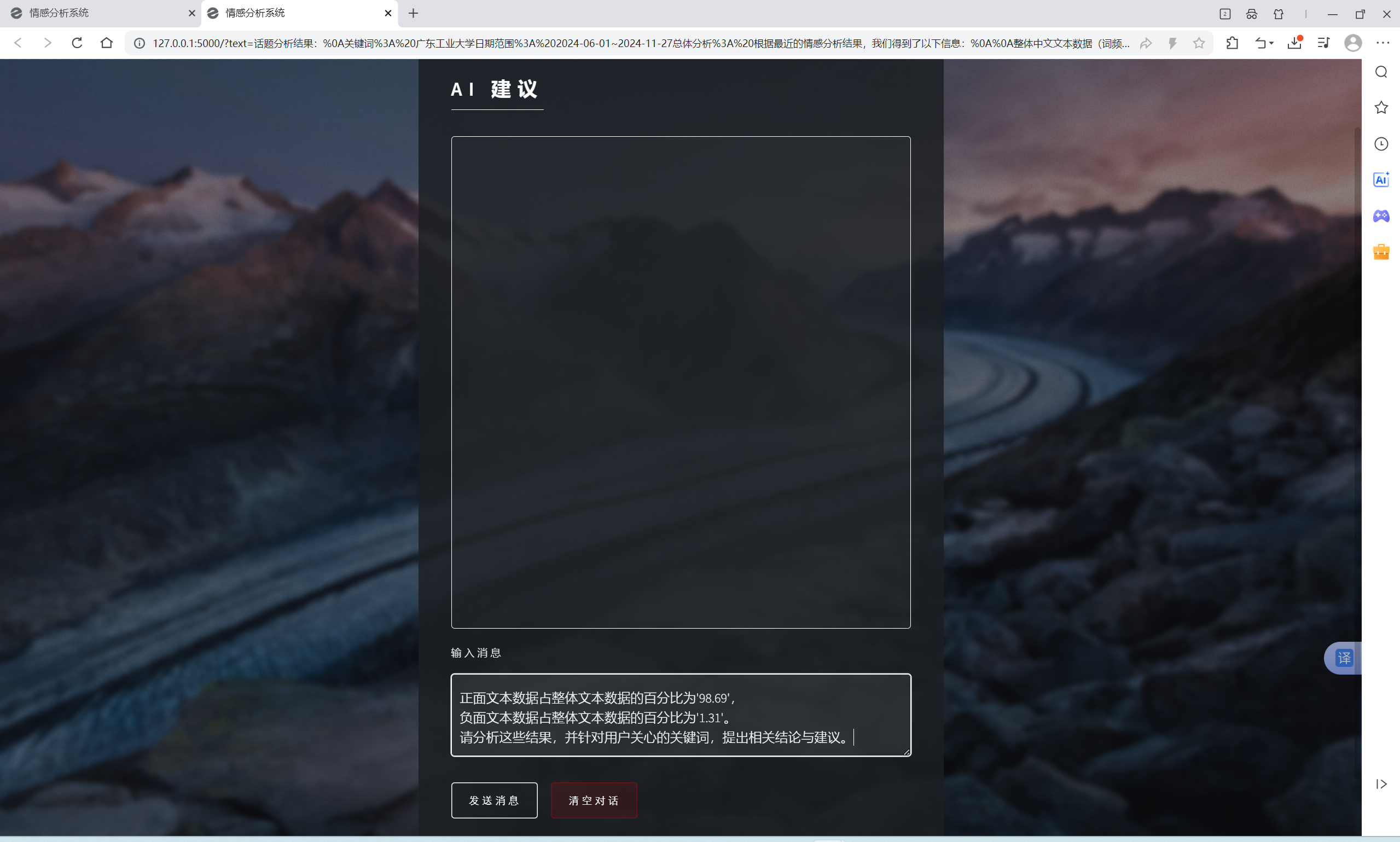 , ,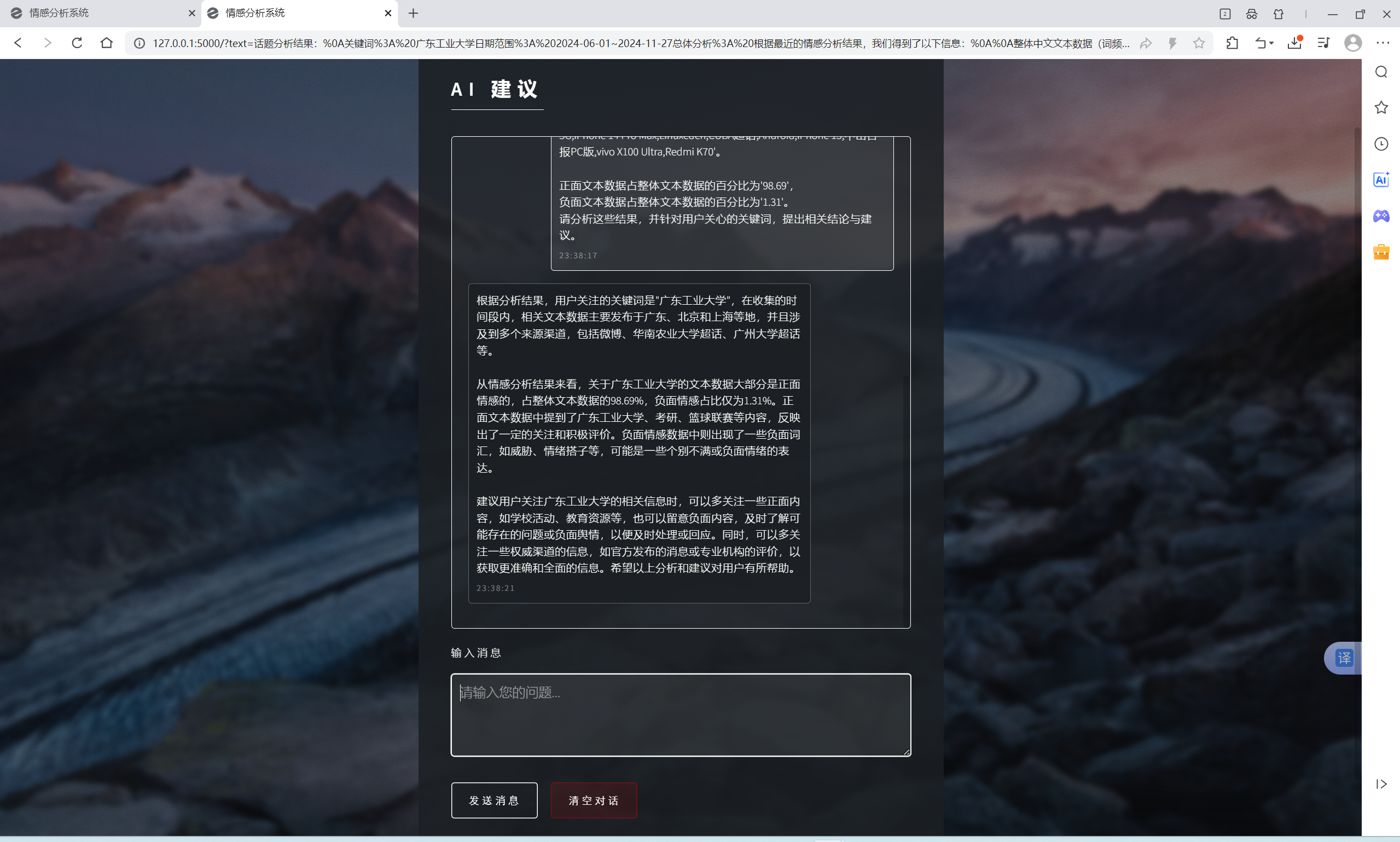 , , |
T |  , , , , , , , ,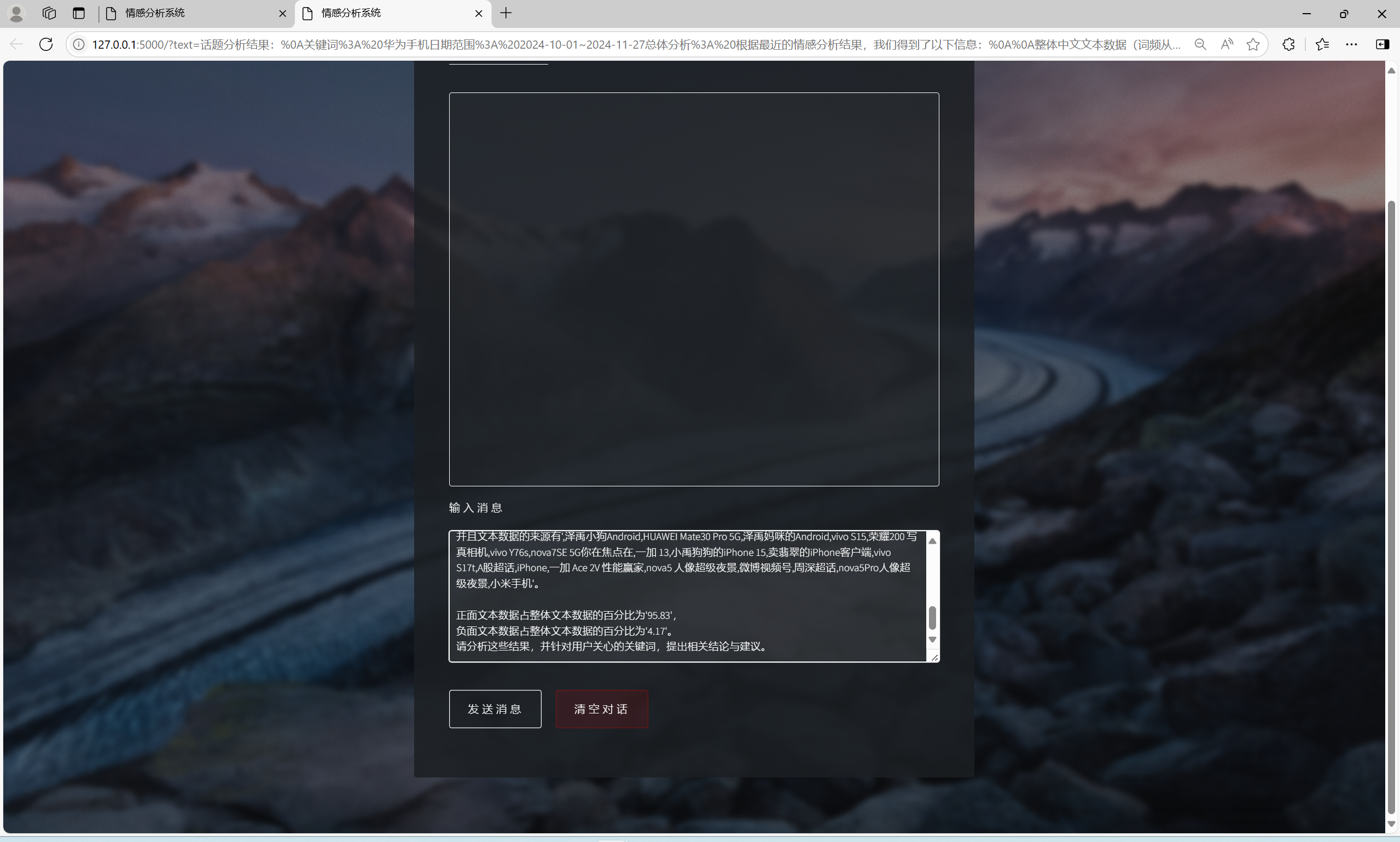 , ,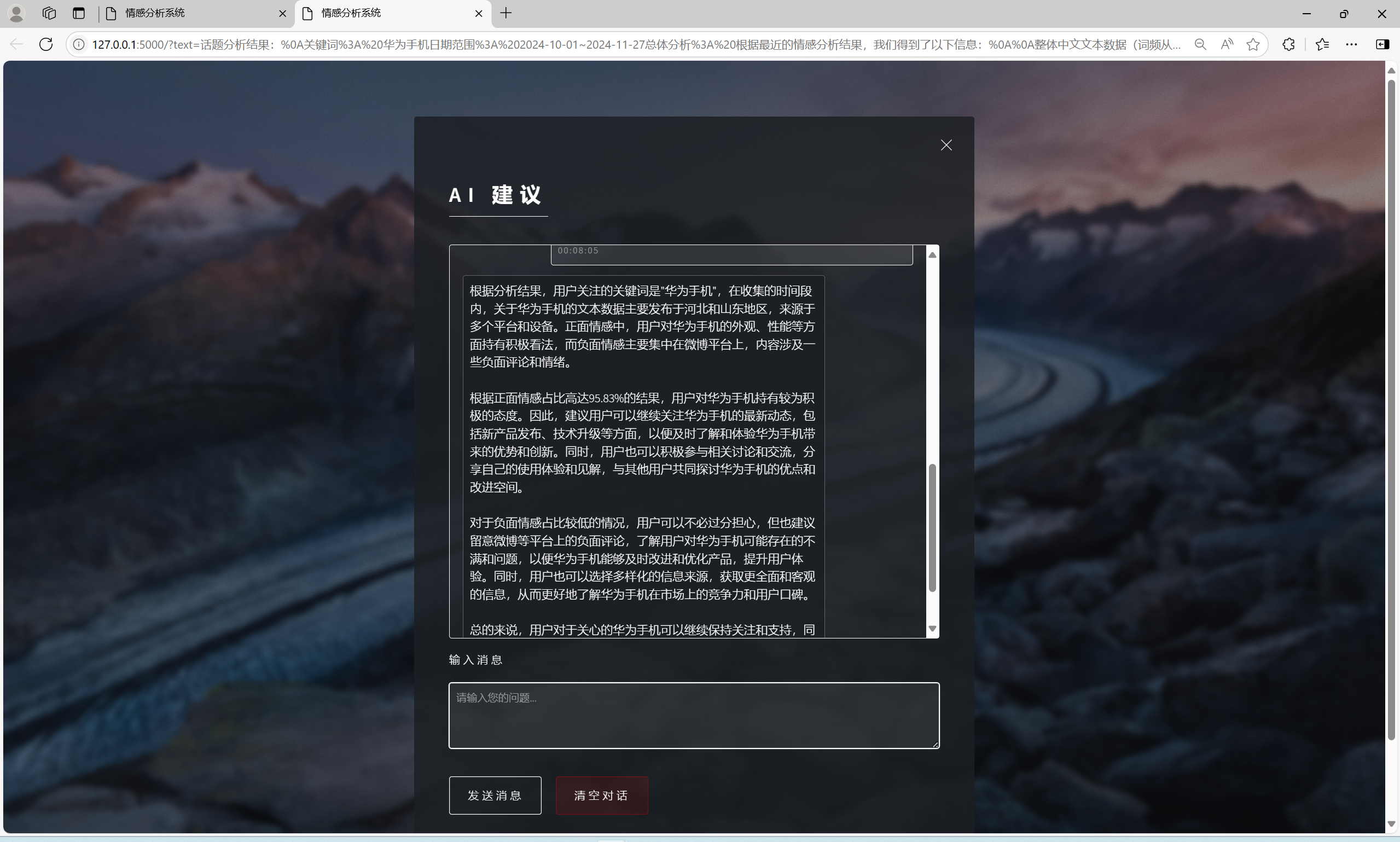 , ,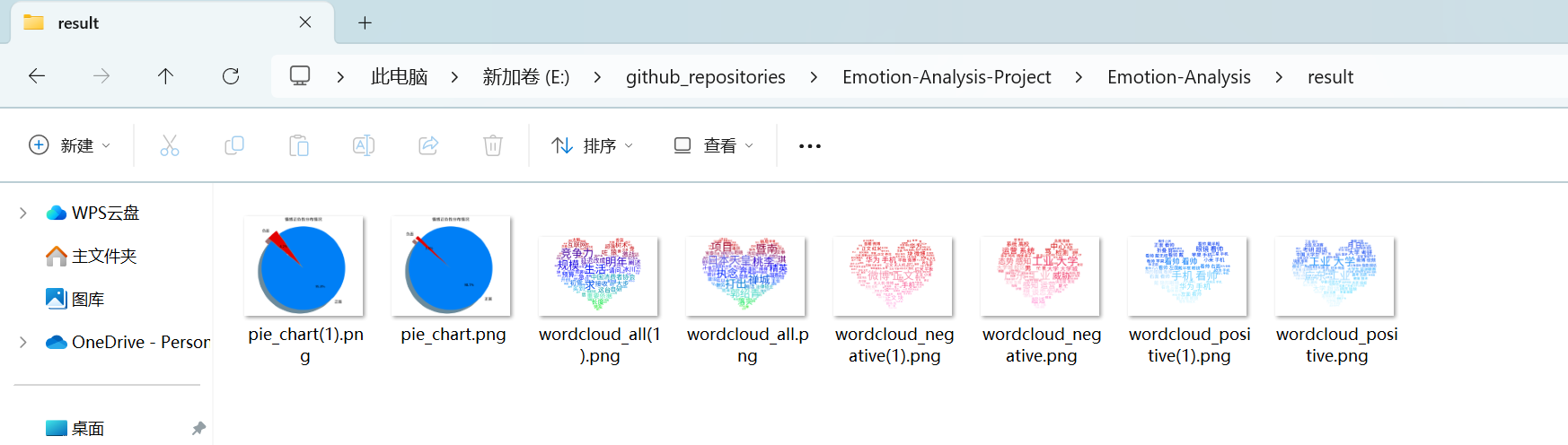 |
T | 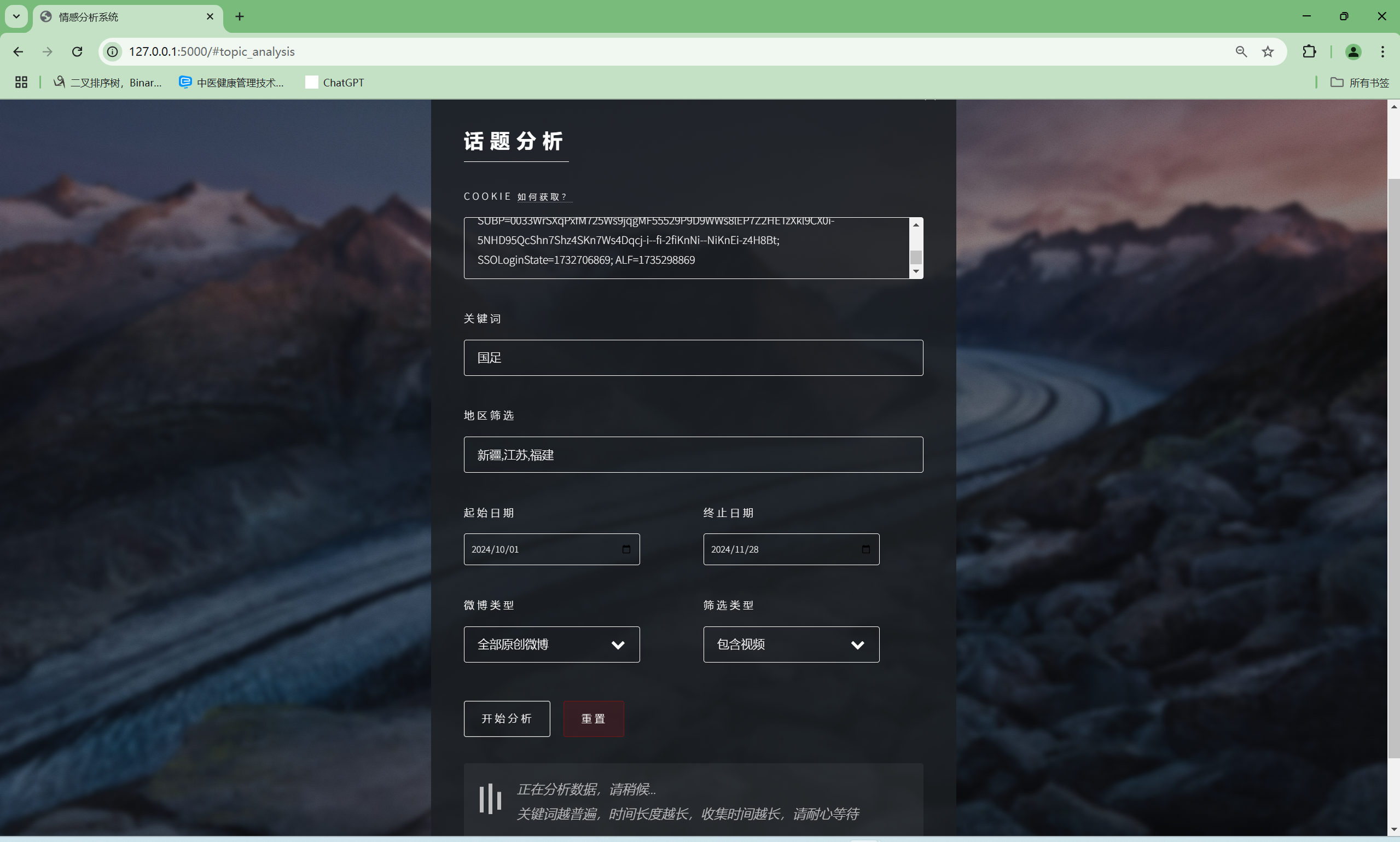 , ,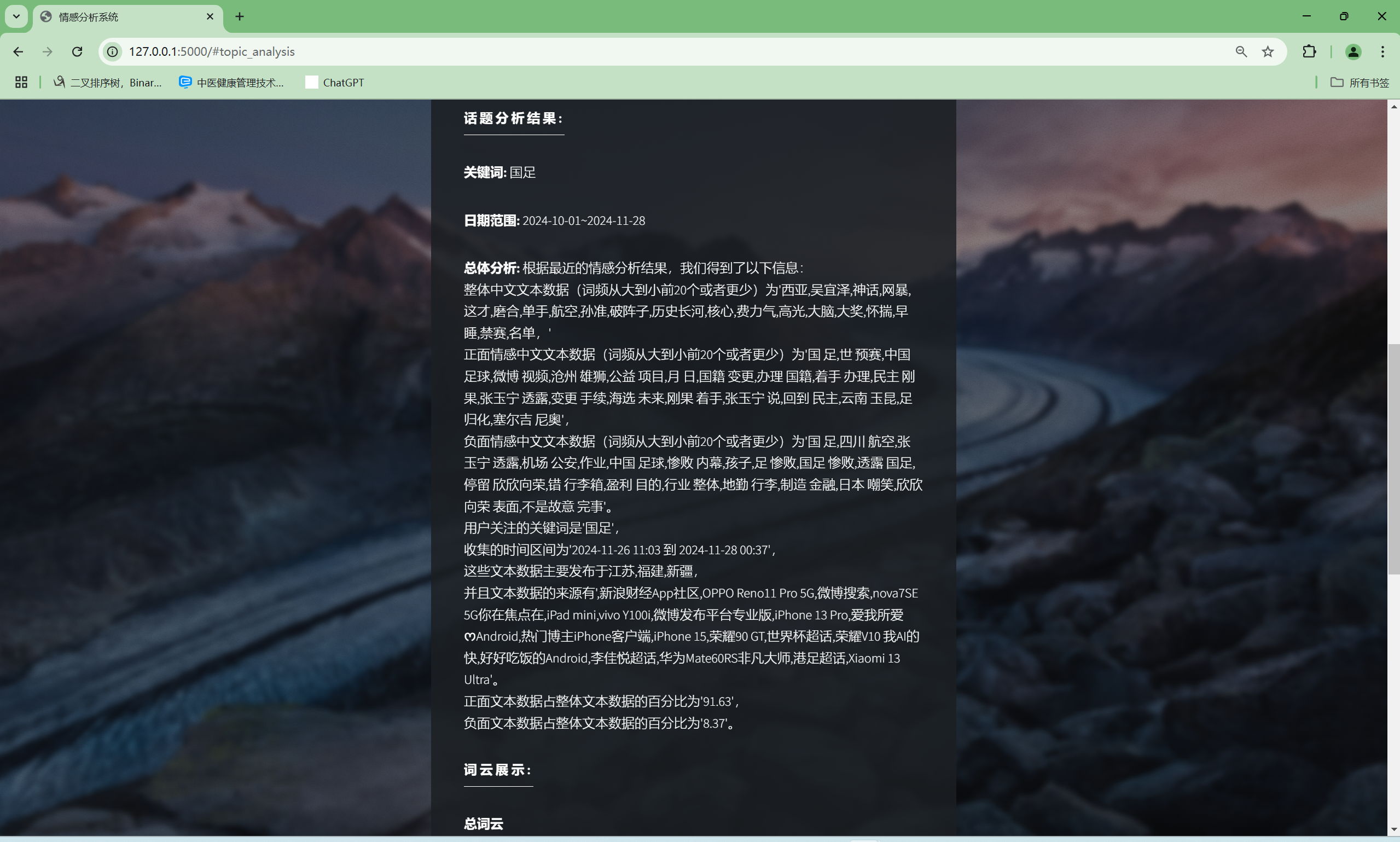 , ,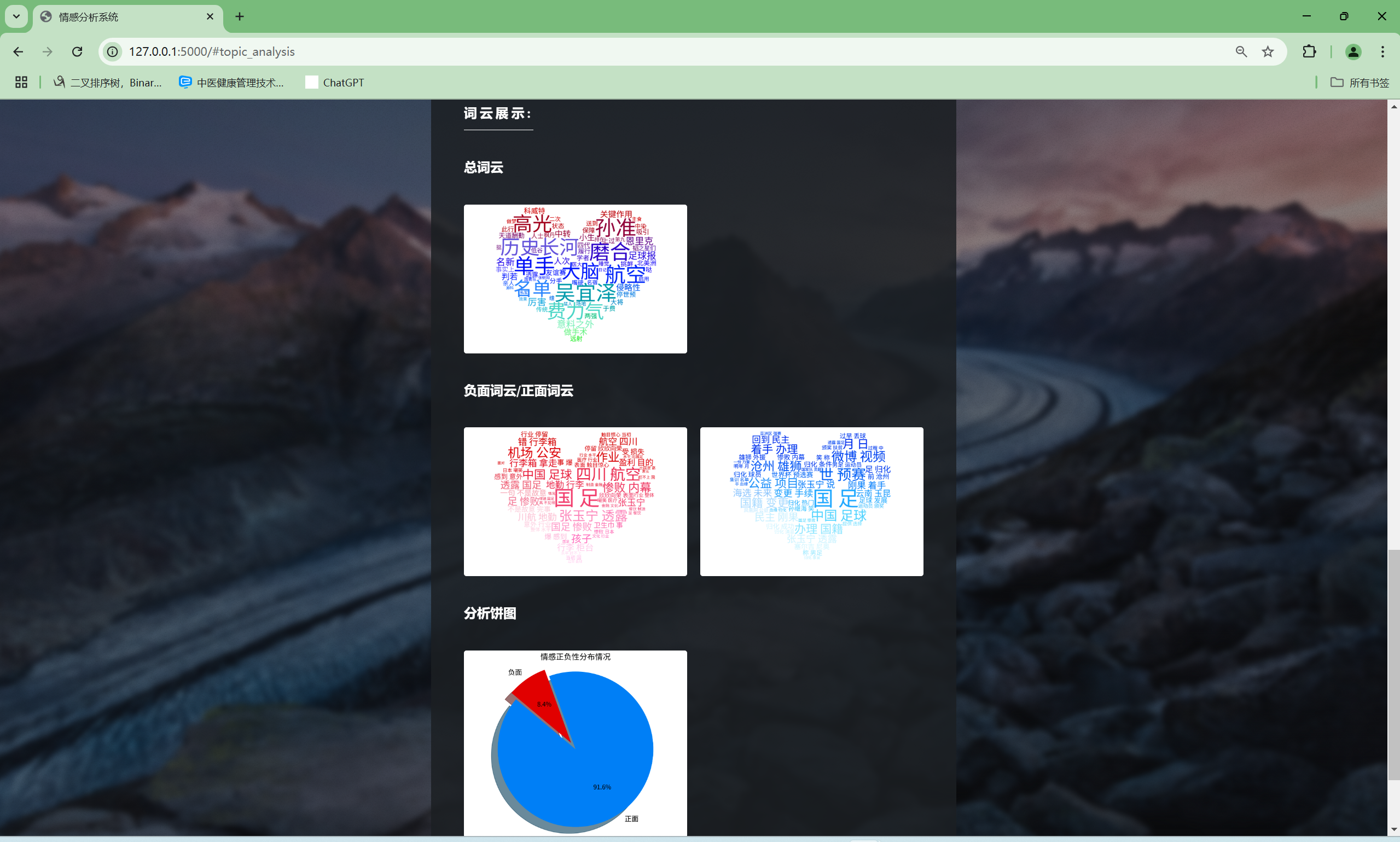 , ,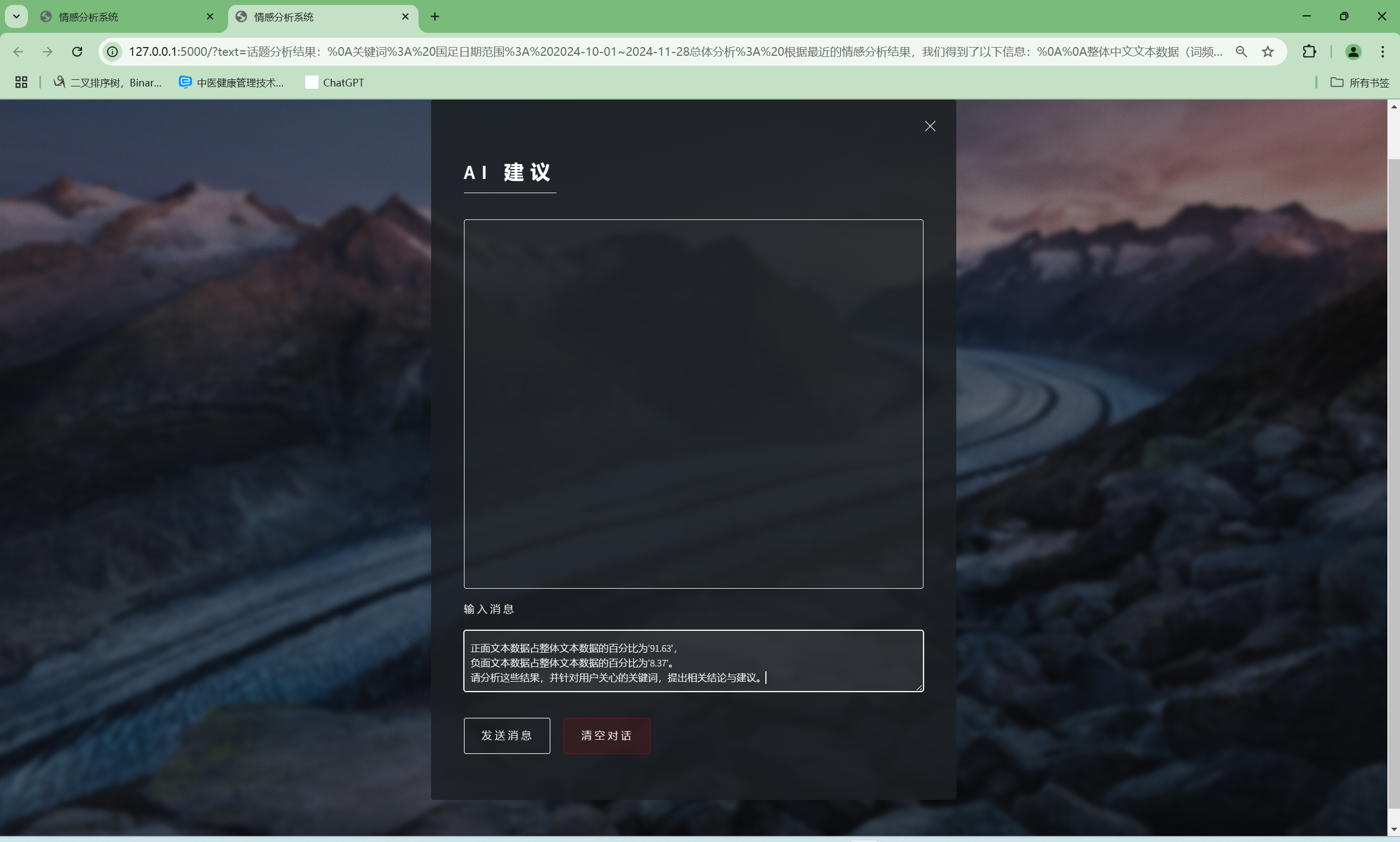 , ,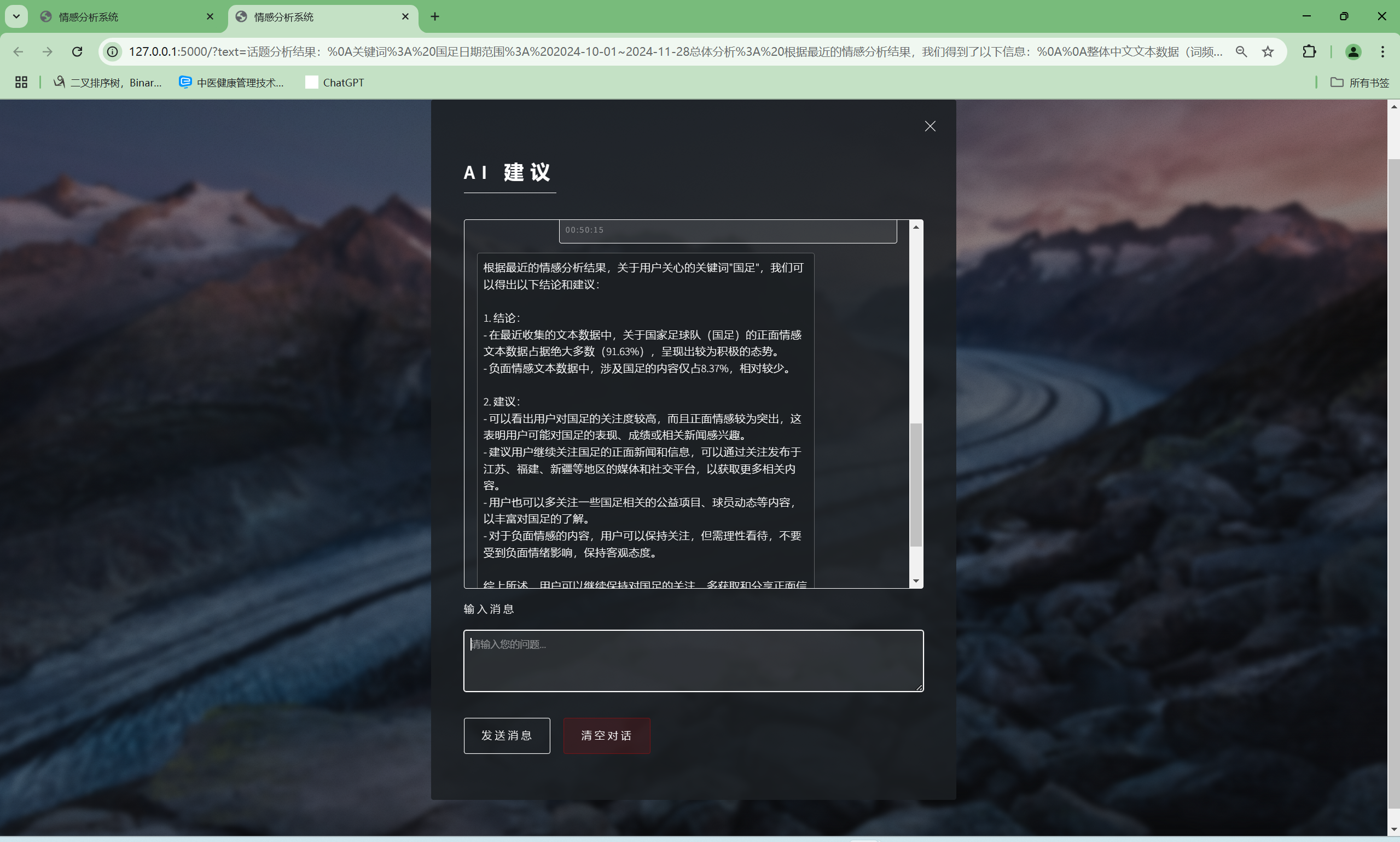 , , |
