队名:P人大联盟
团队成员
| 姓名 |
学号 |
| 王睿娴 |
3222003968 |
| 张颢严 |
3222004426 |
| 梁恬(组长) |
3222004467 |
| 潘思言 |
3222004423 |
本篇博客目录
4.2、的目录索引无法响应,其子目录可响应
1、Scrum Meeting
1.1、站立式会议照片
1.2、会议总结
| 昨日安排的任务 |
负责成员 |
实际完成情况 |
工作中遇到的困难 |
| 完成对爬取的文本数据的清洗分词,并传递了相关文件到模型模块文件夹,在词云生成模块增加对情感分析结果文件的分类 |
梁恬 |
完成词云生成前的分类,文本数据的清洗与分词,进一步的向量化,数据集和测试集的划分还未完成 |
情感分析模型的输入不明确,文本预处理的输出不明确 |
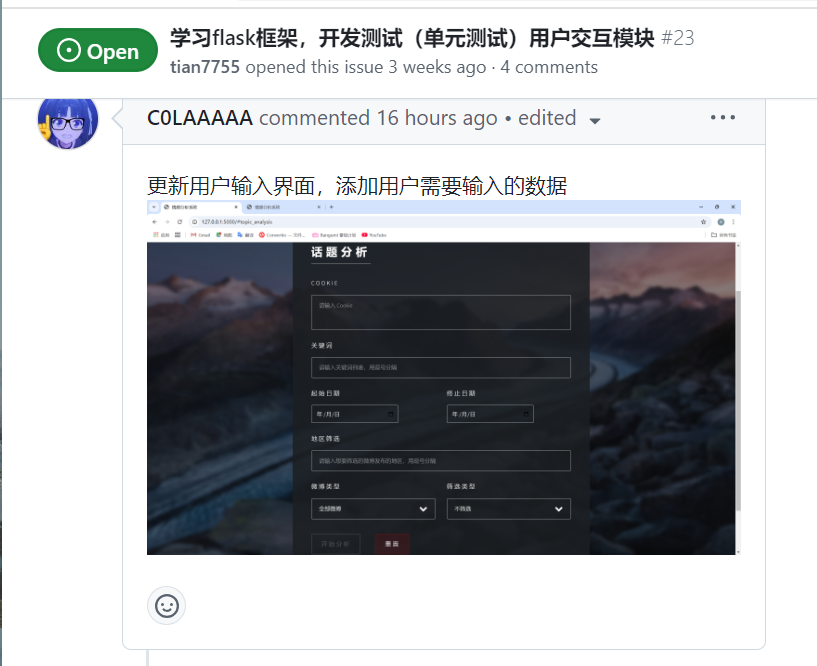
| 更新用户输入界面 |
潘思言 |
完成 |
输入差错处理逻辑仍需更新 |
| 优化 BERT 模型性能,处理数据集预处理问题 |
张颢严 |
完成模型优化和部分性能测试 |
数据预处理的多任务协调耗时较长,部分测试指标仍需完善 |
| 调试与错误修复 |
王睿娴 |
完成 |
不同微博结构的适配 |
| 今日计划的任务 |
