
第5篇Scrum冲刺博客
| 软件工程 | 班级链接 |
|---|---|
| 作业要求 | 作业要求 |
| 作业目标 | 项目冲刺 |
| github仓库 | 团队项目 |
队名:P人大联盟
团队成员
| 姓名 | 学号 |
|---|---|
| 王睿娴 | 3222003968 |
| 张颢严 | 3222004426 |
| 梁恬(组长) | 3222004467 |
| 潘思言 | 3222004423 |
本篇博客目录
4.2、的目录索引无法响应,其子目录可响应
1、Scrum Meeting
1.1、站立式会议照片

1.2、会议总结
| 昨日安排的任务 | 负责成员 | 实际完成情况 | 工作中遇到的困难 |
|---|---|---|---|
| 查看现有词云图在用户界面上的效果,对生成模块进行调整 | 梁恬 | 已根据网页大小调整词云图为合适大小 | flask框架下要传到页面需要将文件保存到static中,更换保存目录 |
| 确定词云图在结果展示的样式 | 潘思言 | 基本完成 | 移动端词云图的排列样式设计 |
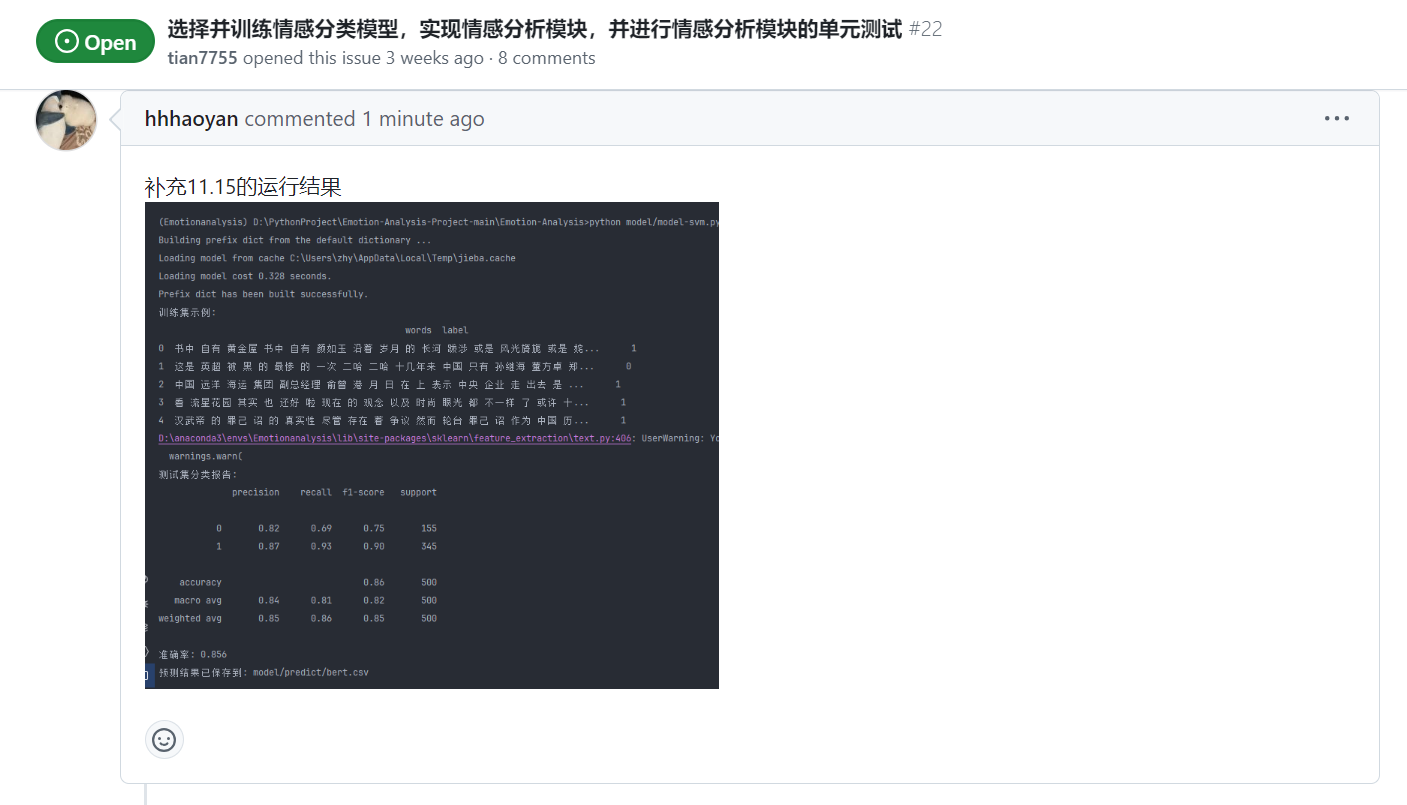
| 使用 PyTorch 的 transformers 库来搭建一个BERT 模型进行情感分析 | 张颢严 | 已完成模型搭建与初步测试 | 数据集预处理耗时较长;优化模型时 GPU 内存不足 |
| 添加多个解析模块、csv数据存储 | 王睿娴 | 基本完成 | 数据存储到 CSV 文件时出现编码问题 |
| 今日计划的任务 | 负责成员 |
|---|---|
| 完成对爬取的文本数据的清洗分词,并传递了相关文件到模型模块文件夹,在词云生成模块增加对情感分析结果文件的分类 | 梁恬 |
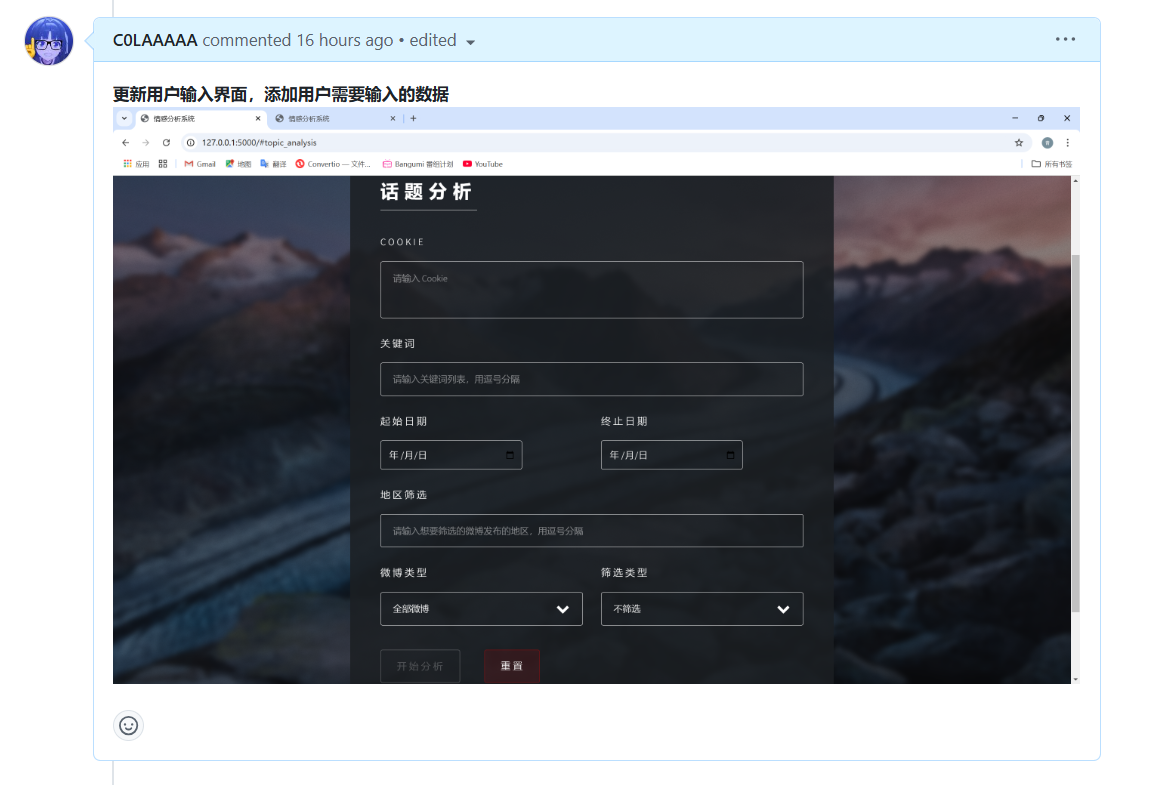
| 更新用户输入界面 | 潘思言 |
| 优化 BERT 模型性能,处理数据集预处理问题 | 张颢严 |
| 调试与错误修复 | 王睿娴 |
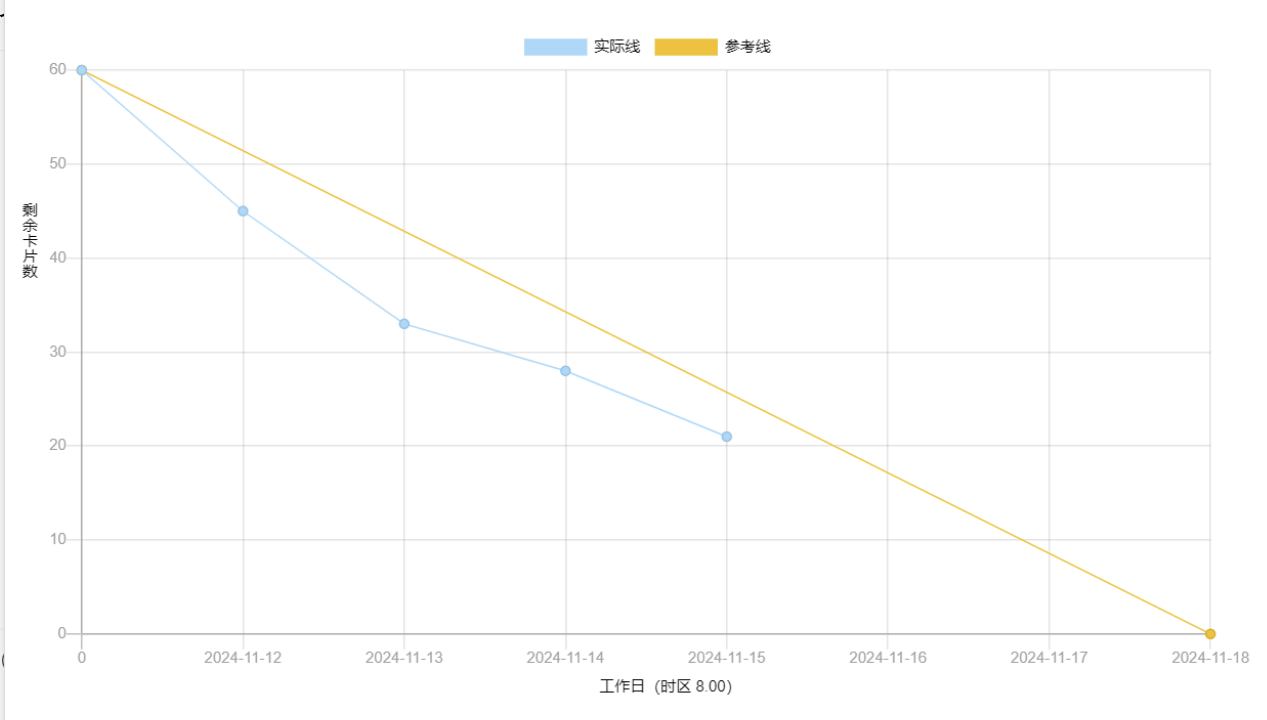
2、燃尽图
3、代码/文档签入记录