| AI建议交流功能 | “AI建议”界面 | AI会根据输入信息进行回复 | T | 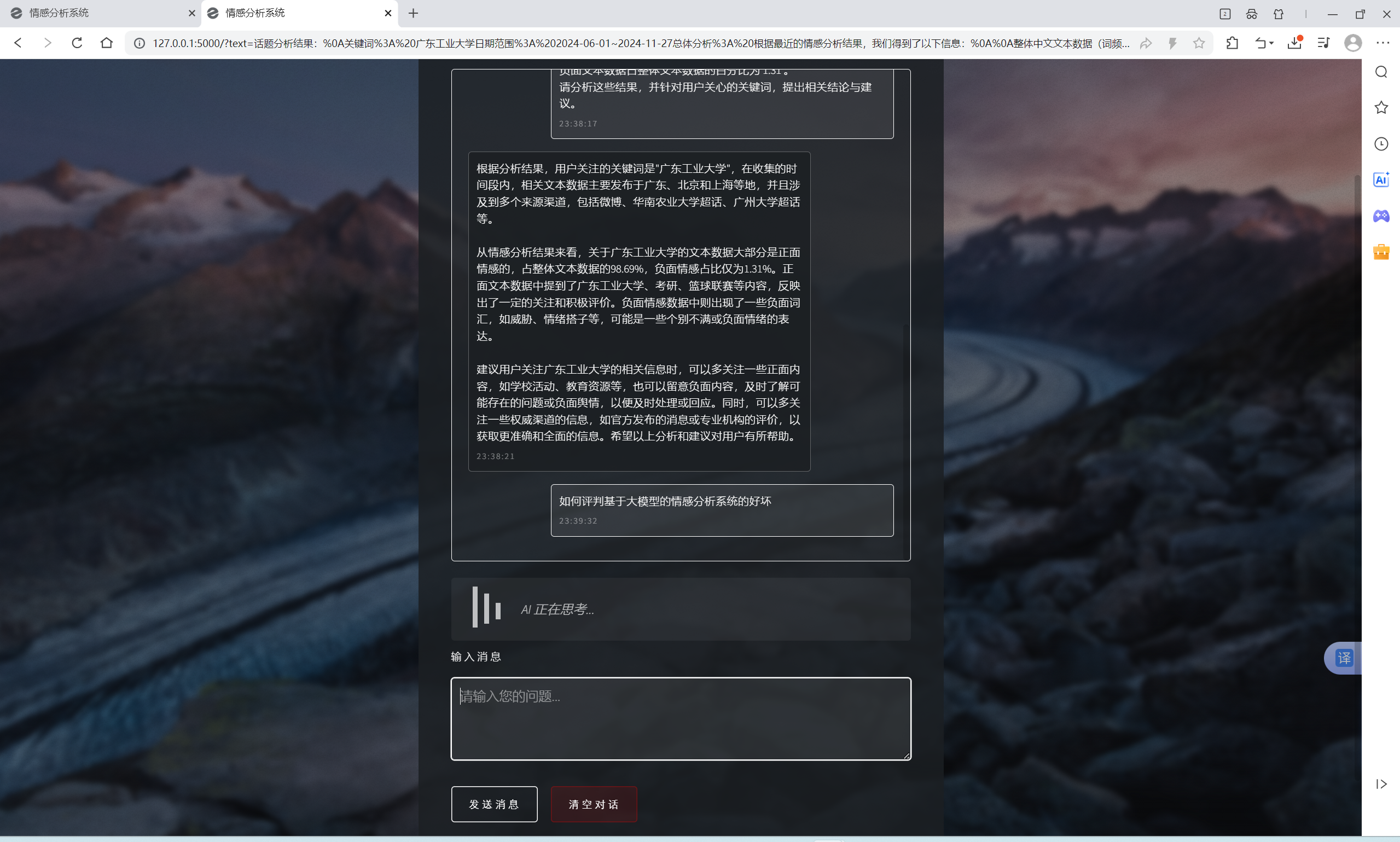 , ,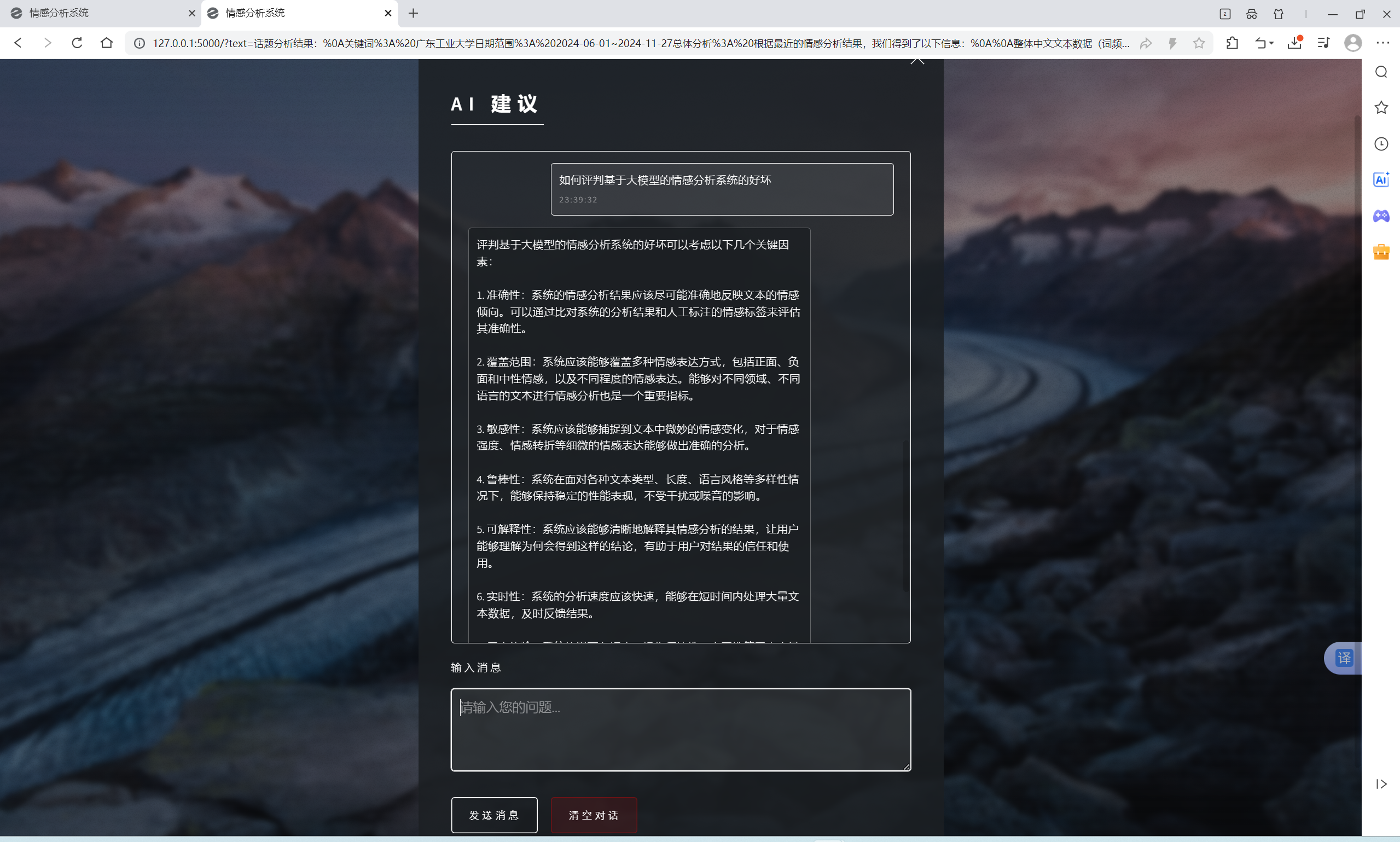 |
T | 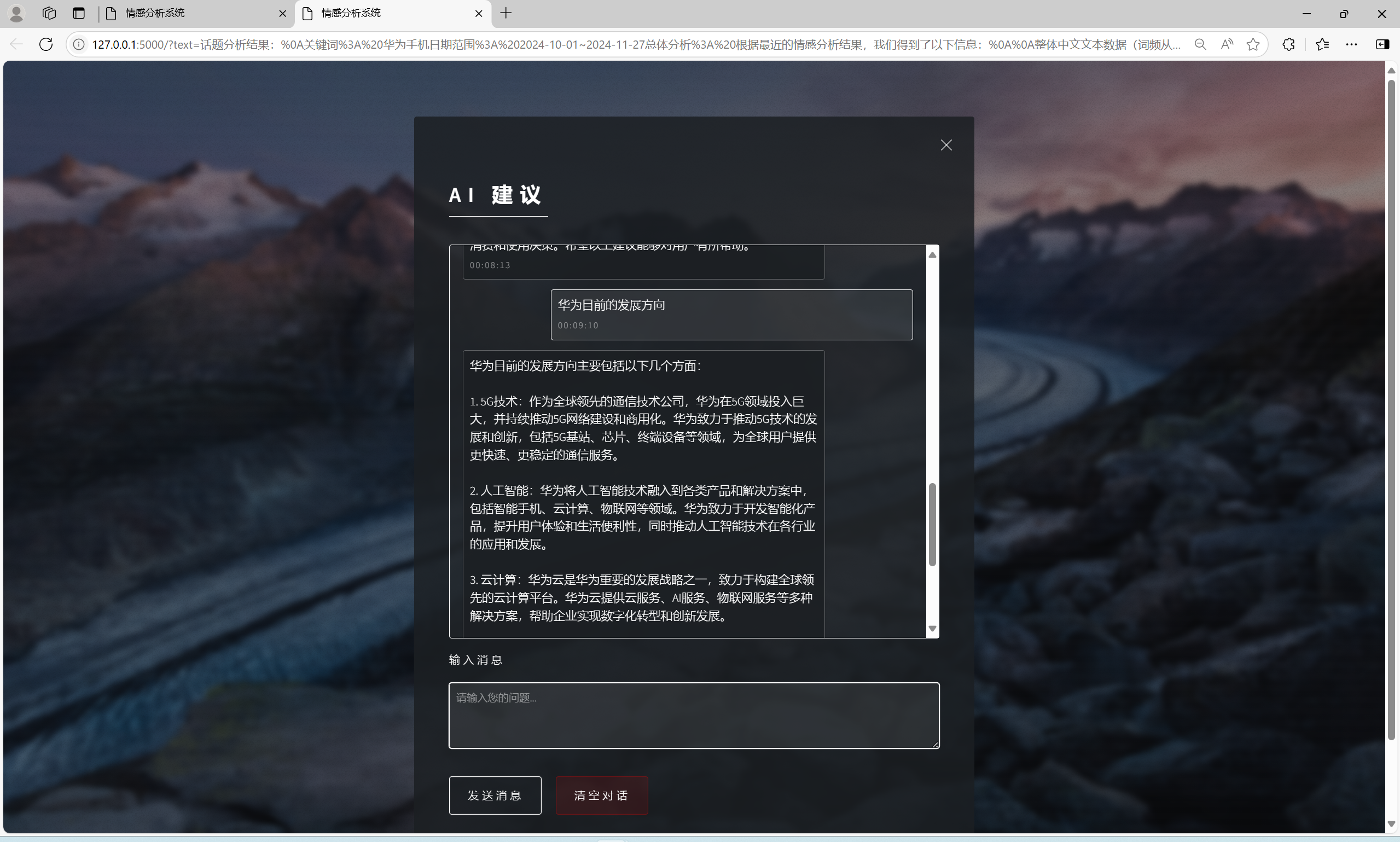 |
T | 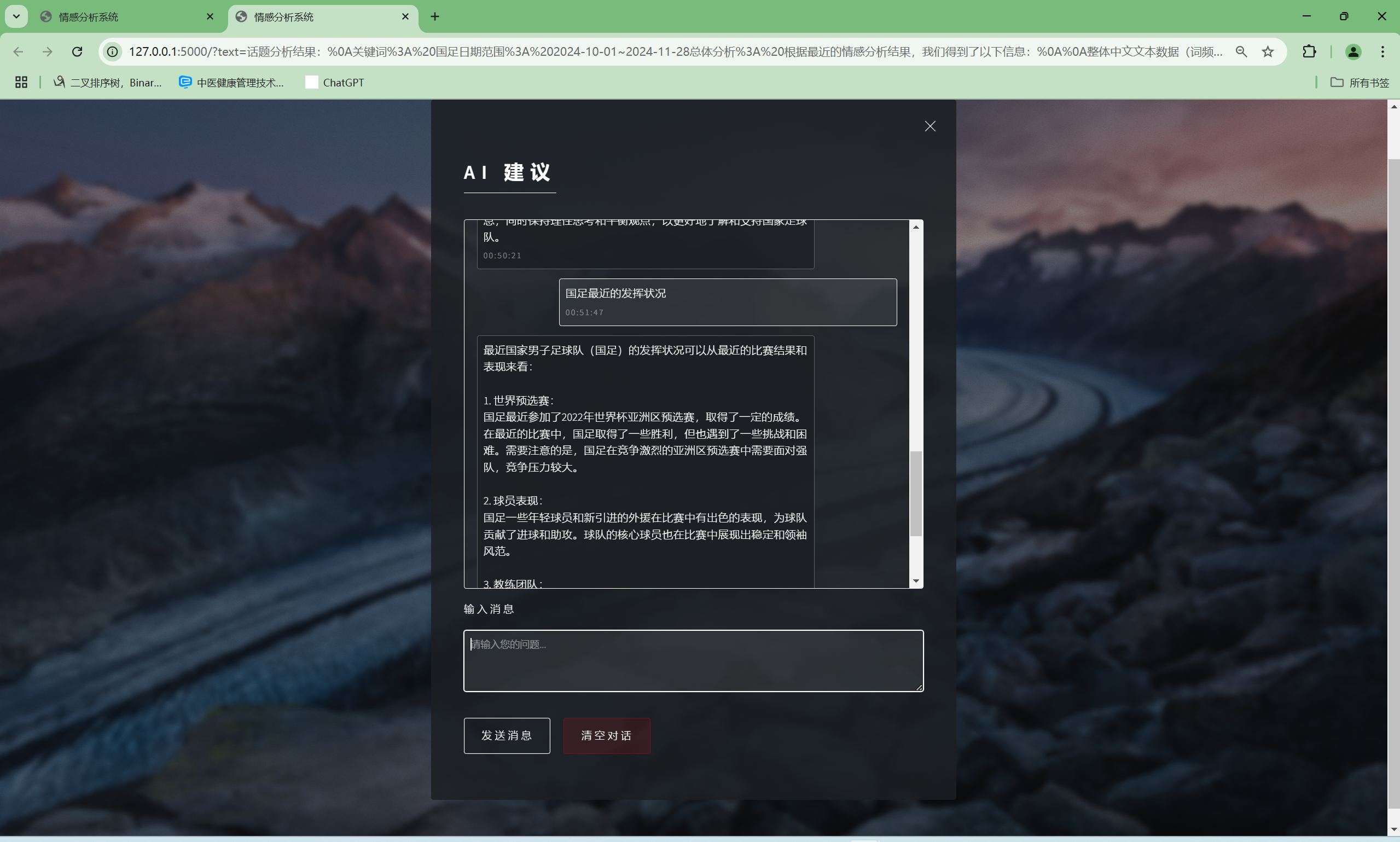 |
1.4、出口条件
- 软件能在Windows 11, Python 3.11以及PyCharm平台上正常运行,对指定关键词,地区,时间,内容类型和筛选类型的微博发布中文文本进行情感分析,输出词云和分布扇形图,且AI能根据分析结果提供相关建议,可与AI进行交流
2、Alpha版本发布说明
2.1、功能介绍
| 功能 | 描述 | 截图 |
|---|---|---|
