队名:P人大联盟
团队成员
| 姓名 |
学号 |
| 王睿娴 |
3222003968 |
| 张颢严 |
3222004426 |
| 梁恬(组长) |
3222004467 |
| 潘思言 |
3222004423 |
本篇博客目录
4.2、的目录索引无法响应,其子目录可响应
1、Scrum Meeting
1.1、站立式会议照片

1.2、会议总结
| 昨日安排的任务 |
负责成员 |
实际完成情况 |
工作中遇到的困难 |
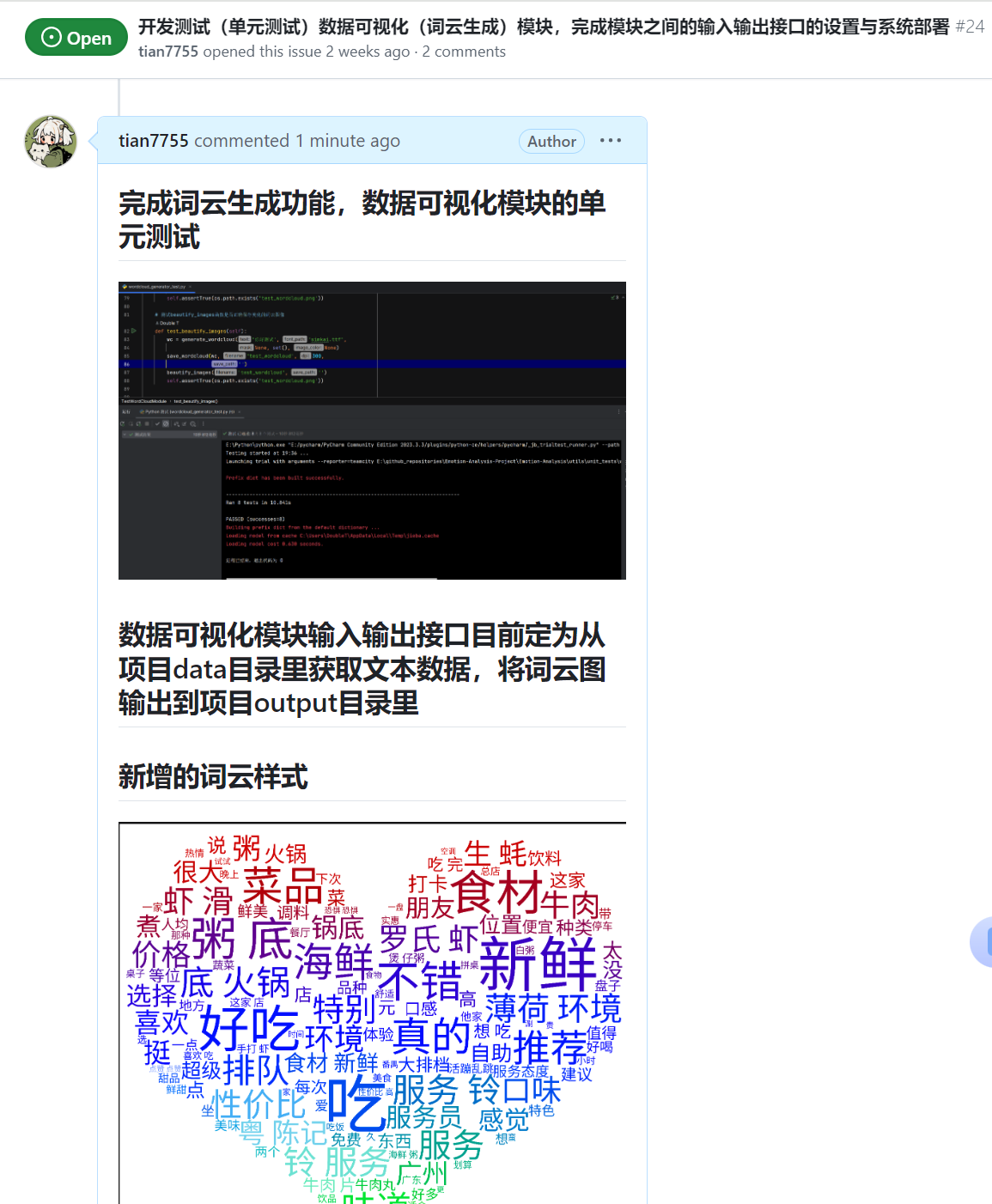
| 完善词云生成模块,设计确定词云样式,部署用户交互跟数据可视化(词云生成)之间的接口,对数据可视化模块进行单元测试 |
梁恬 |
词云生成功能已完成,还未确定词云样式,测试已完成编码,未完成全部验证,输入输出接口改为在项目目录里进行文件调用 |
词云生成时长 |
| 搭建基本前端界面 |
潘思言 |
前端界面需求的显示与交互正常运行 |
输入的异常处理仍需改进 |
| 综合评估多种模型 |
张颢严 |
对数据进行标注 |
数据量较大,标注过程中耗时较多 |
| 初步实现了微博爬虫的基本框架 |
王睿娴 |
正常运行 |
URL逻辑结构不一致 |
| 今日计划的任务 |
负责成员 |
| 完成数据可视化的单元测试的全部验证,商讨确认词云样式,查询并尝试搭建后期部署到互联网上的架构 |
梁恬 |
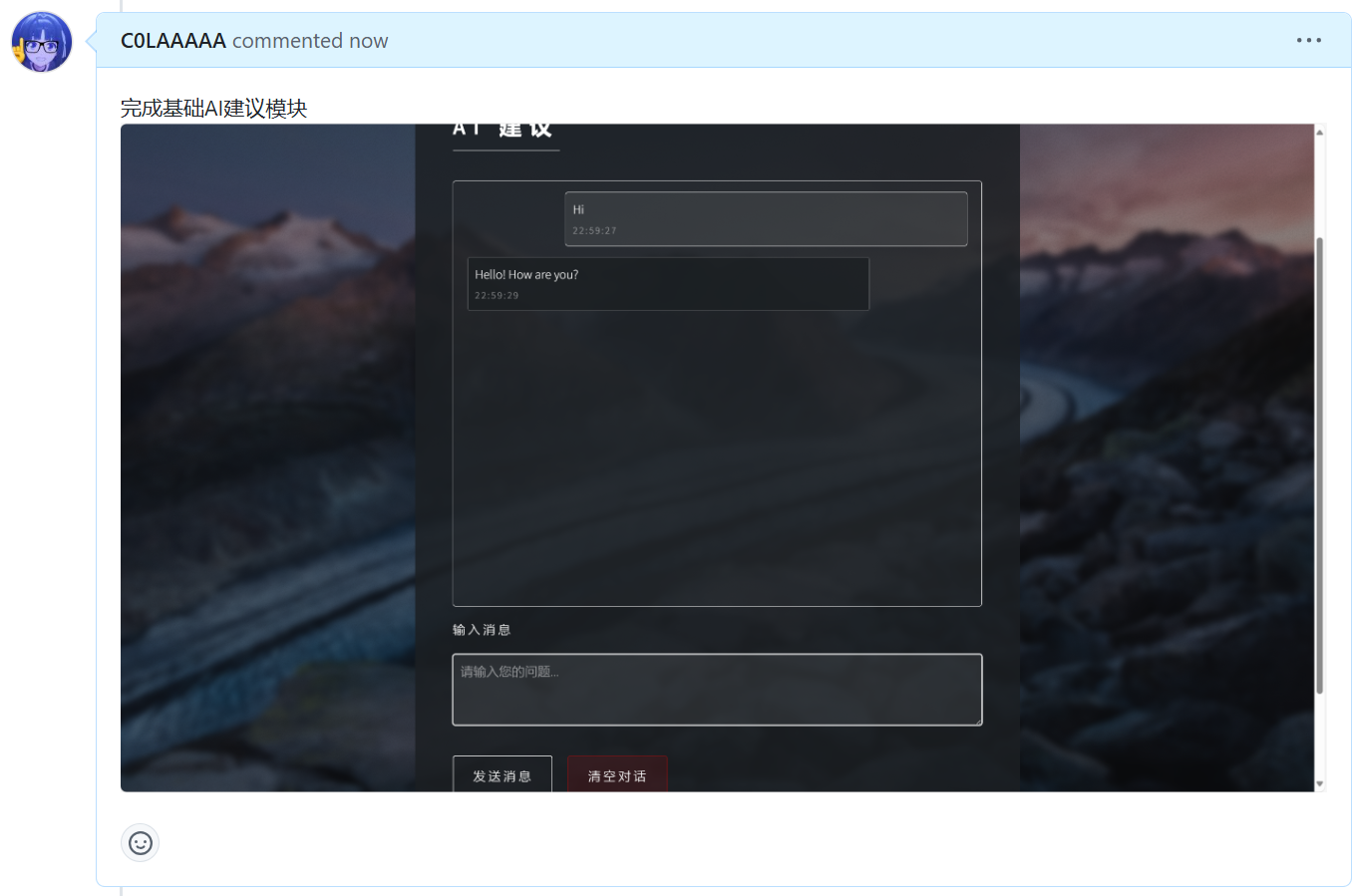
| AI建议模块初步实现 |
潘思言 |
| 编写基于朴素贝叶斯分类器进行情感分析的程序,训练数据集中的微博文本,提取关键词 |
张颢严 |
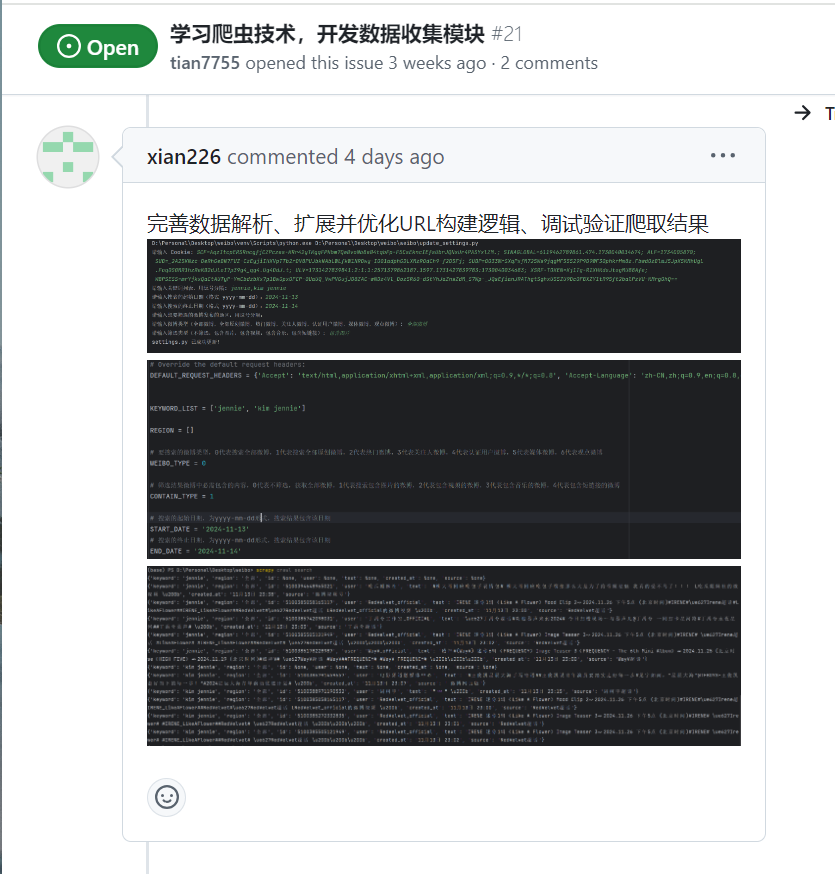
| 完善数据解析、扩展并优化URL构建逻辑、调试验证爬取结果 |
王睿娴 |
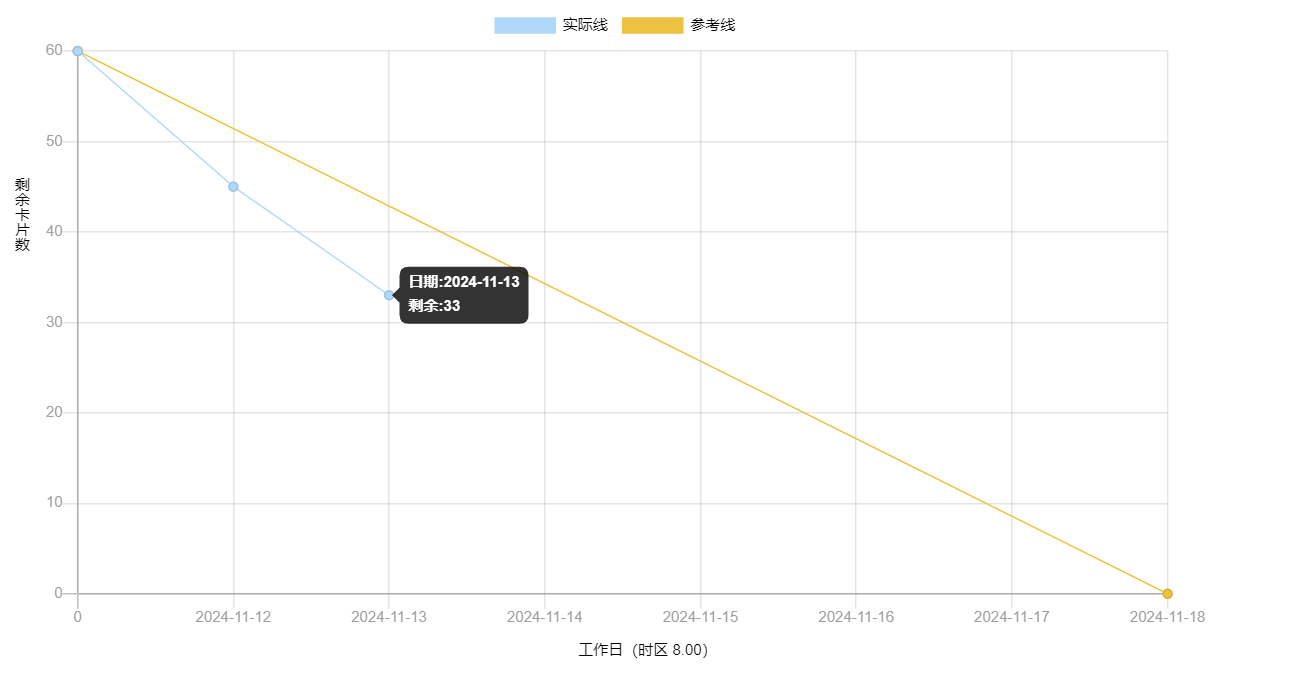
2、燃尽图
3、代码/文档签入记录
3.1、当天编码规范文档更新截图

4、项目程序/模块的最新
4.1、最新模块的代码
点击查看数据可视化模块最新代码
wordcloud_generator_test.py
import os
import unittest
from unittest.mock import patch, mock_open # unittest.mock用于编写和运行测试用例
from utils.wordcloud_generator import (load_text_data, load_stopwords,
generate_wordcloud, save_wordcloud,