负责成员 |
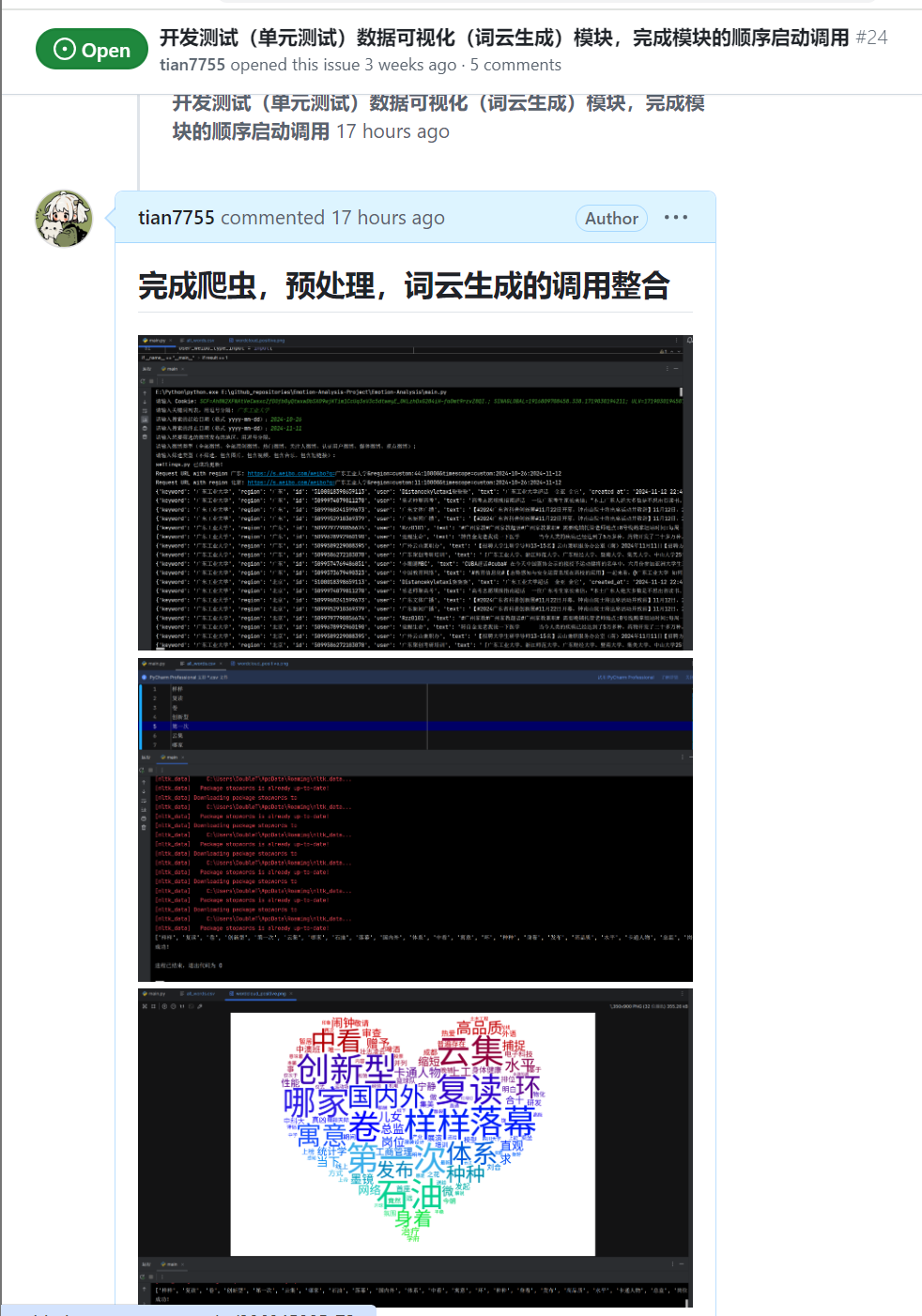
| 完成爬虫,文本预处理和词云生成的调用整合 |
梁恬 |
| 链接前端输入 |
潘思言 |
| 微调 bys 模型并优化情感分类准确率 |
张颢严 |
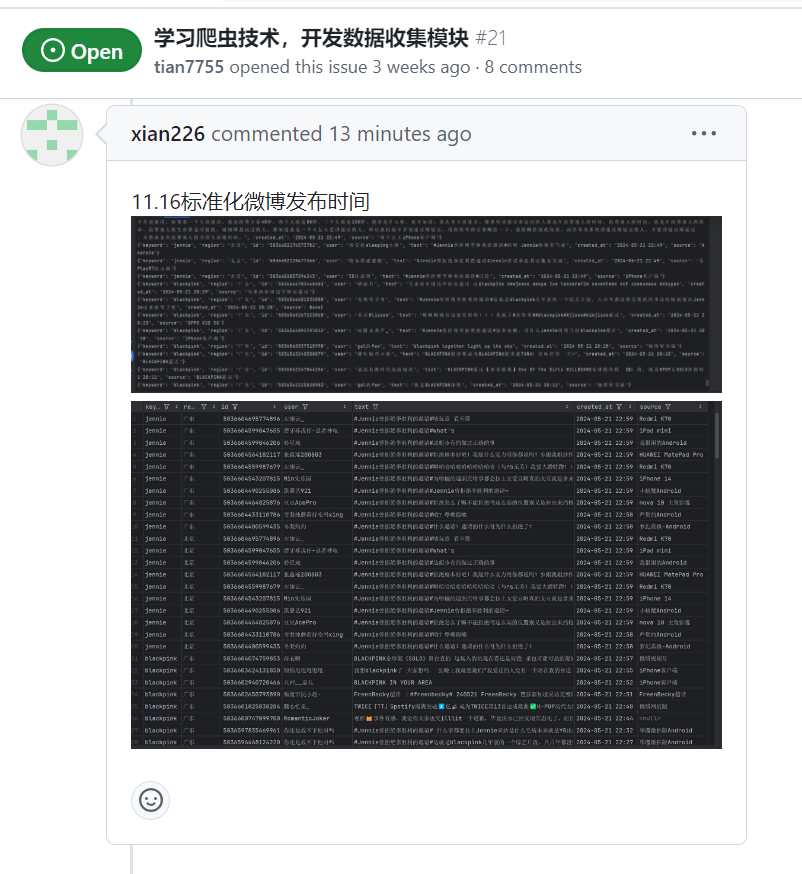
| 标准化微博发布时间 |
王睿娴 |
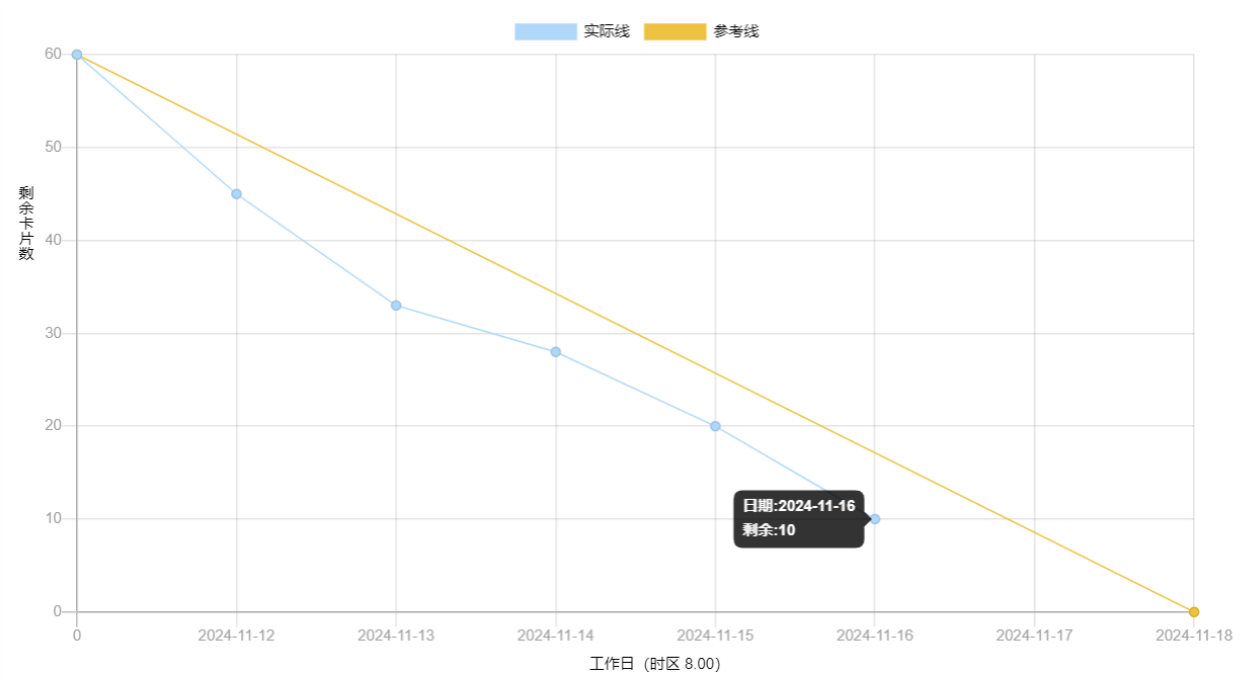
2、燃尽图
3、代码/文档签入记录
当天编码规范文档无更新
4、项目程序/模块的最新
4.1、最新模块的代码
点击查看数据可视化模块最新代码
wordcloud_generator.py更新的函数
# 读取文本数据
def load_text_data(file_path):
try:
with open(file_path, 'r', encoding='utf-8-sig') as csvfile:
return " ".join(row[0] for row in csv.reader(csvfile)).strip()
except FileNotFoundError:
logger.error(f"File {file_path} not found.")