| 微博中文文本内容情感分析 | 输入微博登录后的网页cookie,需要重点关注的关键词,地区,微博内容选取和类型,获取微博相关中文文本的情感极性分布饼图,整体和所有情感极性文本数据的词云图,另外还可将分析结果向AI提问,AI提供相关分析说明建议 |  , , |
| AI建议交流 | 在提问输入框中输入交流与提问,AI链接显示窗口将显示AI得回答 |  , , 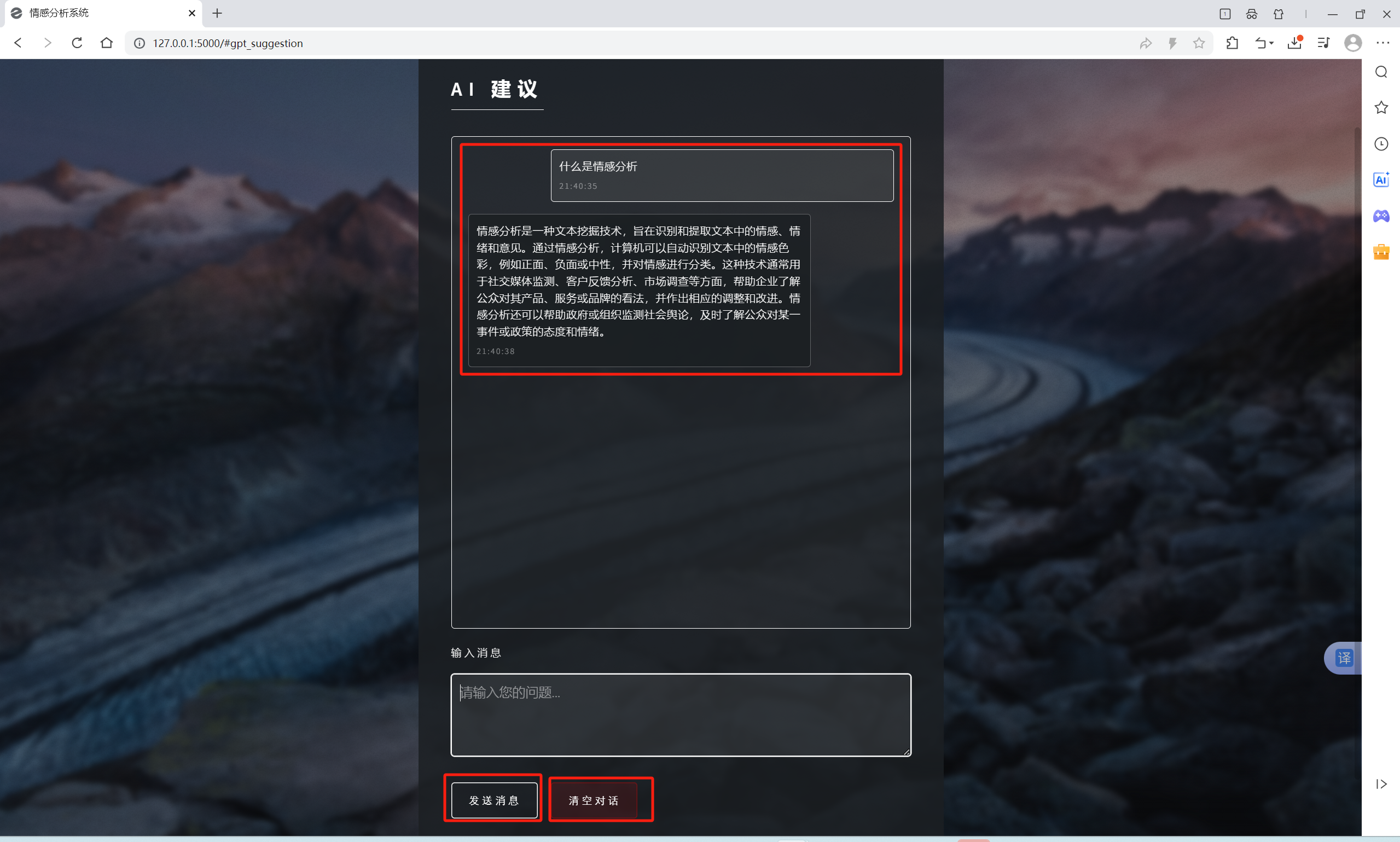 |
2.2、修复的缺陷
- 该版本为第一个版本,暂无已修复的缺陷。
2.3、环境要求
- 操作系统:Windows 11
- IDE:PyCharm 2023.3.3 (Community Edition)或以上版本或专业版本
- Python:python 3.11 或以上版本
- 依赖库:requirements.txt文件里的依赖库
2.4、安装开始使用方法
(1)配置硬软件环境
- 在Windows 11操作系统中,安装配置适合Windows 11操作系统的Python 3.11,PyCharm 2023.3.3(Community Edition)