beautify_images, cut_words)
class TestWordCloudModule(unittest.TestCase):
# 设置测试环境
def setUp(self):
# 设置测试数据文件和停用词文件的路径
self.test_data_path = 'test_data.csv'
# 创建测试数据文件
with open(self.test_data_path, 'w', encoding='utf-8-sig') as f:
f.write('这是对词云生成功能的测试用例')
# 清理测试环境
def tearDown(self):
# 删除测试数据文件和停用词文件
os.remove(self.test_data_path)
os.remove(self.test_stopwords_path)
# 测试load_text_data函数是否正确读取文件内容
def test_load_text_data(self):
# 模拟文件打开操作
with patch('builtins.open', mock_open(read_data='这是对词云生成功能'
'的测试用例')):
result = load_text_data('test_data.txt')
self.assertEqual(result, '这是对词云生成功能的测试用例')
# 测试load_text_data函数在文件不存在时的行为
def test_load_text_data_file_not_found(self):
# 模拟文件打开时抛出FileNotFoundError异常
with patch('builtins.open', side_effect=FileNotFoundError):
result = load_text_data('non_existent_file.txt')
self.assertIsNone(result)
# 测试load_stopwords函数在文件不存在时的行为
def test_load_stopwords_file_not_found(self):
with patch('builtins.open', side_effect=FileNotFoundError):
result = load_stopwords('non_existent_file.txt')
self.assertEqual(result, set())
# 测试generate_wordcloud函数是否正确生成词云对象
def test_generate_wordcloud(self):
