第2篇Scrum冲刺博客
| 软件工程 | 班级链接 |
|---|---|
| 作业要求 | 作业要求 |
| 作业目标 | 项目冲刺 |
| github仓库 | 团队项目 |
队名:P人大联盟
团队成员
| 姓名 | 学号 |
|---|---|
| 王睿娴 | 3222003968 |
| 张颢严 | 3222004426 |
| 梁恬(组长) | 3222004467 |
| 潘思言 | 3222004423 |
本篇博客目录
1、Scrum Meeting
1.1、站立式会议照片

1.2、会议总结
| 昨日安排的任务 | 负责成员 | 实际完成情况 | 工作中遇到的困难 |
|---|---|---|---|
| 搭建基本项目架构,完成初步的词云生成算法 | 梁恬 | 搭建好并上传到团队github仓库,已可根据.csv文本数据文件生成默认矩形词云图 | 如何使得词云图的分辨率与字体内容清晰度更高 |
| 搭建基础的AI建议模块架构 | 潘思言 | 完成与现有AI 的接口链接 | 如何处理并发问题 |
| 收集多种模型资料 | 张颢严 | 使用现有数据集尝试加载模型观察效果 | 模型性能与现有任务的匹配度需进一步验证 |
| 编写初步的爬虫逻辑、编写动态更新配置的 Python 脚本 | 王睿娴 | 完成了SearchSpider爬虫,能抓取并解析微博内容实现了动态更新settings.py配置的功能 | 微博页面结构复杂,定位元素时 XPath 编写较为繁琐 |
| 今日计划的任务 | 负责成员 |
|---|---|
| 完善词云生成模块,设计确定词云样式,部署用户交互跟数据可视化(词云生成)之间的接口,对数据可视化模块进行单元测试 | 梁恬 |
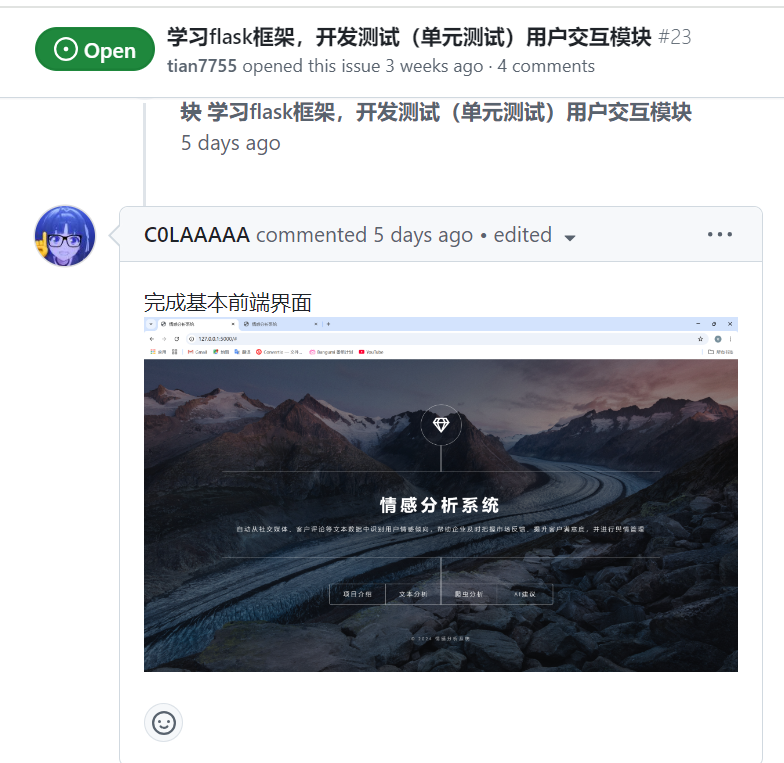
| 搭建基本前端界面 | 潘思言 |