- 安装配置教程可参考:Python 3.11 安装教程,PyCharm 2023.3.3 Community Edition 安装教程
(2)下载解压软件
- 下载并解压软件压缩包
(3)设置编码与运行配置
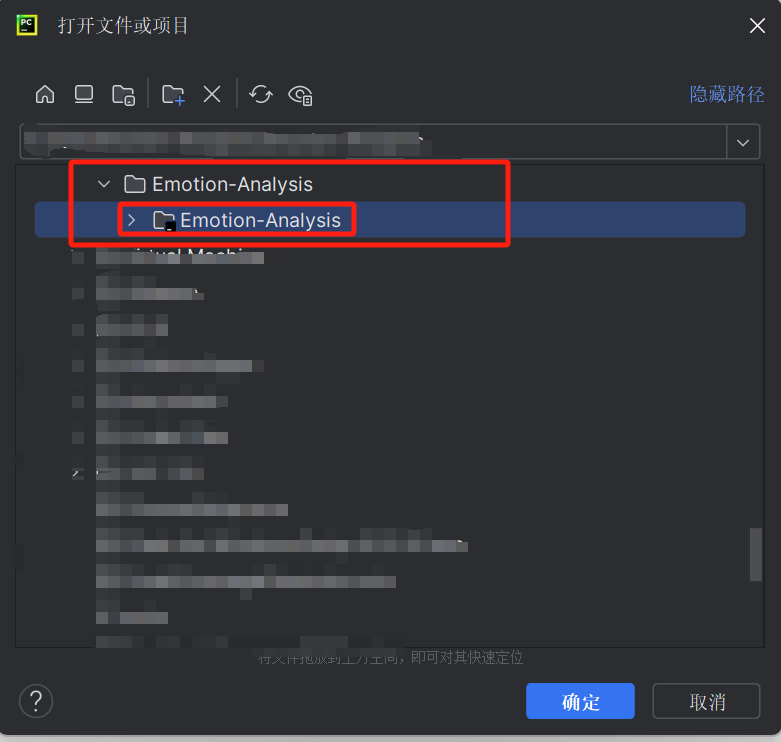
- 用PyCharm打开解压的软件文件夹中的Emotion-Analysis pycharm项目文件夹,如图:
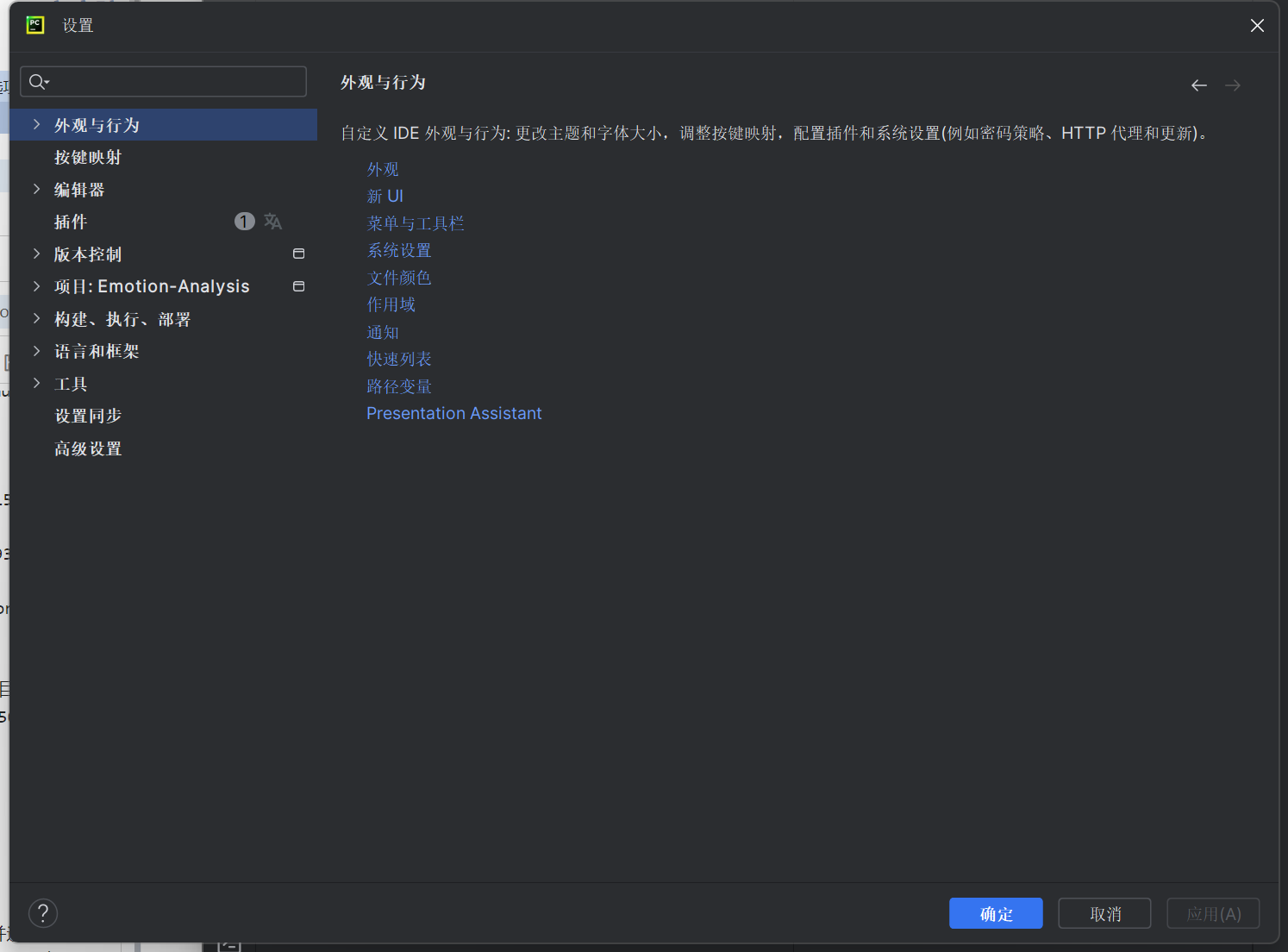
- 在PyCharm中键盘输入快捷键“ctrl+alt+s”打开设置,如图:
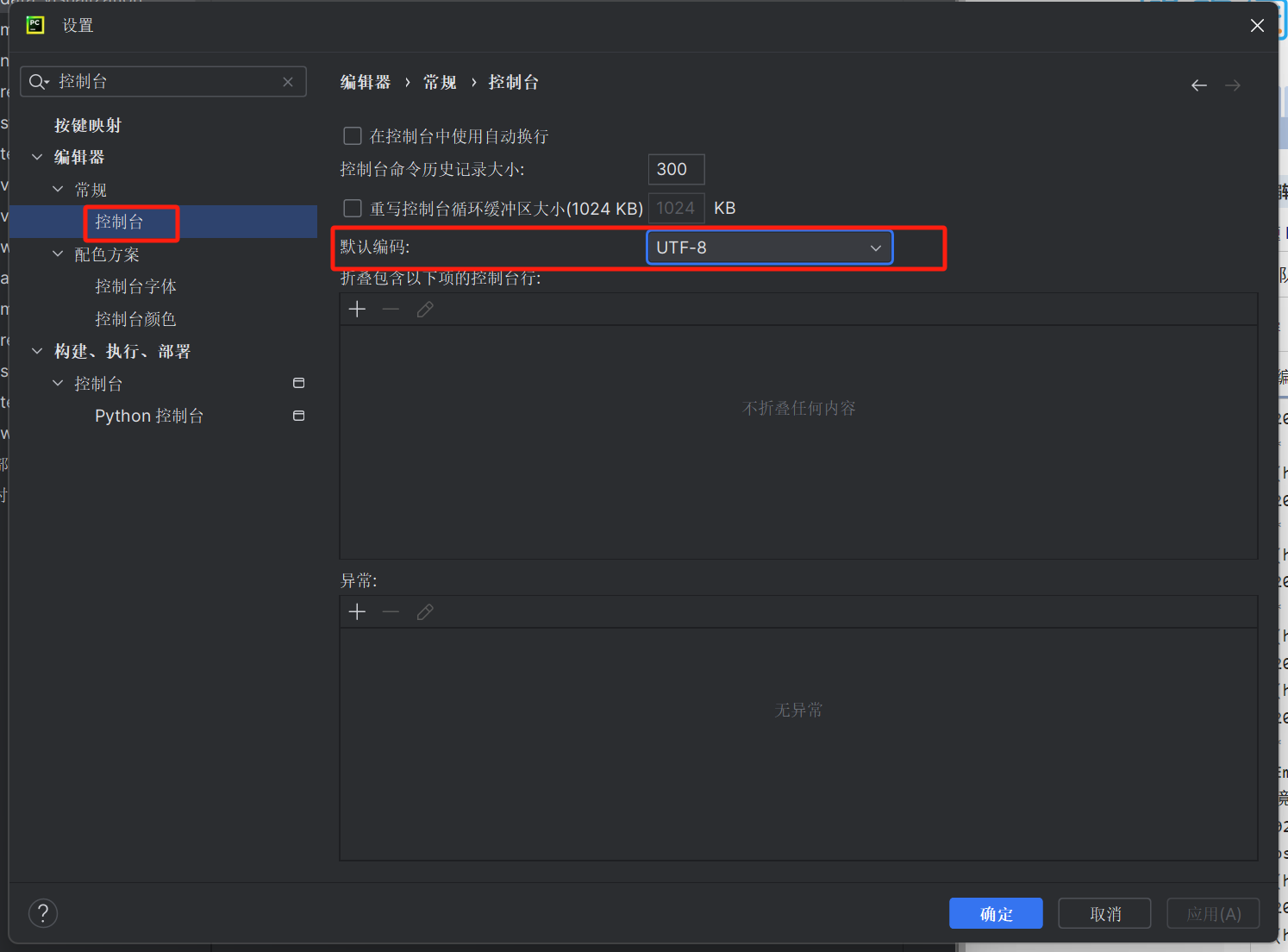
- 在设置的搜索中输入“控制台”,将“默认编码”设置为“UTF-8”,如图:
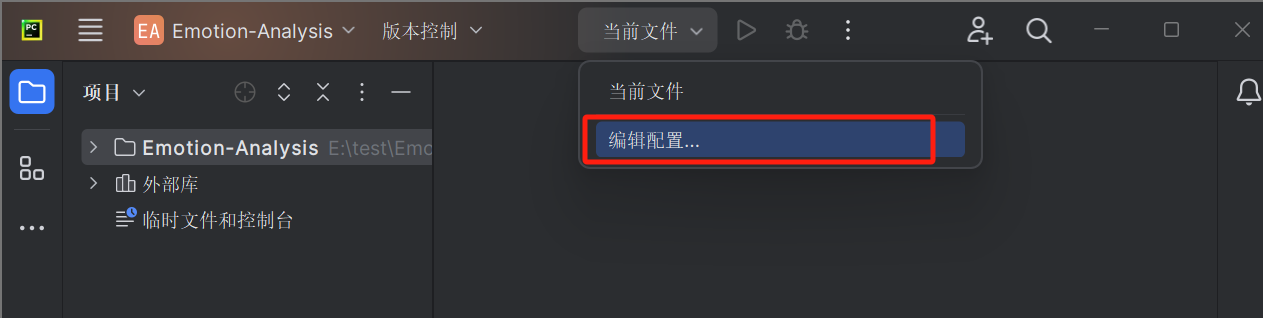
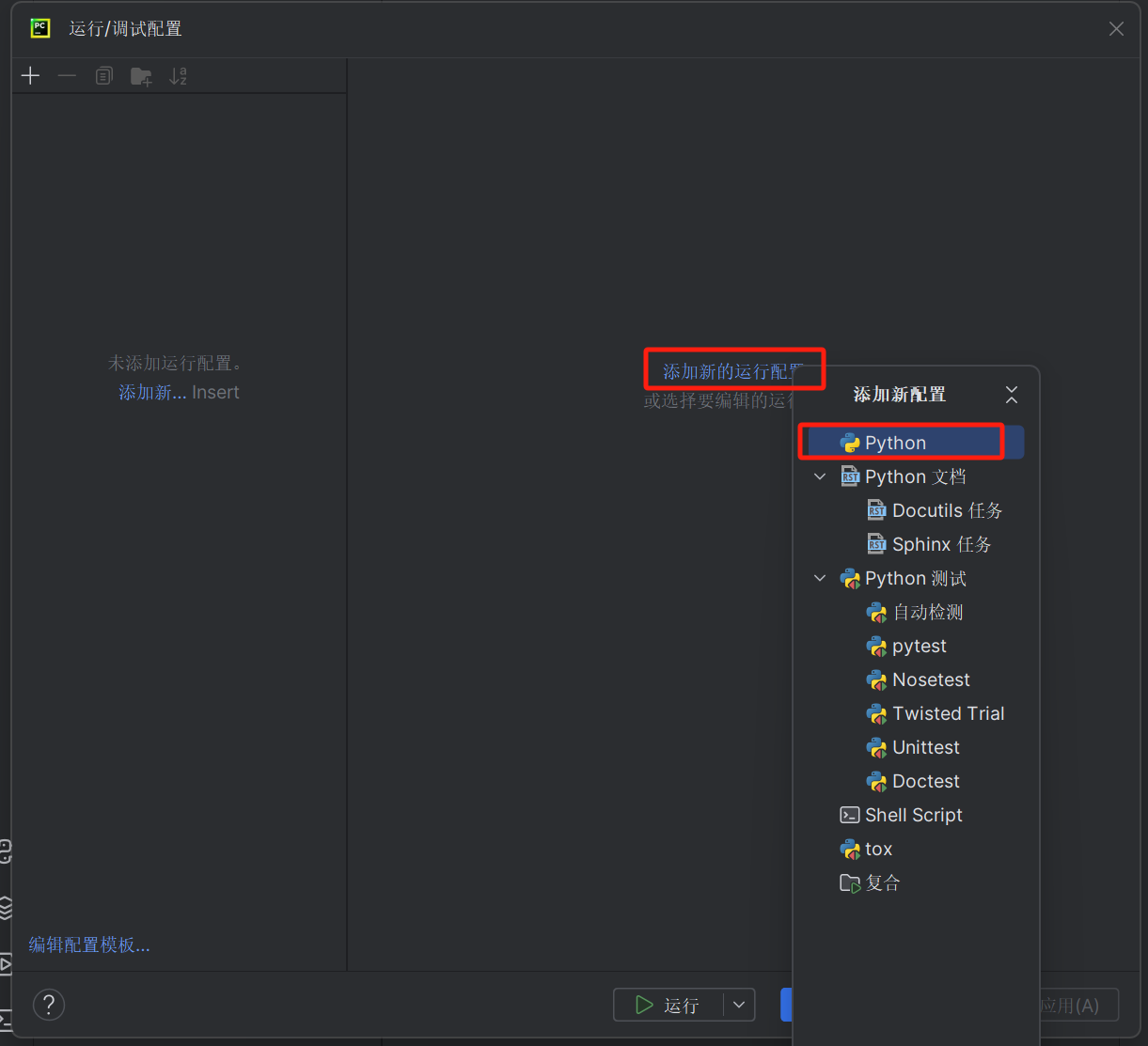