text = '你好测试'
font_path = 'simkai.ttf'
mask = None
stopwords = set()
image_color = None
wc = generate_wordcloud(text, font_path, mask, stopwords, image_color)
self.assertIsNotNone(wc)
# 测试save_wordcloud函数是否正确保存词云图像
def test_save_wordcloud(self):
# 测试保存词云图函数
wc = generate_wordcloud('你好测试', 'simkai.ttf',
None, set(), None)
save_wordcloud(wc, 'test_wordcloud', 300,
'')
self.assertTrue(os.path.exists('test_wordcloud.png'))
# 测试beautify_images函数是否正确保存美化的词云图像
def test_beautify_images(self):
wc = generate_wordcloud('你好测试', 'simkai.ttf',
None, set(), None)
save_wordcloud(wc, 'test_wordcloud', 300,
'')
beautify_images('test_wordcloud', '')
self.assertTrue(os.path.exists('test_wordcloud.png'))
if __name__ == '__main__':
unittest.main()
点击查看建议模块最新代码
@pb.route('/gpt_suggestion', methods=['GET', 'POST'])
def gpt_suggestion():
preset_text = request.args.get('text', '')
user_input = request.form.get('text') or preset_text
if not user_input:
return jsonify(result={'error': '未提供输入文本'})
try:
chat_history = json.loads(request.form.get('history', '[]'))
messages = [{"role": "assistant" if msg['type'] == 'ai' else "user", "content": msg['content']}