| 综合评估多种模型 | 张颢严 |
| 继续编写初步的爬虫逻辑 | 王睿娴 |
2、燃尽图
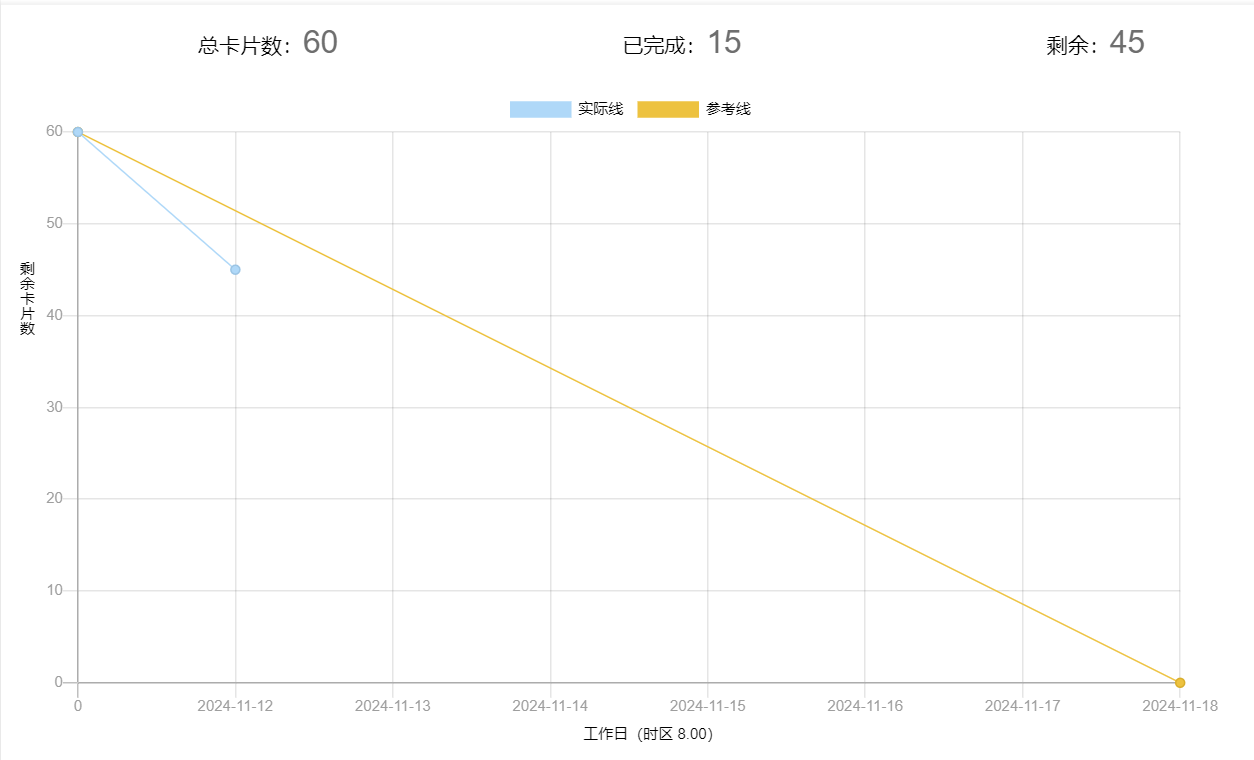
3、代码/文档签入记录
| 团队成员 | 代码/文档签入截图 | 对应的issues内容截图 | 对应的issues链接 |
|---|---|---|---|
| 梁恬 |  |
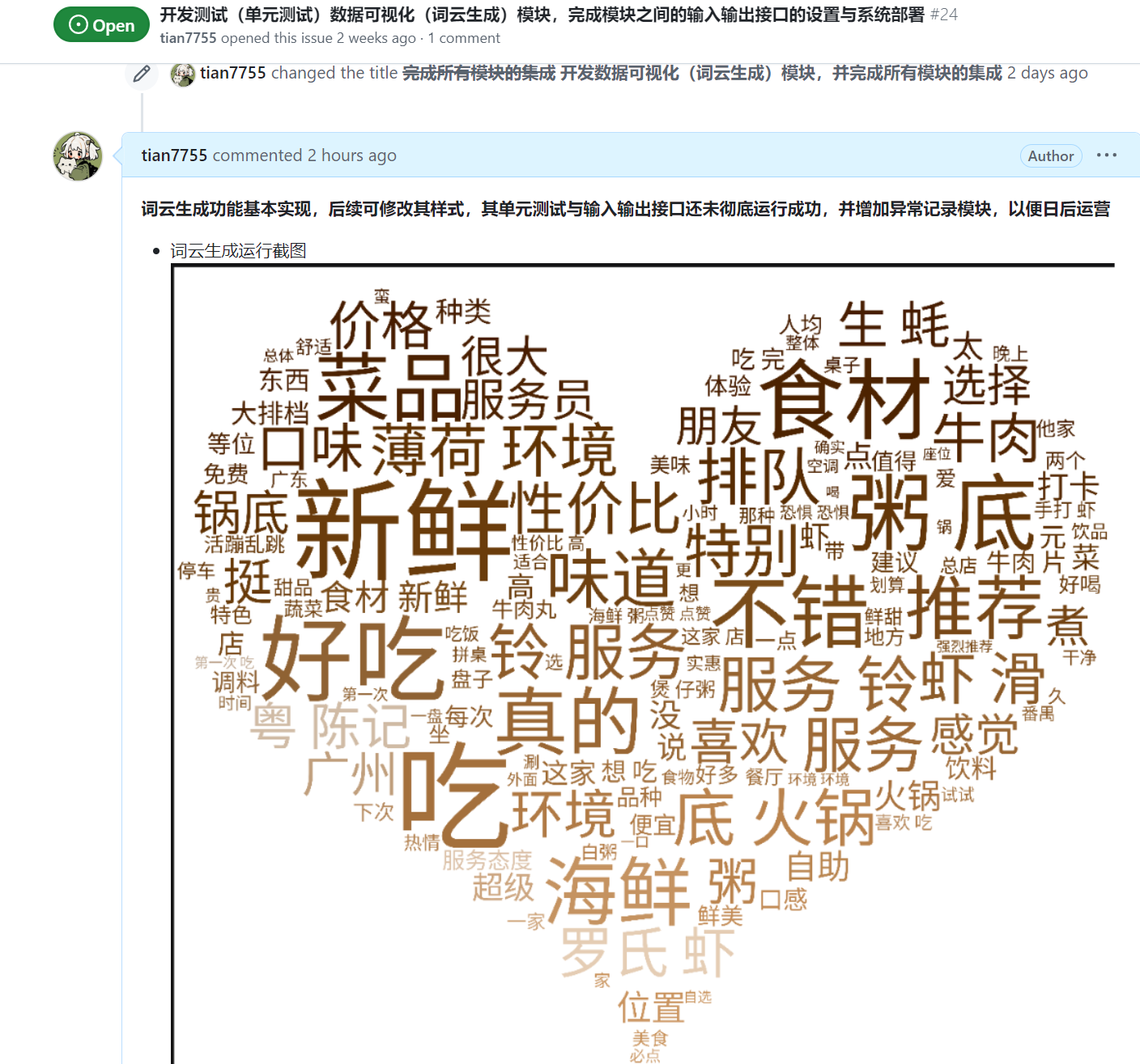 |
issues链接 |
| 潘思言 | 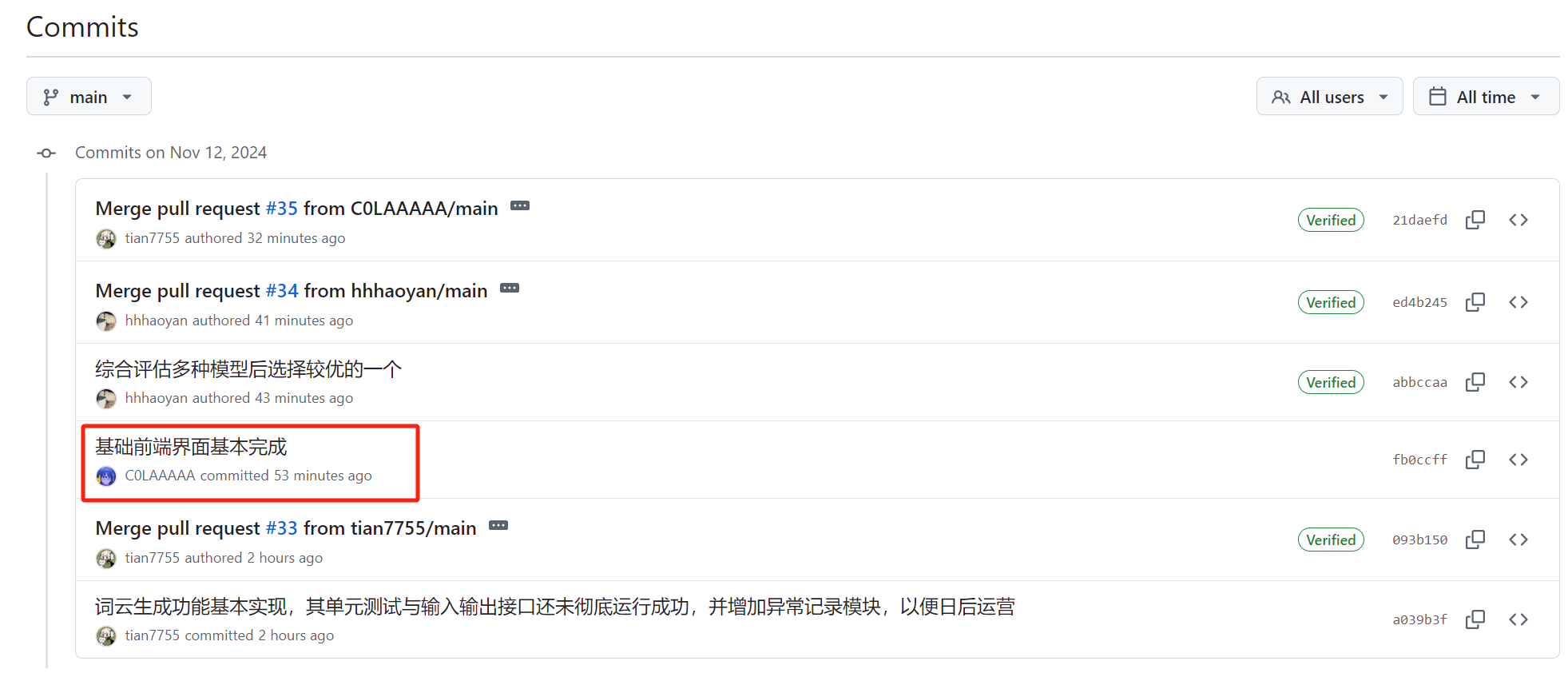 |
 |
issues链接 |
| 张颢严 | 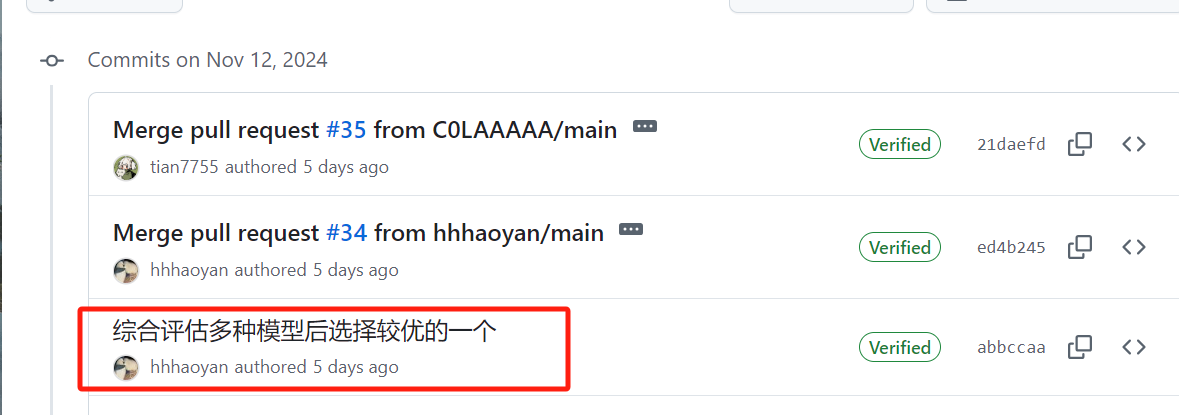 |
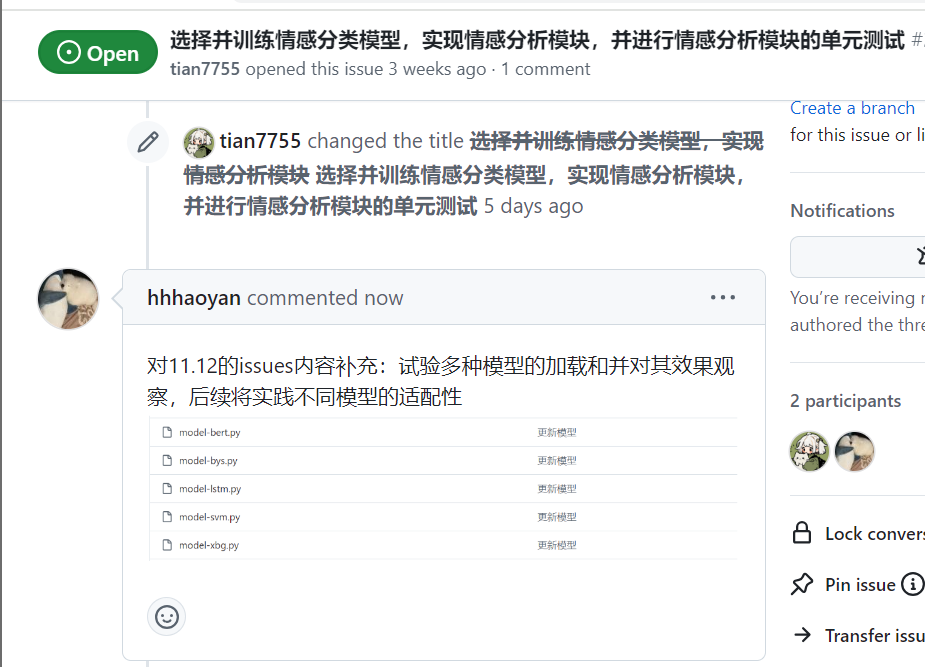 |
issues链接 |
| 王睿娴 | 不熟悉团队版本管理操作,因此在第二天一早先只是在在个人fork仓库提交完成内容  |
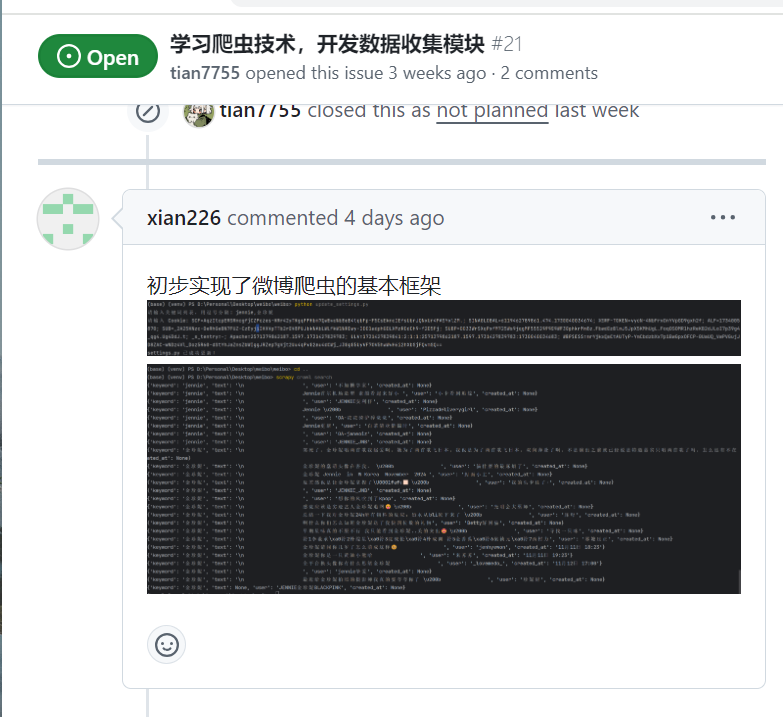 |
issues链接 |
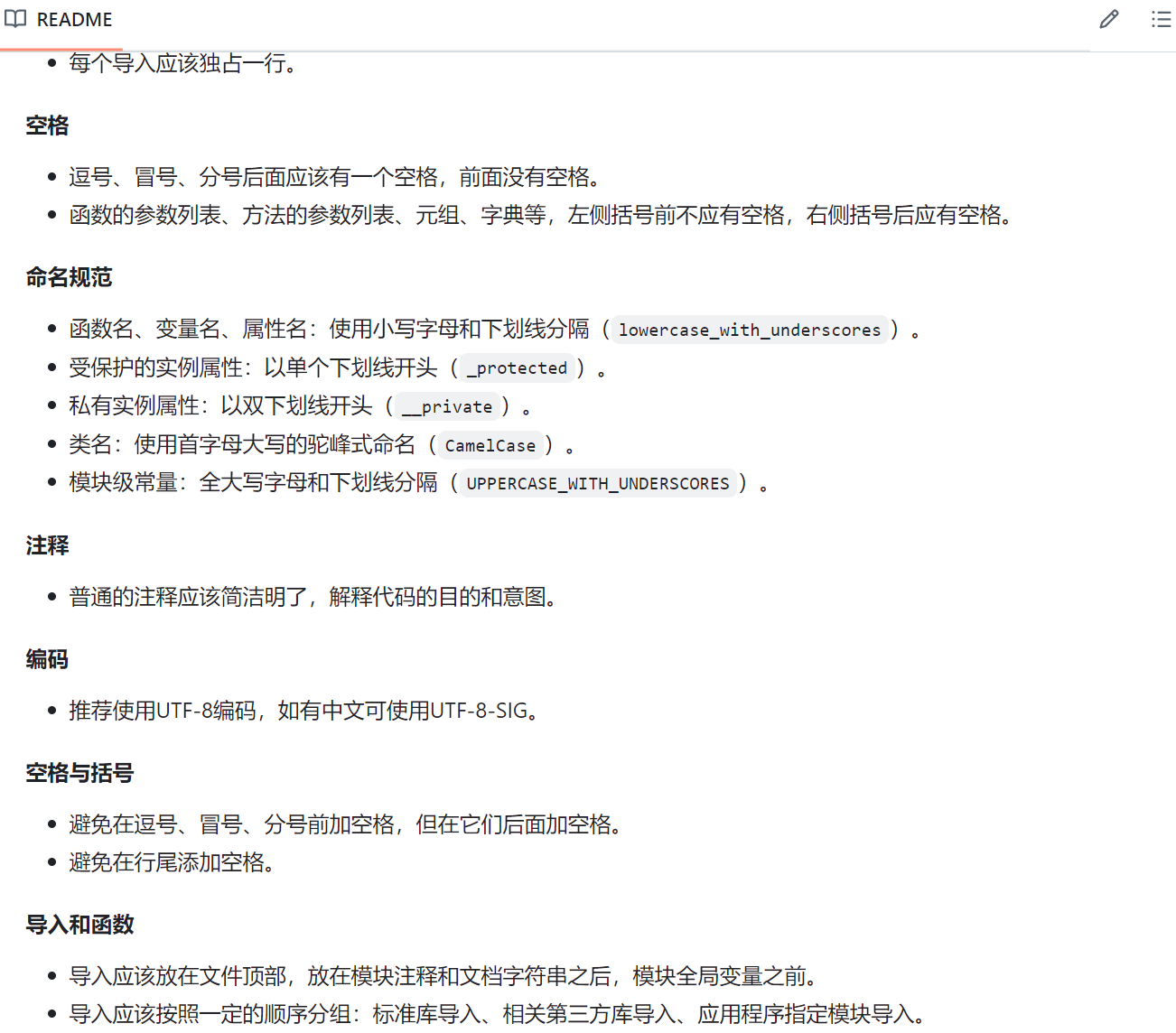
3.1、当日编码规范文档截图

4、项目程序/模块的最新
4.1、最新模块的代码
点击查看数据可视化模块最新代码
wordcloud.py
# import jieba
# import concurrent.futures
import imageio.v2 as imageio
# 导入配置好的logger对象
from logger_config import logger
from PIL import Image, ImageEnhance