return None
# 创建词云图
def generate_wordcloud(text, font_path, mask, image_color):
return WordCloud(
font_path=font_path,
background_color="white", # 设置背景颜色
color_func=image_color, # 设置字体颜色,将上面模板图像生成的颜色传入词云
mask=mask,
prefer_horizontal=1.0, # 词语横排显示的概率
scale=3 # 增加 scale 参数以提高输出图像的分辨率
).generate(text)
# 美化词云图
def beautify_images(filename, save_path=''):
image_path = f"{save_path}{filename}.png"
image = Image.open(image_path)
# 调整图片的对比度、色彩饱和度和锐度
# 对比度增强30%
img_enhanced = ImageEnhance.Contrast(image).enhance(1.3)
# 色彩饱和度增强30%
img_enhanced = ImageEnhance.Color(img_enhanced).enhance(1.3)
# 锐度增强50%
img_enhanced = ImageEnhance.Sharpness(img_enhanced).enhance(1.5)
img_enhanced.save(image_path)
# 单个文件的词云图生成
def wordcloud_generator(sentiment, file_info, save_path, font_path):
# 读取文本数据与读取异常处理
words = load_text_data(file_info['text'])
if words is None:
logger.error(f"Failed to load data file: {file_info['text']}")
return
try:
# 引进背景图片与图片颜色
bg_image = imageio.imread((file_info['background']))
bg_image_color = ImageColorGenerator(bg_image)
# 创建,保存并优化词云图
wordcloud = generate_wordcloud(words, font_path, bg_image,
bg_image_color)
save_wordcloud(wordcloud, f'wordcloud_{sentiment}', dpi=150,
save_path=save_path)
beautify_images(f'wordcloud_{sentiment}', save_path)
except Exception as e:
logger.error(f"Error generating {sentiment} wordcloud: {e}")
点击查看数据收集模块最新代码
from datetime import datetime, timedelta
def standardize_date(created_at):
"""标准化微博发布时间"""
if "刚刚" in created_at:
created_at = datetime.now().strftime("%Y-%m-%d %H:%M")
elif "秒" in created_at:
second = created_at[:created_at.find(u"秒")]
second = timedelta(seconds=int(second))
created_at = (datetime.now() - second).strftime("%Y-%m-%d %H:%M")
elif "分钟" in created_at:
minute = created_at[:created_at.find(u"分钟")]
minute = timedelta(minutes=int(minute))
created_at = (datetime.now() - minute).strftime("%Y-%m-%d %H:%M")
elif "小时" in created_at:
hour = created_at[:created_at.find(u"小时")]
hour = timedelta(hours=int(hour))
created_at = (datetime.now() - hour).strftime("%Y-%m-%d %H:%M")
elif "今天" in created_at:
today = datetime.now().strftime('%Y-%m-%d')
created_at = today + ' ' + created_at[2:]
elif '年' not in created_at:
year = datetime.now().strftime("%Y")
month = created_at[:2]
day = created_at[3:5]
time = created_at[6:]
created_at = year + '-' + month + '-' + day + ' ' + time
else:
year = created_at[:4]
month = created_at[5:7]
day = created_at[8:10]
time = created_at[11:]
created_at = year + '-' + month + '-' + day + ' ' + time
return created_at
点击查看情感分析模块最新代码
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