| 团队成员 | 代码/文档签入截图 | 对应的issues内容截图 | 对应的issues链接 |
|---|---|---|---|
| 梁恬 | 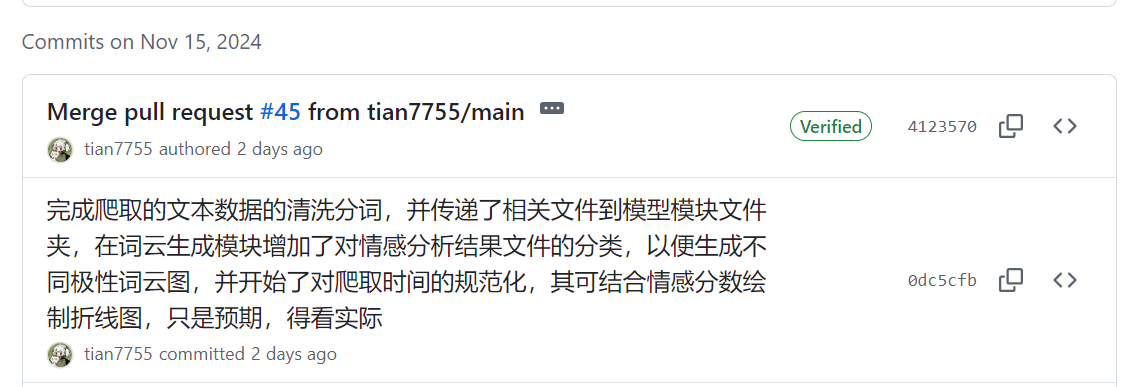 |
 , , |
issues链接1,issues链接2 |
| 潘思言 |  |
 |
issues链接 |
| 张颢严 |  |
 |
issues链接 |
| 王睿娴 | 11.15忘记签入了修改部分与11.16完成内容一起签入 | 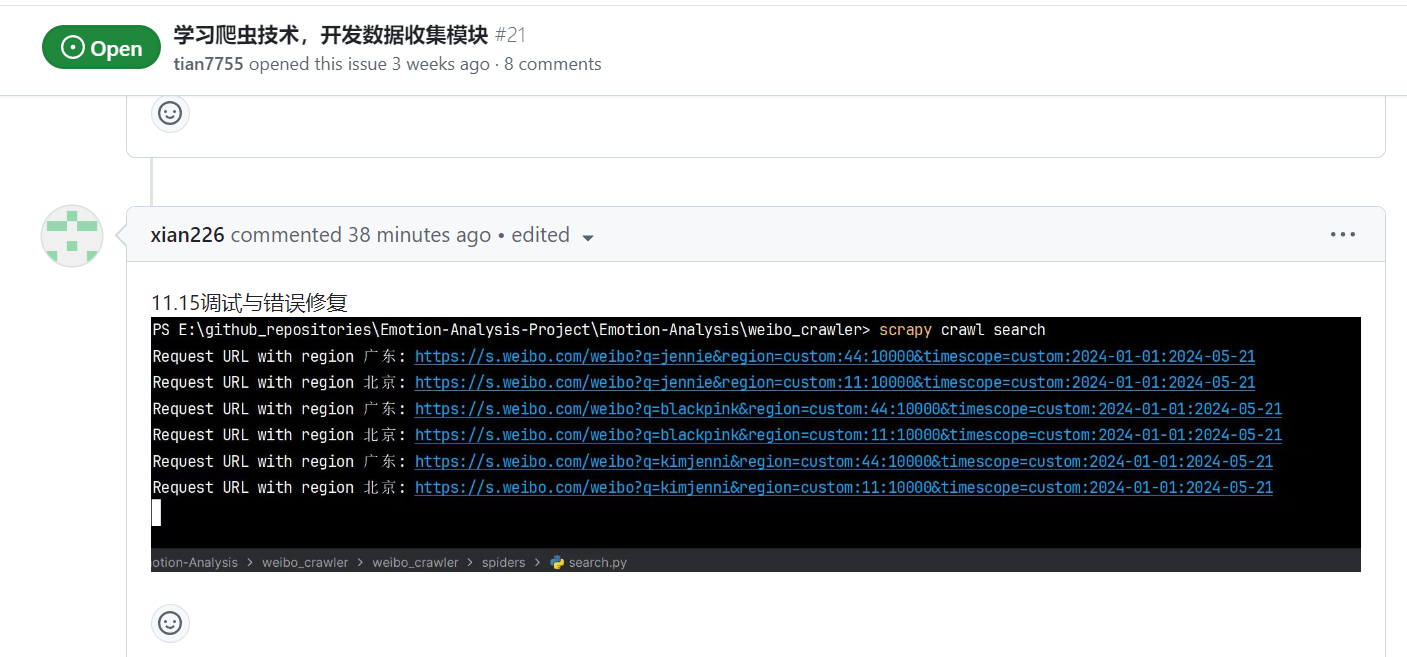 |
issues链接 |
当日编码规范文档无更新
4、项目程序/模块的最新
4.1、最新模块的代码
点击查看数据可视化模块最新代码
classification.py
import json
import csv
def classifcation(json_file_path):
# 读取JSON文件
with open(json_file_path, 'r', encoding='utf-8-sig') as jsonfile:
sentiment_results = json.load(jsonfile)
# 准备三个CSV文件,分别存储正面、负面和中性的情感文本
csv_files = {
'positive': 'positive_texts.csv',
'negative': 'negative_texts.csv',
'neutral': 'neutral_texts.csv'
}
# 确保CSV文件存在
for filename in csv_files.values():
open(filename, 'a').close()
# 根据情感标签将文本写入对应的CSV文件
for sentiment_result in sentiment_results:
label = sentiment_result['sentiment_label']
text = sentiment_result['text']
# 跳过没有标签的情感结果
if label not in csv_files:
continue
# 将文本按空格分词并写入对应的CSV文件
with open(csv_files[label], 'a', encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
for word in text.split():
writer.writerow([word]) # 每个词单独一行
print("情感文本已根据情感标签分类并保存到CSV文件。")
if __name__ == "__main__":
json_file_path = '../model/sentiment_results.json'
classifcation(json_file_path)
点击查看数据预处理模块最新代码
text_processor.py
import json
import re
import csv
import emoji
import jieba
import unicodedata
from bs4 import BeautifulSoup
from datetime import datetime
from stopwords.get_stopwords import get_stopwords
from visualization.logger_config import logger
def load_scraped_data(csv_path, data):
try:
with open(csv_path, 'r', encoding='utf-8-sig') as file:
# 创建一个csv.DictReader对象
reader = csv.DictReader(file)
# 遍历csv文件中的每一行
for row in reader:
# 将每一行转换为字典,并添加到列表中
data.append(row)
# 打印结果,查看前几行数据
# for item in data[:5]:
# print(item)
# print("-" * 50)
except FileNotFoundError:
logger.error(f"CSV File {csv_path} not found.")