for msg in chat_history[-10:]]
messages.append({"role": "user", "content": user_input})
openai.api_key = os.getenv("OPENAI_API_KEY")
openai.api_base = os.getenv("OPENAI_API_BASE")
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages,
max_tokens=1000,
temperature=0.7
)
gpt_response = response['choices'][0]['message']['content'].strip()
return jsonify(result={'gpt_response': gpt_response})
except openai.error.OpenAIError as e:
return jsonify(result={'error': f"GPT API 调用出错: {str(e)}"})
except Exception as e:
return jsonify(result={'error': f"出现未知错误: {str(e)}"})
点击查看情感分析模块最新代码
import os
from snownlp import SnowNLP
import pandas as pd
# 加载原始评论数据
def load_raw_comments(file_path):
"""
从文件中加载原始评论数据
:param file_path: 文本文件路径,每行一个评论
:return: 评论列表
"""
comments = []
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
comment = line.strip()
if comment:
comments.append(comment)
return comments
# 标注情感标签
def label_sentiments(comments):
"""
使用 SnowNLP 对评论进行情感分析并标注标签
:param comments: 评论列表
:return: DataFrame,包含评论和情感标签
"""
labeled_data = []
for comment in comments:
try:
s = SnowNLP(comment)
sentiment_score = s.sentiments # 得到情感得分,范围为 [0, 1]