from utils import load_corpus, stopwords, processing
# 设置文件路径
TRAIN_PATH = "./data/weibo2018/train.txt"
TEST_PATH = "./data/weibo2018/test.txt"
PREDICT_PATH = "model/labeled_comments.csv"
if __name__ == "__main__":
# 加载训练集和测试集
train_data = load_corpus(TRAIN_PATH)
test_data = load_corpus(TEST_PATH)
# 将训练集和测试集转换为 DataFrame
df_train = pd.DataFrame(train_data, columns=["words", "label"])
df_test = pd.DataFrame(test_data, columns=["words", "label"])
# 查看训练集数据
print("训练集示例:")
print(df_train.head())
# 使用 CountVectorizer 对文本进行向量化
vectorizer = CountVectorizer(token_pattern=r'\[?\w+\]?', stop_words=stopwords)
# 转换训练集文本为特征向量
X_train = vectorizer.fit_transform(df_train["words"])
y_train = df_train["label"]
# 转换测试集文本为特征向量
X_test = vectorizer.transform(df_test["words"])
y_test = df_test["label"]
# 使用 Multinomial Naive Bayes 训练模型
clf = MultinomialNB()
clf.fit(X_train, y_train)
# 使用训练好的模型进行预测
y_pred = clf.predict(X_test)
# 输出测试集效果评估
print(metrics.classification_report(y_test, y_pred))
print("准确率:", metrics.accuracy_score(y_test, y_pred))
# 加载 CSV 文件中的测试文本
predict_df = pd.read_csv(PREDICT_PATH)
print(predict_df.columns)
# 确保测试文本列存在并进行预处理
# 确保测试文本列存在并进行预处理
if "Comment" not in predict_df.columns:
raise ValueError("CSV 文件中必须包含 'Comment' 列")
