
第7篇Scrum冲刺博客
| 软件工程 | 班级链接 |
|---|---|
| 作业要求 | 作业要求 |
| 作业目标 | 项目冲刺 |
| github仓库 | 团队项目 |
队名:P人大联盟
团队成员
| 姓名 | 学号 |
|---|---|
| 王睿娴 | 3222003968 |
| 张颢严 | 3222004426 |
| 梁恬(组长) | 3222004467 |
| 潘思言 | 3222004423 |
本篇博客目录
4.2、的目录索引无法响应,其子目录可响应
1、Scrum Meeting
1.1、站立式会议照片

1.2、会议总结
| 昨日安排的任务 | 负责成员 | 实际完成情况 | 工作中遇到的困难 |
|---|---|---|---|
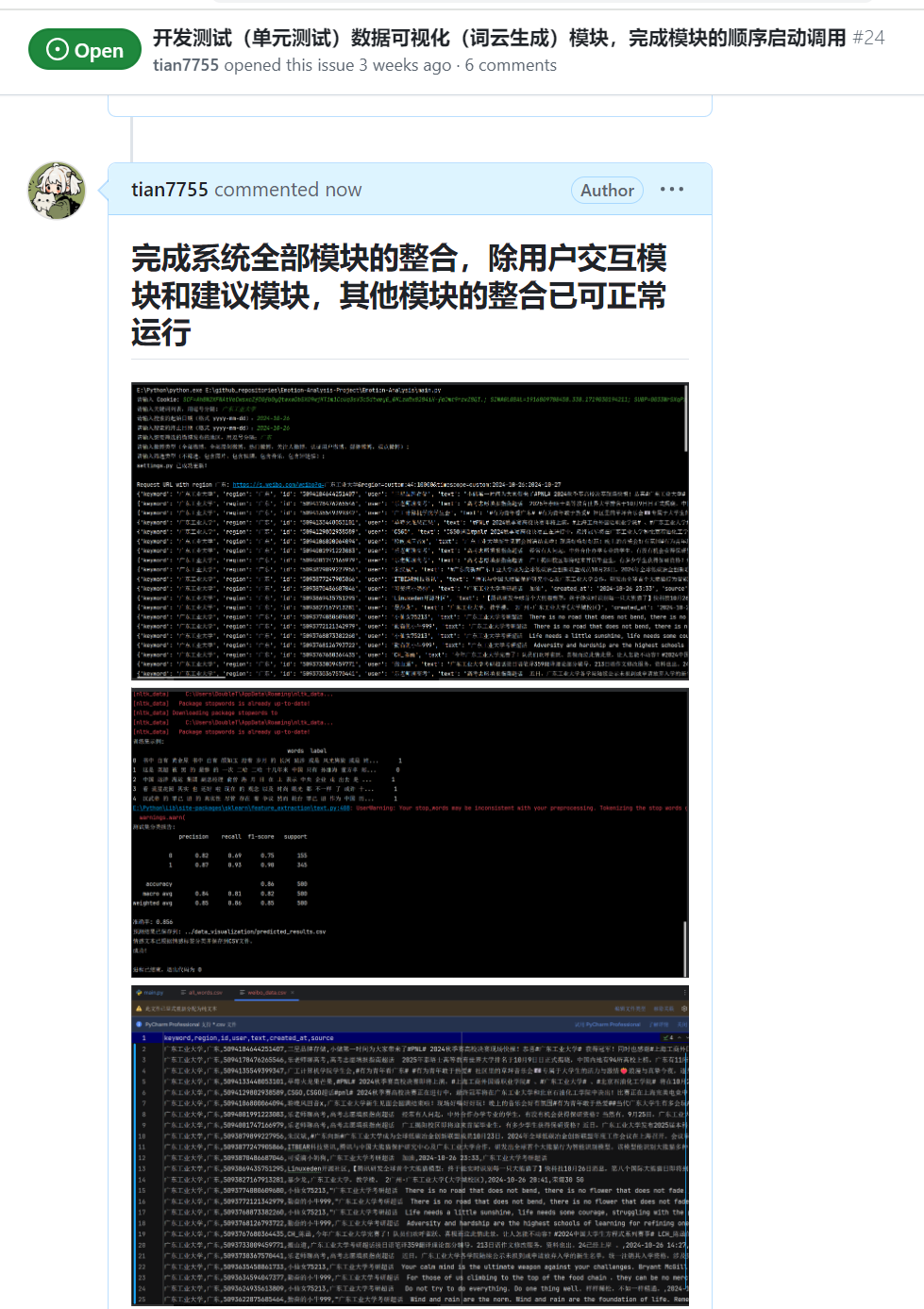
| 完成爬虫,文本预处理和词云生成的调用整合 | 梁恬 | 已完成这三个模块的调用整合,运行也正常 | 不同模块运行时的目录转换 |
| 连接前端输入 | 潘思言 | 基本完成 | 控制台默认编码为GBK导致打印微博内容失败 |
| 微调 bys 模型并优化情感分类准确率 | 张颢严 | 完成 BERT 模型优化及 BYS 模型搭建 | 调试过程中数据预处理效率较低,影响整体运行速度 |
| 标准化微博发布时间 | 王睿娴 | 基本完成 | 时间格式不匹配的问题 |
| 今日计划的任务 | 负责成员 |
|---|---|
| 完成文本预处理模块的数据集和测试集的划分,情感分析模型与系统其他模块的整合,词云样式的最终确定 | 梁恬 |
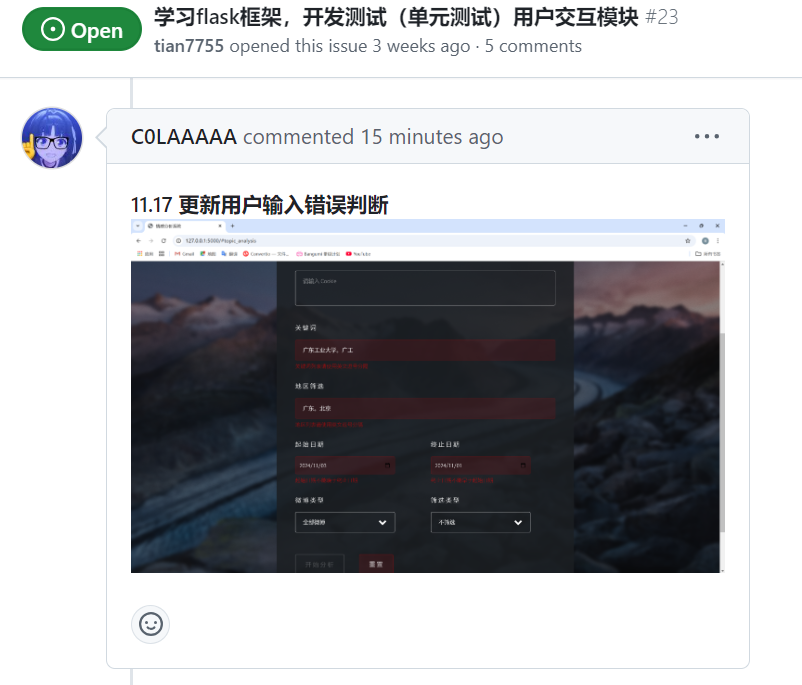
| 实现用户输入差错处理 | 潘思言 |
| 完善 LSTM、SVM、XGBoost 的模型搭建和优化 | 张颢严 |
| 测试 | 王睿娴 |
2、燃尽图
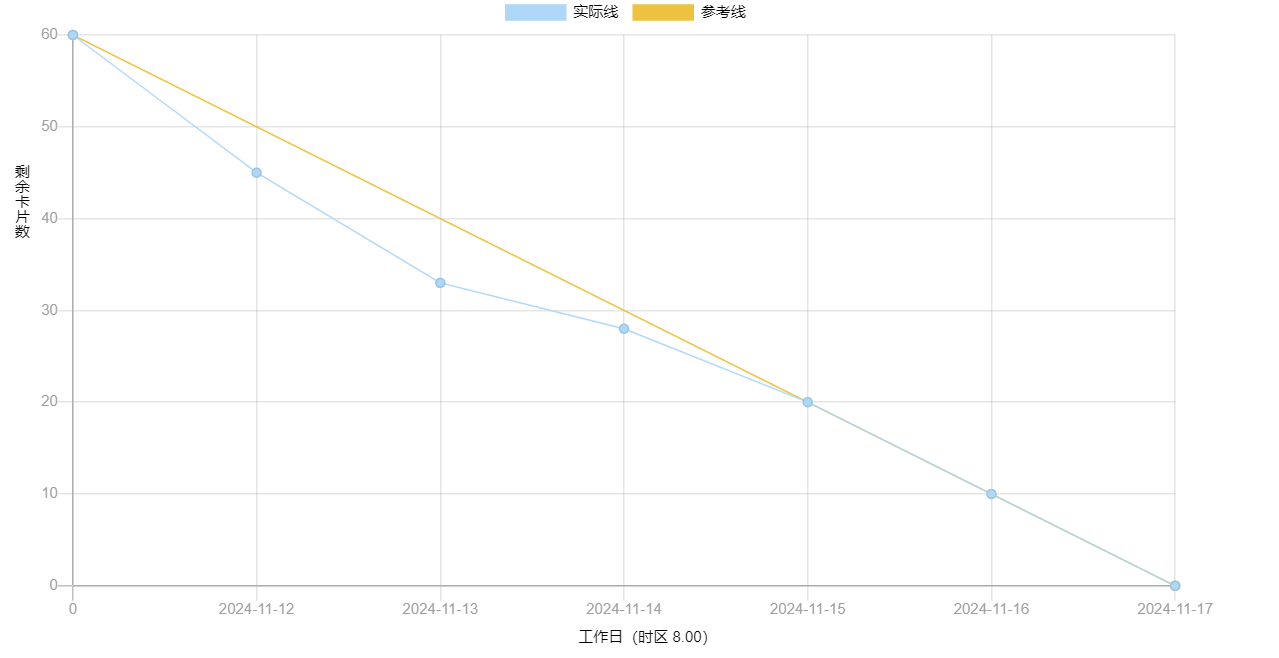
3、代码/文档签入记录
| 团队成员 | 代码/文档签入截图 | 对应的issues内容截图 | 对应的issues链接 |
|---|---|---|---|
| 梁恬 | 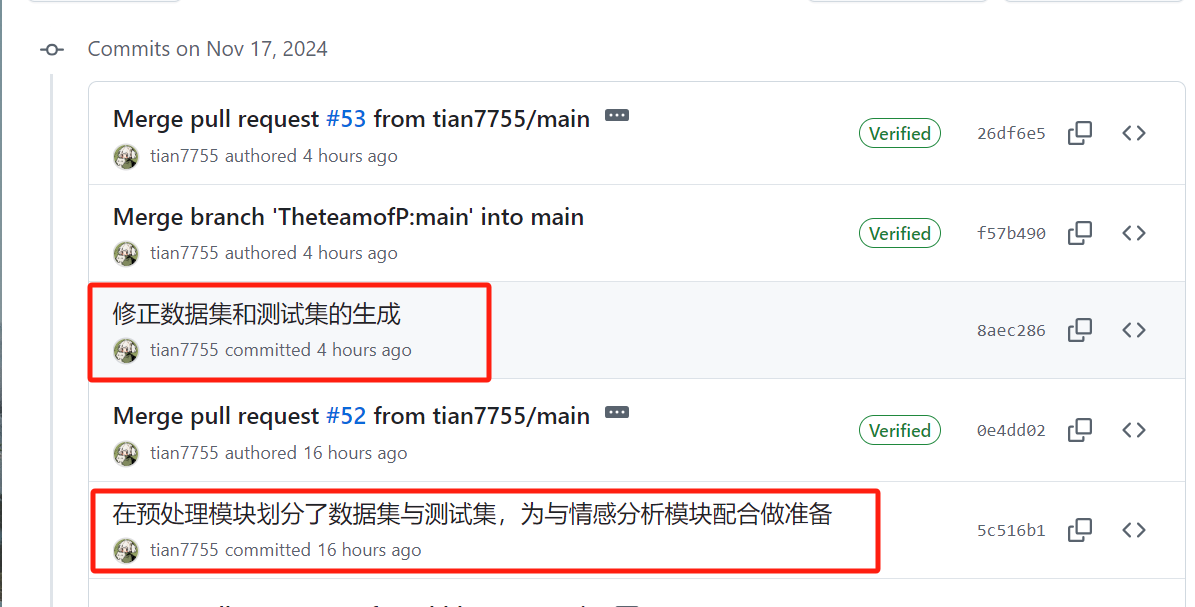 , ,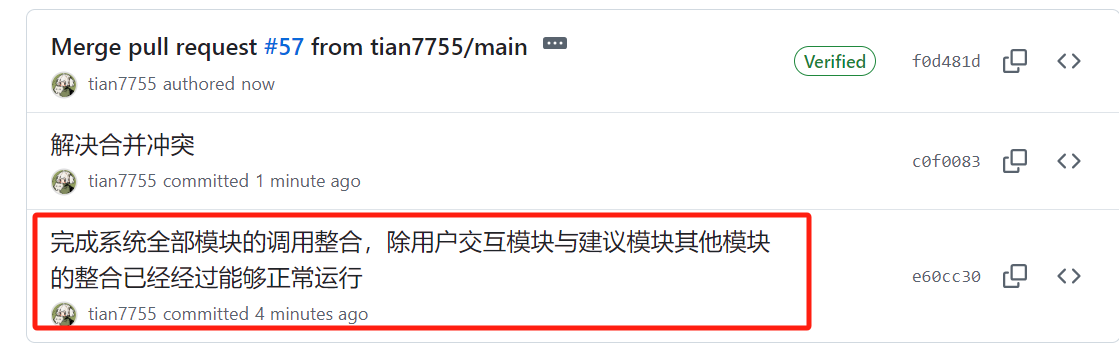 |
 , , |
issues链接1,issues链接2 |
| 潘思言 |  |
 |
issues链接 |
| 张颢严 |  |
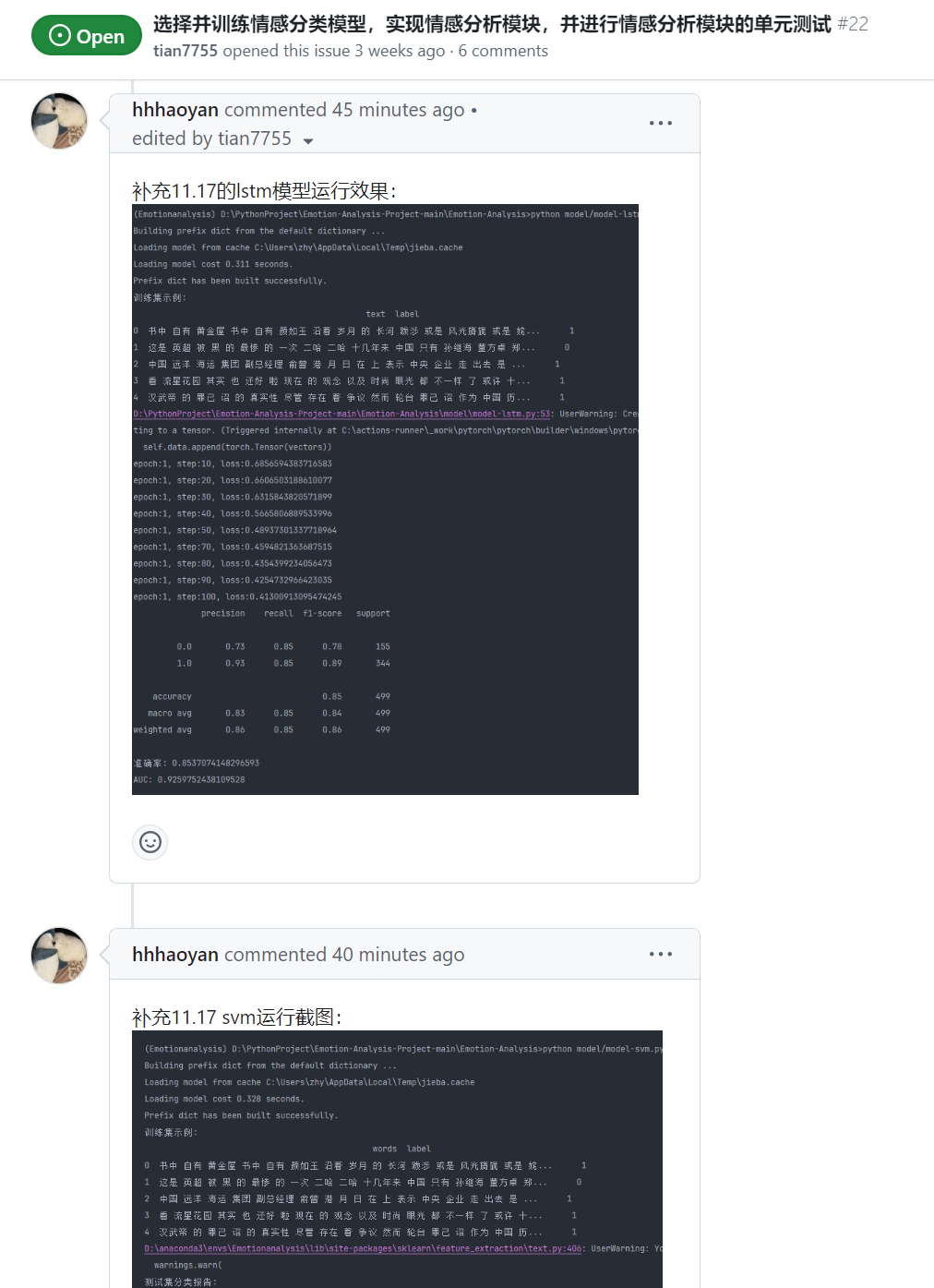 |
issues链接 |
| 王睿娴 | 无 |  |
issues链接 |
当天编码规范文档无更新
4、项目程序/模块的最新
4.1、最新模块的代码
点击查看用户交互模块最新代码
<!-- 话题分析 -->
<article id="topic_analysis">
<h2 class="major">话题分析</h2>
<form id="topicAnalysisForm" method="post">
<div class="fields">
<div class="field">
<label for="topic_cookie">COOKIE</label>
<textarea id="topic_cookie" name="cookie" style="height:100px; resize:none; font-size: medium" placeholder="请输入 Cookie" required></textarea>
<small id="topic_cookieError" class="error-message" style="color: rgba(255, 0, 0, 0.7); display: block; margin-top: 5px; font-size: 0.7em;"></small>
</div>
<div class="field">
<label for="topic_keyword">关键词</label>
<input type="text" id="topic_keyword" name="keyword" value="" placeholder="请输入关键词列表,用英文逗号分隔" style="font-size: medium" required>
<small id="topic_keywordError" class="error-message" style="color: rgba(255, 0, 0, 0.7); display: block; margin-top: 5px; font-size: 0.7em;"></small>
</div>
<div class="field">
<label for="regions">地区筛选</label>
<input type="text" name="regions" id="regions" value="" placeholder="请输入想要筛选的微博发布的地区,用英文逗号分隔" style="font-size: medium" required />
<small id="regionsError" class="error-message" style="color: rgba(255, 0, 0, 0.7); display: block; margin-top: 5px; font-size: 0.7em;"></small>
</div>
<div class="field half">
<label for="start_date">起始日期</label>
<input type="date" name="start_date" id="start_date" value="" placeholder="请输入搜索的起始日期" required />
<small id="start_dateError" class="error-message" style="color: rgba(255, 0, 0, 0.7); display: block; margin-top: 5px; font-size: 0.7em;"></small>
</div>
<div class="field half">
<label for="end_date">终止日期</label>
<input type="date" name="end_date" id="end_date" value="" placeholder="请输入搜索的终止日期" required />
<small id="end_dateError" class="error-message" style="color: rgba(255, 0, 0, 0.7); display: block; margin-top: 5px; font-size: 0.7em;"></small>
</div>
<div class="field half">
<label for="weibo_type_input">微博类型</label>
<select name="weibo_type_input" id="weibo_type_input" style="font-size: medium;width: 80%">