print(f"scores : {sentiment_score}")
# 标注情感标签
if sentiment_score < 0.6:
label = 0 # 负面
elif sentiment_score <= 0.99:
label = 1 # 中性
else:
label = 2 # 正面
labeled_data.append((comment, label))
except Exception as e:
print(f"Error processing comment: {comment}, Error: {e}")
# 转为 DataFrame
df = pd.DataFrame(labeled_data, columns=['Comment', 'Sentiment_Label'])
return df
# 保存标注结果
def save_labeled_data(df, output_path):
"""
保存标注后的数据到文件
:param df: 标注后的 DataFrame
:param output_path: 输出文件路径
"""
df.to_csv(output_path, index=False, encoding='utf-8')
if __name__ == '__main__':
# 文件路径设置
input_file = r'D:\PythonProject\Emotion-Analysis-Project-main\Emotion-Analysis\model\train_texts.csv' # 原始评论文件路径
output_file = 'labeled_train_comments.csv' # 标注结果保存路径
# 检查文件是否存在
if not os.path.exists(input_file):
print(f"Input file not found: {input_file}")
exit()
# 加载评论
print("Loading comments...")
comments = load_raw_comments(input_file)
# 进行情感标注
print("Labeling sentiments...")
labeled_df = label_sentiments(comments)
# 保存标注结果
print(f"Saving labeled data to {output_file}...")
save_labeled_data(labeled_df, output_file)
print("Process completed successfully!")