predict_texts = predict_df["Comment"].apply(processing).tolist()
# 转换测试文本为特征向量
vec = vectorizer.transform(predict_texts)
# 预测并输出结果
predictions = clf.predict(vec)
predict_df["prediction"] = predictions
# 保存预测结果到 CSV 文件
output_path = "model/predict/bys.csv"
predict_df.to_csv(output_path, index=False, encoding="utf-8")
print(f"预测结果已保存到: {output_path}")
点击查看系统调用整合最新代码
main.py
import os
import subprocess
from weibo_crawler.weibo_crawler.update_settings import main
from nlp.text_processor import text_processor
from data_visualization.logger_config import logger
from data_visualization.wordcloud_generator import wordclouds_generator
# 改变运行目录并执行对应模块函数
def change_directory_and_execute(original_dir, directory, func, *args):
try:
os.chdir(os.path.join(original_dir, directory))
func(*args)
except Exception as e:
logger.error(f"Error in {directory}: {e}")
return False
finally:
os.chdir(original_dir)
return True
# 整合调用各个模块
def emotion_analyzer(cookie, keywords, start_date, end_date, regions,
weibo_type_input, contain_type_input):
# 保存原始目录
original_dir = os.getcwd()
if not change_directory_and_execute(original_dir, 'weibo_crawler',
main, cookie, keywords,
start_date, end_date, regions,
weibo_type_input, contain_type_input):
return None
try:
subprocess.run(['scrapy', 'crawl', 'search'], check=True)