<option value="全部微博">全部微博</option>
<option value="全部原创微博">全部原创微博</option>
<option value="热门微博">热门微博</option>
<option value="关注人微博">关注人微博</option>
<option value="认证用户微博">认证用户微博</option>
<option value="媒体微博">媒体微博</option>
<option value="观点微博">观点微博</option>
</select>
<small id="weibo_type_inputError" class="error-message" style="color: #ff3860; display: block; margin-top: 5px; font-size: 0.7em;"></small>
</div>
<div class="field half">
<label for="contain_type_input">筛选类型</label>
<select name="contain_type_input" id="contain_type_input" style="font-size: medium;width: 80%">
<option value="不筛选">不筛选</option>
<option value="包含图片">包含图片</option>
<option value="包含视频">包含视频</option>
<option value="包含音乐">包含音乐</option>
<option value="包含短链接">包含短链接</option>
</select>
<small id="contain_type_inputError" class="error-message" style="color: #ff3860; display: block; margin-top: 5px; font-size: 0.7em;"></small>
</div>
</div>
<ul class="actions">
<li><button type="submit" id="topic_submit" disabled>开始分析</button></li>
<li><input type="reset" value="重置"/></li>
</ul>
</form>
<div id="topic_result"></div>
</article>
省略部分
$(document).ready(function () {
const submitButton = document.getElementById('topic_submit');
const form = document.getElementById('topicAnalysisForm');
const inputs = form.querySelectorAll('input[required], textarea[required]');
const startDateInput = document.getElementById("start_date");
const endDateInput = document.getElementById("end_date");
// 验证单个字段
function validateField(field) {
const fieldValue = field.value.trim();
const errorElem = document.getElementById(field.id + "Error");
let isValid = true;
// 移除之前的错误样式
field.classList.remove('error');
errorElem.textContent = "";
// 只检查格式错误,不检查空值
if (fieldValue !== "") {
if (field.id === 'topic_keyword') {
// 检查是否包含中文逗号、英文句号或中文句号
if (/[,。.]/.test(fieldValue)) {
errorElem.textContent = "关键词列表请使用英文逗号分隔";
field.classList.add('error');
isValid = false;
}
// 检查格式:不允许连续逗号、开头结尾逗号、空格+逗号或逗号+空格的组合
else if (/(^,|,$|,,|\s,|,\s)/.test(fieldValue)) {
errorElem.textContent = "关键词列表格式不正确,请用英文逗号分隔且避免空项";
field.classList.add('error');
isValid = false;
}
} else if (field.id === 'regions') {
// 检查是否包含中文逗号、英文句号或中文句号
if (/[,。.]/.test(fieldValue)) {
errorElem.textContent = "地区列表请使用英文逗号分隔";
field.classList.add('error');
isValid = false;
}
// 检查格式:不允许连续逗号、开头结尾逗号、空格+逗号或逗号+空格的组合
else if (/(^,|,$|,,|\s,|,\s)/.test(fieldValue)) {
errorElem.textContent = "地区列表格式不正确,请用英文逗号分隔且避免空项";
field.classList.add('error');
isValid = false;
}
}
}
return isValid;
}
// 验证日期
function validateDateFields() {
const startDateErrorElem = document.getElementById("start_dateError");
const endDateErrorElem = document.getElementById("end_dateError");
let isValid = true;
// 清除之前的错误样式和消息
startDateInput.classList.remove('error');
endDateInput.classList.remove('error');
startDateErrorElem.textContent = "";
endDateErrorElem.textContent = "";
// 只在两个日期都有值的情况下才进行比较
if (startDateInput.value && endDateInput.value) {
if (new Date(startDateInput.value) > new Date(endDateInput.value)) {
startDateErrorElem.textContent = "起始日期不能晚于终止日期";
endDateErrorElem.textContent = "终止日期不能早于起始日期";