4.2、各更新模块/系统的运行截图
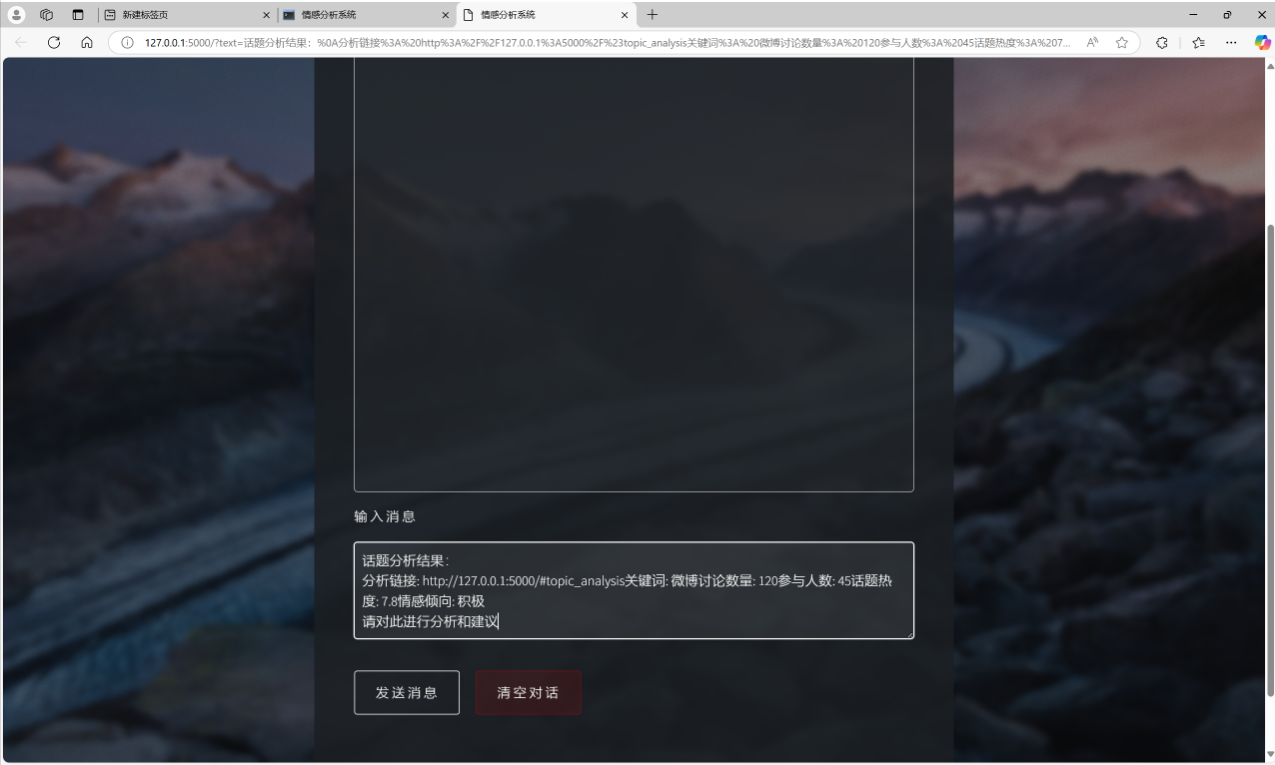
建议模块
数据可视化模块
- 单元测试截图


数据收集模块
情感分析模块
- 其中标注结果0,1,2分别表示负面,中性和正面

5、每人每日总结
| 团队成员 |
每日总结 |
| 梁恬 |
今天基本完成数据可视化模块,之后会根据前后对接模块进行输入输出的调整。词云生成慢的解决方法是直接接收数据处理跟情感分析模块已经经过分词处理的文件,减少分词在生成中占用的时间。部署查了相关资料但有点拿不太准,需要对flask框架搭建的用户界面的代码进行改进与应用,因此后续将由潘思言主导部署系统,我则协同 |
| 潘思言 |
采用调用API实现网页内的AI建议功能,仍需根据其他模块的实现效果进行调整修改 |
| 张颢严 |
用于加载评论数据、使用 SnowNLP 进行情感分析、标注情感标签,并将结果保存到 CSV 文件。测试了代码的运行逻辑,能够正确读取输入数据并生成标注结果文件 |
| 王睿娴 |
今日完成了完善数据解析、扩展并优化URL构建逻辑、调试验证爬取结果,但还需要进一步优化 |










 浙公网安备 33010602011771号
浙公网安备 33010602011771号