def explain_emojis(text):
return emoji.demojize(text, language="zh")
def cut_words(text):
words = jieba.cut(text, cut_all=False)
return " ".join(word for word in words if word)
def rm_url_html(text):
soup = BeautifulSoup(text, 'html.parser')
text = soup.get_text()
text = re.sub('(http://.*)$', '', text)
url_regex = re.compile(
r'(?i)\b((?:https?://|www\d{0,3}[.]|[a-z0-9.\-]+[.][a-z]{2,4}/)'
r'(?:[^\s()<>]+|\(([^\s()<>]+|(\([^\s()<>]+\)))*\))+(?:\(([^\s()<>]+'
r'|(\([^\s()<>]+\)))*\)|[^\s`!()\[\]{};:\'".,<>?«»“”‘’]))',
re.IGNORECASE)
return re.sub(url_regex, "", text)
def rm_punctuation_symbols(text):
return ''.join(ch for ch in text
if unicodedata.category(ch)[0] not in ['P', 'S'])
def rm_extra_linebreaks(text):
lines = text.splitlines()
return '\n'.join(
re.sub(r'[\s]+', ' ', l).strip()
for l in lines if l.strip())
def rm_meaningless(text):
text = re.sub('[#\n]*', '', text)
text = text.replace("转发微博", "")
text = re.sub(r"\s+", " ", text) # 替换多个空格为一个空格
text = re.sub(r"(回复)?(//)?\s*@\S*?\s*(:| |$)", " ", text)
return text.strip()
def rm_english_number(text):
return re.sub(r'[a-zA-Z0-9]+', '', text)
def keep_only_chinese(text):
# 正则表达式匹配所有中文字符
chinese_pattern = re.compile(u"[\u4e00-\u9fa5]+")
# 找到所有匹配的中文字符
chinese_only = chinese_pattern.findall(text)
# 将匹配的中文字符连接成一个新的字符串
return ''.join(chinese_only)
def rm_stopwords(words):
stopwords = get_stopwords()
return [word for word in words if word.strip() and word not in stopwords]
def clean(text):
text = explain_emojis(text)
text = rm_url_html(text)
text = rm_punctuation_symbols(text)
text = rm_extra_linebreaks(text)
text = rm_meaningless(text)
text = rm_english_number(text)
text = keep_only_chinese(text)
return text.strip()
def text_processor():
# CSV文件路径
csv_file_path = '../weibo_crawler/weibo_data.csv'
# 加载csv爬虫数据文件
data_list = []
load_scraped_data(csv_file_path, data_list)
all_texts = [] # 保存所有文本
all_words = [] # 保存所有单词
if data_list:
for item in data_list:
if 'text' in item:
text_value = item['text']
# 数据清洗
text_value = clean(text_value)
# 中文分词
words = cut_words(text_value).split()
# 移除停用词
words = rm_stopwords(words)
item['text'] = " ".join(words)
# 保存处理后的文本
all_texts.append(item['text'])
# 将处理后的单词添加到 all_words 列表中
all_words.extend(words)
else:
logger.warning(f"The 'text' key is not found in the"
f" dictionary.")