startDateInput.classList.add('error');
endDateInput.classList.add('error');
isValid = false;
}
}
return isValid;
}
// 检查表单是否可提交
function checkFormValidity() {
let isFormValid = true;
// 检查所有必填字段是否有值
inputs.forEach(input => {
if (!input.value.trim()) {
isFormValid = false;
}
});
// 检查格式错误
inputs.forEach(input => {
if (!validateField(input)) {
isFormValid = false;
}
});
// 检查日期
if (!validateDateFields()) {
isFormValid = false;
}
// 更新提交按钮状态
submitButton.disabled = !isFormValid;
}
// 为所有输入字段添加验证事件监听
inputs.forEach(input => {
input.addEventListener('input', () => {
validateField(input);
checkFormValidity();
});
// 失焦时验证
input.addEventListener('blur', () => {
validateField(input);
checkFormValidity();
});
});
// 为日期输入添加事件监听
[startDateInput, endDateInput].forEach(input => {
input.addEventListener('input', () => {
validateDateFields();
checkFormValidity();
});
input.addEventListener('blur', () => {
validateDateFields();
checkFormValidity();
});
});
// 表单重置处理
form.addEventListener('reset', () => {
// 清除所有错误消息
document.querySelectorAll('.error-message').forEach(elem => {
elem.textContent = "";
});
// 移除所有错误样式
document.querySelectorAll('.error').forEach(elem => {
elem.classList.remove('error');
});
// 禁用提交按钮
submitButton.disabled = true;
// 延迟检查表单有效性,等待重置完成
setTimeout(checkFormValidity, 0);
});
// 页面加载时检查表单有效性
checkFormValidity();
$('#topicAnalysisForm').on('submit', function(event) {
event.preventDefault();
var formData = $(this).serialize();
$.ajax({
type: 'POST',
url: '{{ url_for("page.spider_analysis_topic") }}',
data: formData,
success: function(response) {
console.log("话题分析返回的数据:", response);
if(response.status === 'failed') {
$('#topic_result').html('<h3 class="error">' + response.message + '</h3>');
} else {
// 构建并显示话题分析结果,包括词云图片
let resultHTML = '<h3 class="major">话题分析结果:</h3>';
resultHTML += '<div class="result-content">';
resultHTML += '<p><strong>关键词:</strong> ' + response.result.keyword + '</p>';
resultHTML += '<p><strong>日期范围:</strong> ' + response.result.start_date + '~' + response.result.end_date + '</p>';
resultHTML += '</div>';
// 插入词云图片
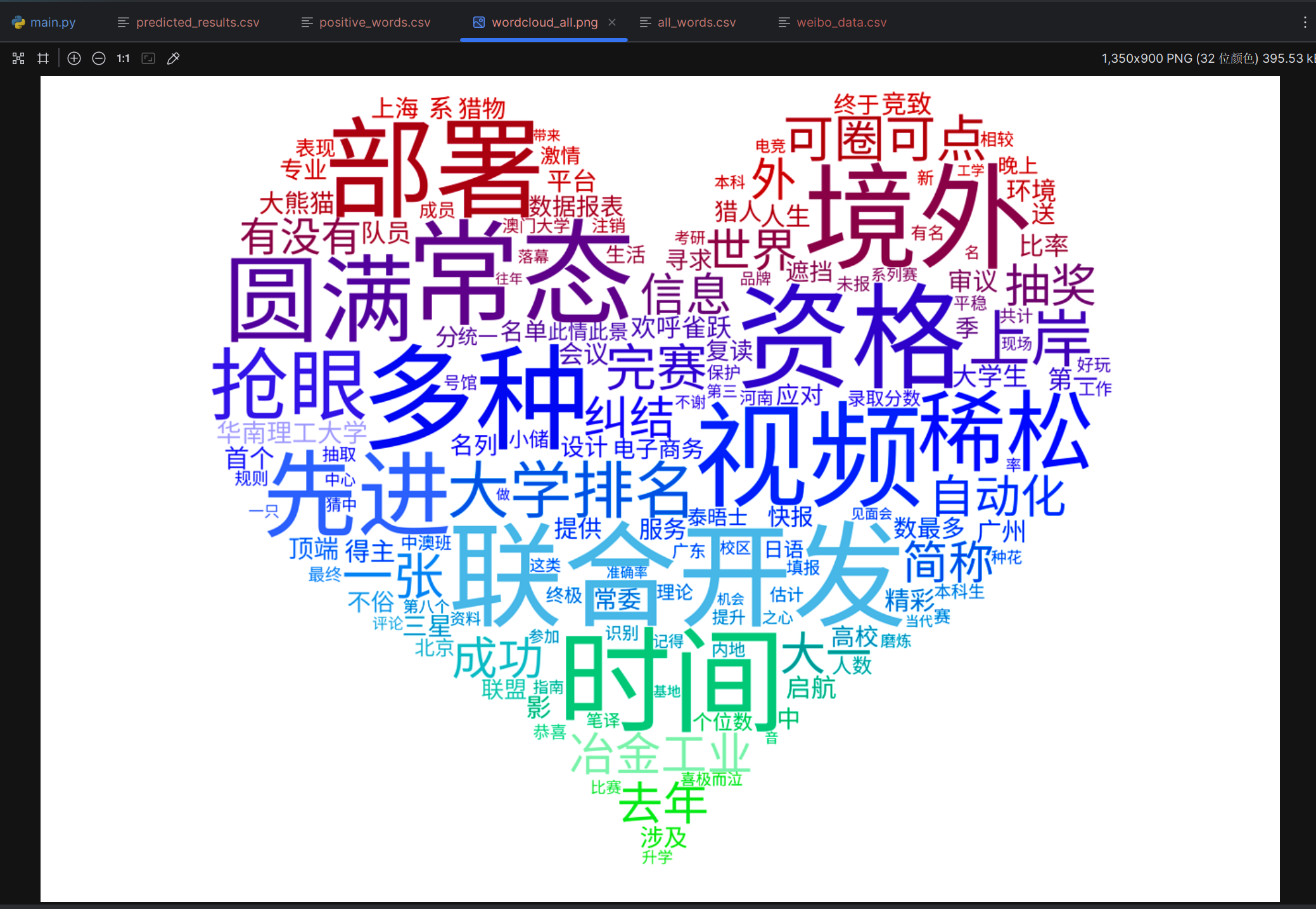
resultHTML += '<h3 class="major">词云展示:</h3>';
resultHTML += '<div class="image-grid">';
resultHTML += '<div class="image"><img src="{{ url_for("static", filename="wordclouds/wordcloud_all.png") }}" alt="词云图" class="wordcloud"></div>';
resultHTML += '</div>';
// 添加按钮
resultHTML += '<button id="gpt_suggest" style="display:block;">点击查看AI助手建议</button>';
$('#topic_result').html(resultHTML);
$('#gpt_suggest').on('click', function() {
var resultText = $('#topic_result .result-content').text();
var suggestionText = "话题分析结果:\n" + resultText + "\n请对此进行分析和建议";
window.open('{{ url_for("home") }}?text=' + encodeURIComponent(suggestionText) + '#gpt_suggestion', '_blank');
});
}
},
error: function(xhr) {
$('#topic_result').html('<h3 class="error">分析失败,请重试</h3>');
}
});
});
});
main.css
.error-message {
color: rgba(255, 0, 0, 0.7);
display: block;
margin-top: 5px;
font-size: 0.8em;
min-height: 1em;
}
input.error, textarea.error, select.error {
border-color: rgba(255, 0, 0, 0.3) !important;
background-color: rgba(255, 0, 0, 0.1) !important;
}