except subprocess.CalledProcessError as e:
logger.error(f"Error executing Scrapy command: {e}")
return None
if not change_directory_and_execute(original_dir, 'nlp',
text_processor):
return None
if not change_directory_and_execute(original_dir,
'data_visualization',
wordclouds_generator):
return None
logger.info("Emotion analysis completed successfully")
return 1
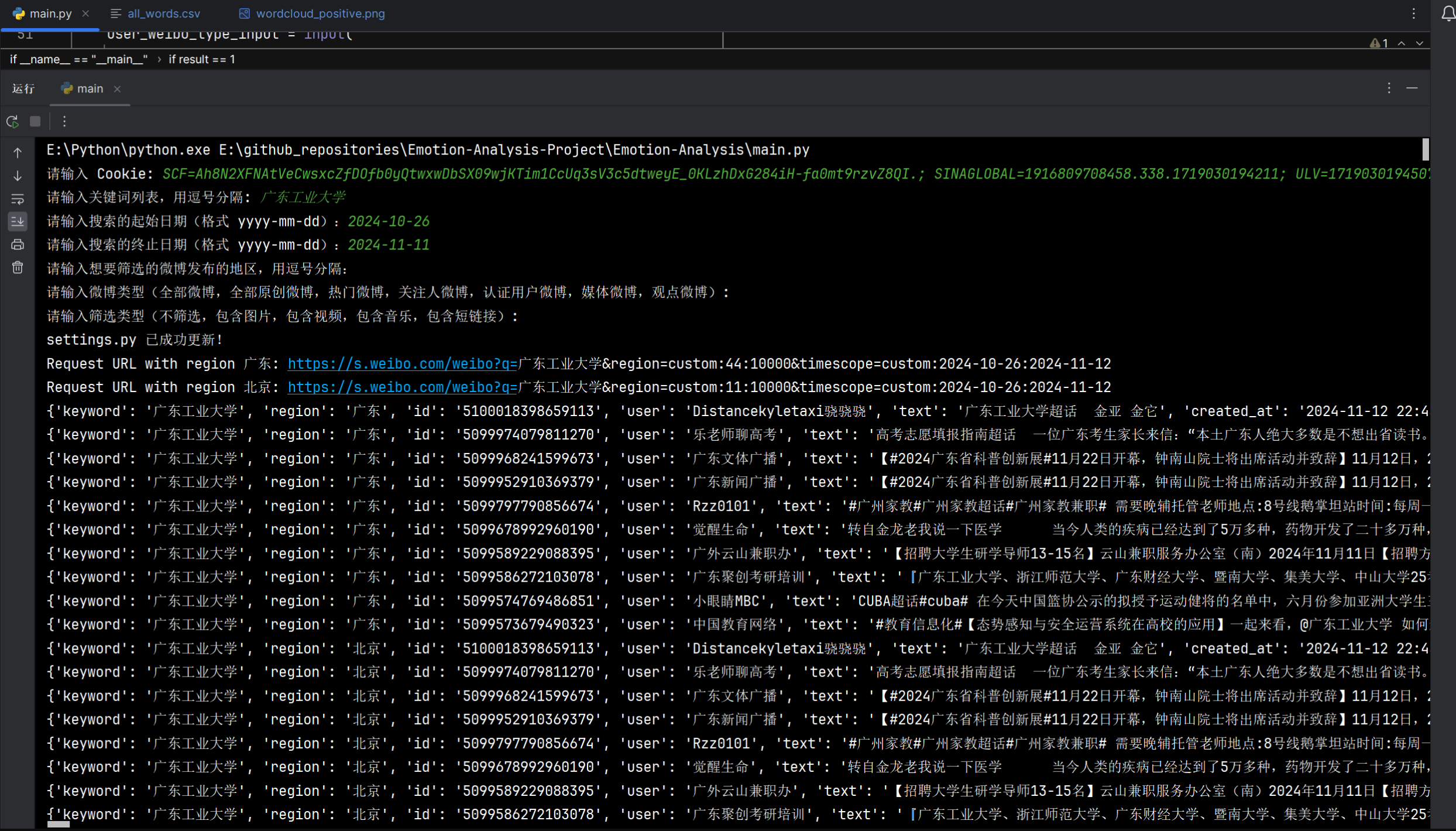
if __name__ == "__main__":
# 调试测试用
user_cookie = input("请输入 Cookie: ")
user_keywords = input("请输入关键词列表,用逗号分隔: ")
user_start_date = input("请输入搜索的起始日期(格式 yyyy-mm-dd):")
user_end_date = input("请输入搜索的终止日期(格式 yyyy-mm-dd):")
user_regions = input("请输入想要筛选的微博发布的地区,用逗号分隔:")
user_weibo_type_input = input(
"请输入微博类型(全部微博,全部原创微博,热门微博,关注人微博,认证用户微博"
",媒体微博,观点微博): ")
user_contain_type_input = input(
"请输入筛选类型(不筛选,包含图片,包含视频,包含音乐,包含短链接): ")
点击查看用户交互模块最新代码
@pb.route('/spider_analysis/topic', methods=['POST'])
def spider_analysis_topic():
cookie = request.form.get('cookie')
keywords = request.form.get('keyword')
start_date = request.form.get('start_date')
end_date = request.form.get('end_date')
regions = request.form.get('regions')
weibo_type_input = request.form.get('weibo_type_input')
contain_type_input = request.form.get('contain_type_input')
analysis_result = {
'cookie': cookie,