# 删除 'id' 和 'user' 键值对
item.pop('id', None) # 使用 pop 来避免 KeyError
item.pop('user', None)
# 规范化 'create_at' 时间格式
if 'create_at' in item:
# 获取当前日期
current_date = datetime.now().date()
# 将当前日期格式化为字符串
current_date_str = current_date.strftime('%Y-%m-%d')
original_time = item['create_at']
if "今天" in original_time or "前" in original_time:
formatted_time = current_date_str
else:
try:
# 尝试解析时间字符串,至少包含年月日
parsed_time = datetime.strptime(original_time,
'%m-%d')
formatted_time = original_time
except ValueError:
# 解析时间字符串
parsed_time = datetime.strptime(original_time,
'%a %b %d %H'
':%M:%S %z %Y')
# 格式化时间为年月日
formatted_time = parsed_time.strftime('%Y-%m-%d')
# 更新 'create_at' 为规范化后的时间
item['create_at'] = formatted_time
# 保存处理后的数据到 CSV 文件
csv_file_path = '../visualization/processed_data.csv'
fieldnames = ['keyword', 'region', 'text', 'created_at',
'source']
with open(csv_file_path, 'w', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# 写入数据
for item in data_list:
writer.writerow(item)
# 保存 all_words 为 CSV 文件
all_words = list(set(all_words)) # 去重
print(all_words)
csv_file_path = '../visualization/all_words.csv'
with open(csv_file_path, 'w', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
for word in all_words:
writer.writerow([word])
# 词汇表
word_index = {}
index_word = {}
for i, word in enumerate(all_words):
word_index[word] = i
index_word[i] = word
# 保存词汇表为 JSON 文件
json_file_path = '../model/word_index.json'
with open(json_file_path, 'w', encoding='utf-8-sig') as jsonfile:
json.dump(word_index, jsonfile, ensure_ascii=False)
# 将文本转化为整数序列
sequences = [[word_index[word] for word in text.split()] for text in
all_texts]
# 保存整数序列(可选,用于调试和验证)
csv_file_path = '../model/sequences.csv'
with open(csv_file_path, 'w', newline='',
encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
for sequence in sequences:
writer.writerow(sequence)
# 保存情感分数与文本的字典为 JSON 文件
json_file_path = '../model/sentiment_results.json'
with open(json_file_path, 'w', encoding='utf-8-sig') as jsonfile:
json.dump(sentiment_results, jsonfile, ensure_ascii=False)
if __name__ == "__main__":
text_processor()
点击查看情感分析模块最新代码
import os
import pandas as pd
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoader
from transformers import BertTokenizer, BertModel
from sklearn import metrics
# 设置环境变量避免BERT报错
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
# 数据路径
TRAIN_PATH = "./data/weibo2018/train.txt"
TEST_PATH = "./data/weibo2018/test.txt"
PREDICT_PATH = "model/labeled_comments.csv"
# 加载数据集
def load_corpus_from_csv(file_path):
try:
df = pd.read_csv(file_path)
if "text" not in df.columns or "Sentiment_Label" not in df.columns:
raise ValueError("CSV 文件中必须包含 'text' 和 'Sentiment_Label' 列")
texts = df["text"].tolist()