点击查看数据预处理模块最新代码
text_processor.py
import json
import re
import csv
import emoji
import jieba
import unicodedata
from bs4 import BeautifulSoup
from sklearn.model_selection import train_test_split
from nlp.stopwords.get_stopwords import get_stopwords
from data_visualization.logger_config import logger
# 加载爬取数据
def load_scraped_data(csv_path):
data = []
try:
with open(csv_path, 'r', encoding='utf-8-sig') as file:
reader = csv.DictReader(file)
data.extend(reader)
except FileNotFoundError:
logger.error(f"CSV File {csv_path} not found.")
return data
# 将表情转换为中文
def explain_emojis(text):
return emoji.demojize(text, language="zh")
# 中文分词
def cut_words(text):
return " ".join(jieba.cut(text, cut_all=False))
# 清洗url,html
def rm_url_html(text):
soup = BeautifulSoup(text, 'html.parser')
text = soup.get_text()
url_regex = re.compile(
r'(?i)\b((?:https?://|www\d{0,3}[.]|[a-z0-9.\-]+[.][a-z]{2,4}/)'
r'(?:[^\s()<>]+|\(([^\s()<>]+|(\([^\s()<>]+\)))*\))+'
r'(?:\(([^\s()<>]+|(\([^\s()<>]+\)))*\)|[^\s`!()\[\]{};:\'".,'
r'<>?«»“”‘’]))',
re.IGNORECASE)
return re.sub(url_regex, "", text)
# 清洗标点符号和符号
def rm_punctuation_symbols(text):
return ''.join(ch for ch in text if unicodedata.category(ch)[0] not in
['P', 'S'])
# 清洗多余的空行
def rm_extra_linebreaks(text):
lines = text.splitlines()
return '\n'.join(re.sub(r'\s+', ' ', line).strip() for line in lines if line.strip())
# 清洗微博评论无意义字符
def rm_meaningless(text):
text = re.sub('[#\n]*', '', text)
text = text.replace("转发微博", "")
text = re.sub(r"\s+", " ", text)
text = re.sub(r"(回复)?(//)?\s*@\S*?\s*(:| |$)", " ", text)
return text.strip()
# 清洗英文跟数字
def rm_english_number(text):
return re.sub(r'[a-zA-Z0-9]+', '', text)
# 清洗为只有中文
def keep_only_chinese(text):
chinese_pattern = re.compile(u"[\u4e00-\u9fa5]+")
return ''.join(chinese_pattern.findall(text))
# 移除停用词
def rm_stopwords(words):
stopwords = get_stopwords()
return [word for word in words if word.strip() and word not in stopwords]
# 数据清洗
def clean(text):
text = explain_emojis(text)
text = rm_url_html(text)
text = rm_punctuation_symbols(text)
text = rm_extra_linebreaks(text)
text = rm_meaningless(text)
text = rm_english_number(text)
text = keep_only_chinese(text)
return text.strip()
# 数据预处理
def process_data(data_list):
all_texts = []
all_data = [] # 用于存储所有数据,包括文本和其他键值对
all_words = set()
for item in data_list:
text_value = item.get('text', '')
text_value = clean(text_value)
words = rm_stopwords(cut_words(text_value).split())
item.pop('id', None)
item.pop('user', None)
item['sentiment_label'] = None
item['sentiment_score'] = 0
cleaned_item = item.copy() # 创建字典的副本以避免修改原始数据
cleaned_item['text'] = " ".join(words)
all_texts.append(cleaned_item['text'])
all_data.append(cleaned_item) # 存储清理后的数据项
all_words.update(words)
# 生成索引并划分数据集和测试集
train_indices, test_indices = train_test_split(
range(len(all_data)), test_size=0.2, random_state=42)
# 使用索引来划分数据
train_data = [all_data[i] for i in train_indices]
test_data = [all_data[i] for i in test_indices]
# 提取训练集和测试集的文本
train_texts = [item['text'] for item in train_data]
test_texts = [item['text'] for item in test_data]
return list(all_words), train_data, test_data, train_texts, test_texts