'keyword': keywords,
'start_date': start_date,
'end_date': end_date,
'regions': regions,
'weibo_type': weibo_type_input,
'contain_type': contain_type_input
}
from main import emotion_analyzer
result = emotion_analyzer(cookie, keywords, start_date, end_date, regions,
weibo_type_input, contain_type_input)
if result == 1:
return jsonify({'status': 'success', 'result': analysis_result})
else:
return jsonify({'status': 'failed', 'message': '情绪分析未成功完成'})
app.py
from flask import Flask, render_template
from views.page import page
import io
import sys
app = Flask(__name__)
app.register_blueprint(page.pb)
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8')
@app.route('/')
def home():
return render_template('index.html')
if __name__ == '__main__':
app.run()
4.2、各更新模块/系统的运行截图
用户交互模块
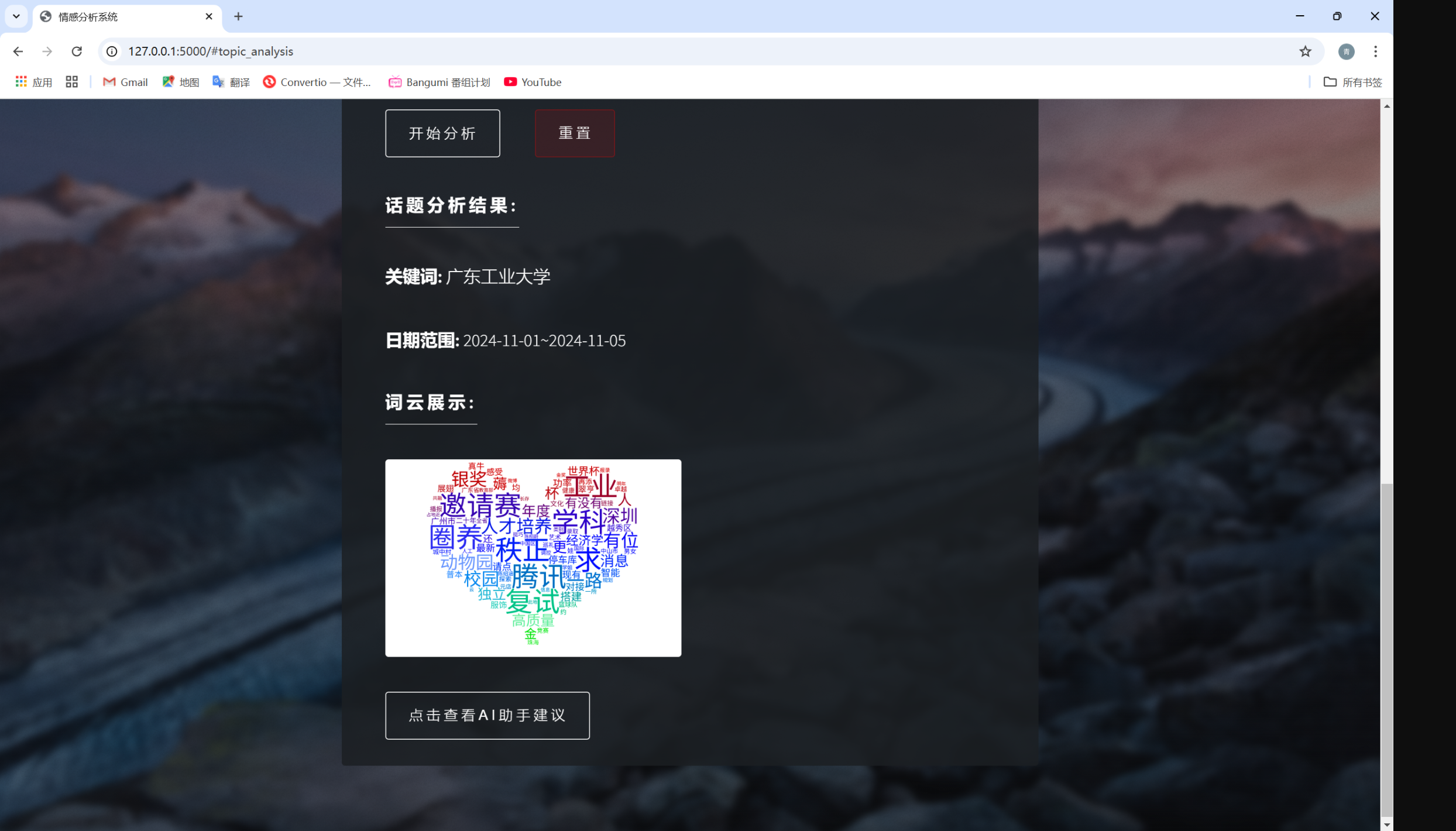
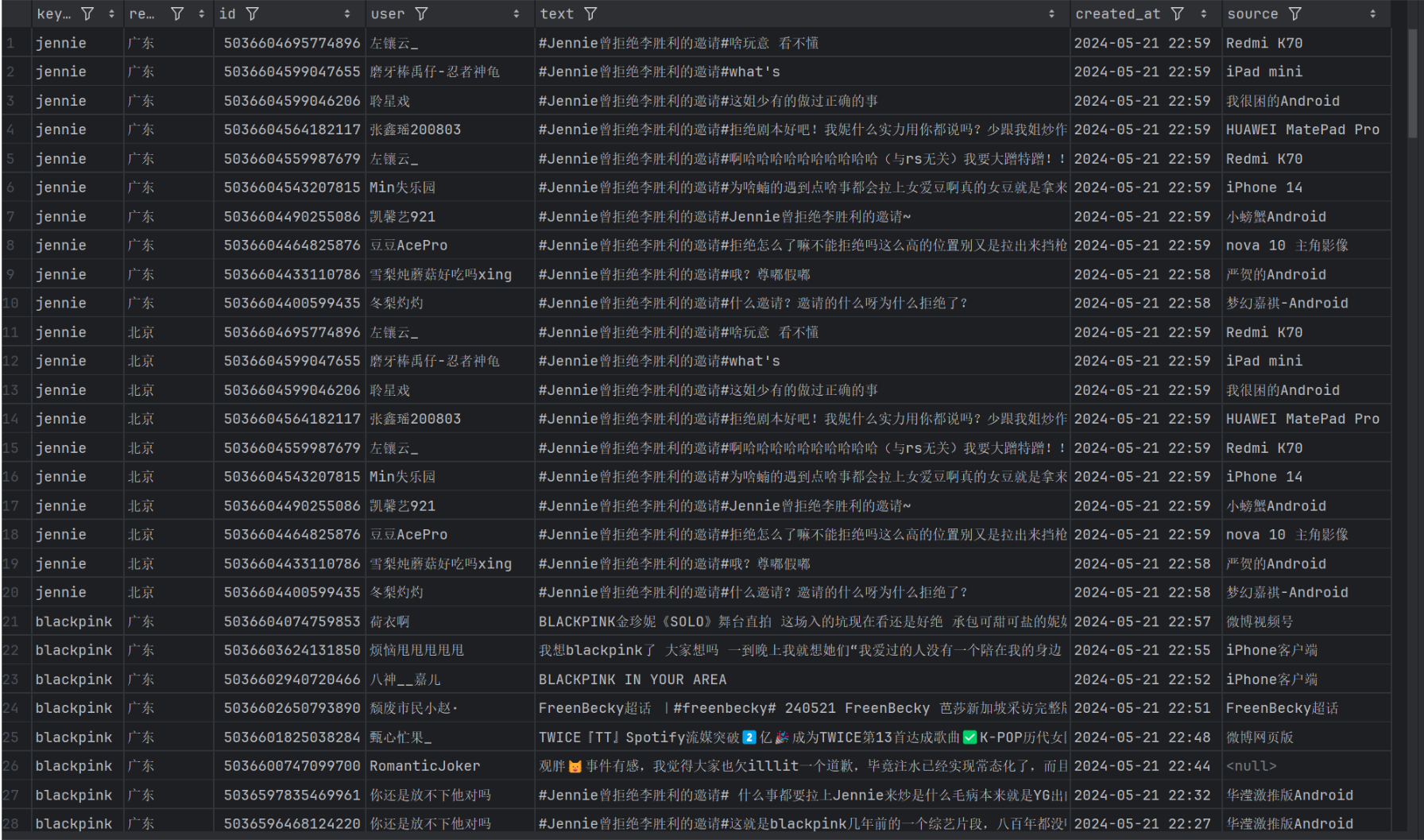
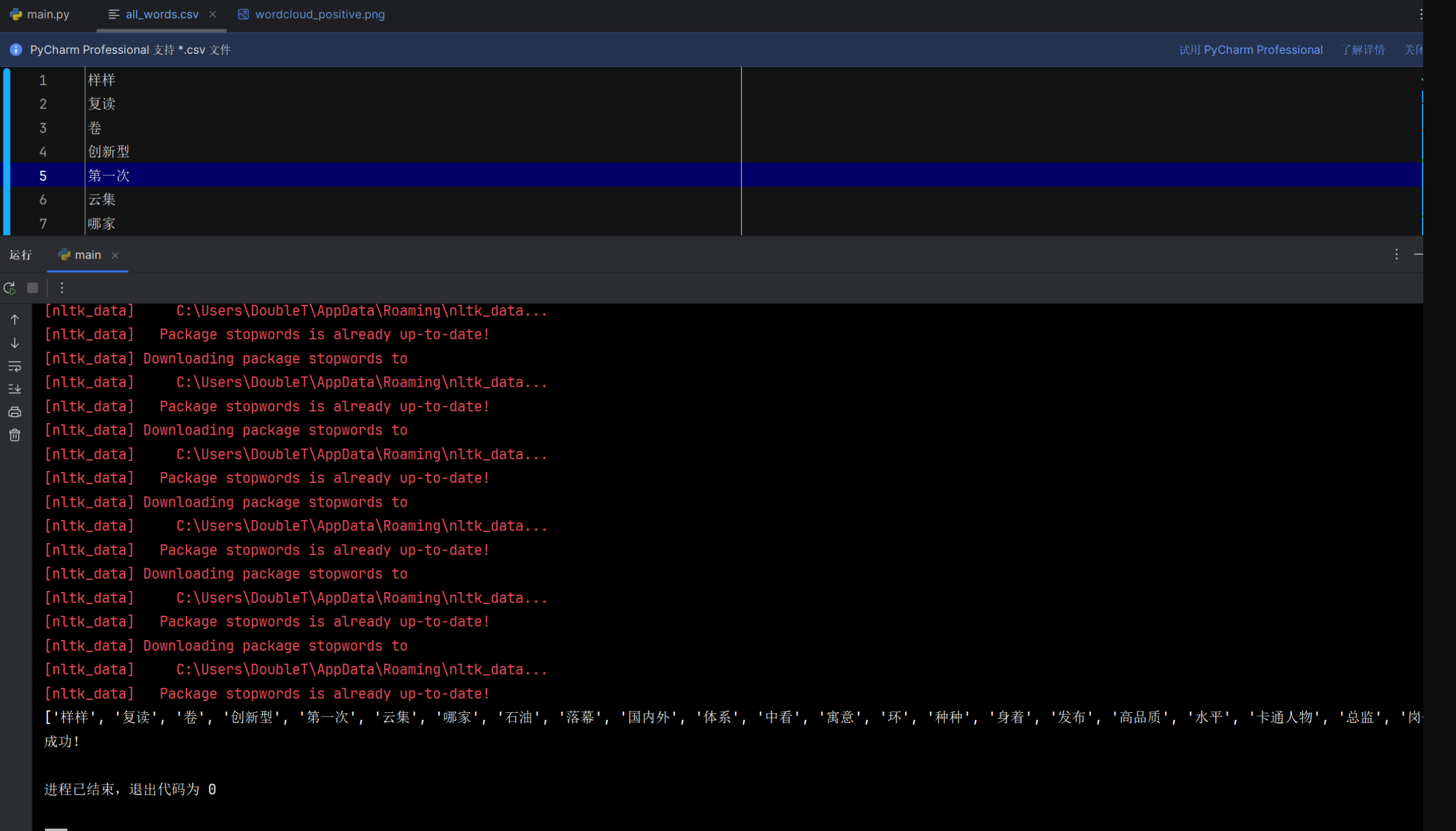
数据收集模块
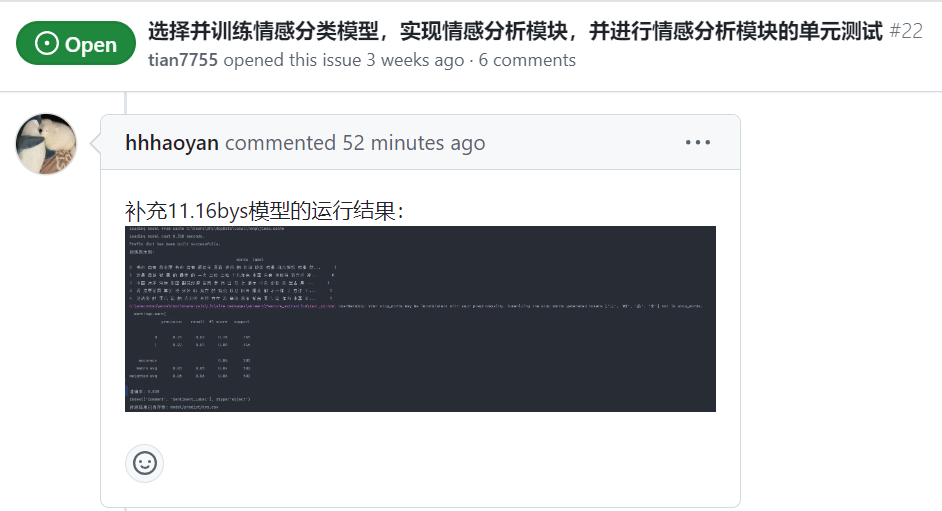
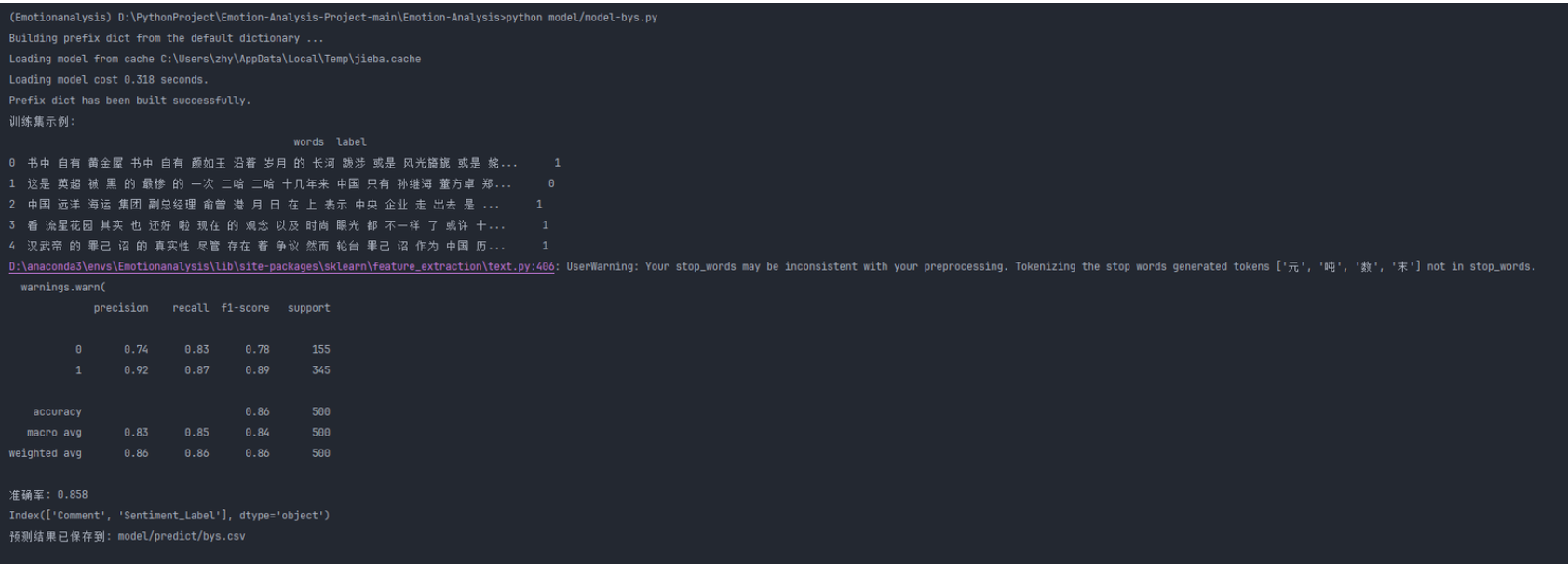
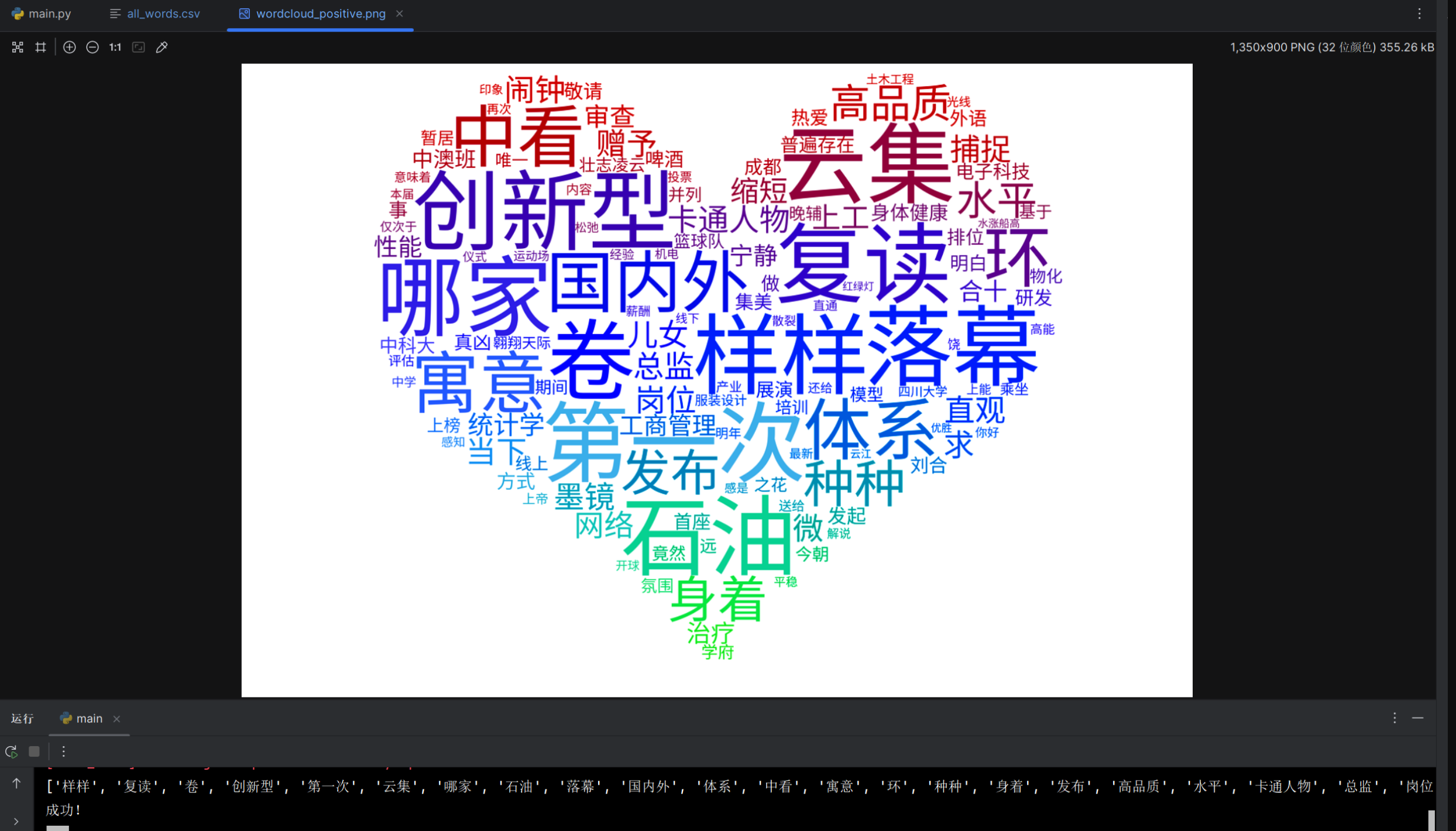
情感分析模块
系统调用整合
5、每人每日总结
| 团队成员 |
每日总结 |
| 梁恬 |
今日完成了其中三个模块之间的调用整合,希望之后的用户界面与情感分析模型的整合能够顺利 |
| 潘思言 |
在前端输入数据,并成功根据爬取的数据生成了词云图 |
| 张颢严 |
今天完成了基于贝叶斯(BYS)模型的搭建,并对其进行了初步测试。模型在情感分类任务中表现良好,下一步将对特征选择进行优化以提升准确率 |
| 王睿娴 |
完善对不同时间格式的适配。成功匹配各种格式 |