labels = df["Sentiment_Label"].tolist()
return texts, labels
except Exception as e:
print(f"加载数据时出错: {e}")
return [], []
# 加载训练集和测试集
print("加载训练集和测试集...")
train_texts, train_labels = load_corpus_from_csv(TRAIN_PATH)
test_texts, test_labels = load_corpus_from_csv(TEST_PATH)
print("数据加载完成!")
# BERT模型路径
MODEL_PATH = "bert-base-chinese"
print("加载BERT模型...")
tokenizer = BertTokenizer.from_pretrained(MODEL_PATH)
bert = BertModel.from_pretrained(MODEL_PATH)
print("BERT模型加载成功!")
# 设置设备
device = "cuda:0" if torch.cuda.is_available() else "cpu"
print(f"使用设备: {device}")
# 超参数
learning_rate = 1e-4
input_size = 768
num_epoches = 5
batch_size = 32
decay_rate = 0.9
# 数据集类
class MyDataset(Dataset):
def __init__(self, texts, labels):
self.texts = texts
self.labels = labels
def __getitem__(self, index):
return self.texts[index], self.labels[index]
def __len__(self):
return len(self.labels)
# 创建训练集和测试集 DataLoader
train_data = MyDataset(train_texts, train_labels)
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
test_data = MyDataset(test_texts, test_labels)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False)
# 网络结构
class Net(nn.Module):
def __init__(self, input_size):
super(Net, self).__init__()
self.fc = nn.Linear(input_size, 1) # 全连接层
self.sigmoid = nn.Sigmoid() # Sigmoid激活函数
def forward(self, x):
out = self.fc(x)
out = self.sigmoid(out) # 返回sigmoid激活后的输出
return out
# 初始化模型
net = Net(input_size).to(device)
# 损失函数和优化器
criterion = nn.BCELoss()
optimizer = torch.optim.Adam(net.parameters(), lr=learning_rate)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=decay_rate)
def test():
net.eval() # 评估模式
y_pred, y_true = [], []
with torch.no_grad(): # 不计算梯度
for words, labels in test_loader:
tokens = tokenizer(words, padding=True, truncation=True, max_length=128, return_tensors="pt").to(device)
input_ids = tokens["input_ids"]
attention_mask = tokens["attention_mask"]
last_hidden_states = bert(input_ids, attention_mask=attention_mask)
bert_output = last_hidden_states[0][:, 0] # 获取[CLS] token的输出
outputs = net(bert_output) # 前向传播
y_pred.append(outputs.cpu())
y_true.append(torch.tensor(labels).float().cpu())
y_prob = torch.cat(y_pred)
y_true = torch.cat(y_true)
y_pred_bin = (y_prob > 0.5).int() # 将概率转换为二分类标签
print(metrics.classification_report(y_true, y_pred_bin))
print("准确率:", metrics.accuracy_score(y_true, y_pred_bin))
print("AUC:", metrics.roc_auc_score(y_true, y_prob))
def predict_from_csv(file_path):
"""
从 CSV 文件加载文本并进行预测
:param file_path: 包含文本的 CSV 文件路径
:return: DataFrame,包含预测结果
"""
df = pd.read_csv(file_path)
texts = df["text"].tolist()
net.eval()
predictions = []
with torch.no_grad():
for text in texts:
tokens = tokenizer([text], padding=True, truncation=True, max_length=128, return_tensors="pt").to(device)
input_ids = tokens["input_ids"]
attention_mask = tokens["attention_mask"]
last_hidden_states = bert(input_ids, attention_mask=attention_mask)
bert_output = last_hidden_states[0][:, 0] # 获取[CLS] token的输出
outputs = net(bert_output).cpu().numpy().flatten()
predictions.append(outputs[0])
df["prediction"] = predictions
return df
if __name__ == "__main__":
# 训练模型
for epoch in range(num_epoches):
net.train() # 训练模式
total_loss = 0
for i, (words, labels) in enumerate(train_loader):
tokens = tokenizer(words, padding=True, truncation=True, max_length=128, return_tensors="pt").to(device)
input_ids = tokens["input_ids"]
attention_mask = tokens["attention_mask"]
labels = torch.tensor(labels).float().to(device)
optimizer.zero_grad() # 清零梯度
last_hidden_states = bert(input_ids, attention_mask=attention_mask)
bert_output = last_hidden_states[0][:, 0] # 获取[CLS] token的输出
outputs = net(bert_output) # 前向传播
loss = criterion(outputs.view(-1), labels) # 计算损失
total_loss += loss.item()
loss.backward() # 反向传播
optimizer.step() # 更新梯度
if (i + 1) % 10 == 0:
print(f"epoch:{epoch + 1}, step:{i + 1}, loss:{total_loss / 10:.4f}")
total_loss = 0
scheduler.step() # 学习率衰减
# 每个epoch结束后进行测试
print(f"Testing after epoch {epoch + 1}:")
test()
# 保存模型
model_path = f"./model/bert_dnn_epoch{epoch + 1}.pth"
torch.save(net.state_dict(), model_path)
print(f"Saved model: {model_path}")
# 从 CSV 文件预测
predict_df = predict_from_csv(PREDICT_PATH)
output_path = "./model/predicted_results.csv"
predict_df.to_csv(output_path, index=False, encoding="utf-8")
print(f"Predictions saved to {output_path}")
点击查看用户交互模块最新代码
index.html
<!-- 话题分析 -->
<article id="topic_analysis">
<h2 class="major">话题分析</h2>
<form id="topicAnalysisForm" method="post">
<div class="fields">
<div class="field">
<label for="topic_cookie">COOKIE</label>
<textarea id="topic_cookie" name="cookie" style="height:100px; resize:none; font-size: medium" placeholder="请输入 Cookie" required ></textarea>
</div>
<div class="field">
<label for="topic_keyword">关键词</label>
<input type="text" id="topic_keyword" name="keyword" value="" placeholder="请输入关键词列表,用逗号分隔" style="font-size: medium" required>
</div>
<div class="field half">
<label for="start_date">起始日期</label>
<input type="date" name="start_date" id="start_date" value="" placeholder="请输入搜索的起始日期" required/>
</div>
<div class="field half">
<label for="end_date">终止日期</label>
<input type="date" name="end_date" id="end_date" value="" placeholder="请输入搜索的终止日期" required/>
</div>
<div class="field">
<label for="regions">地区筛选</label>
<input type="text" name="regions" id="regions" value="" placeholder="请输入想要筛选的微博发布的地区,用逗号分隔" style="font-size: medium" required/>
</div>