# 存储整体文本数据字典给情感模型
def save_to_csv(data_list, csv_file_path, fieldnames):
with open(csv_file_path, 'w', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(data_list)
# 存储整体文本数据(已分词版)给词云生成
def save_words_to_csv(words, csv_file_path):
with open(csv_file_path, 'w', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
for word in words:
writer.writerow([word])
# 文本预处理
def text_processor():
csv_file_path = '../weibo_crawler/weibo_data.csv'
data_list = load_scraped_data(csv_file_path)
if data_list:
# all_texts
all_words, train_data, test_data, train_texts, test_texts = process_data(data_list)
# 保存训练集和测试集
save_words_to_csv(train_texts, '../model/train_texts.csv')
save_words_to_csv(test_texts, '../model/test_texts.csv')
save_to_csv(train_data, '../model/train_data.csv',
['keyword', 'region', 'text', 'created_at',
'source', 'sentiment_label', 'sentiment_score'])
save_to_csv(test_data, '../model/test_data.csv',
['keyword', 'region', 'text', 'created_at',
'source', 'sentiment_label', 'sentiment_score'])
save_words_to_csv(all_words, '../data_visualization'
'/all_words.csv')
if __name__ == "__main__":
text_processor()
点击查看情感分析模块最新代码
LSTM
import pandas as pd
import torch
from torch import nn
from torch.nn.utils.rnn import pad_sequence
from torch.utils.data import Dataset, DataLoader
from gensim import models
from sklearn import metrics
from utils import load_corpus, stopwords, processing
# 设置文件路径
TRAIN_PATH = "./data/weibo2018/train.txt"
TEST_PATH = "./data/weibo2018/test.txt"
PREDICT_PATH = "model/labeled_comments.csv"
if __name__ == "__main__":
# 加载训练集和测试集
train_data = load_corpus(TRAIN_PATH)
test_data = load_corpus(TEST_PATH)
# 将数据转换为 DataFrame
df_train = pd.DataFrame(train_data, columns=["text", "label"])
df_test = pd.DataFrame(test_data, columns=["text", "label"])
# 打印训练数据预览
print("训练集示例:")
print(df_train.head())
# Word2Vec 输入格式:list(word)
wv_input = df_train['text'].map(lambda s: [w for w in s.split(" ") if w not in stopwords])
# 训练 Word2Vec 模型
word2vec = models.Word2Vec(wv_input, vector_size=64, min_count=1, epochs=1000)
# 使用设备判断来选择 CPU 或 GPU
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# 超参数设置
learning_rate = 5e-4
num_epoches = 5
batch_size = 100
embed_size = 64
hidden_size = 64
num_layers = 2
# 定义数据集类
class MyDataset(Dataset):
def __init__(self, df):
self.data = []
self.label = []
for s, label in zip(df["text"].tolist(), df["label"].tolist()):
vectors = [word2vec.wv[w] for w in s.split(" ") if w in word2vec.wv.key_to_index]
if len(vectors) > 0: # 仅保留非空序列
self.data.append(torch.Tensor(vectors))
self.label.append(label)
def __getitem__(self, index):
return self.data[index], self.label[index]
def __len__(self):
return len(self.label)
# 自定义 batch 处理函数
def collate_fn(data):
# 过滤掉空序列
data = [item for item in data if len(item[0]) > 0]
if len(data) == 0: # 确保批次中有数据
raise ValueError("所有样本均为空序列,请检查数据处理逻辑。")
data.sort(key=lambda x: len(x[0]), reverse=True) # 按序列长度降序排列
data_length = [len(sq[0]) for sq in data]
x = [i[0] for i in data]
y = [i[1] for i in data]
data = pad_sequence(x, batch_first=True, padding_value=0)
return data, torch.tensor(y, dtype=torch.float32), data_length
# 创建训练集与测试集
train_data = MyDataset(df_train)