from matplotlib import pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
# 读取文本数据
def load_text_data(file_path):
try:
with open(file_path, 'r', encoding='utf-8-sig') as f:
return f.read()
except FileNotFoundError:
logger.error(f"文件 {file_path} 未找到。")
return None
# 加载停用词列表
def load_stopwords(file_path):
try:
with open(file_path, 'r', encoding='utf-8-sig') as f:
return set(f.read().splitlines())
except FileNotFoundError:
logger.error(f"文件 {file_path} 未找到。")
return set()
# 创建词云图
def generate_wordcloud(text, font_path, mask, stopwords, image_color):
wc = WordCloud(
font_path=font_path,
background_color="white", # 设置背景颜色
color_func=image_color, # 设置字体颜色,将上面模板图像生成的颜色传入词云
max_words=250, # 最多显示的词数
max_font_size=250, # 字体最大值
min_font_size=30, # 字体最小值
random_state=60, # 设置随机种子以获得可重复的结果
width=2000, height=1800, # 设置图片的尺寸
margin=1, # 设置词与词之间的距离
stopwords=stopwords,
mask=mask,
prefer_horizontal=1.0, # 词语横排显示的概率
scale=3 # 增加 scale 参数以提高输出图像的分辨率
)
return wc.generate(text)
# 保存词云图
def save_wordcloud(wc, filename, dpi, save_path=''):
# 显式地关闭所有打开的图形
plt.close('all')
# 使用Agg后端避免启动GUI
plt.switch_backend('Agg')
plt.figure(figsize=(20, 18), dpi=dpi) # 设置图像尺寸和 DPI
plt.imshow(wc, interpolation='bilinear') # 使用抗锯齿插值
plt.axis("off")
plt.tight_layout(pad=0)
plt.savefig(f"{save_path}{filename}.png", dpi=dpi) # 保存为 PNG 格式
# 美化词云图
def beautify_images(filename, dpi, save_path=''):
image = Image.open(f"{save_path}{filename}.png")
# 调整图片的对比度、色彩饱和度和锐度
contrast = 1.1 # 对比度增强10%
color = 1.1 # 色彩饱和度增强10%
sharp = 1.3 # 锐度增强30%
img_contrast = ImageEnhance.Contrast(image).enhance(contrast)
img_color = ImageEnhance.Color(img_contrast).enhance(color)