- 打开运行/调试配置,添加新配置,如图:
 ,
,
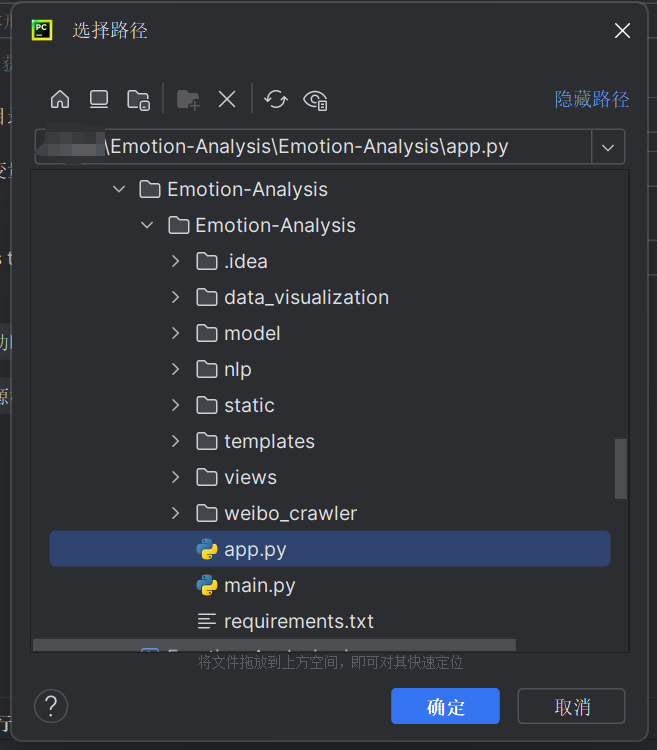
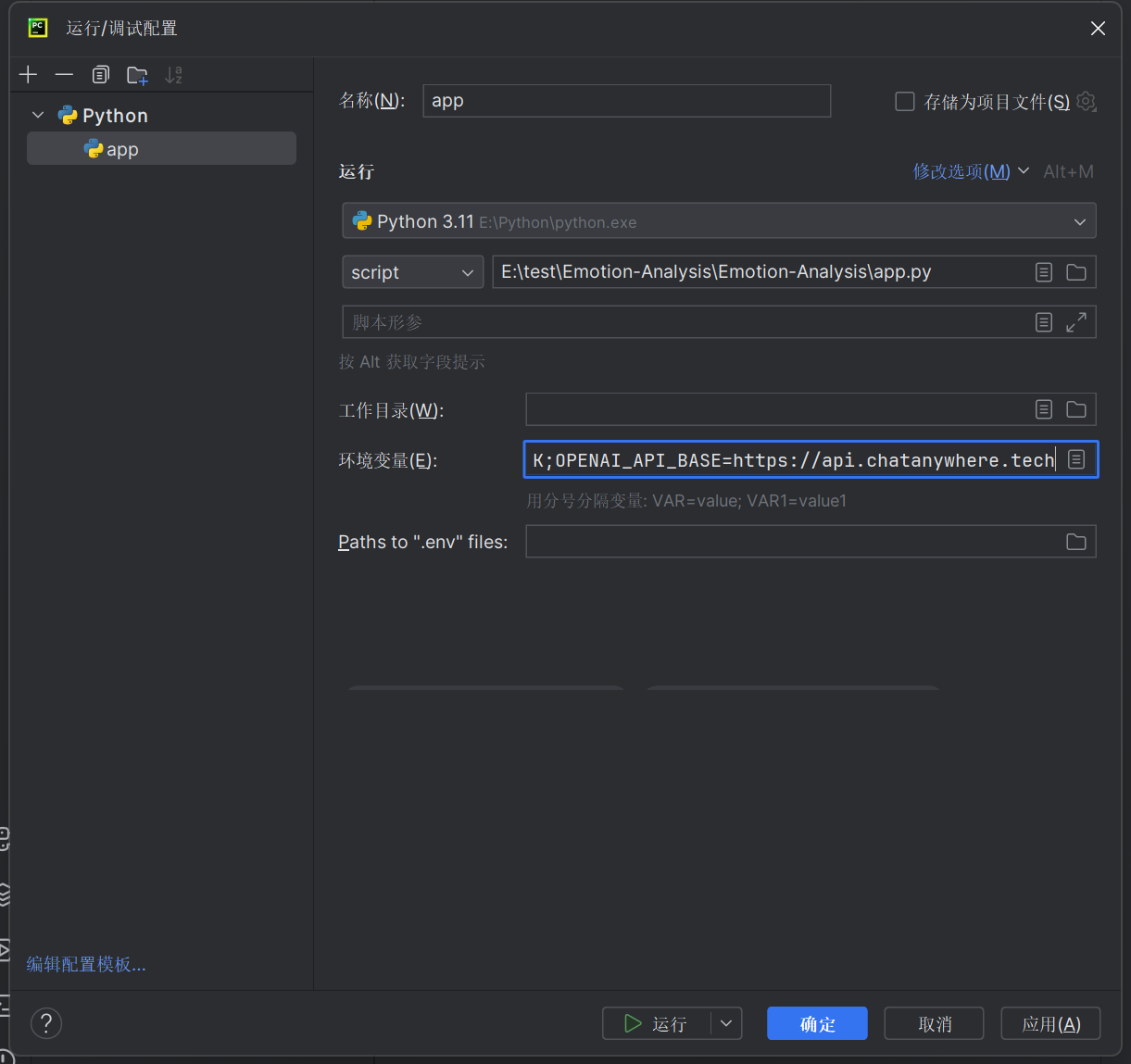
- 在新配置的运行中选择下载的Python 3.11文件夹中的python.exe,并选择Emotion-Analysis pycharm项目文件夹中的app.py文件作为脚本,并替换原本的环境变量为:
OPENAI_API_KEY=sk-02HUIWUOSRHjsGaKTSHFgjAWPZPNKBla7SrrlwPt05hqhOnK;OPENAI_API_BASE=https://api.chatanywhere.tech,如图: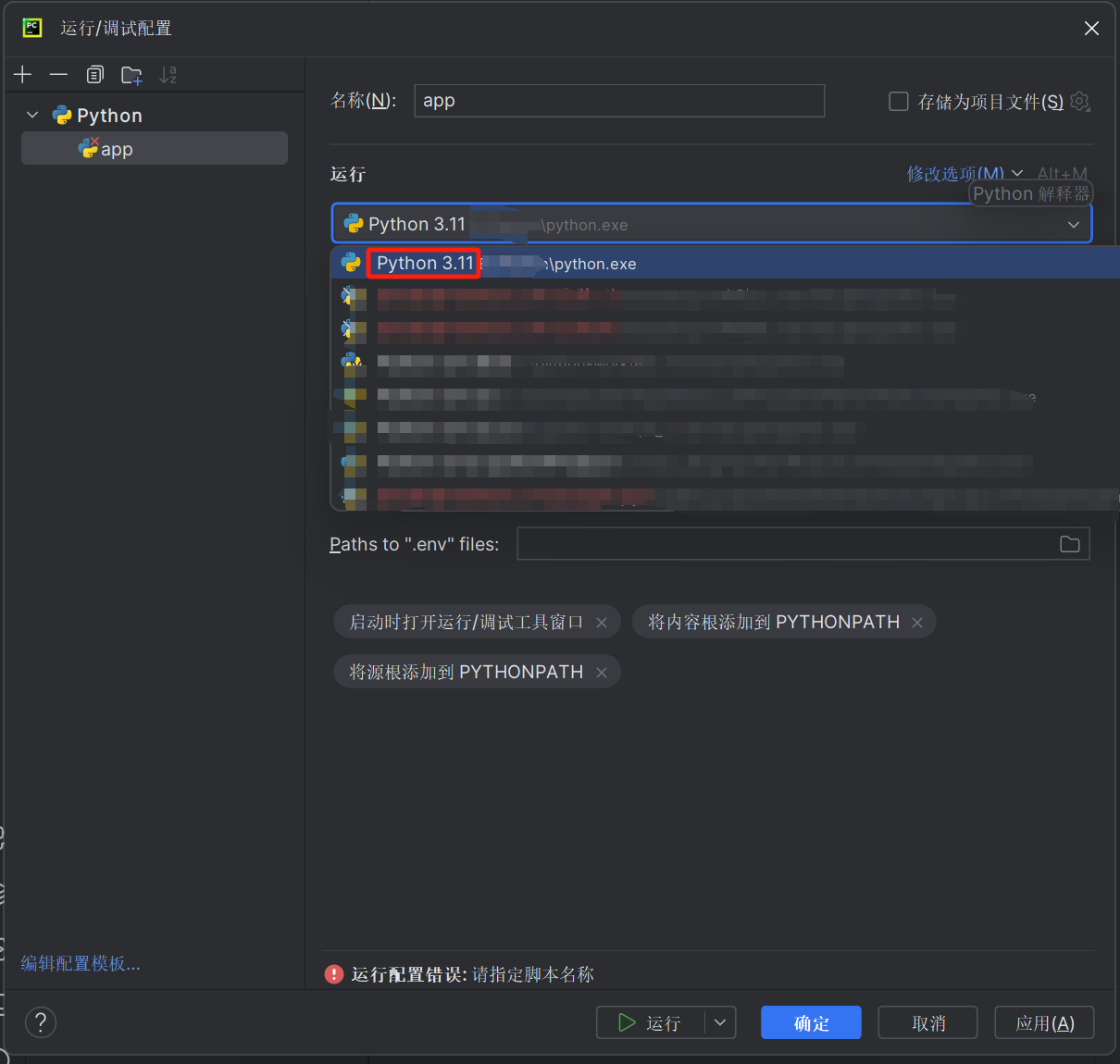 ,
, ,
, ,
,
(4)开始使用,启动项目
- 点击“应用”和“运行”,如图:

- 点击运行界面中的网址,如图:
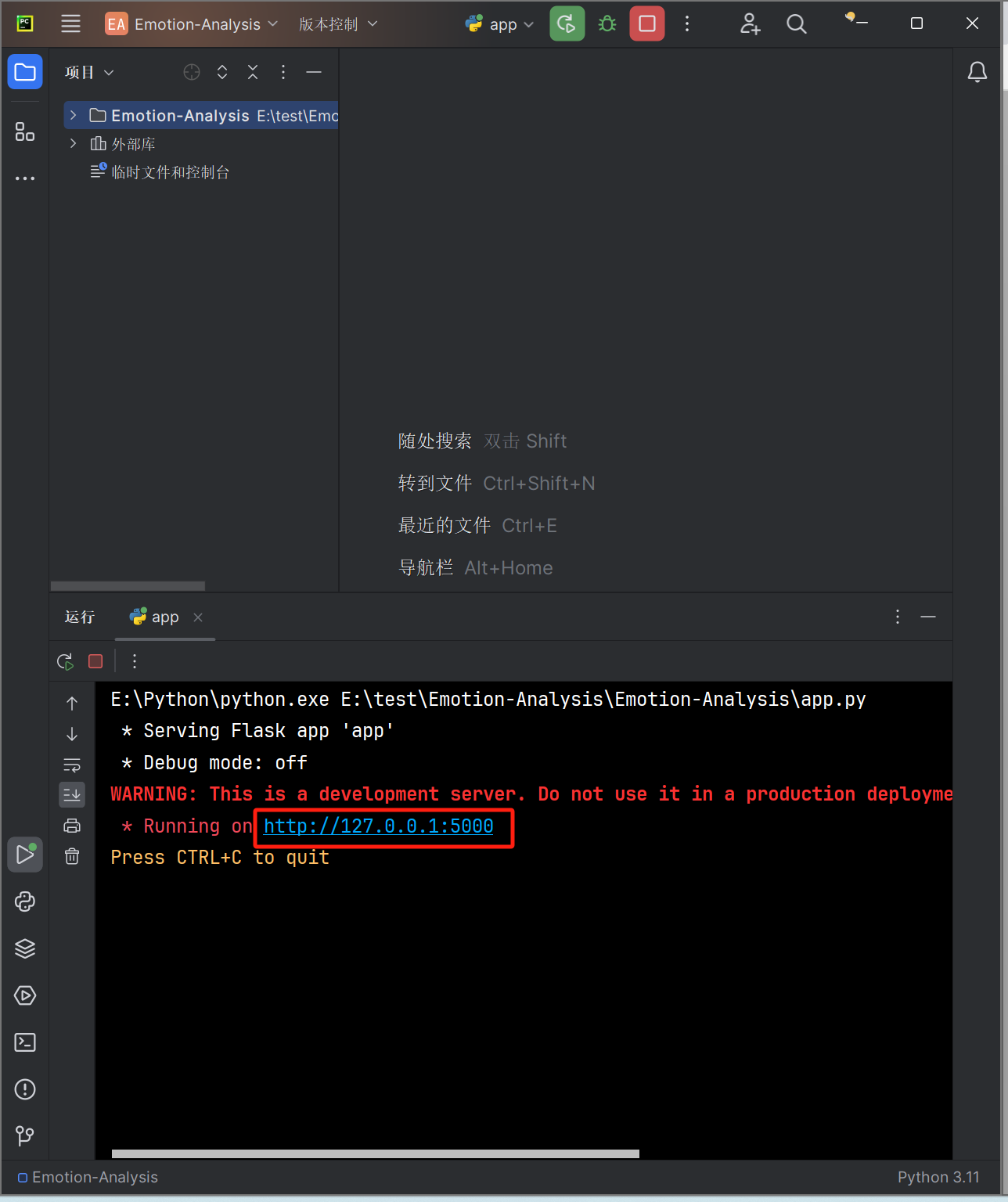
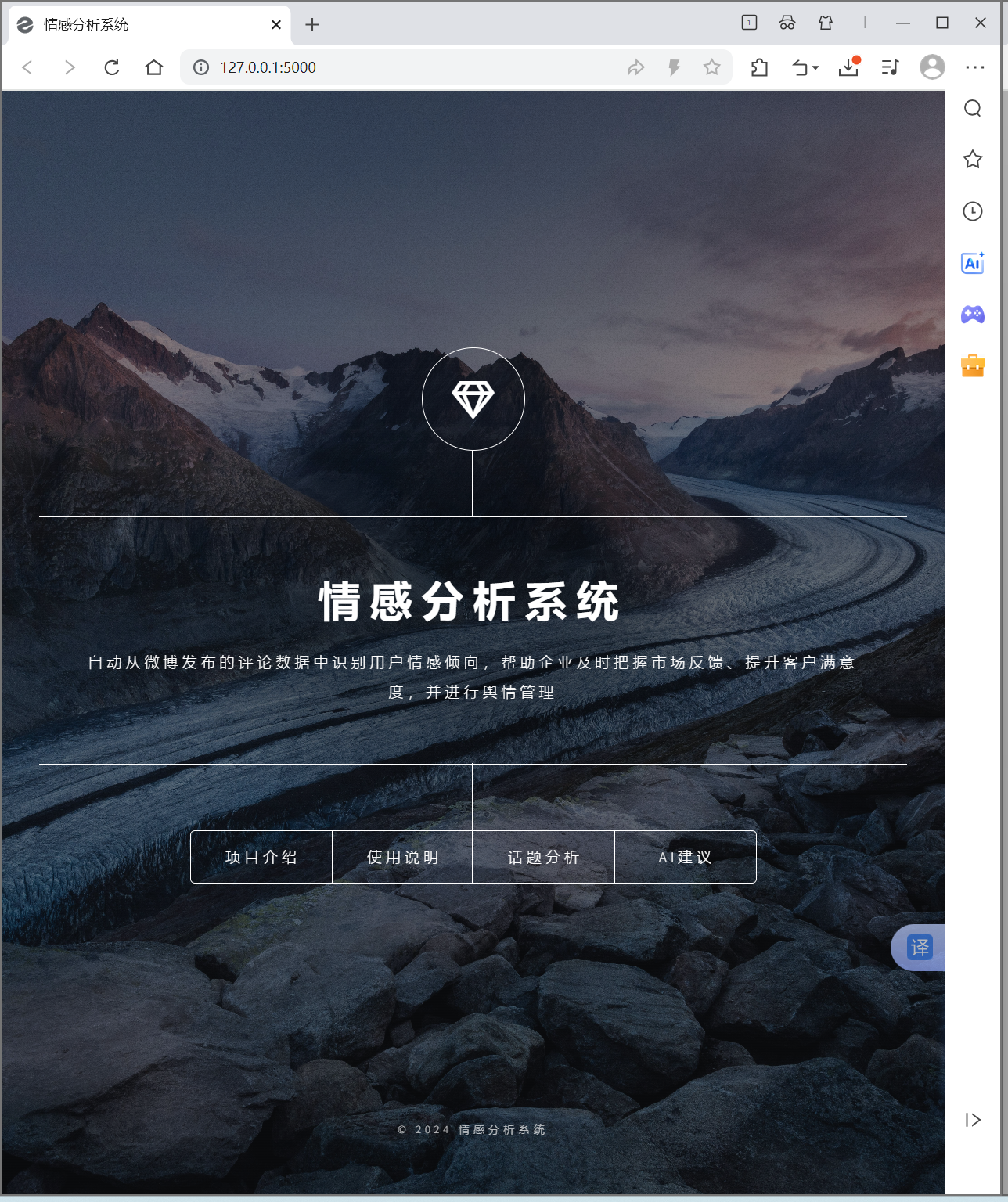
- 默认浏览器将出现“情感分析系统”网页,即可开始使用软件,如图:
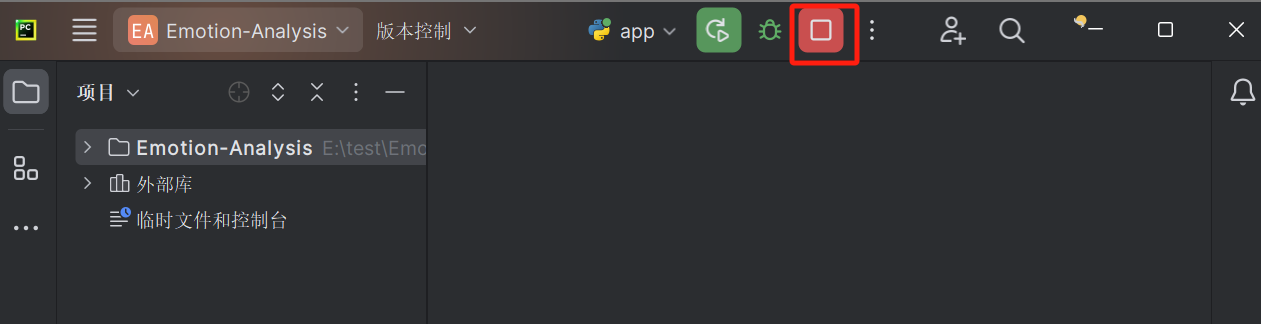
- 如果想要停止使用,则关闭“情感分析系统”网页,如下图软件终止程序,关闭Pycharm应用即可,
*(5)提示
- “话题分析”得出结果的时间难以预测,关键词越普遍,时间长度越长,收集时间越长,请耐心等待
- “话题分析”得出分析结果后点击最下方的“点击查看AI助手建议”可跳转至AI建议,发送“输入信息”框已有的内容,即可得到AI对分析结果的结论与建议
- “话题分析”分析得到的词云图和分布扇形图将保存在Emotion-Analysis pycharm项目文件夹的result文件夹中,可按需取用
- “AI建议”的AI能接收并正确处理恢复的信息最多只能输入1600个中文字符
- “AI建议”输入信息可通过回车发送,回车+shift换行