train_loader = DataLoader(train_data, batch_size=batch_size, collate_fn=collate_fn, shuffle=True)
test_data = MyDataset(df_test)
test_loader = DataLoader(test_data, batch_size=batch_size, collate_fn=collate_fn, shuffle=False)
# 定义 LSTM 模型
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers):
super(LSTM, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True, bidirectional=True)
self.fc = nn.Linear(hidden_size * 2, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x, lengths):
h0 = torch.zeros(self.num_layers * 2, x.size(0), self.hidden_size).to(device)
c0 = torch.zeros(self.num_layers * 2, x.size(0), self.hidden_size).to(device)
packed_input = torch.nn.utils.rnn.pack_padded_sequence(input=x, lengths=lengths, batch_first=True)
packed_out, (h_n, h_c) = self.lstm(packed_input, (h0, c0))
lstm_out = torch.cat([h_n[-2], h_n[-1]], 1)
out = self.fc(lstm_out)
out = self.sigmoid(out)
return out
# 实例化模型
lstm = LSTM(embed_size, hidden_size, num_layers).to(device)
# 定义损失函数与优化器
criterion = nn.BCELoss()
optimizer = torch.optim.Adam(lstm.parameters(), lr=learning_rate)
# 测试函数
def test():
lstm.eval()
y_pred, y_true = [], []
with torch.no_grad():
for x, labels, lengths in test_loader:
x = x.to(device)
outputs = lstm(x, lengths)
outputs = outputs.view(-1)
y_pred.append(outputs)
y_true.append(labels)
y_prob = torch.cat(y_pred)
y_true = torch.cat(y_true)
y_pred_bin = (y_prob > 0.5).int()
print(metrics.classification_report(y_true, y_pred_bin))
print("准确率:", metrics.accuracy_score(y_true, y_pred_bin))
print("AUC:", metrics.roc_auc_score(y_true, y_prob))
# 训练过程
for epoch in range(num_epoches):
lstm.train()
total_loss = 0
for i, (x, labels, lengths) in enumerate(train_loader):
x = x.to(device)
labels = labels.to(device)
outputs = lstm(x, lengths)
logits = outputs.view(-1)
loss = criterion(logits, labels)
total_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 10 == 0:
print(f"epoch:{epoch + 1}, step:{i + 1}, loss:{total_loss / 10}")
total_loss = 0
# 测试并保存模型
test()
model_path = f"./model/lstm_{epoch + 1}.model"
torch.save(lstm.state_dict(), model_path)
print(f"Saved model: {model_path}")
# 从 CSV 文件预测
predict_df = pd.read_csv(PREDICT_PATH)
if "text" not in predict_df.columns:
raise ValueError("CSV 文件中必须包含 'text' 列")
predict_texts = []
for s in predict_df["text"].apply(processing).tolist():
vectors = [word2vec.wv[w] for w in s.split(" ") if w in word2vec.wv.key_to_index]
predict_texts.append(torch.Tensor(vectors))
x, _, lengths = collate_fn(list(zip(predict_texts, [-1] * len(predict_texts))))
x = x.to(device)
outputs = lstm(x, lengths)
outputs = outputs.view(-1).tolist()
predict_df["prediction"] = outputs
output_path = "model/predict/lstm.csv"
predict_df.to_csv(output_path, index=False, encoding="utf-8")
print(f"预测结果已保存到: {output_path}")
SVM:
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn import svm
from sklearn import metrics
from utils import load_corpus, stopwords, processing
# 文件路径
TRAIN_PATH = "./data/weibo2018/train.txt"
TEST_PATH = "./data/weibo2018/test.txt"
PREDICT_PATH = "model/labeled_comments.csv"
if __name__ == "__main__":
# 加载训练集和测试集
train_data = load_corpus(TRAIN_PATH)
test_data = load_corpus(TEST_PATH)