img_sharp = ImageEnhance.Sharpness(img_color).enhance(sharp)
img_sharp.save(f"{save_path}{filename}_beautified.png")
# 单个文件的词云图生成
def wordcloud_generator(sentiment, file_info, save_path, font_path, stopwords):
try:
# 读取文本数据与读取异常处理
text_data = load_text_data(file_info['text'])
if text_data is None:
logger.error(f"未能加载数据文件: {file_info['text']}, 中断该文件的词云图生成")
return
# 引进背景图片与图片颜色
bg_image = imageio.imread((file_info['background'])) # 使用 PIL 读取背景图片
bg_image_color = ImageColorGenerator(bg_image)
# 创建,保存并优化词云图
wordcloud = generate_wordcloud(words, font_path, bg_image, stopwords, bg_image_color)
save_wordcloud(wordcloud, f'wordcloud_{sentiment}', dpi=300, save_path=save_path)
beautify_images(f'wordcloud_{sentiment}', 300, save_path)
except Exception as e:
logger.error(f"生成 {sentiment} 词云图时发生错误: {e}")
# 整体词云图生成器
def wordclouds_generator():
# 参数data_file
# 定义文本数据文件路径
data_files = {
'positive': {
'text': '../data/positive_data.csv',
'background': '../images/wordcloud_backgrounds/positive_background.png'
},
'negative': {
'text': '../data/negative_data.csv',
'background': '../images/wordcloud_backgrounds/negative_background.png'
},
'neutral': {
'text': '../data/neutral_data.csv',
'background': '../images/wordcloud_backgrounds/neutral_background.png'
},
'all': {
'text': '../data/preprocess_data.csv',
'background': '../images/wordcloud_backgrounds/all_background.png'
}
}
# 定义保存和字体路径
save_path = '../output/wordclouds/'
font_path = '../fonts/NotoSansSC-Regular.ttf'
# 加载停用词列表
stopwords = load_stopwords('../stopwords/stopwords.txt')
for sentiment, file_info in data_files.items():