- 点击网页背景部分可返回首页,如果误点,请不要担心,此时正在进行的“话题分析”或“AI建议”不会因此停止或消失
*(6)“话题分析”中需要输入的Cookie的获取方法
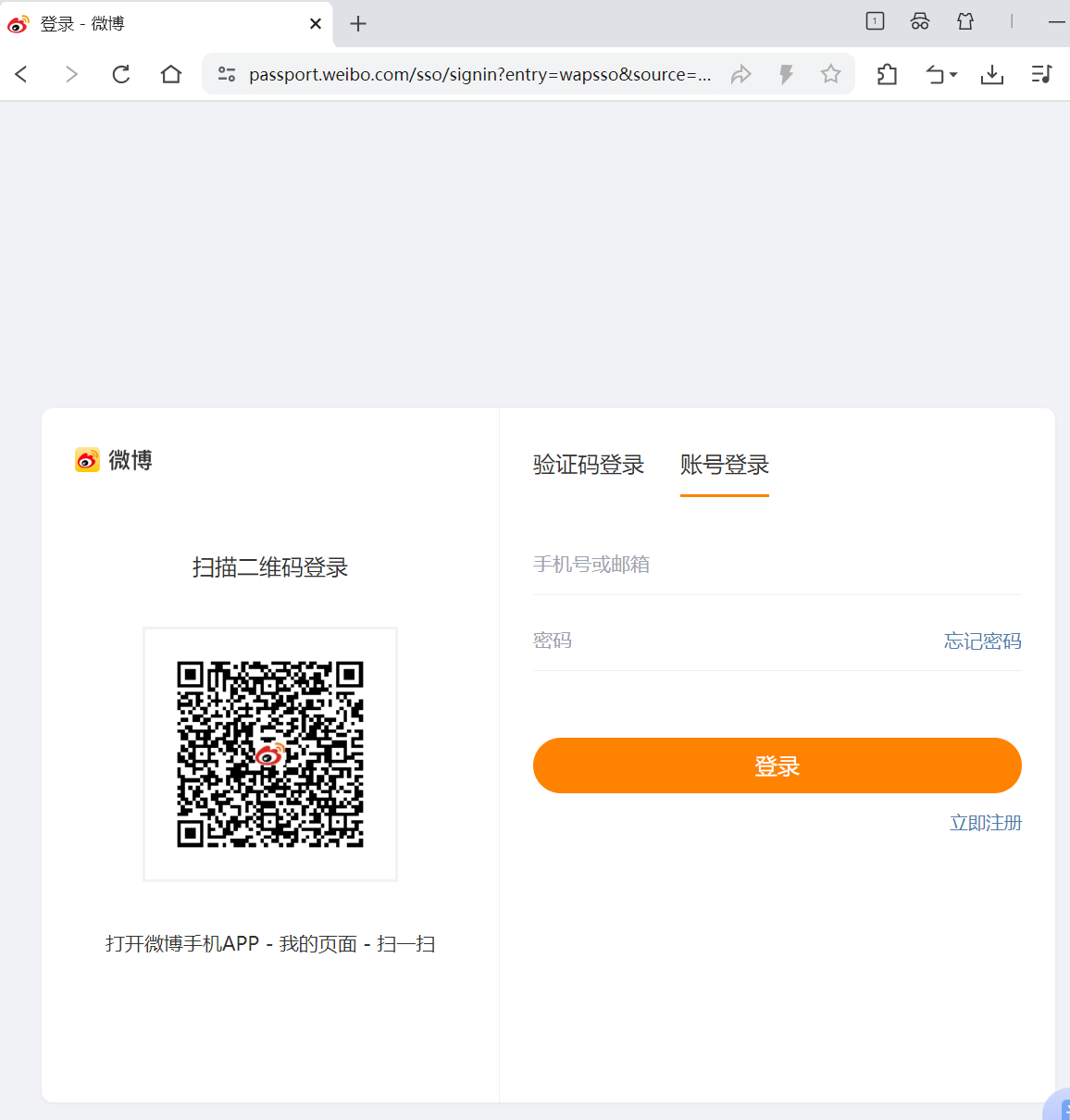
- 打开微博网址
- 点击“登录”,登录微博,如图:
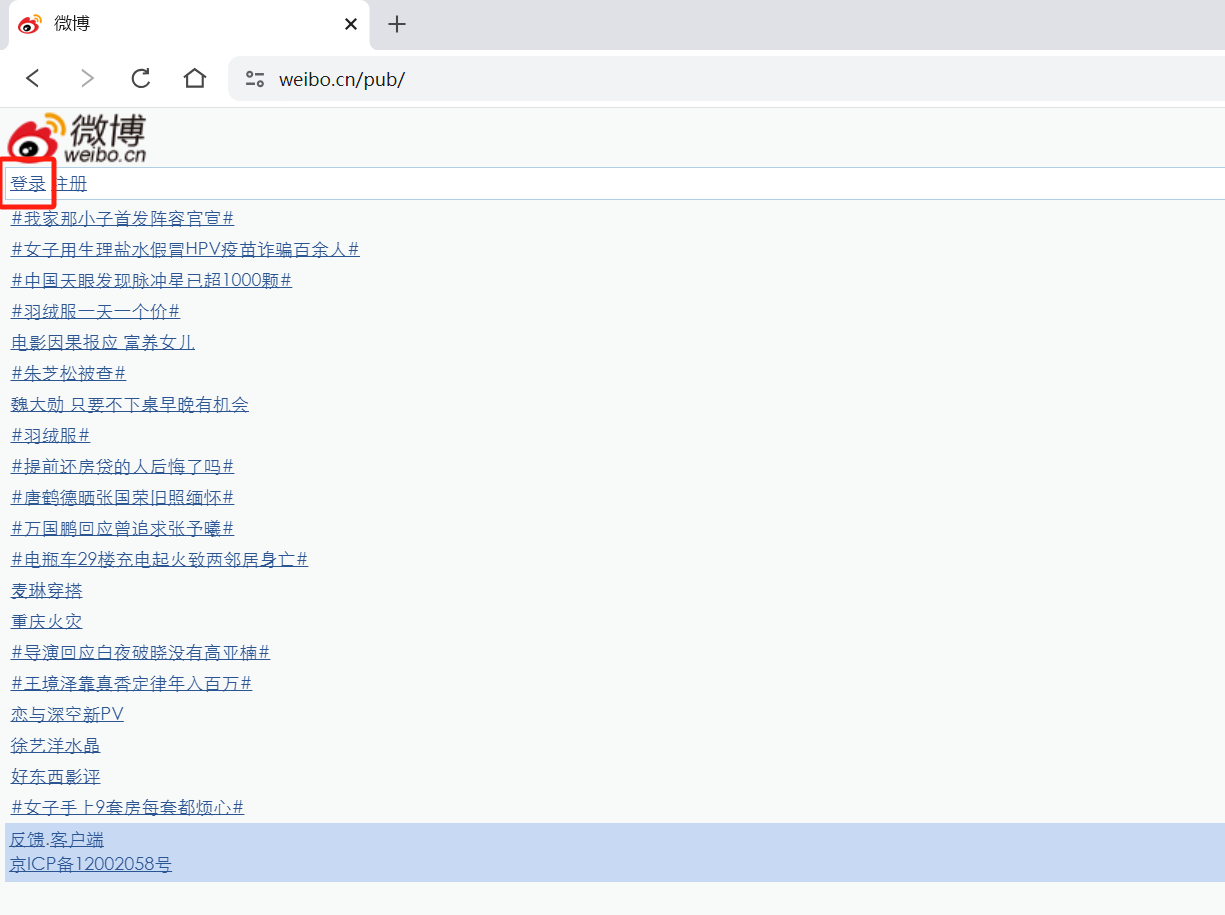 ,
,
- 登录微博后,在微博网址打开浏览器的开发者工具,如图:
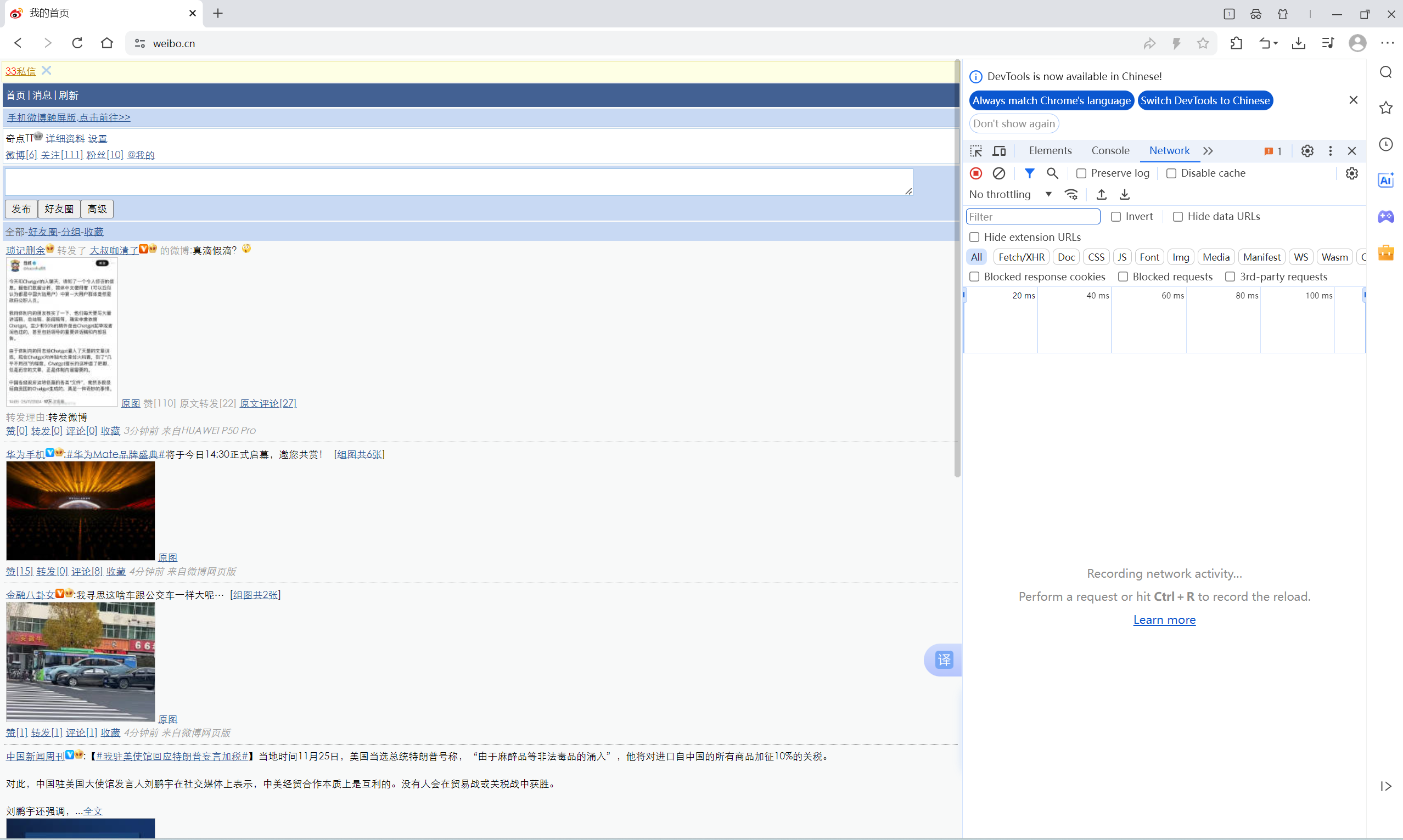
- 保持开发者工具打开,点击“下页”,见图红框:
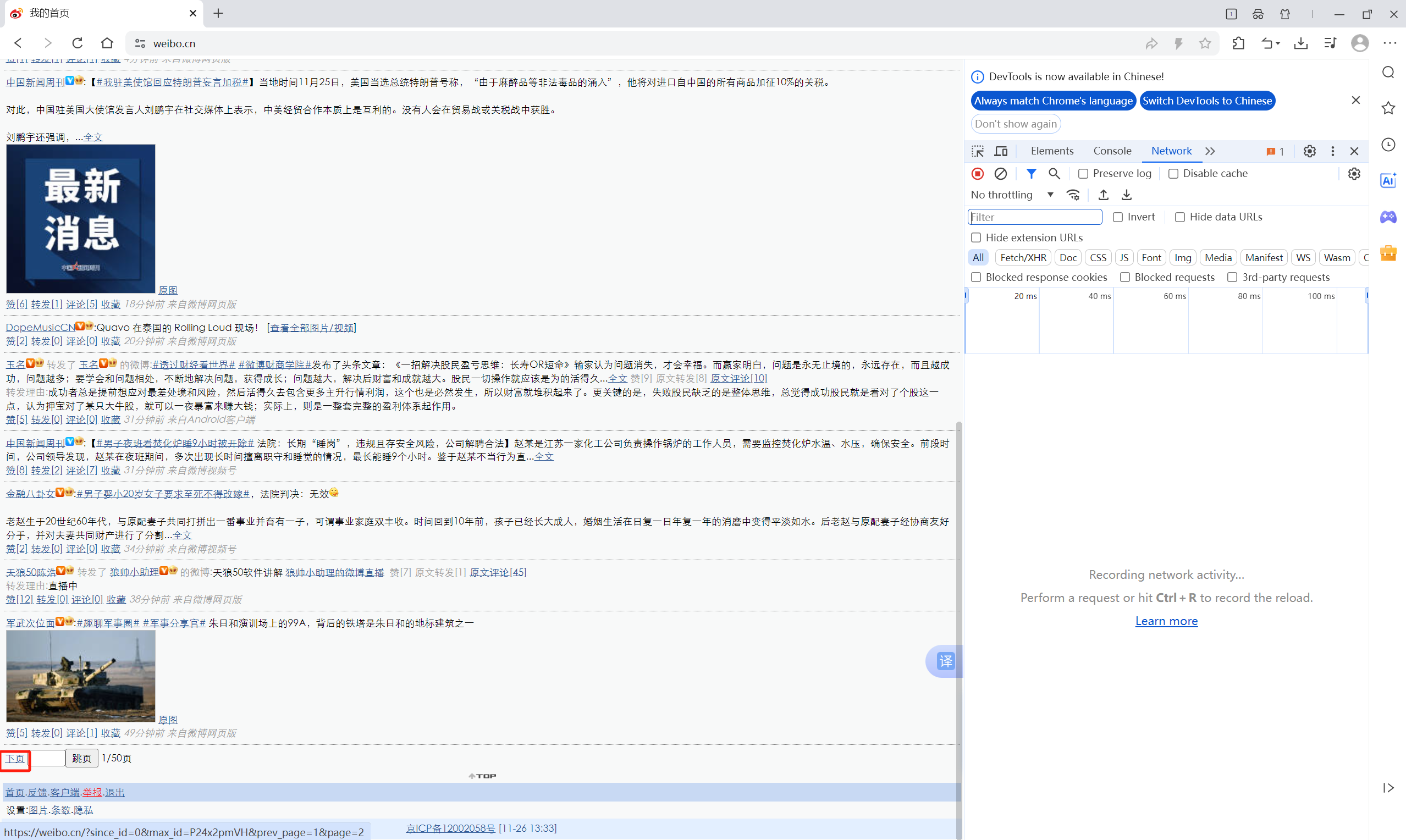
- 选择开发者工具的网络Network,选择Name列表中的第一项,在左侧的请求头Request Headers中找到Cookie对应右侧的值即为需要输入分析系统的Cookie,见下图红框:

2.5、已知问题与限制
- 软件正常运行需要用户安装配置较为复杂的指定的硬件与软件环境
- 处理大量数据会占用较多用户自身电脑配置的内存和计算资源,一旦数据处理规模超出用户自身电脑配置的内存和计算资源则会分析失败
- 情感分析功能得出分析结果需要的时间随用户指定的范围而变化,且难以预测
- AI建议每次消息输入不能超过4096个字符,相当于1600个中文字数
2.6、发布方式及地址
发布方式
- 在github团队项目仓库里中提供可下载,解压后可按照一定使用步骤运行的软件压缩包,并在github团队项目仓库里显示安装与使用方法
发布地址
2.7、发布方式及地址的尝试
尝试的还未成功的发布方式
- 提供可使用软件全部功能的网址
- 已成功将软件项目部署到云服务器上,以网页形式交互,其中用户界面交互都无问题,AI交流功能也正常,但情感分析功能最终的结果上传时请求资源失败,截至目前还未成功解决,因此上交的作业的确定的发布方式只是为软件的压缩包

 浙公网安备 33010602011771号
浙公网安备 33010602011771号