# 将训练集和测试集转换为 DataFrame
df_train = pd.DataFrame(train_data, columns=["words", "label"])
df_test = pd.DataFrame(test_data, columns=["words", "label"])
# 查看训练集数据
print("训练集示例:")
print(df_train.head())
# 使用 TfidfVectorizer 对文本进行向量化
vectorizer = TfidfVectorizer(token_pattern=r'\[?\w+\]?', stop_words=stopwords)
# 转换训练集文本为特征向量
X_train = vectorizer.fit_transform(df_train["words"])
y_train = df_train["label"]
# 转换测试集文本为特征向量
X_test = vectorizer.transform(df_test["words"])
y_test = df_test["label"]
# 使用 SVM 训练模型
clf = svm.SVC()
clf.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = clf.predict(X_test)
# 输出测试集效果评估
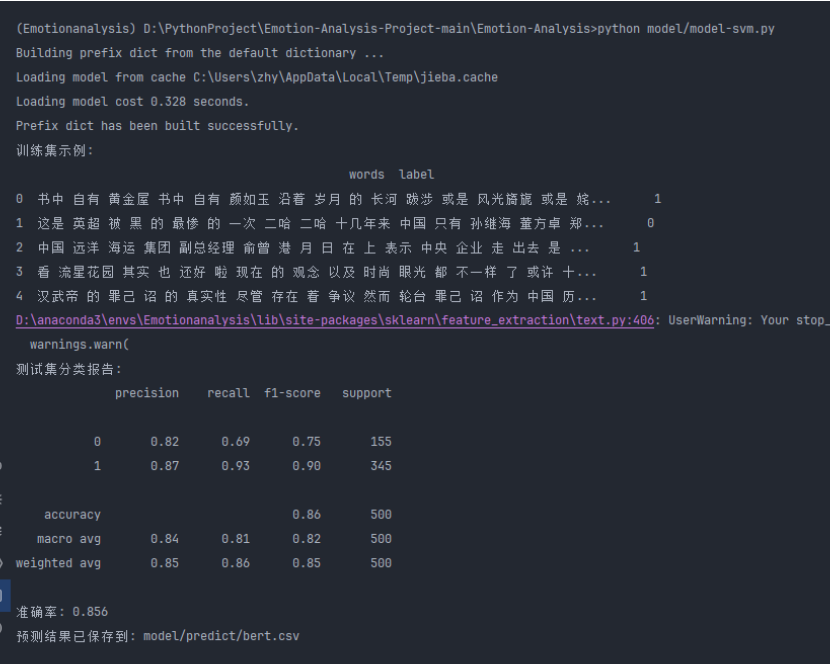
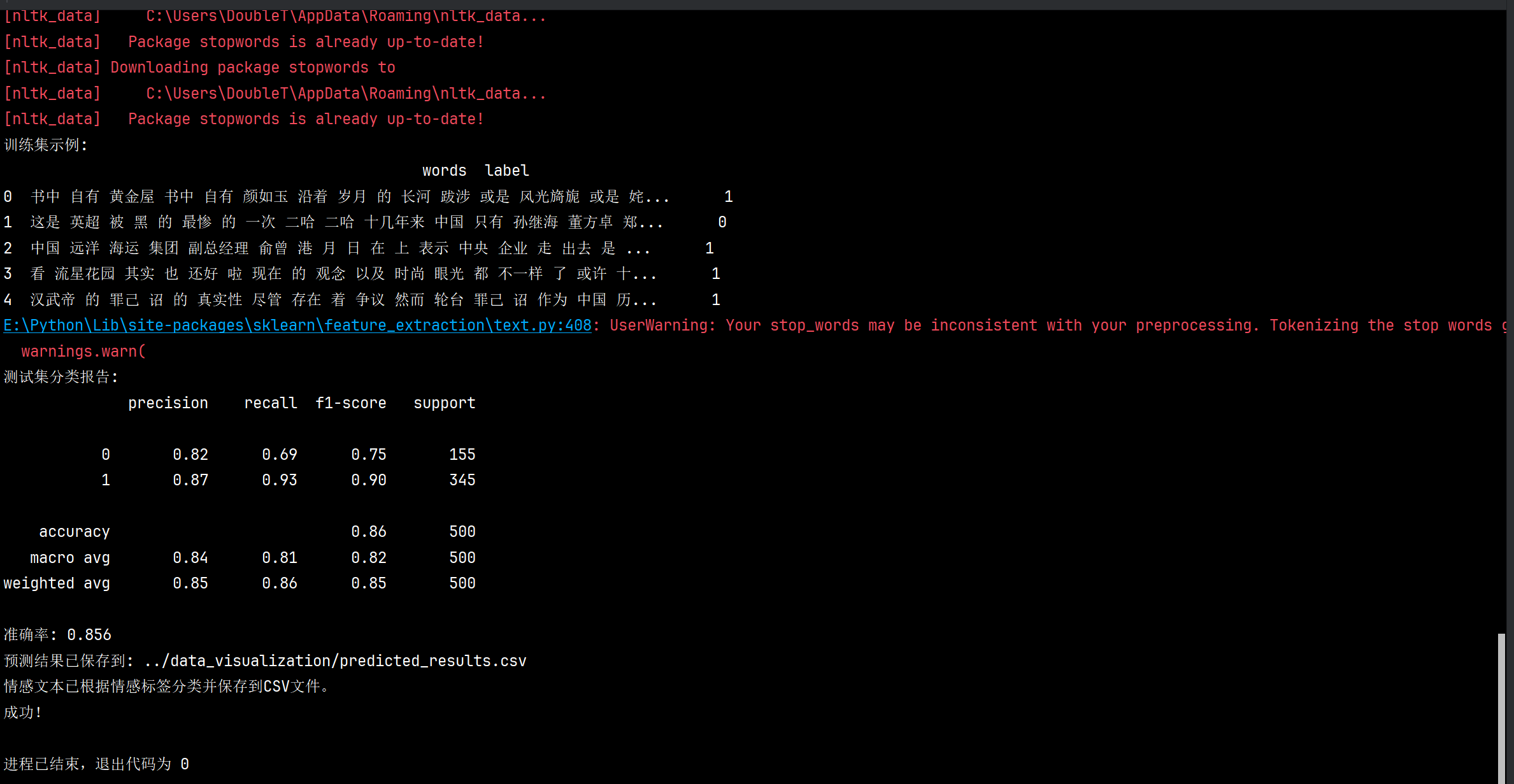
print("测试集分类报告:")
print(metrics.classification_report(y_test, y_pred))
print("准确率:", metrics.accuracy_score(y_test, y_pred))
# 从 CSV 文件加载预测文本
predict_df = pd.read_csv(PREDICT_PATH)
# 确保测试文本列存在并进行预处理
if "Comment" not in predict_df.columns:
raise ValueError("CSV 文件中必须包含 'Comment' 列")
predict_texts = predict_df["Comment"].apply(processing).tolist()
# 转换测试文本为特征向量
vec = vectorizer.transform(predict_texts)
# 预测并输出结果
predictions = clf.predict(vec)
predict_df["prediction"] = predictions
# 保存预测结果到 CSV 文件
output_path = "model/predict/svm.csv"
predict_df.to_csv(output_path, index=False, encoding="utf-8")
print(f"预测结果已保存到: {output_path}")
XBG
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn import metrics
import xgboost as xgb
from utils import load_corpus, stopwords, processing
# 文件路径
TRAIN_PATH = "./data/weibo2018/train.txt"
TEST_PATH = "./data/weibo2018/test.txt"
PREDICT_PATH = "model/labeled_comments.csv"
if __name__ == "__main__":
# 加载训练集和测试集
train_data = load_corpus(TRAIN_PATH)
test_data = load_corpus(TEST_PATH)
# 将训练集和测试集转换为 DataFrame
df_train = pd.DataFrame(train_data, columns=["words", "label"])
df_test = pd.DataFrame(test_data, columns=["words", "label"])
# 查看训练集数据
print("训练集示例:")
print(df_train.head())
# 使用 CountVectorizer 对文本进行向量化
vectorizer = CountVectorizer(token_pattern=r'\[?\w+\]?', stop_words=stopwords, max_features=2000)
# 转换训练集文本为特征向量
X_train = vectorizer.fit_transform(df_train["words"])
y_train = df_train["label"]
# 转换测试集文本为特征向量
X_test = vectorizer.transform(df_test["words"])
y_test = df_test["label"]
# 使用 XGBoost 训练模型
param = {
'booster': 'gbtree',
'max_depth': 6,
'scale_pos_weight': 0.5,
'colsample_bytree': 0.8,
'objective': 'binary:logistic',
'eval_metric': 'error',
'eta': 0.3,
'nthread': 10,
}
# 创建 DMatrix
dmatrix_train = xgb.DMatrix(X_train.tocsr(), label=y_train)
model = xgb.train(param, dmatrix_train, num_boost_round=200)
# 在测试集上用模型预测结果
dmatrix_test = xgb.DMatrix(X_test.tocsr())
y_pred = model.predict(dmatrix_test)
# 测试集效果检验
# 计算 AUC
auc_score = metrics.roc_auc_score(y_test, y_pred)
# 将预测概率转换为 0/1
y_pred_binary = (y_pred > 0.5).astype(int)
# 打印分类报告和其他指标
print(metrics.classification_report(y_test, y_pred_binary))
print("准确率:", metrics.accuracy_score(y_test, y_pred_binary))
print("AUC:", auc_score)
# 从 CSV 文件加载预测文本
predict_df = pd.read_csv(PREDICT_PATH)
# 确保测试文本列存在并进行预处理
if "Comment" not in predict_df.columns:
raise ValueError("CSV 文件中必须包含 'Comment' 列")
predict_texts = predict_df["Comment"].apply(processing).tolist()