wordcloud_generator(sentiment, file_info, save_path, font_path, stopwords)
if __name__ == "__main__":
wordclouds_generator()
点击查看用户交互模块最新代码
app.py
from flask import Flask, render_template
from views.page import page
app = Flask(__name__)
app.register_blueprint(page.pb)
@app.route('/')
def home():
return render_template('index.html')
if __name__ == '__main__':
app.run()
page.py
from flask import Blueprint, request, jsonify
pb = Blueprint('page', __name__, url_prefix='/page', template_folder='templates')
@pb.route('/text_analysis', methods=['POST'])
def text_analysis():
result = None
text = request.form.get('text')
if text == '测试':
result = '正面'
else:
result = '中性'
return jsonify(result=result)
@pb.route('/spider_analysis/topic', methods=['POST'])
def spider_analysis_topic():
result = None
url = request.form.get('url')
cookie = request.form.get('cookie')
keyword = request.form.get('keyword')
analysis_result = {
'url': url,
'cookie': cookie,
'keyword': keyword,
'discussion_count': 120,
'participant_count': 45,
'popularity_score': 7.8,
'sentiment': '积极'
}
return jsonify(result=analysis_result)
4.2、各更新模块/系统的运行结果截图
用户交互模块




数据可视化模块





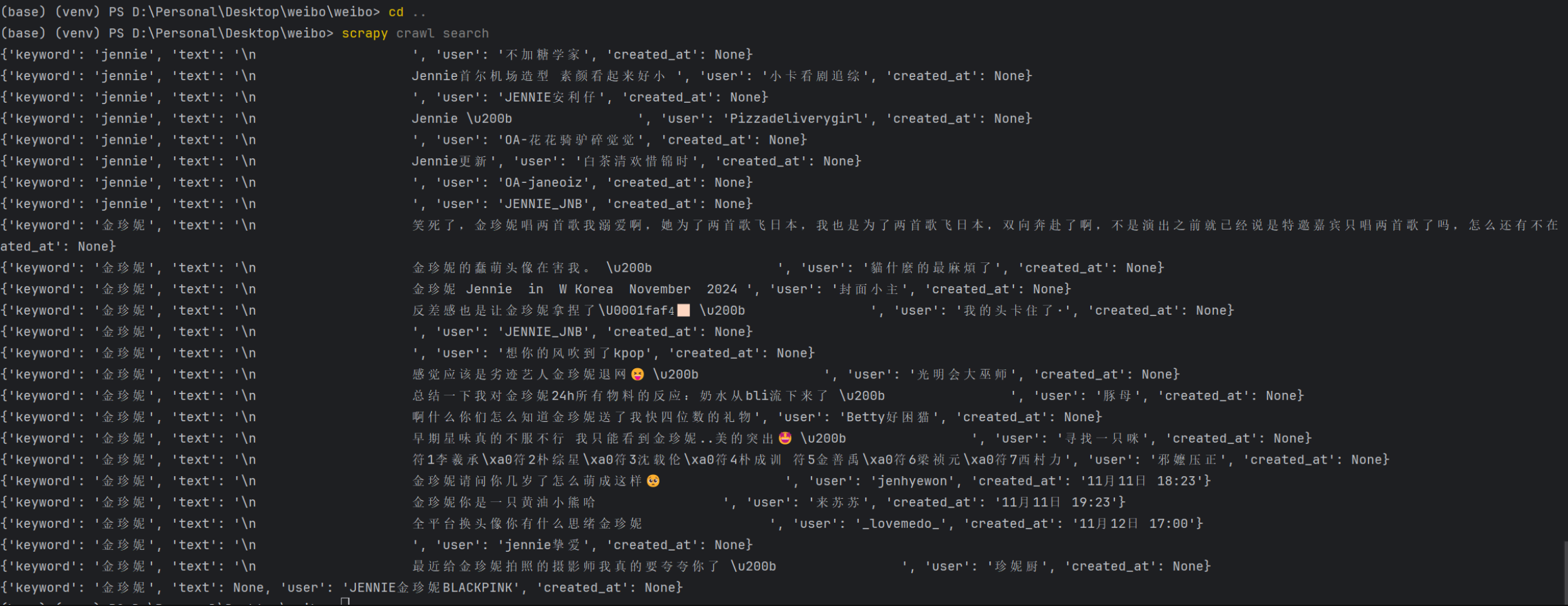
数据收集模块

5、每人每日总结
| 团队成员 | 每日总结 |
|---|---|
| 梁恬 | 今天效率一般,花费超出预期的时间也没能彻底完成要求的任务,还需再接再厉。并且发现模块实现具体成果,输入输出以及每天需要提交记录进度还未彻底明确,导致大家在进行开发自身模块之外的团队工作时有点手忙脚乱。明天会议上将对此进行更细致的商讨与确认。 |
| 潘思言 | 今天的开发很好地锻炼了我的团队协作能力,更进一步地认识到团队开发的流程 |
| 张颢严 | 今天主要是试验多种模型的加载和效果观察,逐渐对模型的选择方向有了更清晰的理解。不过仍需在后续工作中深入调研不同模型的适配性,并与团队讨论如何更高效利用现有数据。 |
| 王睿娴 | 今日的工作有效奠定了微博爬虫的基础框架,已成功实现了基本数据抓取。虽然过程中遇到了一些配置和页面解析的挑战,但通过耐心调试和调整,基本达成了预期目标。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号