<div class="field half">
<label for="weibo_type_input">微博类型</label>
<select name="weibo_type_input" id="weibo_type_input" style="font-size: medium" >
<option value="全部微博">全部微博</option>
<option value="全部原创微博">全部原创微博</option>
<option value="热门微博">热门微博</option>
<option value="关注人微博">关注人微博</option>
<option value="认证用户微博">认证用户微博</option>
<option value="媒体微博">媒体微博</option>
<option value="观点微博">观点微博</option>
</select>
</div>
<div class="field half">
<label for="contain_type_input">筛选类型</label>
<select name="contain_type_input" id="contain_type_input" style="font-size: medium">
<option value="不筛选">不筛选</option>
<option value="包含图片">包含图片</option>
<option value="包含视频">包含视频</option>
<option value="包含音乐">包含音乐</option>
<option value="包含短链接">包含短链接</option>
</select>
</div>
</div>
<ul class="actions">
<li><button type="submit" id="topic_submit" disabled>开始分析</button></li>
<li><input type="reset" value="重置"/></li>
</ul>
</form>
<div id="topic_result"></div>
</article>
main.css
input[type="date"] {
-moz-transition: border-color 0.2s ease-in-out, box-shadow 0.2s ease-in-out, background-color 0.2s ease-in-out;
-webkit-transition: border-color 0.2s ease-in-out, box-shadow 0.2s ease-in-out, background-color 0.2s ease-in-out;
-ms-transition: border-color 0.2s ease-in-out, box-shadow 0.2s ease-in-out, background-color 0.2s ease-in-out;
transition: border-color 0.2s ease-in-out, box-shadow 0.2s ease-in-out, background-color 0.2s ease-in-out;
border-radius: 4px;
border: solid 1px #ffffff;
background: transparent;
color: #ffffff;
width: 80%;
height: auto;
padding: 0.5rem;
font-size: medium;
}
input[type="date"]:focus {
background: rgba(255, 255, 255, 0.075);
border-color: #ffffff;
box-shadow: 0 0 0 1px #ffffff;
outline: none;
}
input[type="date"]::placeholder {
color: rgba(255, 255, 255, 0.5);
opacity: 1;
}
::-webkit-input-placeholder {
color: rgba(255, 255, 255, 0.5);
opacity: 1;
}
:-moz-placeholder {
color: rgba(255, 255, 255, 0.5);
opacity: 1;
}
::-moz-placeholder {
color: rgba(255, 255, 255, 0.5);
opacity: 1;
}
:-ms-input-placeholder {
color: rgba(255, 255, 255, 0.5);
opacity: 1;
}
4.2、各更新模块/系统的运行截图
用户交互模块
数据可视化模块

数据预处理模块
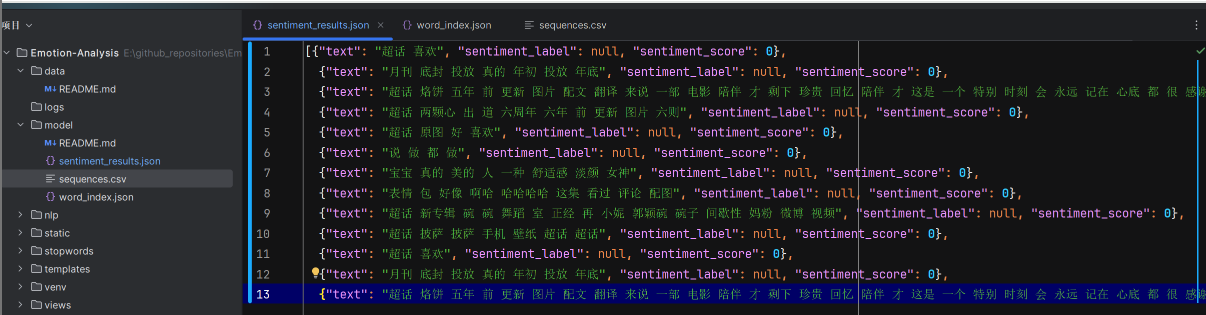

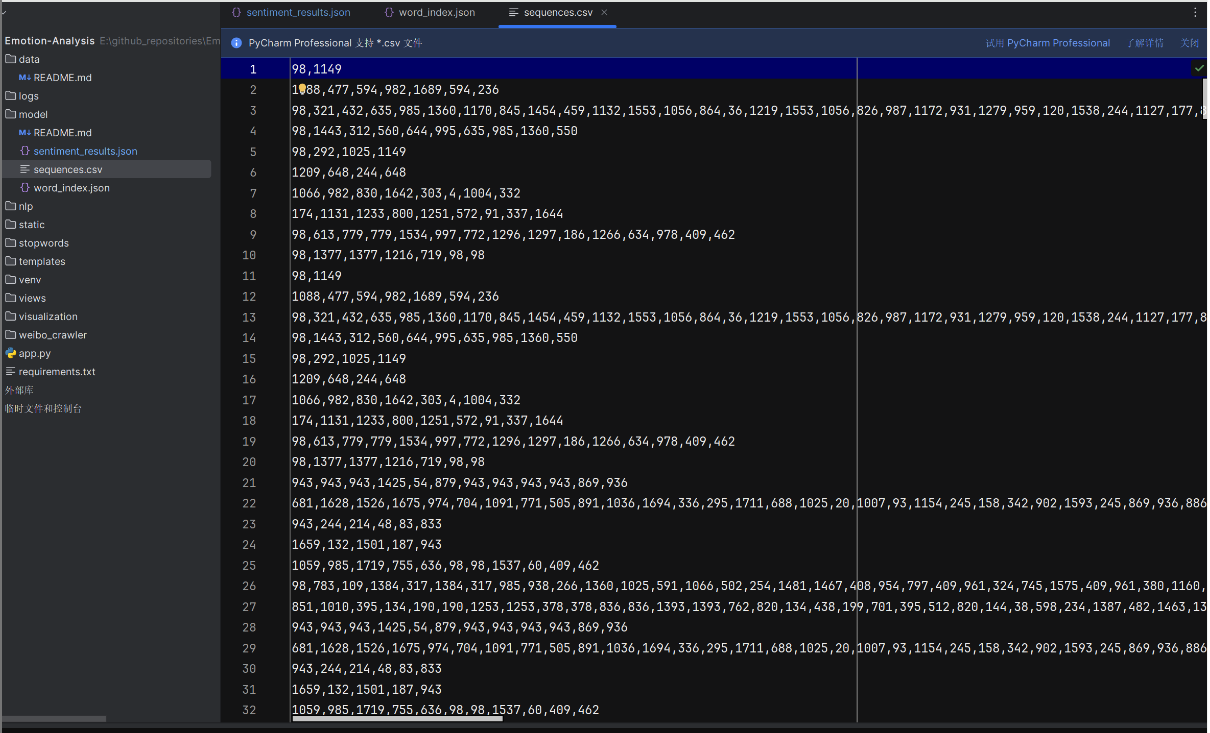
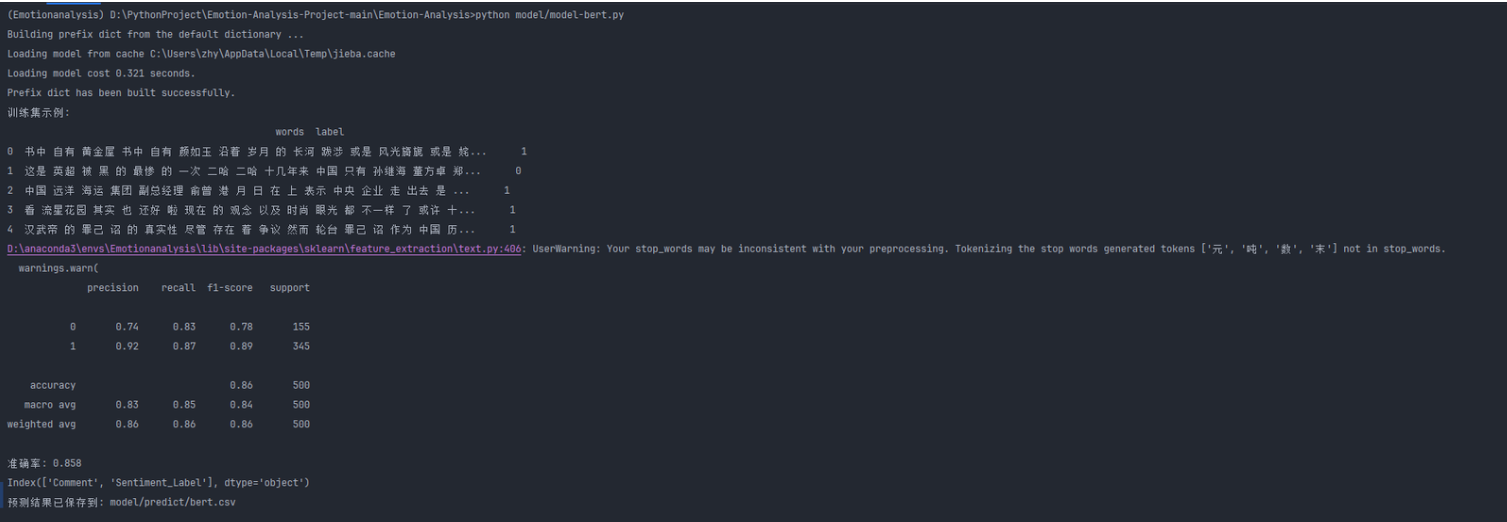
情感分析模块
5、每人每日总结
| 团队成员 | 每日总结 |
|---|---|
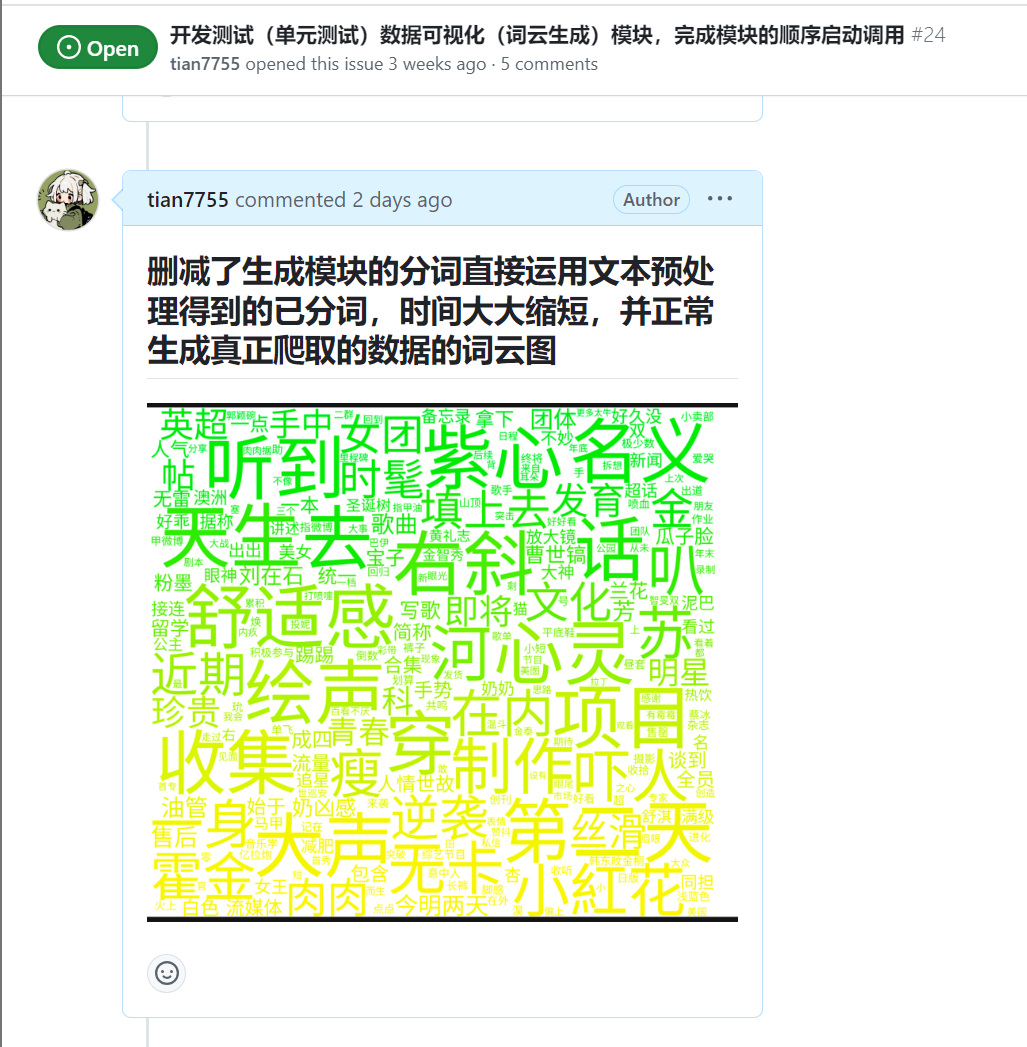
| 梁恬 | 今天完成了文本预处理模块的编写,但由于情感分析模型的输入不太明确,只是初步存储了可编写情感分析结果的字典,词汇表和文本整数序列化文件,后续还未根据情感分析模型进行修改。此外从文本预处理模块,直接将已分词的文本数据传入词云生成模块,节省了词云生成时间,并成功生成真正爬取的文本数据的词云图 |
| 潘思言 | 根据数据收集模块调整了前端输入界面,美化了输入界面样式,并优化交互模块 |
| 张颢严 | 今天完成了 BERT 模型的进一步优化,解决了数据预处理耗时问题,并对模型进行了初步评估。完成了情感分类任务的部分指标计算,但仍需调整超参数以提高模型精度和泛化能力 |
| 王睿娴 | 对微博正文的提取逻辑增加了安全性检查,确保 txt_sel 不为空后才调用相关方法。同时添加对长微博解析的支持 |