# 转换预测文本为特征向量
vec = vectorizer.transform(predict_texts)
# 转换为 DMatrix
dmatrix = xgb.DMatrix(vec)
# 预测并输出结果
predictions = model.predict(dmatrix)
predict_df["prediction"] = predictions
# 保存预测结果到 CSV 文件
output_path = "model/predict/xbg.csv"
predict_df.to_csv(output_path, index=False, encoding="utf-8")
print(f"预测结果已保存到: {output_path}")
点击查看系统整合调用代码
main.py
import os
import subprocess
from weibo_crawler.weibo_crawler.update_settings import main
from nlp.text_processor import text_processor
from model.model_svm import model_svm
from data_visualization.logger_config import logger
from data_visualization.classification import classifcation
from data_visualization.wordcloud_generator import wordclouds_generator
# 改变运行目录并执行对应模块函数
def change_directory_and_execute(original_dir, directory, func, *args,
is_scrapy):
try:
os.chdir(os.path.join(original_dir, directory))
func(*args)
if is_scrapy:
try:
subprocess.run(['scrapy', 'crawl', 'search'], check=True)
except subprocess.CalledProcessError as e:
logger.error(f"Error executing Scrapy command: {e}")
except Exception as e:
logger.error(f"Error in {directory}: {e}")
return False
finally:
os.chdir(original_dir)
return True
# 整合调用各个模块
def emotion_analyzer(cookie, keywords, start_date, end_date, regions,
weibo_type_input, contain_type_input):
# 保存原始目录
original_dir = os.getcwd()
if not change_directory_and_execute(original_dir, 'weibo_crawler',
main, cookie, keywords,
start_date, end_date, regions,
weibo_type_input, contain_type_input,
is_scrapy=True):
return None
if not change_directory_and_execute(original_dir, 'nlp',
text_processor,
is_scrapy=False):
return None
if not change_directory_and_execute(original_dir, 'model',
model_svm, is_scrapy=False):
return None
if not change_directory_and_execute(original_dir, 'data_visualization',
classifcation, is_scrapy=False):
return None
if not change_directory_and_execute(original_dir,
'data_visualization',
wordclouds_generator, is_scrapy=False):
return None
logger.info("Emotion analysis completed successfully")
return 1
if __name__ == "__main__":
# 调试测试用
user_cookie = input("请输入 Cookie: ")
user_keywords = input("请输入关键词列表,用逗号分隔: ")
user_start_date = input("请输入搜索的起始日期(格式 yyyy-mm-dd):")
user_end_date = input("请输入搜索的终止日期(格式 yyyy-mm-dd):")
user_regions = input("请输入想要筛选的微博发布的地区,用逗号分隔:")
user_weibo_type_input = input(
"请输入微博类型(全部微博,全部原创微博,热门微博,关注人微博,认证用户微博"
",媒体微博,观点微博): ")
user_contain_type_input = input(
"请输入筛选类型(不筛选,包含图片,包含视频,包含音乐,包含短链接): ")
result = emotion_analyzer(user_cookie, user_keywords, user_start_date,
user_end_date, user_regions,
user_weibo_type_input, user_contain_type_input)
if result == 1:
print("成功!")
else:
logger.info("情绪分析未成功完成")
4.2、各更新模块/系统的运行截图
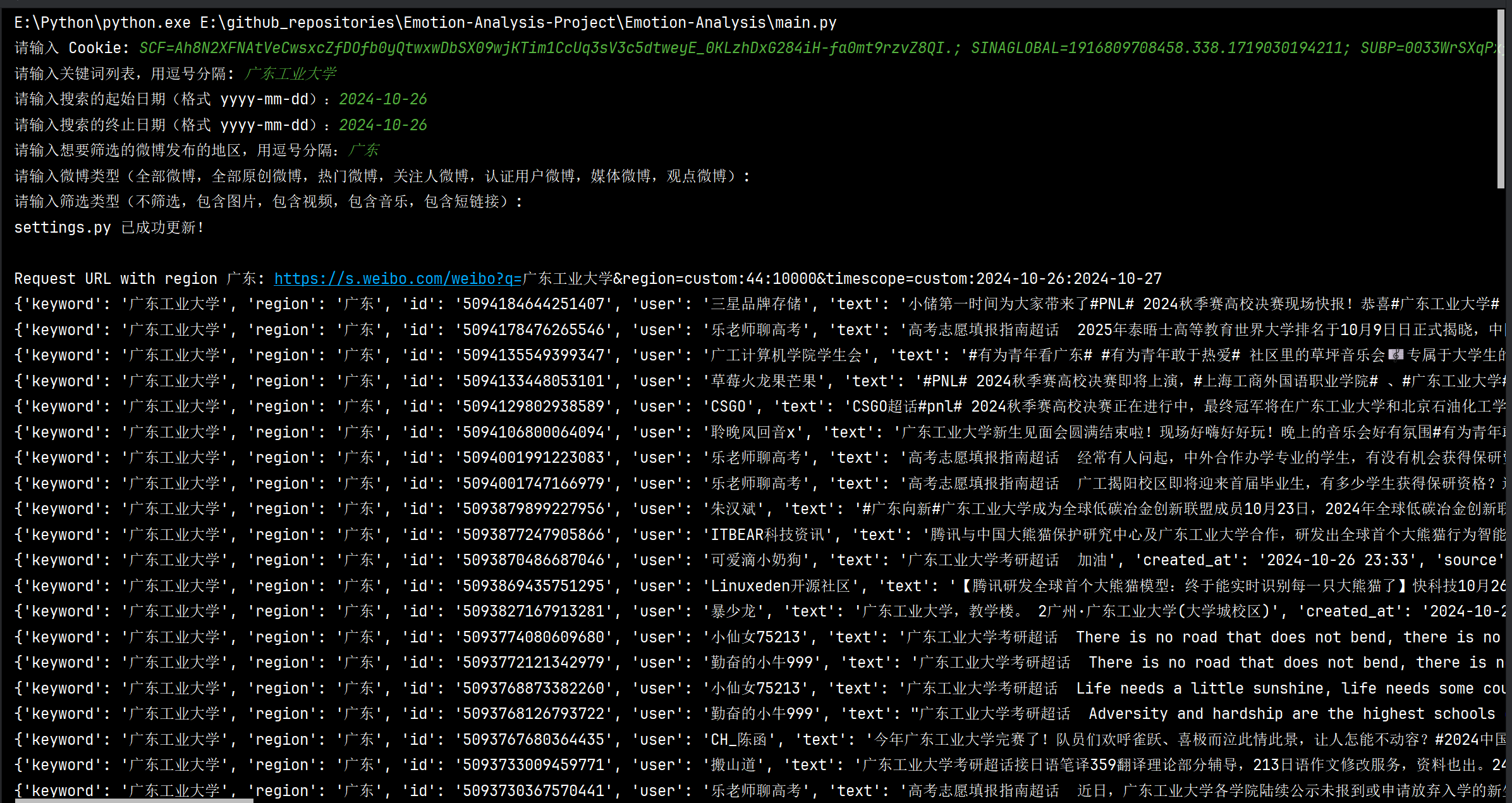
用户交互模块
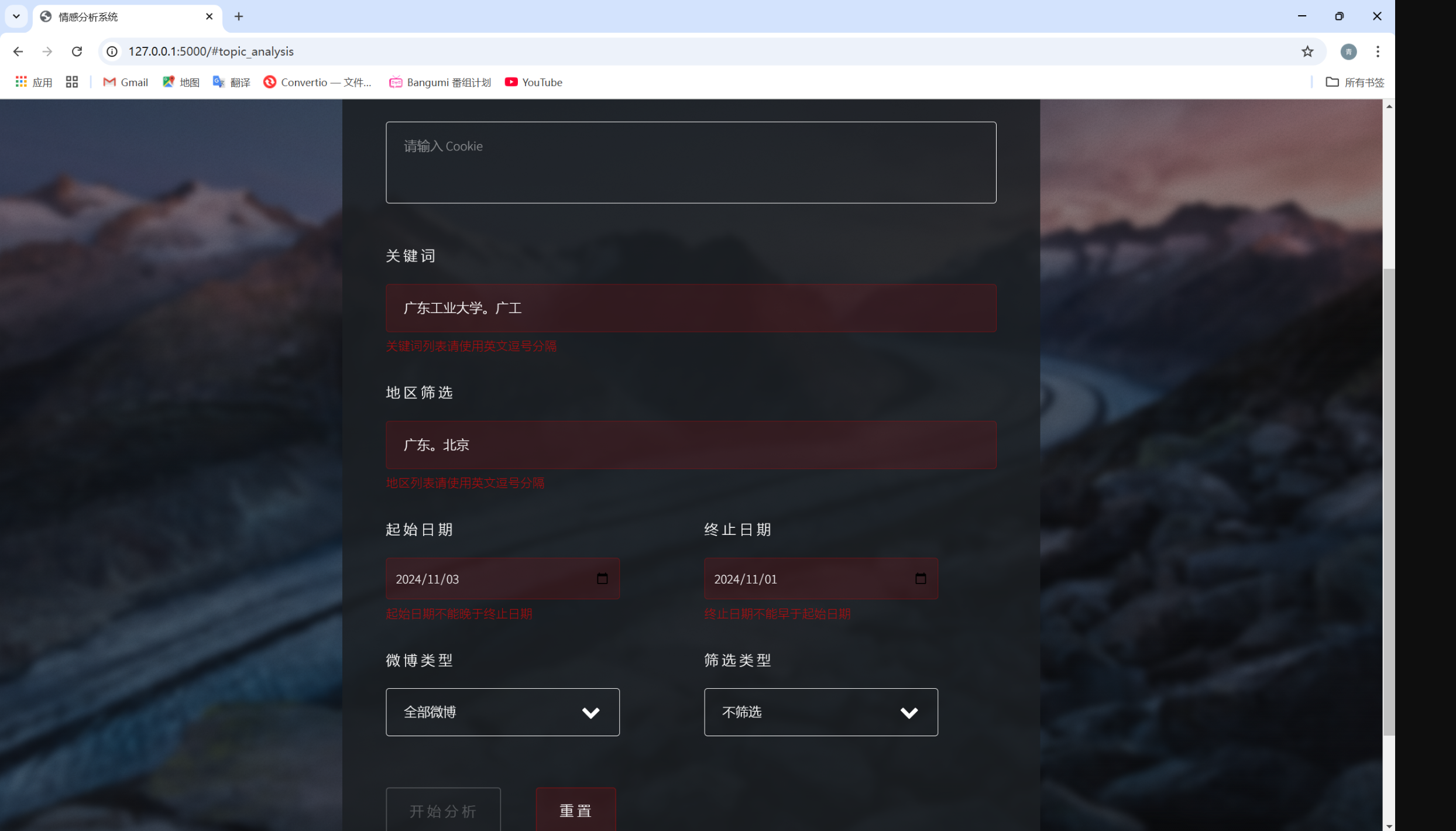
数据预处理模块
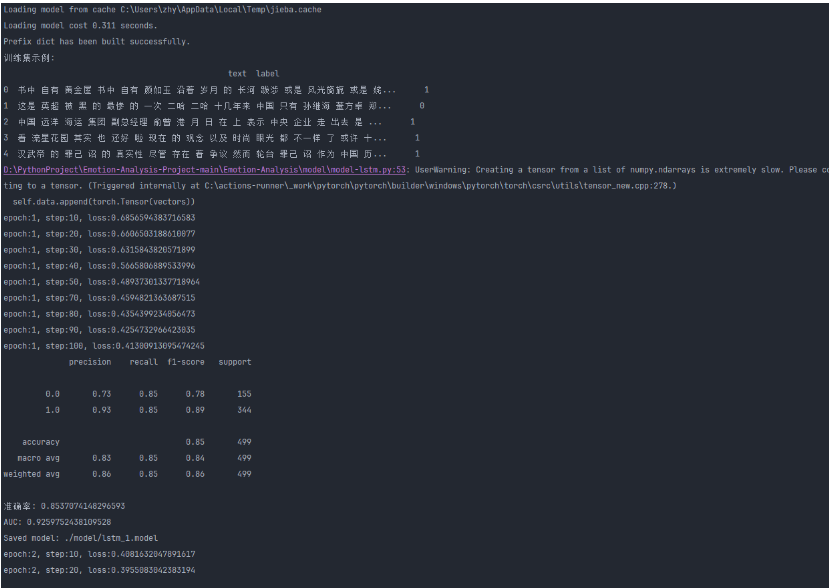
情感分析模块
系统调用整合
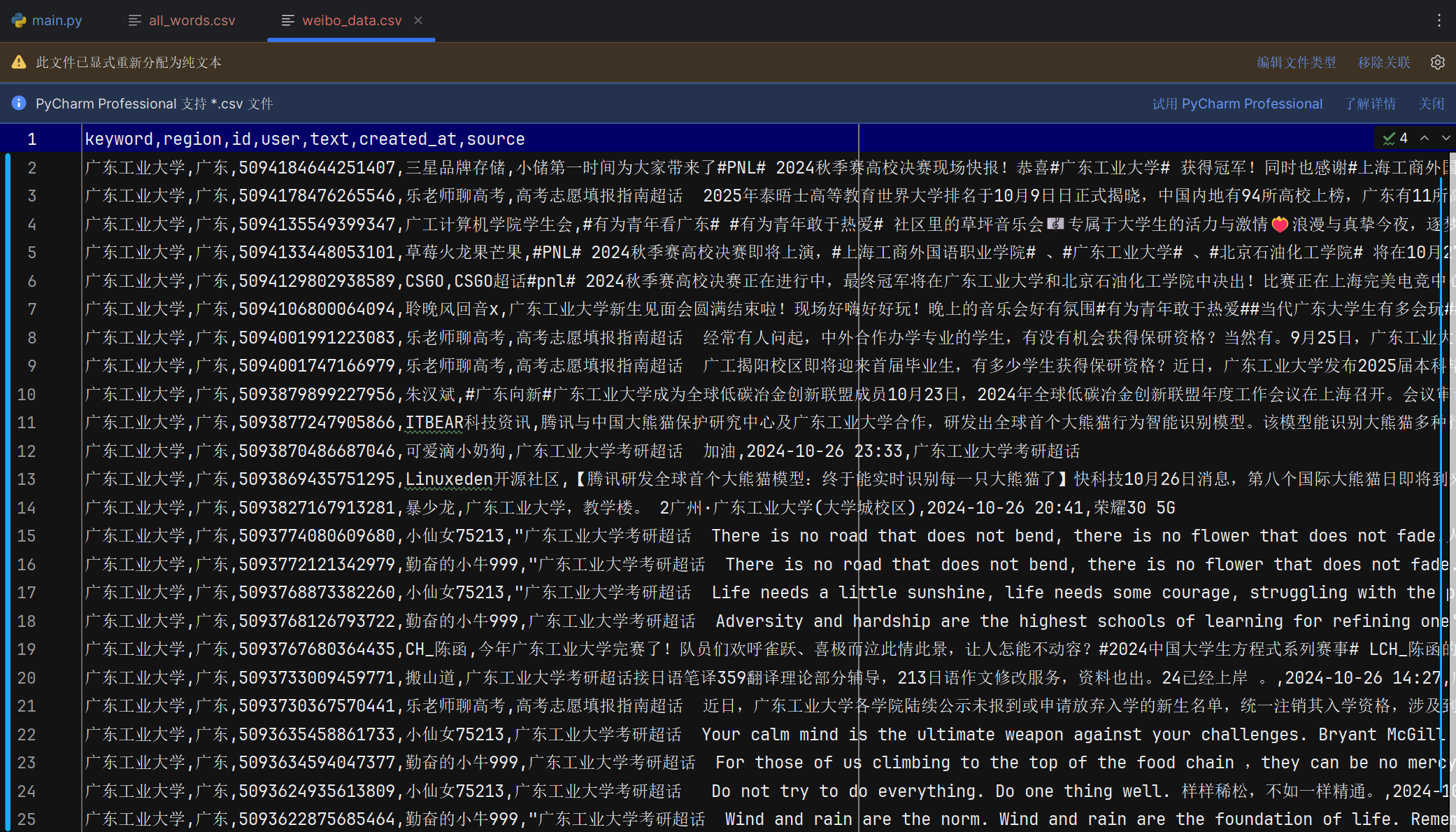

5、每人每日总结
| 团队成员 | 每日总结 |
|---|---|
| 梁恬 | 完成最终整合,但还没进行全面的测试与正常运行通过,之后的测试与发布一周中会进一步优化与改进,并尝试进行互联网的部署 |
| 潘思言 | 完成了用户差错处理,避免起始日期大于终止日期等情况的发生 |
| 张颢严 | 完成了 LSTM 模型的优化与训练,解决了空序列导致的训练中断问题,并对数据集预处理逻辑进行了改进。同时初步搭建了 SVM 和 XGBoost 模型,待后续完善与调试 |
| 王睿娴 | 对前几日的工作进行了一个复盘总结 |

